
요즘 내가 자소서에 자주 쓰고 있는 나의 목표인 크고 깊은 딥러닝 모델 구축의 근거가 되는 논문이다. 물론 논문을 자세히 살펴보지는 못했기 때문에 리뷰를 해보고자 한다.
Abstract:
최신 딥러닝 모델의 크기가 증가함에 따라 double_descent 현상을 보인다. 모델 크기 함수 뿐만 아니라 epoch 수에서도 발생한다.
그 뒤부터는 거의 실험에 대한 내용이고 이론은 적지만 이미 가장 중요한 포인트가 나온 것 같다.
Introduction:
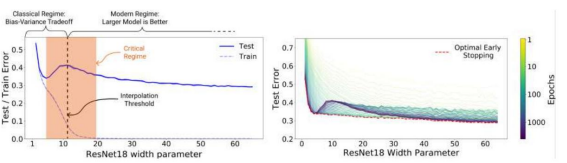
CIFAR-10 데이터를 ResNel18로 작업한 내용이다. 보면 double_descent 현상을 바로 볼 수 있는데 과거 모델의 복잡성이 특정 임계값을 통과하면 테스트 오류를 지배하는 분산 방향으로 과적합 되는데 이 시점부터 모델의 복잡성이 증가하면 성능이 저하된다고 발표했다.
고전 통계의 통념: 단 특정 임계값을 통과 하면 "모델이 클수록 더 나빠진다"
현대 신경망에서는 이 현상이 보이지 않는다. 현대 실무자들은 더 큰 모델이 더 좋다고 주장한다.
early-stop 또한 논란의 여지가 많다. 일부에서는 성능 향상을 위해 early-stop시키지만 다른 설정에서는 오류 없이 훈련하여 epoch수를 늘려 더 성능을 향상시킨다.
고전 통계학자와 딥러닝 실무자의 공통된 의견은 더 많은 데이터가 항상 더 좋다. 이다.
앞의 Introduction을 딥러닝 실무자 입장에서만 요약해본다면...
1. 더 복잡한 모델일수록 좋다.
2. 오류 없이 epoch수를 늘려 오래 학습한 모델이 더 좋다.
3. 더 많은 데이터를 사용할 수록 좋다.
MNIST데이터와 언어번역 Task에서도 실험하였고 Double-Descent는 발생했다.
모델 복잡성의 테스트 오류는 고전적인 Bios/variance tradeoff에 의해 U자 모형이 나타나지만 모델 복잡성이 보간할 수 있을 만큼 충분히 커지면... 즉 훈련 오류가 0에 가까운 수치에 도달하면 Double-Descent가 발생한다.
Early-stop은 매개변수화된 모델의 상대적으로 좁은 매개변수 영역에서만 도움이 된다.
결국 실험을 통해 위의 1,2번의 고전적 이론을 타파했다.
그 뒤부터는 자체적인 조정으로 실험을 진행한다. ResNet을 주로 사용했고 언어 번역 모델 실험도 진행한다.
Conclusion and Discussion:
결론적으로 Double-Descent 현상이 발생하긴 하나 그 조건이 중요하다. 오류 없이 모델 학습을 진행하는 것이 중요하다... 하지만 이를 정확히 이행했을 때 최적의 early-stop의 경우보다 더 좋은 성능의 모델을 만들 수 있고 early-stop의 경우 데이터를 더 잘 활용할 수 있다는 점에서 좋다. 이 두가지 경우는 열린 문제라고 필자는 주장하고 있다...
나의 결론:
하지만 나는 결과적으로 Double-Descent의 발생으로 모델의 성능을 계속 내린 다는 점에서 딥러닝의 크고 복잡한 모델과 많은 양의 데이터의 중요성을 배웠다. 물론 상황에 따라 최선의 결론으로 학습을 진행하는 것이 유능한 AI 엔지니어겠지만 일단 정말 크고 복잡하고 깊은 모델 구축을 꼭 함께 해보고싶다.
