
0930
1. 도커 (Docker)
-
어플리케이션을 신속하게 구축, 테스트 및 배포할 수 있는 소프트웨어 플랫폼
-
"컨테이너 기반의 오픈소스 가상화 플랫폼"
-
로컬과 클라우드의 OS나 버전, 환경세팅이 다르기 때문에 발생하는 오류를
쉽게 해결 -
윈도우에서 우분투나 다양한 환경 사용가능
-
전체적인 환경 설정을 컨테이너화한 이미지를 Pull 해서 설치할 수 있음
-
컨테이너는 격리된 공간에서 프로세스가 동작하는 기술
-
협업 진행 시 팀원들 간의 Node 버전이 달라 충돌하고 에러가 발생하는 것을 방지
1) 설치 (윈도우)
https://hub.docker.com/search?type=edition&offering=community 에서 다운
- cmd 창에서
docker --version버전이 확인된다면 설치 된 것- x64 머신용 최신 WSL2 Linux 커널 업데이트 패키지 설치
2) 도커 실습
(1) 우분투 컨테이너 실행
docker run ubuntu:latest 하면 이미지 풀링되고 도커 컨테이너에 새로운것 추가됨
컨테이너를 이미지화해서 가져옴
docker run --rm -it ubuntu:latest /bin/bash 우분투에서 터미널 실행-> 바로 전환됨. 빠르고 경량화 장점
cat /etc/issue하면 우분투 환경 버전 나옴 (상태확인)
==> 도커환경에서 서버구축 완료. 그대로 ec2에서 실행하면 된다
==> putty로 pem키 이용해서 접속할 필요가 없어짐!
(2) tesorflow 실행
docker run -d -p 8888:8888 -p 6006:6006 teamlab/pydata-tensorflow:0.1하고 http://localhost:8888/ 로 들어가면 주피터 노트북 뜸 ㄷㄷ
(3) docker ps 하면 실행중인거 나옴 여기서 컨테이너 id볼수 있음

docker stop +해당id 하면 멈춤
docker rm +해당id 하면 삭제
docker images 하면 다운로드 된 이미지들 나옴
docker rmi +이미지 id하면 이미지 삭제3) 도커와 쿠버네티스
- 도커 : 하나의 컨테이너 관리
- 쿠버네티스 : 다수의 컨테이너 한번에 관리 가능
2. ELK Stack
ELK Stack 이란 Elastic Search / Logstash / Kibana 모두를 칭함
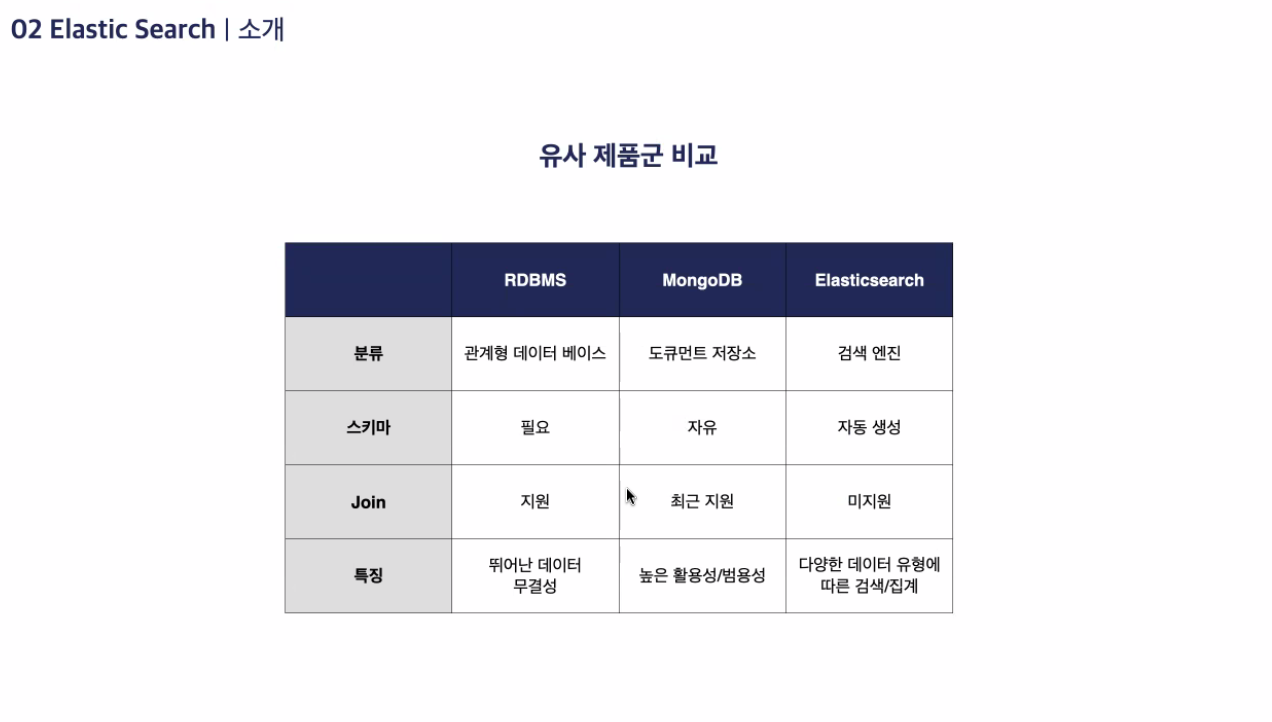
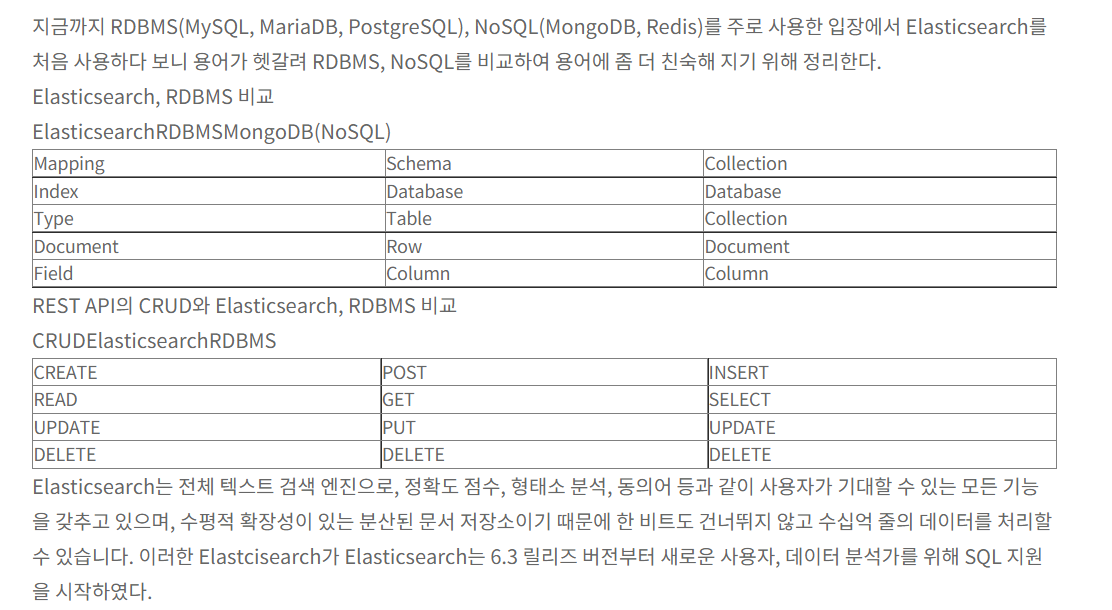
Elastic Search : 검색엔진 + 통계를 내는 툴. 데이터 저장 가능하지만 특화되어있지는 않음
Logstash : 데이터 로그 수집, DB에 있는 데이터를 전달, DB와 Elasticsearch의 통로
Kibana : 데이터들을 시각화
사용 흐름은 Logstash -> Elastic search -> Kibana
1) Elastic Search : 분산 검색 엔진
-
데이터 저장소가 아니며 MySQL과 같은 데이터베이스를 대체할 수는 없음
-
방대한 양의 데이터 신속 / 실시간으로 저장, 검색, 분석 가능
-
Json 형태로 데이터를 저장
-
모든 요청을 rest API 형태로 요청 및 응답
2) Elasticsearch 환경 구축
powershell에서 ssac 폴더 내에
git clone https://github.com/ksundong/docker-elk-kor.git=> 한글화 그런거 잘되어있다고함
cd docker-elk-kor로 폴더이동후
docker-compose build : 이미지 빌드
docker-compose up -d : 백그라운드 실행
docker-compose down -v : 종료도커에 E L K 모두 설치된다!
http://localhost:5601 로 들어가면 elastic이 딱!
3) Kibana 사용
http://localhost:5601 접속해서 dev tools 로 이동
POST : 생성
PUT : 생성 및 수정 PUT index이름/_doc (index이름 인 문서 요소 생성)
GET : 조회 => GET index이름/search (index이름 인 요소 전체 조회
DELETE : 삭제
POST_bulk : 대용량 데이터를 저장할때
=> 프리티 하게 쓰면 안된다!(ndjson 형태)
POST _bulk
{"index : {"_index": A, "id": 1}}
{"field":"test1"}
{"index : {"_index": A, "id": 2}}
{"field":"test2"}
{"index : {"_index": A, "id": 3}}
{"field":"test3"}
=> index 값은 A가 됨
4) 분석기
GET test/_analyze
{
"analyzer": "standard",
"text" : "ssac is seoul sofrtware academy cluster"
}=> text 값이 문자열로 쪼개져서 인덱싱 된다
-
캐릭터필드 : 입력받은 문자열을 변경, 불필요한 문자열 제거, 조건에 맞게 필터링
-
토크나이저 : 문자열을 토큰으로 분리 => 토큰: 분석기 내부에서 일시 저장 상태
-
토큰필터 : 분리된 토큰들에 대한 필터 작업, 대문자인것을 소문자로 바꿔줌
순서대로 진행되어 인덱스가 부여되어 반환.
=> 문자열을 잘게 쪼개서 역 인덱싱 가능하도록 함
5) 검색
검색방법
(1) Query Context : 유사도 검색 ( 분석기 자동 작동 )
=> 배민에서 '치킨' 검색 시 유사한 결과 모두 검색
(2) Filter Context : Yes or No
=> '치킨'이 있는지 없는지만 검색


Query Context 도 두가지로 나뉨
- Query String
GET kibana_sample_data_ecommerce/_search?q=customer_full_name:Mary
=> 표현방식이 한정적
- Query DSL
GET kibana_sample_data_ecommerce/_search
{
"query": {
"match": {
"customer_full_name": "mary"
}
}
}
GET kibana_sample_data_ecommerce/_search
{
"_source": ["customer_full_name"], ->이건 customer_full_name 만 뽑아옴
"query": {
"match": {
"customer_full_name": "mary"
}
}
}
GET kibana_sample_data_ecommerce/_search
{
"_source": ["customer_full_name"], ->이건 customer_full_name 만 뽑아옴
"size": 30,
"query": {
"match": {
"customer_full_name": {
"query": "mary bailey",
"operator": "and" >이건 mary 와 bailey 둘다 있어야 라는 조건 추가 / 기본은 or임
}
}
}
}
=> 다양한 옵션 추가 가능
match_phrase 는 단어의 순서까지 같아야만 가져옴
GET kibana_sample_data_ecommerce/_search
{
"_source": ["customer_full_name"],
"query": {
"match_phrase": {
"customer_full_name": "mary bailey" 와 "bailey mary" 둘이
다른 결과값 반환!
}
}
}
prefix 는 단어가 포함된 모든 것
GET kibana_sample_data_ecommerce/_search
{
"_source": ["customer_full_name"],
"size": 30,
"query": {
"prefix": { => ma 가 포함된 데이터!
"customer_full_name": {
"value": "ma"
}
}
}
}
multi_match 는 글자 순서에 상관없이 포함시 불러옴
GET kibana_sample_data_ecommerce/_search
{
"_source": ["customer_full_name"],
"size": 30,
"query": {
"multi_match": { => mary라는 글자가 어디에 있든 가져옴
"query": "mary",
"fields": [
"customer_first_name",
"customer_last_name"
]
}
}
}
