1주차에서 JVM의 구조를 다뤄봤고 이번 주차는 자바의 데이터 타입, 변수, 배열에 관해 공부해보자
목표
자바의 프리미티브 타입, 변수 그리고 배열을 사용하는 방법을 익힙니다.
학습할 것
- 프리미티브 타입 종류와 값의 범위 그리고 기본 값
- 프리미티브 타입과 레퍼런스 타입
- 리터럴
- 변수 선언 및 초기화하는 방법
- 변수의 스코프와 라이프타입
- 타입 변환, 캐스팅 그리고 타입 프로모션
- 1차 및 2차 배열 선언하기
- 타입 추론, var
1. 프리미티브 타입 종류와 값의 범위 그리고 기본 값
자바는 statically-typed 즉 정적으로 타입됩니다. 즉, 모든 변수를 사용하기 전에 선언을 해야합니다. primitive type은 기본형(원시형)이라고 하며 실제 데이터 값을 저장하는 타입이다. 실제 값(리터럴)에는 정수, 실수, 문자, 논리 형이 존재한다.
| 타입 | 할당되는 메모리 크기 | 기본 값 | 데이터의 표현 범위 | |
|---|---|---|---|---|
| 논리형 | boolean | 1 byte | false | true, false |
| 정수형 | byte | 1 byte | 0 | -128 ~ 127 |
| short | 2 byte | 0 | -32,768 ~ 32,767 | |
| int(기본형) | 4 byte | 0 | -2,147,483,648 ~ 2,147,483,647 | |
| long | 8 byte | 0L | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 | |
| 실수형 | float | 4 byte | 0.0F | (3.4 X 10-38) ~ (3.4 X 1038) 의 근사값 |
| double(기본형) | 8 byte | 0.0 | (1.7 X 10-308) ~ (1.7 X 10308) 의 근사값 | |
| 문자형 | char | 2 byte(유니코드) | '\u0000' | 0 ~ 65,535 |
[표현범위]
각 서로다른 타입의 변수들은 그에 해당하는 표현 범위를 가지고 있는데 전부 기억하진 못해도 얼추 기억은 해놔야한다. 표현 범위를 넘어서는 값을 저장하려 하면 오버플로우가 발생할 수 있기 때문이다.
특히나 PS를 할 떄 int 타입을 사용해서 오버플로우가 발생해 long 타입으로 변경하는 경우가 빈번히 발생한다.
[unsigned를 제공?]
C, C++과는 다르게 Java는 unsigned를 따로 제공해주지 않는데 Java 8부터 이와 관련된 메소드를 제공해준다. 자바에서의 unsigned
[기본값]
각 타입들은 위의 표와 같이 컴파일 단계에서 기본값으로 초기화 된다.
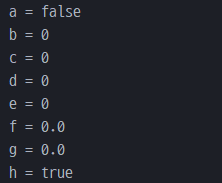
실제로 아래 예제를 코드를 실행하면 결과가 동일하다
public class PrimitiveType {
static boolean a;
static byte b;
static short c;
static int d;
static long e;
static float f;
static double g;
static char h;
public static void main(String[] args) {
int local;
// System.out.println(local);
System.out.println("a = " + a);
System.out.println("b = " + b);
System.out.println("c = " + c);
System.out.println("d = " + d);
System.out.println("e = " + e);
System.out.println("f = " + f);
System.out.println("g = " + g);
System.out.println("h = " + (h == '\u0000'));
}
}
main 메소드 내에 int형 변수 local은 출력하게 되면 오류가 발생하는데 이는 지역변수는 기본값으로 초기화 되지 않고 사용자가 직접 특정 값으로 초기화를 해주어야 하기 때문이다.
즉, 필드만 컴파일러에 의해 기본값으로 초기화 된다.
2. 프리미티브 타입과 레퍼런스 타입
기본형과 참조형의 가장 큰 차이점은 아래와 같다.
- 프리미티브 타입은 메모리에 실제 데이터 값을 저장한다.
- 레퍼런스 타입은 메모리에 실제 데이터가 위치한 주소의 값(참조)를 저장한다.
기본형은 위에서 설명하였으니 레퍼런스 타입을 알아보자 자바에서의 참조 타입의 종류는 다음과 같다.
문자열(String), 배열, 열거(enum), 클래스(class), 인터페이스(interface) 이들은 모두 레퍼런스 타입으로 변수에 실제 값이 직접 저장되는 것이 아닌 실제 값이 위치한 곳의 주소를 가진다(참조) 따라서 레퍼런스 타입으로 불린다.
public class PrimitiveAndReference {
public static void main(String[] args) {
String reference = "hello";
int primitive = 10;
System.out.println("primitive = " + primitive);
System.out.println("reference = " + reference);
}
}위와 같은 코드를 실행하게 되면 실행결과는 아래와 같이 출력된다.
10
hello
변수 reference, primitive 모두 main 메소드의 지역변수이며 각 지역변수들은 Runtime Data Area에 그 공간을 할당받게 된다.
2-1. Runtime Data Area에서의 각 타입의 메모리 할당
프리미티브 타입과 레퍼런스 타입 변수의 Runtime Data Area영역을 살펴보자.
참고: Runtime Data Area 영역은 메소드 영역, 힙 영역, 스택 영역, PC 레지스터, Native 메소드 스택으로 나뉜다.
Runtime Data Area
| Java Stack Area | Java Heap Area |
|---|---|
| (1) reference = ref1 | String Instance : ref1 "hello" |
| (0) primitive = 10 |
기본 자료형인 primitive는 해당 변수의 실제 데이터와 함계 스택영역에 저장된다(자세히는 local variable)참조 자료형은 reference는 해당 변수와 변수의 값으로 값이 위치한 주소가 스택영역에 저장되고, 실제 데이터는 Heap Area에 생성되는것을 알 수 있다.
기본형과 참조형은 변수에 실제 데이터값이 들어가는지 혹은 데이터가 저장된 주소의 값이 저장되는지에 따라서도 구분할 수 있다.
2-2. 참조형과 기본형의 예제
public class PrimitiveAndReference {
public static void main(String[] args) {
StringBuilder reference = new StringBuilder("hello");
int primitive = 10;
System.out.println("before = " + primitive);
System.out.println("before = " + reference);
changeValue(primitive);
changeValue(reference);
System.out.println("After = " + primitive);
System.out.println("After = " + reference);
}
public static void changeValue(int num) {
num = 20;
System.out.println("parameter= " + num);
}
public static void changeValue(StringBuilder str) {
str.append("!!");
System.out.println("parameter= " + str);
}
}
[결과값]
before = 10
before = hello
parameter= 20
parameter= hello!!
After = 10
After = hello!!우리가 프로그래밍을 할 때 매개변수로 레퍼런스 타입변수를 전달하고, 매개변수의 참조값의 데이터를 변경하게 되면 기존 매개변수로 값을 전달한 원래 레퍼런스 타입변수의 참조값의 데이터도 같이 변경된다. 이는 두 변수가 서로 같은 주소를 참조하고 있기 때문에 발생한다.
반면에 프리미티브 타입은 매개변수로 전달하게 되면 변수 뿐만 아니라 값도 완전히 복사되어 다른영역에 생성되므로 매개변수의 값을 변경해도 원래 변수가 가지고 있는 값이 변경되지 않는다.
위의 코드의 결과를 살펴보면 위의 설명을 이해할 수 있을것이다.
3. 리터럴
리터럴이란 값 그 자체를 의미한다. 즉 어떤 변수에 저장되어 있는 값 그 자체를 말한다.(변하지 않는 값)
언뜻생각하면 상수와 비슷한 의미 아닌가 할 수 있지만 차이가 존재하고 뒤에서 그 차이를 알아보자
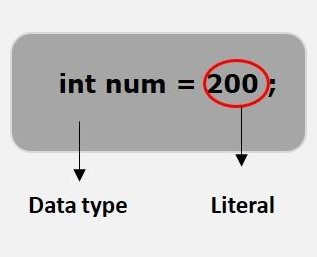
위 사진을 보면 리터럴이 뭔지 좀 더 이해하기 쉬울것이라 생각됩니다!
리터럴은 값 그 자체로 그 종류로는 정수, 실수, 문자, 부울(논리), 문자열이 존재한다.
문자열을 제외하고 프리미티브 타입이며 실제로 예시를 통해 알아보자(특정 블로거 분이 너무나도 잘 작성한 예시가 있어서 가져왔다)
public class Literal {
public static void main(String[] args) {
System.out.println("===== 정수 리터럴 =====");
int int_v1 = 0b10; // 접두문자 0b -> 2진수
int int_v2 = 010; // 접두문자 0 -> 8진수
int int_v3 = 10; // 접두문자 없음 -> 10진수
int int_v4 = 0x10; // 접두문자 0x -> 16진수
long long_v1 = 10L; // 접미문자 l 또는 L -> long 타입 리터럴
System.out.println("2진수 정수 리터럴 : " + int_v1);
System.out.println("8진수 정수 리터럴 : " + int_v2);
System.out.println("10진수 정수 리터럴 : " + int_v3);
System.out.println("16진수 정수 리터럴 : " + int_v4);
System.out.println("long 타입 정수 리터럴 : " + long_v1);
System.out.println();
System.out.println("===== 실수 리터럴 =====");
// 실수 타입 리터럴은 double 타입으로 컴파일 되므로
// float 타입인 경우 명시적으로 f 또는 F 를 명시해줘야 한다.
// double 타입도 d나 D를 명시해줘도 되지만, 안해줘도 상관 없다.
float float_v1 = 1.234F;
double double_v1 = 1.234;
double double_v2 = 1.234d;
double double_v3 = 1234E-3d;
System.out.println("float 타입 실수 리터럴 : " + float_v1);
System.out.println("double 타입 실수 리터럴 1 : " + double_v1);
System.out.println("double 타입 실수 리터럴 2 : " + double_v2);
System.out.println("double 타입 실수 리터럴 3 : " + double_v3);
System.out.println();
System.out.println("===== 문자 리터럴 =====");
char char_v1 = 'C';
char char_v2 = '민';
char char_v3 = '\u1234'; // 백슬러시 u 다음 4자리 16진수 유니코드
System.out.println("문자 리터럴 1 : " + char_v1);
System.out.println("문자 리터럴 2 : " + char_v2);
System.out.println("문자 리터럴 3 : " + char_v3);
System.out.println();
System.out.println("===== 부울(논리) 리터럴 =====");
boolean boolean_v1 = true;
boolean boolean_v2 = 12 > 34;
System.out.println("부울(논리) 리터럴 1 : " + boolean_v1);
System.out.println("부울(논리) 리터럴 2 : " + boolean_v2);
System.out.println();
System.out.println("===== 문자열 리터럴 =====");
String string_v1 = "hello, ws study";
System.out.println("문자열 리터럴 : " + string_v1);
System.out.println();
}
// 출처: https://xxxelppa.tistory.com/195?category=858435
}
결과
===== 정수 리터럴 =====
2진수 정수 리터럴 : 2
8진수 정수 리터럴 : 8
10진수 정수 리터럴 : 10
16진수 정수 리터럴 : 16
long 타입 정수 리터럴 : 10
===== 실수 리터럴 =====
float 타입 실수 리터럴 : 1.234
double 타입 실수 리터럴 1 : 1.234
double 타입 실수 리터럴 2 : 1.234
double 타입 실수 리터럴 3 : 1.234
===== 문자 리터럴 =====
문자 리터럴 1 : C
문자 리터럴 2 : 민
문자 리터럴 3 : ሴ
===== 부울(논리) 리터럴 =====
부울(논리) 리터럴 1 : true
부울(논리) 리터럴 2 : false
===== 문자열 리터럴 =====
문자열 리터럴 : hello, ws study위에서 우항에 있는 값들을 모두 리터럴이라고 말한다. 각 접미사, 접두사를 사용하는 방법을 한번씩 눈여겨 보세요! 후에 꼭 쓸일이 생길것입니다!!
3-1. 상수와 리터럴
리터럴은 언뜻보면 상수와 비슷한 의미를 가진것 같다. 하지만 둘은 서로 바라보는 관점에서의 차이를 가진다.
먼저 리터럴은 변하지 않는 값(데이터)이며 리터럴의 종류로 정수, 실수, 문자, 문자열, 부울이 존재한다.
반면에 상수는 변하지 않는 변수를 말하며 데이터 자체를 가리키는 리터럴과는 차이가 존재한다.
상수는 리터럴의 종류도 될 수 있고 더 나아가 클래스와 같이 객체의 유형도 상수가 될 수 있다.
다만 기본 데이터 타입의 상수는 데이터가 변하면 안되지만 참조변수를 상수로 지정하게 되면, 참조변수에 넣은 인스턴스 안에 데이터는 변화할 수 있다. 그러면 무엇이 변하지 않는가? 참조변수가 가리키는 주소값이 변하지 않는다는 얘기다.
아래 예시를 살펴보면 그 의미를 알 수 있다.
참조변수를 상수로
class Test {
int intField;
public Test() {
this.intField = 20;
}
}
class Main {
final test = new Test();
public static void main(String[] args) throws Exception {
// test = new Test(); // 불가능XXXXXXX
test.intField = 10; // 가능
System.out.println(test.intField);
}
}
출력값 : 10이렇게 상수와 리터럴은 변하지 않는 다는 공통적인 주제를 가지고 있지만 실제 데이터냐 아니면 변수를 의미하냐에 따라 차이를 가진다고 할 수 있다.
4. 변수 선언 및 초기화 하는 방법
자바에서 변수를 사용하려면 선언, 초기화, 사용의 과정이 필요하다.
변수의 선언은 기본형, 참조형 모두 동일하다.
4-1. 변수선언
class Test {...}
class Variable {
static int fieldVar;
static Test fieldTest;
public static void main(String[] args) {
int localVar; // Primitive Type
Test localTest; // Reference Type
}
}위와 같이 변수는 변수타입을 먼저 작성하고, 변수이름을 정해줘야 한다.
변수타입은 변수에 저장 될 값의 타입을 지정한다. 변수는 값을 저장할 수 있는 메모리 공간이므로 변수의 이름을 지정하면 해당 메모리의 공간에 이름을 붙여준다.
즉, 변수를 선언하면 메모리의 빈 공간에 변수타입에 알맞은 크기의 저장공간이 확보되고, 이 저장공간은 변수이름을 통해 사용할 수 있게 된다.
4-2. 변수 초기화
변수선언 이후 변수를 사용할 수 있으나, 반드시 변수를 초기화 하는 작업을 하고 사용해야 한다.
초기화란 변수에 특정 값을 넣는 작업으로 필수적인 작업이다.
초기화는 = 연산자를 이용한다. 실세계에서 등호는 특정 객체 또는 숫자 등이 같다라는 의미이지만, 자바 및 대부분의 프로그래밍 언어에선 등호 기준 좌측의 변수에 우측의 값을 넣겠다는 의미가 된다.
int a // 선언
a = 10; // initialization초기화 작업은 기본형과 참조형이 다른데 아래와 같다.
int a = 10;
int[] arr = new int[3];참조형은 new연산자를 통해 인스턴스(객체)를 생성해주는 역할을 담당한다. 따라서 heap 영역에 실제 new 뒤에 3개의 배열들이 존재하고 스택 영역에 arr이라는 변수와 int[3]의 공간을 가리키는 주소가 arr에 저장된다.
참고로 배열의 초기화는 참조형과 기본형으로 나뉘는데 기본형 배열이라면 기본형의 기본값으로 초기화 되지만, 참조형 배열이라면 기본적으로 null값으로 초기화 된다.
기본형은 우리가 필요한 값만 변수에 초기화 시켜주면 된다.
초기화를 할때는 기본형, 참조형 모두 선언과 분리하여 초기화가 가능하고, 선언과 동시에 초기화도 가능하다.
$ javap -v -p -s Variable.class
Classfile /C:/Java/deep-java/out/production/deep-java/Variable.class
Last modified 2022. 7. 4.; size 443 bytes
MD5 checksum 0f38bdb45118d9db6dd18b3b73eea1e0
Compiled from "Variable.java"
public class Variable
minor version: 0
major version: 55
flags: (0x0021) ACC_PUBLIC, ACC_SUPER
this_class: #2 // Variable
super_class: #3 // java/lang/Object
interfaces: 0, fields: 1, methods: 2, attributes: 1
Constant pool:
#1 = Methodref #3.#22 // java/lang/Object."<init>":()V
#2 = Class #23 // Variable
#3 = Class #24 // java/lang/Object
#4 = Utf8 test
#5 = Utf8 LTest;
#6 = Utf8 <init>
#7 = Utf8 ()V
#8 = Utf8 Code
#9 = Utf8 LineNumberTable
#10 = Utf8 LocalVariableTable
#11 = Utf8 this
#12 = Utf8 LVariable;
#13 = Utf8 main
#14 = Utf8 ([Ljava/lang/String;)V
#15 = Utf8 args
#16 = Utf8 [Ljava/lang/String;
#17 = Utf8 var1
#18 = Utf8 I
#19 = Utf8 var2
#20 = Utf8 SourceFile
#21 = Utf8 Variable.java
#22 = NameAndType #6:#7 // "<init>":()V
#23 = Utf8 Variable
#24 = Utf8 java/lang/Object
{
static Test test;
descriptor: LTest;
flags: (0x0008) ACC_STATIC
public Variable();
descriptor: ()V
flags: (0x0001) ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 1: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this LVariable;
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=3, args_size=1
0: bipush 10
2: istore_1
3: bipush 20
5: istore_2
6: return
LineNumberTable:
line 4: 0
line 6: 3
line 7: 6
LocalVariableTable:
Start Length Slot Name Signature
0 7 0 args [Ljava/lang/String;
3 4 1 var1 I
6 1 2 var2 I
}
SourceFile: "Variable.java"
--------------------------------------------------------------------------------------------------
[원본 코드]
public class Variable {
static Test test;
public static void main(String[] args) {
int var1 = 10;
int var2;
var2 = 20;
}
}
class Test {
}다른 분의 게시물을 봤을때 변수의 선언과 초기화를 한번에 하는것과 나눠서 하는것의 차이가 바이트코드에서 나타나지 않는다길래 한번 직접 확인해봤다. 실제로 크게 다른점은 없는것 같다.
5. 변수의 스코프와 라이프타임
변수의 스코프는 단순히 변수의 사용가능한 범위가 되겠다. 라이프타임은 변수의 생명주기가 언제부터 어디까지인지로 이해하면 되곘다.
5-1. Class Scope(클래스의 필드)
class Test {
// 해당 클래스 중괄호 내부에서만 사용가능
private int data = 10;
public void method() {
data++; // 클래스의 필드로 선언된 변수라면 해당 클래스의 메소드에서 직접 접근이 가능하다.
}
}5-2. Method Scope(메소드 내 지역변수)
class Test {
public void method() {
int count = 10;
// 해당 메소드 중괄호 안에서만 사용 가능하다.
}
public void method2() {
count++;
// 다른 메소드의 변수는 이용할 수 없음, 즉 동일 메서드 내에서만 유효하다.
}
}5-3. Loop Scope(루프내 지역변수)
public class Test {
public void printNums() {
for (int i = 0; i < 10; i++) {
System.out.println(i + 1);
}
System.out.println(i); // 루프내에서만 사용되는 i 변수를 루프 범위 밖에서 사용할 수 없다.
}
}5-4. Bracket Scope(임의의 중괄호 범위 변수)
public class Test {
public void method() {
{
int a = 10;
}
a = 5; // 에러, 임의의 중괄호안에 포함되어있는 변수의 생명주기는 해당 중괄호만 포함된다.
}
}5-5. Scope and Variable Shadowing
클래스 스코프와 메소드 스코프에 동일한 이름의 변수가 존재한다면, 자바에서는 오류를 뱉지 않는다.
그렇다면 어떻게 동작할까?
class ShadowingTestClass {
private String name = "Hoseok";
public void printName() {
System.out.println("Before: " + name);
String name = "Lee";
System.out.println("After: " + name);
}
}
public class VariableScopeAndLifeCycle {
public static void main(String[] args) {
ShadowingTestClass testClass = new ShadowingTestClass();
testClass.printName();
}
}위와 같은 코드에서 Before: 로 시작하는 name변수는 해당 클래스의 필드의 값인 Hoseok을 가리키고
local variable이며 필드와 동일한 name을 선언한 이후 name을 출력하면 local의 값이 출력된다.
이것을 variable shadowing이라 부른다. 즉 가까이에 있는 스코프의 변수가 우선순위를 가진다고 생각하면 된다.
위와 같이 동일한 변수 이름을 사용해야 하는 상황이라면 명시적으로 this 키워드를 붙여서 사용하는것이 바람직하다.
5-6. 변수의 라이프사이클
변수는 크게 클래스 변수, 인스턴스 변수, 매개 변수, 지역 변수가 존재한다.
class Test {
static int a = 10;
int b = 20;
public void method(int c) {
int d = c + 30;
System.out.println(d);
}
}
a: 클래스 변수, b: 인스턴스 변수, c: 매개 변수, d: 지역 변수먼저 클래스 변수는 클래스 레벨에서 static 키워드가 붙은 필드를 말하는데
클래스가 메모리에 올라갈때 Runtime Data Area의 Method Area에 올라가게 된다.
따라서 이 변수는 인스턴스의 것이 아니라 클래스 레벨에서 관리 되므로 클래스가 메모리에 올라갈때 생성되고(객체 생성 전)
해당 프로그램이 종료될때까지 생명을 유지하다 같이 소멸한다.
참고로 참조형의 클래스 변수는 변수의 이름과 실제 주소를 Mathod Area에 저장하고, 실제 값은 heap 영역에 저장한다.
인스턴스 변수는 특정 클래스의 필드를 말하며 클래스의 인스턴스와 생명주기를 동일시 한다. 인스턴스는 heap 영역에 저장되며 만약 해당 인스턴스를 참조하는 변수가 존재하지 않는다면 GC에 의해 회수되고 생명이 끝나게 된다.
매개 변수 및 지역 변수는 포함된 중괄호의 시작과 끝까지의 생명주기를 가지는데 약간의 차이점이 존재한다.
매개변수는 위의 method(int)의 메소드가 호출되면서 생명주기가 시작되고, 지역변수는 해당 메소드의 중괄호가 시작될 떄 생명주기가 시작된다. 이후 중괄호가 끝나는 부분에서 매개변수, 지역변수 모두 생명주기가 끝나게 된다.
6. 타입 변환, 캐스팅 그리고 타입 프로모션
특정 데이터 타입에서 다른 데이터 타입으로 변경하는 것을 타입 변환이라고 한다.
일반적으로 타입 변환은 묵시적 변환(타입 프로모션), 명시적 변환(캐스팅)이 존재한다.
어느 블로거 분이 명확하게 정의해 주었다.
1. 자신의 표현 범위를 모두 포함한 데이터 타입으로의 변환. (타입 프로모션)
2. 자신의 표현 범위를 모두 포함하지 못한 데이터 타입으로의 변환. (타입 캐스팅)
출처: https://xxxelppa.tistory.com/195?category=858435 [한칸짜리책상서랍:티스토리]
6-1. Type Promotion
타입 프로모션(묵시적인 형변환)은 데이터의 표현 범위 기준 int, long을 예시로 들 수 있다.
int보다 long이 데이터를 표현할 수 있는 범위가 더 크므로 int 타입은 long 타입으로 묵시적인 형변환이 가능하다.
int a = 10;
long b = a; // 가능Newmeric Promotions
또한 아래와 같은 경우엔 호환성을 위해 지원하는 규칙(Newmeric Promotion)이 적용된다.
byte o1 = 1;
byte o2 = 2;
byte result = (byte) (o1 + o2);위의 코드에서 o1 + o2는 byte타입 끼리의 연산이지만 결과 값을 byte로 캐스팅 해야한다. 왜 그럴까?
이항 연산을 실행할 때 두 피연산자는 크기 면에서 호환되어야 한다. 따라서 다음과 같은 규칙이 적용된다.
1. 피연산자중 하나가 double이면 다른 하나도 double로 프로모션됨
2. double이 없고, 피연산자중 하나가 float이면 다른 하나는 float으로 승격된다.
3. double, float이 둘 다 아니고, 피연산자 하나가 long이면 다른 하나도 long으로 승격된다.
4. 1,2,3 모두 아니라면 int로 간주된다.따라서 위의 코드에서 o1 + o2는 int로 간주되므로 byte 타입으로 캐스팅 해주어야 한다.
6-2. Casting
캐스팅(명시적인 형변환)은 float과 long으로 예시를 들 수 있다.
float a = 10.8f;
long b = (long) a;
System.out.println(b);캐스팅은 명시적으로 형변환을 하는것이고, 이것은 원본 데이터가 변환될 데이터 타입으로 모두 담지 못하는 경우에 캐스팅을 해주어야 한다. 즉 데이터의 손실이 발생할 수 있고, 작성자가 그것을 감수하겠다와 같은 약속이라 볼 수 있다.
위의 코드의 결과는 0.8이 잘려나간 10이된다. long타입은 정수만 취급하므로 소수점 아래의 값은 담을 수 없기 때문이다.
이러한 캐스팅은 부모, 자식간의 클래스 관계에서도 가능하다.
class Parent {
public void parentMethod() {...}
}
class Child extends Parents {
public void childMethod() {...}
}
class Test {
public void main(String[] args) {
Parent child = new Child();
/*
UpCasting(서브타입의 인스턴스를 수퍼타입의 변수로 접근하는 것)
상위 클래스의 공통 메서드, 필드는 하위 클래스에서 사용가능하다.
하지만 하위 클래스의 메소드 및 필드는 접근할 수 없다.
*/
child.childMethod(); // 컴파일 오류
/*
강제형변환이 일어나며, DownCasting 타입에서 선언된 모든 필드와 메서드에 접근이 가능합니다.
*/
realChild = (Child) child;
child.childMethod(); // Down Casting(서브타입 인스턴스를 참조하는 수퍼타입 변수를 재참조)
// 즉 부모클래스가 자식클래스로 캐스팅한 것을 말한다.
}
}7. 1차 및 2차 배열 선언하기
배열은 같은 타입의 여러 변수를 하나의 묶음으로 다루는 것을 배열이라 한다.
예를들어 한 반의 30명의 학생의 수학 점수를 담고 싶다면, 배열을 사용하지 않으면 30개의 서로 다른 변수를 선언하고 초기화 해주어야 한다.
7-1. 배열의 선언 및 생성
하지만 배열을 사용하게 되면 하나의 변수명과 인덱스를 이용해 30명의 수학 점수를 일괄적으로 관리할 수 있고, 가독성마저 좋아진다. 그렇다면 자바에서는 배열을 어떻게 선언할까?
public class Test {
public static void main(String[] args) {
// [1차원 배열]
// 선언과 생성을 동시에
int[] mathScores = new int[30];
// 선언과 생성을 분리
int[] arr1;
arr = new int[10];
// 선언과 생성 및 초기화 동시에_1
int[] arr2 = new int[]{1, 2, 3, 4, 5, 6};
// 선언과 생성 및 초기화 동시에_2
int[] arr3 = {1, 2, 3, 4, 5, 6};
// 선언과 생성, 초기화를 동시에 하는경우 선언과 생성을 분리할 수 없음
// int[] arr4;
// arr = {1, 2, 3, 4, 5}; --> 컴파일 오류
// [2차원 배열]
// 선언과 생성만 하는 경우 분리하여 작성할 수 있다.
int[][] arr4 = new int[10][10];
int[][] arr5;
arr5 = new int[10][10];
// 초기화를 동시에 선언과 분리할 수 없음
int[][] arr6 = new int[][]{{1, 2, 3}, {4, 5, 6}};
int[][] arr7 = {{1, 1, 1}, {2, 2, 2}}
}
}위의 방식은 1차원 배열 및 2차원 배열을 선언하는 대표적인 방식들이다. 선언 및 생성과 동시에 초기화를 하는 경우는 선언과 생성을 분리할 수 없다. 위에서는 주로 첫 번째로 작성한 방식들이 간결하여 많이 이용하는듯 합니다.
배열의 초기값이 정해지지 않았다면, 보통 for문을 이용해 사용자에게 값을 받거나 하는 방식으로 일괄적으로 초기화를 하는 경우가 많습니다. 따라서 각 변수를 일일이 선언하는 방식보다 훨씬 간결함을 알 수 있습니다.
7-2. 배열의 메모리 구조
배열 또한 참조형이므로 변수와 해당 배열의 주소는 Runtime Data Area의 스택 영역에, 실제 배열의 공간들은 Heap 영역에 생성된다.
1차원 배열 Runtime Data Area
| Java Stack Area | Java Heap Area |
|---|---|
| (0) arr = ref1 | ref1: [4byte][4byte][4byte][4byte][4byte] |
위와 같이 변수의 명과 실제 위치의 주소는 stack area에 존재하고 실제 배열들은 힙 영역에 생성되어있고 스택영역에서 해당 영역을 참조하고 있다.
int[][] arr = new int[][]{{5, 6, 7}, {8, 9, 0}};
해당 코드를 선언하면 메모리에 어떤식으로 저장될까?2차원 배열 Runtime Data Area
| Java Stack Area | Java Heap Area |
|---|---|
| (0) arr = ref1 | ref1: [ref2][ref3] |
| ref2: [5][6][7] | |
| ref3: [8][9][0] |
2차원 배열은 참조를 한 단계 더 들어가는 모습을 보인다. 즉 각각의 행이 해당 행의 열의 시작주소를 참조하고 있다. 따라서 위의 참조 과정이 깊어질수록 더 고차원의 배열을 생성할 수 있다.
배열들은 접근할때 변수명[인덱스]와 같은 형식으로 접근한다
int[] arr = new int[10]; // 기본형 타입의 배열은 해당 기본형의 기본값으로 초기화 됨
for (int i = 0; i < 10; i++) {
System.out.print(arr[i] + " ");
}
결과: 0 0 0 0 0 0 0 0 0 0거의 대부분의 프로그래밍 언어가 그렇듯 인덱스는 0 ~ n - 1(n == 배열의 크기)로 접근한다.
배열은 초기 선언 이후 새로 객체를 생성하여 대체하는 방법 말고는 크기를 늘릴 수 없으므로 인덱스로 접근할 때 주의해야 한다.
8. 타입 추론, var
우선 타입 추론은 자바 컴파일러가 각 메소드의 호출과 이에 대응하는 선언을 보고 호출을 적용할 유형 인수를 결정하는 기능이며, 가능한 경우에 할당되는 타입, 리턴 타입까지 결정한다.
타입을 추론을 위한 추론 알고리즘은 모든 인자와 가장 어울리는 선에서(공통 부모) 가장 구체적인 타입을 찾게 된다.
8-1. Type Inference
하나의 예시를 보자
static <T> T pick(T a1, T a2) {
return a2;
}
public static void main(String[] args) {
Serializable d = pick("d", new ArrayList<String>());
}pick의 인자로 String, ArrayList타입을 넘겨줬다. 따라서 이런 경우에 추론 알고리즘은 모든 인자와 가장 어울리는 공통 부모를 찾게 되는데 두 클래스 모두 Serializable을 구현하고 있으므로 Serializable이 선택된다.
8-2. Generic Method and Type Inference
위와같은 타입 추론 덕분에 제네릭 메소드를 사용할 때 보통의 메소드와 마찬가지로 특정 타입을 명시하지 않은 채로 호출할 수 있다.
public class BoxDemo {
public static <U> void addBox(U u, java.util.List<Box<U>> boxes) {
Box<U> box = new Box<>();
box.set(u);
boxes.add(box);
}
public static void main(String[] args) {
java.util.ArrayList<Box<Integer>> listOfIntegerBoxes = new java.util.ArrayList<>();
// 1.
BoxDemo.<Integer>addBox(Integer.valueOf(10), listOfIntegerBoxes);
// 2.
BoxDemo.addBox(Integer.valueOf(30), listOfIntegerBoxes);
}
}
출처: 오라클 공식문서1번은 Type Witness를 직접 명시해 주었다. 하지만, 자바 컴파일러가 메소드의 인자로부터 자동으로 type 매개변수가 Integer임을 추론했으므로 type witness를 2번처럼 생략할 수 있다.
8-3. Generic Classes의 인스턴스화 및 타입 추론
제목은 어려워 보이지만 우리가 흔히 많이 사용하는 방식이다.
즉 컴파일러가 컨텍스트에서 해당 형식을 유추할 수 있다면 제네릭 클래스의 생성자를 호출 시 필요한 Type을 굳이 작성하지 않아도 된다.
HashMap<String, String> map = new HashMap<>(); // <>를 비공식적으로 다이아몬드라고 부름하지만 <> 자체를 생략하게 되면 컴파일 오류가 발생하니 주의해야 한다.
8-4. 타입 추론과 Generic 생성자
클래스가 Generic, non-generic인 여부와 상관없이 생성자는 generic 일 수 있다. (자신만의 Type Arguments를 가질 수 있음)
public class TypeInference {
static class MyClass<X>{
<T> MyClass(T t) {
System.out.println("hello" + t);
}
}
public static void main(String[] args) {
MyClass<String> myClass = new MyClass<>(32);
}
}
코드를 보면 MyClass의 타입은 String이지만 생성자의 type arguments는 Integer타입이다.
8-5. Target Types
static <T> List<T> emptyList() {
return new ArrayList<>();
}
public static void main(String[] args) {
List<String> list = Collections.emptyList();
// 물론 Collections.emptyList<String>(); 과 같이 Type Witness 명시도 가능
}위의 코드에서 변수는 List<String> 객체를 기대한다. 이런 데이터 타입을 Target Type이라 하는데, emptyList 메소드는 List<T> 타입을 리턴하므로 Type arguments가 String 일 것으로 추론한다.
Java 8은 아래와 같은 기능도 제공한다.
void processingStringList(List<String> stringList) {...}
// main 에서
// java 8
processingStringList(Collections.emptyList());
// 하지만 위의 코드는 Java 7 버젼은 오류를 뱉음
processingStringList(Collections.<String>emptyList()); // 이렇게 적어주어야 한다.8-6. var!
Java 10에 새로 도입된 문법으로 변수를 선언할때 타입을 명시적으로 선언하지 않고 var를 이용하는 방식을 말한다. 이는 컴파일 타임에 추론하므로 Runtime에 추가적인 연산이 없어 성능에 영향을 주지 않는다.
아래와 같이 다양하게 사용이 가능합니다.
var str = "hello!!";
System.out.println(str); // hello!! 출력
var list = new ArrayList(); // Object 타입으로 리스트 생성
var list2 = new ArrayList<String>();
int[] arr = new int[]{1, 2, 3}; // 반복문 내에서 사용가능
for (var num : arr) {
System.out.println(num);
}하지만 var는 여러가지 제약사항이 존재한다.
- 지역 변수에서만 사용가능
- 초기화 필요(선언, 초기화 분리작성 불가능)
- null 초기화 불가능
- 배열에 사용 불가능
- Lambda에 사용 불가능
개인적으로는 너무 생략하는것은 오히려 가독성에 좋지 않다는 생각이 듭니다.
타입 추론까지가 딱 적당하다는 생각입니다 ㅎㅎ
References
