Synchronized Collection과 Concurrent Collection의 차이에 대해 정리해보려한다.
Synchronized Collection
Synchronized Collection에는 대표적으로 다음과 같은 클래스가 있다.
- Vector
- HashTable
- Collections.synchronized~
해당 클래스들은 모두 메서드에 synchronized를 사용해 한번에 하나의 스레드만 사용할 수 있도록 하면서 동시성을 보장해주고 있다.
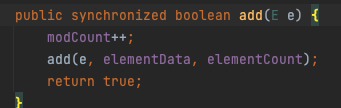
대표적으로 Vector를 살펴보면, 거의 대부분의 메서드에 synchonized가 붙어있는 걸 확인할 수 있다.
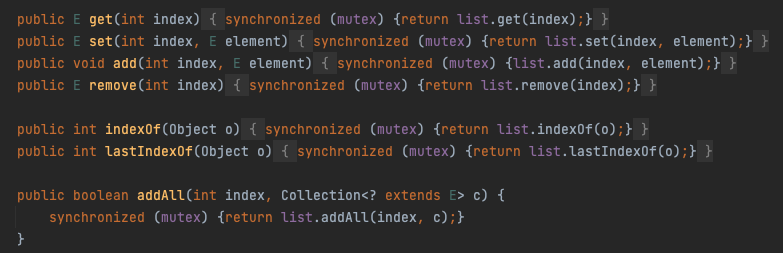
다음으로 Collections.synchronizedList를 살펴보면 마찬가지로 모든 메서드에 synchronized가 붙어있고, 추가된 점으로는 mutex를 사용한 것을 볼 수 있다.
이는 동시성을 제어하기 위한 공통적인 객체로 하나의 스레드가 synchronized 블록안에 들어가면 다른 메서드의 synchronized 부분이 모두 lock이 걸리게 된다.
이렇게 다른 스레드의 동작을 blocking 해버리기 때문에, 성능 상 상대적으로 ConcurrentCollection에 비해 열세일 수 밖에 없다.
Concurrent Collection
java.util.concurrent 패키지 아래에서 아래 클래스 외에도 많은 Concurrent Collection을 제공한다.
- ConcurrentHashMap
- CopyOnWriteArrayList
이 중 ConcurrentHashMap의 putVal 메서드를 살펴보자.
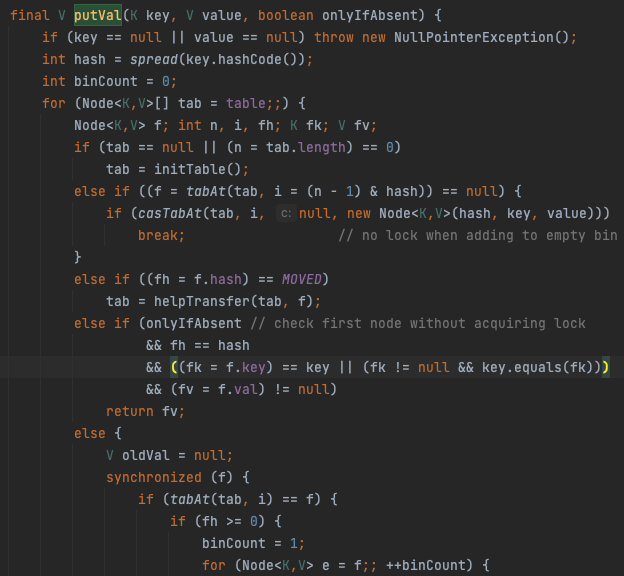
(코드가 길어 이하는 생략)
해시 버킷이 비어있는 경우와 그렇지 않은 경우로 나누어서 설명하려 한다.
해시 버킷이 비어있는 경우
- 새 노드를 삽입하기 위해, 해당 버킷 값을 가져와 비어있는지 확인
- 노드에 담겨 있는 volatile 변수에 접근하여 기존 값과 비교한 후 같으면 새 노드를 저장한다. 그렇지 않으면 다시 돌아간다(CAS 알고리즘)
volatile과 CAS 알고리즘에 대해 간단히 정의하면 아래와 같다.
vaolatile : 변수를 CPU cache가 아닌 Main Memory에 저장하게 해주는 예약어. 변수의 값을 read/write 시 Main Memory에서 처리한다.
이렇게 하면, Multi Thread 환경에서 해당 값을 read해올때 가장 최신 값을 보장해줄 수 있으나, Multi Thread가 동시에 Write하는 경우에는 최신 값을 보장할 수 없어 synchronized를 사용해야한다.
CAS 알고리즘 : 현재 스레드가 가지고 있는 기존 값과 메모리가 가지고 있는 값을 비교해 같은 경우 변경할 값을 메모리에 반영하고 true를 반환, 다른 경우에는 변경 값이 반영되지 않고 false 반환 후 재시도 하는 알고리즘
해시 버킷에 노드가 존재하는 경우
- 노드가 존재하는 경우, synchronized를 사용하여 하나의 Thread만 접근하도록 한다. 이때, 비어있지 않은 해시 버킷에 lock을 걸기 때문에, 동일한 버킷에 접근하는 다른 스레드들은 Blocking 된다.
- 새 노드로 교체하고, 해시 충돌이 일어난 경우 처리한다.
결론 : synchronized Collection들은 대부분 모든 동작에 대해 synchronized가 되어있어, 성능 상 열세지만, Concurrent Collection들은 Collection 별로 성능 상 좋지 못한 최대한 적게 synchronized를 사용하고 있다. Concurrent Collection을 적극적으로 사용하자!
2차 추가사항
Concurrent Collection이 내부적으로 어떻게 syncronized를 적게 사용하는지에 대해 내용 설명이 부족한 것 같아 추가.
위에서 다룬 ConcurrentHashMap을 기준으로 설명하자면,
우선 해당 컬렉션(다른 Concurrent들도 포함)은 제한적으로 여러 스레드가 동시에 접근 가능하다.
1. JAVA 8 이전
- ReentrantLock을 상속받는 Segment를 이용해 영역을 구분하고 영역 별 잠금
- JAVA 8 이후
- 각 테이블 버킷을 독립적으로 잠금
- 빈 버킷에 노드 삽입할 경우 lock 대신 CAS 알고리즘
- 그 외 변경은 각 버킷 첫 노드를 기준으로 부분 잠금(syncronized block) 획득
- Race Condition 최소화
