
카프카의 내부 동작 원리와 구현
카프카 리플리케이션
고용성 분산 스트리밍 플랫폼인 카프카는 무수히 많은 데이터 파이프라인의 정중앙에 위치하는 메인 허브 역할을 한다
- 카프카는 초기 설계 단계에서부터 일시적인 하드웨어 이슈 등으로 브로커 한두 대에서 장애가 발생하더라도
중앙 데이터 허브로서 안정적인 서비스가 운영될 수 있도록 구상되었다 - 안정성을 확보하기 위해 카프카 내부에서는
리플리케이션이라는 동작을 한다
리플리케이션 동작 개요
카프카는 브로커의 장애에도 연속적으로 안정적인 서비스를 제공함으로써 데이터 유실을 방지하며 유연성을 제공한다
- 카프카의 리플리케이션 동작을 위해 토픽 생성시 필숫값으로 replication factor라는 옵션을 설정해야 한다.
토픽 생성 (replication-factor 3)
kafka-topics --bootstrap-server kafka1:9091 --create --topic chaptor4-topic01 --partitions 1 --replication-factor 3
토픽 상세보기 (describe)
kafka-topics --bootstrap-server kafka1:9091 --topic chaptor4-topic01 --describe
- 토픽의 파티션 수인 1과 리플리케이션 수인 3이 표시되어있다.
- 파티션 0의 리더는 브로커 2 (Leader)
- 리플리케이션들은 브로커 2,1,3에 있음을 나타낸다 (Replicas)
- 현재 동기화 되고 있는 리플리케이션들은 브로커 2,1,3이다 (Isr)
- 중요한 사실은 리플리케이션되는 것은 토픽이 아니라 토픽을 구성하는 각각의 파티션들이라는 점이다

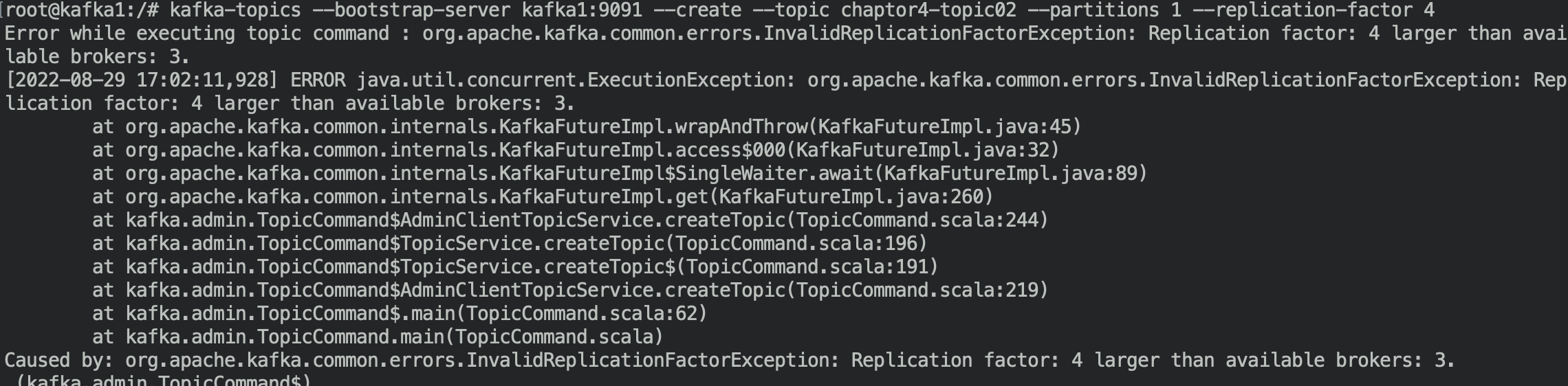
- 만약 리플리케이션의 수를 브로커의 수보다 많게 한다면?
현재 브로커의수 3, 리플리케이션 수 4개로 토픽생성
-
프로듀서를 이용해 chaptor4-topic01 토픽에 메세지 전송
Kafka-console-producer --bootstrap-server kafka2:9092 --topic chaptor4-topic01- Leader가 2로 (kafka2) 잡혀있으므로 kafka2에서 메세지 전송
- kafka1에서 전송시 WARN발생 (Leader가 아니므로)

-
세그먼트 파일 내용확인
root@kafka2:/# kafka-console-producer --bootstrap-server kafka2:9092 --topic chaptor4-topic01
kafka2> test message
kafka2> ^Croot@kafka2:kafka-dump-log --print-data-log --files /var/lib/kafka/data/chaptor4-topic01-0/00000000000000000000.log
Dumping /var/lib/kafka/data/chaptor4-topic01-0/00000000000000000000.log
Starting offset: 0 (1)
baseOffset: 0 lastOffset: 0 count: 1 (2) baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1661793994504 size: 80 magic: 2 compresscodec: NONE crc: 313329200 isvalid: true
| offset: 0 CreateTime: 1661793994504 keysize: -1 valuesize: 12 sequence: -1 headerKeys: [] payload: test message (3)
(1) : 시작오프셋
(2) : 메세지 카운트
(3) : 프로듀서를 통해 보낸 메세지 정보현재 접속한 서버는 kafka2지만, 카프카 클러스터를 이루는 다른 브로커(kafka1, kafka3)에서도 dump를 확인해보면 동일한 메세지를 갖고 있음을 확인할 수 있다
- 즉 콘솔 프로듀서로 보낸 메세지 하나를 총 3대의 브로커들이 모두 갖고있는 형태이다
- 이렇게 카프카는 리플리케이션 팩터라는 옵션을 이용해 관리자가 지정한 수만큼의 리플리케이션을 가질 수 있기 때문에 브로커의 장애가 발생해도 메세지 손실없이 안정적으로 메세지를 주고받을 수 있다
리더와 팔로워
- 토픽 상세보기 명령어를 통해 파티션의 Leader를 확인할 수 있다.
- 리더만의 역할이 있기때문에, 리더를 특별히 강조해 표시한다
- 카프카는 내부적으로 모두 동일한 리플리케이션들을 리더와 팔로워로 구분하고, 각자의 역할을 분담시킨다
- 리더는 리플리케이션 중 하나가 선정되며, 읽기와 쓰기는 그 리더를 통해서만 가능하다
- 프로듀서는 모든 리플리케이션에 메세지를 보내는 것이 아니라 리더에게만 메세지를 전송한다
- 컨슈머도 오직 리더로부터 메세지를 가져온다
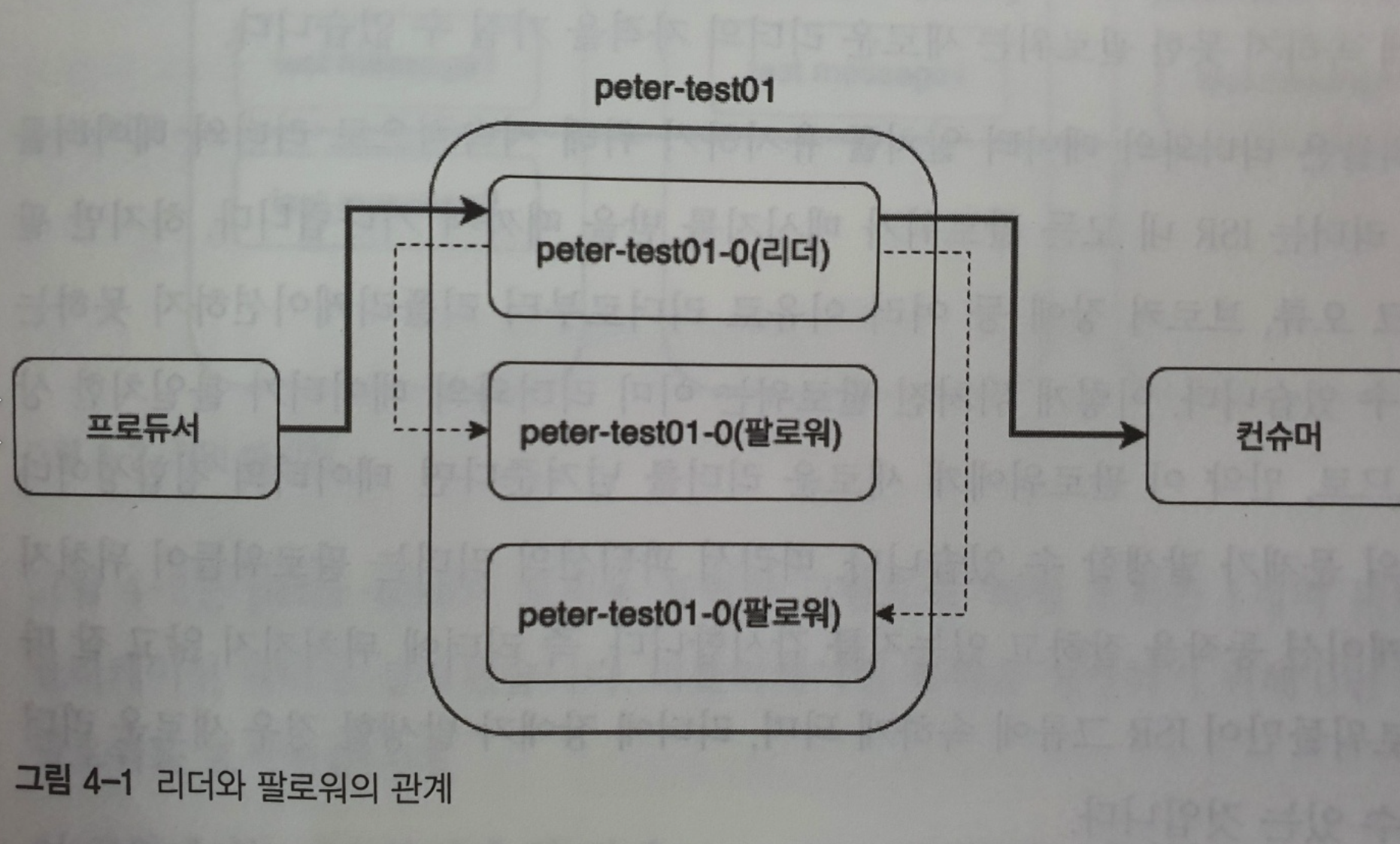
위 그림은 프로듀서와 컨슈머, 리더의 관계를 그림으로 표현한 것입니다
- 팔로워도 그저 대기만하는 것이 아니라 리더에 문제가 발생하거나 이슈가 있을 경우를 대비해 언제든지 새로운 리더가 될 준비를 해야한다
- 따라서 컨슈머가 토픽의 메세지를 꺼내 가는 것과 비슷한 동작으로 지속적으로 파티션의 리더가 새로운 메세지를 받았는지 확인하고, 새로운 메세지가 있다면 해당 메세지를 리더로부터 복제한다
복제 유지와 커밋
- 리더와 팔로워는
ISR(InSyncReplica)이라는 논리적 그룹으로 묶여있다 - 이렇게
리더와 팔로워를 별도의 그룹으로 나누는 이유는 해당 그룹 안에 속한 팔로웓르만이 새로운 리더의 자격을 가질 수 있기 때문이다 ISR내의 팔로워들은 리더와의 데이터 일치를 유지하기 위해 지속적으로 리더의 데이터를 따라가게 된다리더는 ISR 내 모든 팔로워가 메세지를 받을 때까지 기다린다- 팔로워가 네트워크 오류, 브로커 장애 등 여러 이유로
리더로부터 리플리케이션하지 못하는 경우도 발생할 수 있다- 뒤처진 팔로워는 리더와의
데이터가 불일치한 상태에 놓이게 된다 - 만약 이 팔로워에게 새로운 리더를 넘겨준다면
데이터 정합성이나 메세지 손실 등의 문제가 발생할 수 있다 - 따라서
리더는 팔로워들이 뒤쳐지지 않고 리플리케이션 동작을 잘하고 있는지 감시한다 - 리더에 뒤처지지 않고 잘따라잡고 있는 팔로워들만이 ISR 그룹에 속하게 되며, 리더에 장애가 발생할 경우 새로운 리더의 자격을 얻을 수 있다
- 뒤처진 팔로워는 리더와의
그럼 리더와 팔로워 중 리플리케이션 동작을 잘하고 있는지 여부 등은 누가 판단하고, 어떤기 준으로 판단할까?
리더는 읽고 쓰는 동작은 물론, 팔로워가 리플리케이션 동작을 잘 수행하고 있는지도 판단한다팔로워가 특정 주기의 시간만큼 복제 요청을 하지 않는 다면,리더는 해당 팔로워가 리플리케이션 동작에 문제가 발생했다고 판단해 ISR 그룹에서 추방한다- ISR에 속한 팔로워만 리더 자격을 가질 수 있으므로,
추방된 팔로우는 새로운 리더가 될 자격을 박탈당하게 된다 - ISR 내에서 모든 팔로워의 복제가 완료되면,
리더는 내부적으로 커밋되었다는 표시를 한다 - 마지막 커밋 오프셋 위치는
하이워터마크라고 부른다 - 즉,
커밋되었다는 것은 리플리케이션 팩터 수의 모든 리플리케이션이 전부 메세지를 저장했음을 의미한다 - 커밋된 메세지만 컨슈머가 읽어갈 수 있다
- 카프카는 일관성을 유지하기 위해 커밋되지 않은 메세지를
컨슈머가 읽을 수 없게 한다
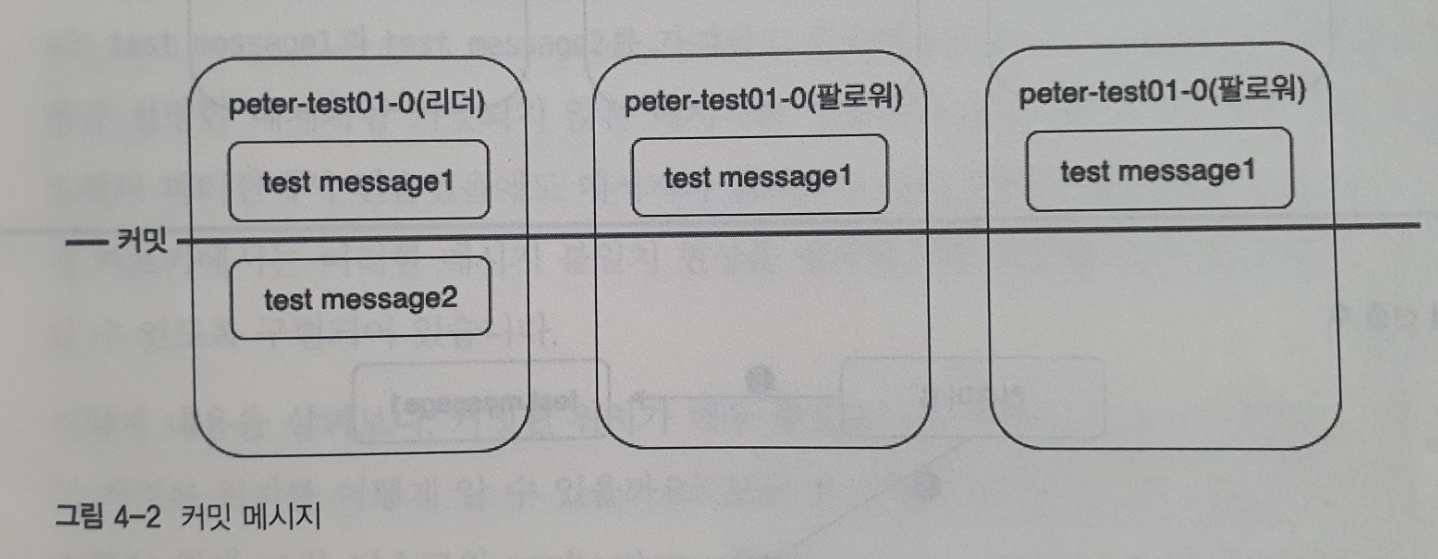
커밋되기전 메세지를 컨슈머가 읽을 수 있다고 가정한 흐름
1. 컨슈머 A는 peter-test01 토픽을 컨슘
2. 컨슈머 A는 peter-test01 토픽의 파티션 리더로부터 메세지를 읽어간다, 읽어간 메세지는 test message1, 2입니다 (리플리케이션 동작전)
3. peter-test01 토픽의 파티션 리더가 있는 브로커에 문제가 발생해 팔로워 중 하나가 새로운 리더가 됩니다
4. 프로듀서가 보낸 test message2 메세지는 아직 팔로워들에게 리플리케이션이 되지 않은 상태에서 새로운 리더로 변경했으므로, 새로운 리더는 test message1 메세지만 갖고있다
5. 새로운 컨슈머 B가 peter-test01 토픽을 컨슘
6. 새로운 리더로부터 메세지를 읽어가고, 읽어간 메세지는 오직 test message1
- test message2의 메세지 유실이 발생한다
커밋된 위치는 중요하다
커밋된 위치를 어떻게 알 수 있을까?
- 모든
브로커는 재시작할 때, 커밋된 메세지를 유지하기 위해 로컬 디스크의replication-offset-checkpoint라는 파일에 마지막 커밋 오프셋 위치를 저장한다 replication-offset-checkpoint파일은 브로커 설정 파일에서 설정한 로그 디렉토리 경로에 있다- 브로커 설정 파일의 로그 디렉토리는 /data/kafka-logs 로 설정되어 있으므로, 해당 디렉토리 하위에 위치한다
- 도커로 실행시 경로는 /var/lib/kafka/data/
- cat 으로 내용 확인
- cat /var/lib/kafka/data/replication-offset-checkpoint
- 앞의 0은
파티션, 뒤의 1은마지막 커밋 오프셋

- 커밋된 오프셋 번호가 증가하는지 확인하기 위해 test message2를 전송한 뒤, cat으로 확인
-chaptor4-topic01 0 2

- 리플리케이션된
다른 브로커들에서도 동일한 명령어로 확인시 모두 동일한 오프셋 번호를 가지고 있음을 확인할 수 있다
만약 특정 토픽 또는 파티션에 복제가 되지 않거나 문제가 있다고 판단되는 경우, replication-offset-checkpoint 라는 파일의 내용을 확인하고, 다른 브로커들과 비교해 살펴보면 문제 파악이 가능하다
리더와 팔로워의 단계별 리플리케이션 동작
- 카프카의 수많은 메세지의 읽기, 쓰기를 처리하는 리더는 매우 바쁘게 동작을 한다
- 바쁜 리더가 리플리케이션 동작을 위해 팔로워들과 많은 통신을 주고 받거나, 리플리케이션 동작에 많은 관여를 한다면 결과적으로 리더의 성능은 떨어지고 카프카의 장점인 빠른 성능을 내기 어려울 것이다
- 카프카는 리더와 팔로워 간의 리플리케이션 동작을 처리할 때 서로의 통신을 최소화 할 수 있도록 설계함으로써 리더의 부하를 줄였다
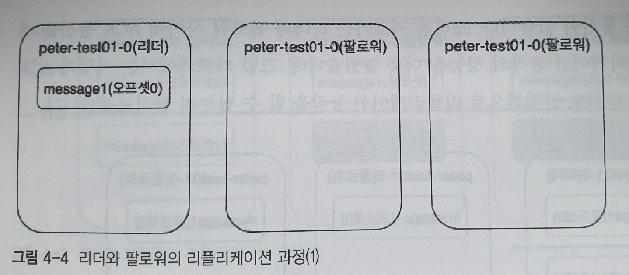
- peter-test01 토픽이 1개의 파티션과 3개의 리플리케이션으로 구성되었다
- 현재 리더만이 0번 오프셋에 message1 이라는 메세지를 갖고 있는 상태
- 프로듀서가 peter-test01 토픽으로 message1 이라는 메세지를 전송햇으며, 리더만 메세지를 저장하고 나머지 팔로워들은 아직 리더에게 저장된 메세지를 리플리케이션 하기 전 상태
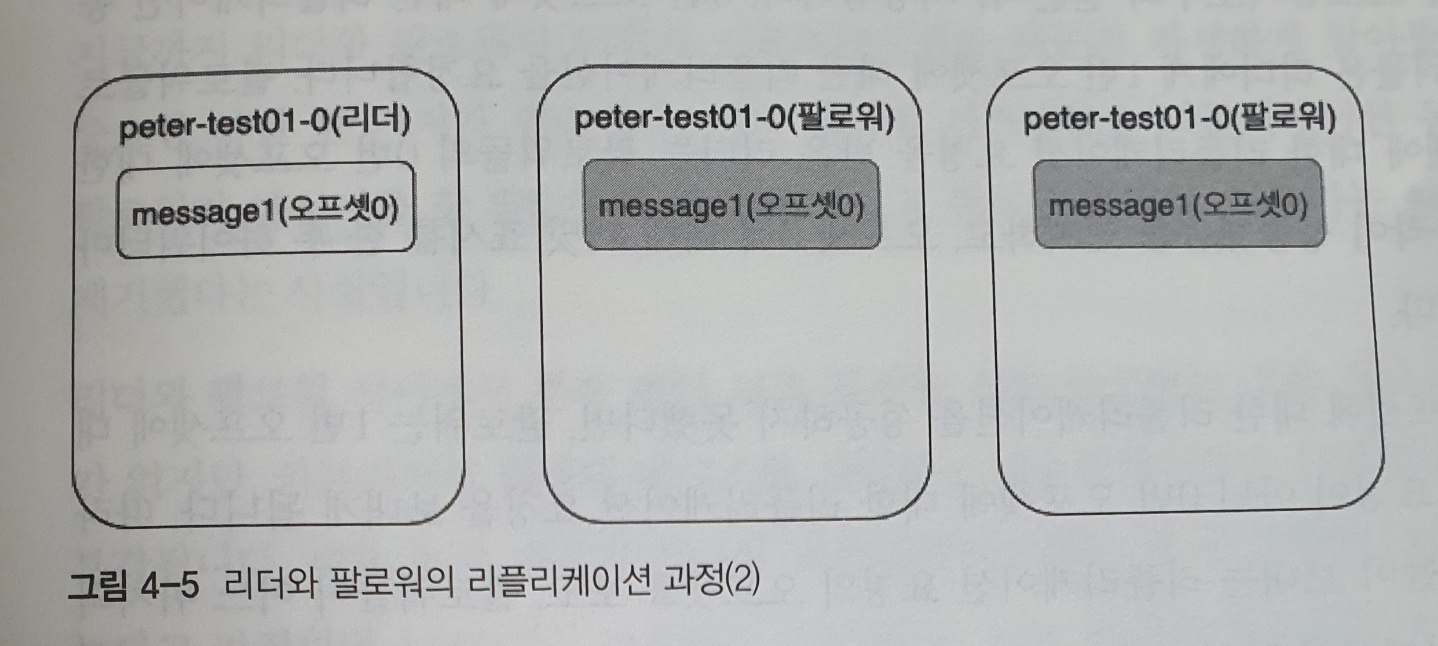
팔로워들이 리더에게 0번 오프셋 메세지 가져오기를 요청 보낸 후 message1 을 리플리케이션 하는 과정리더는 모든 팔로워들이 0번 오프셋 메세지를 리플리케이션을 위한 요청을 보냈다는 사실을 알고 있다- 하지만
리더는 팔로워들이 0번 오프셋에 대한 리플리케이션 동작을 성공했는지 여부를 알지 못한다 - RabbitMQ 의 트랜잭션 모드에서는 모든 미러가 메세지를 받았느느지에 대한 ACK를 리더에게 리턴하므로 리더는 미러들이 메세지를 받았는지 알 수가 있다
카프카의 경우 리더와 팔로워간의 ACK 통신이 없다- ACK 통신을 제거함으로써 리플리케이션 동작의 성능을 더욱 높였다
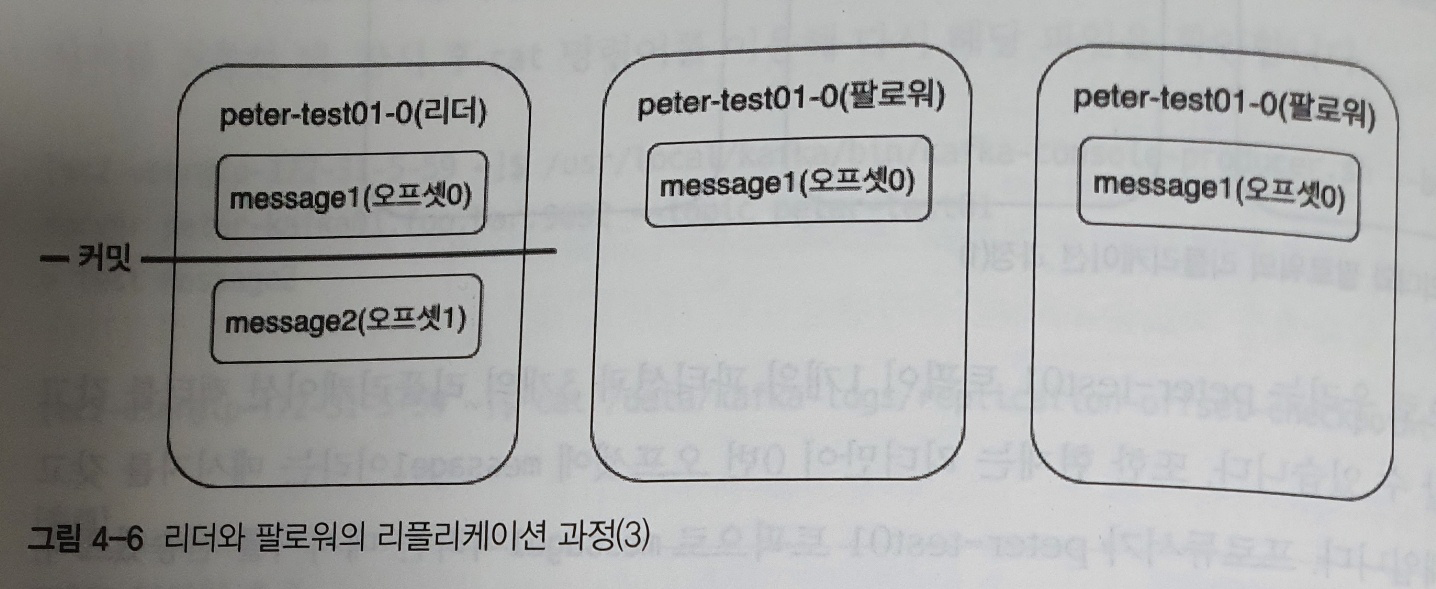
리더는 1번 오프셋 위치에 두 번째 새로운 메세지인 message2를 프로듀서로부터 받은 뒤 저장- 0번 오프셋에 대한 리플리케이션을 마친
팔로워들은 리더에게 1번 오프셋에 대한 리플리케이션 요청 - 1번 오프셋에 대한 리플리케이션 요청을 받은
리더는 팔로워들의 0번 오프셋에 대한 리플리케이션 동작이 성공했음을 인지하고, 오프셋 0에 대해 커밋 표시를 한 후하이워터마크를 증가시킨다팔로워가 0번 오프셋에 대한 리플리케이션을 성공하지 못했다면, 팔로워는 1번 오프셋에 대한 리클리케이션 요청이 아닌 0번 오프셋에 대한 리플리케이션 요청을 보내게 된다리더는 팔로워들이 보내는 리플리케이션 요청의 오프셋을 보고, 팔로워들이 어느 위치의 오프셋까지 리플리케이션을 성공했는지를 인지할 수 있다
- 팔로워들로부터 1번 오프셋 메세지에 대한 리플리케이션 요청을 받은
리더는 응답에 0번 오프셋 message1 메세지가 커밋되었다는 내용도 함께 전달한다
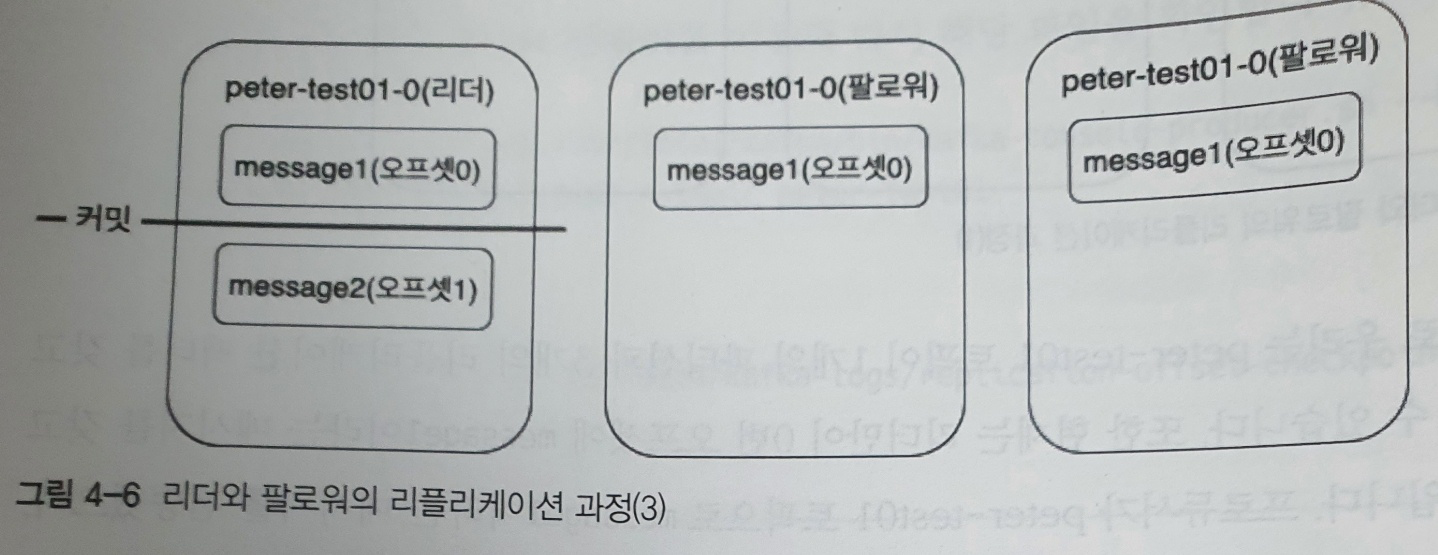
- 리더의 응답을 받은
모든 팔로워는 0번 오프셋 메세지가 커밋되었다는 사실을 인지하며, 리더와 동일하게 커밋 표시를 한다 - 1번 오프셋 메세지인 message2를 리플리케이션 한다
- 이렇게 리더와 팔로워는 해당 내용들을 반복하며 파티션 내의 리더와 팔로워간 메세지의 최신 상태를 유지한다
* 카프카는 다른 메세지큐와 다르게 ACK 통신을 하지 않는다
* ACK 통신을 제외했음에도 불구하고 팔로워와 리더 간의 리플리케이션 동작이 매우 빠르면서 신뢰할 수 있다
* 카프카에서 리더와 팔로워들의 리플리케이션 방식은 리더가 푸시하는 방식이 아니라 팔로워들이 풀 하는 방식으로 동작한다
* 팔로워 풀 방식을 채택한 이유도 리플리케이션 과정에서 리더의 부하를 줄여주기 위함이다리더에포크와 복구
- 리더에포크(LeaderEpoch)는 카프카의 파티션들이 복구 동작을 할 때 메세지의 일관성을 유지하기 위한 용도로 이용된다
- 리더에포크는 컨트롤러에 의해 관리되는 32비트의 숫자로 표현된다
- 리더에포크 정보는 리플리케이션 프로토콜에 의해 전파된다
- 새로운 리더가 변경된 후 변경된 리더에 대한 정보는 팔로워에게 전달된다
- 리더에포크는 복구 동작시 하이워터마크를 대체하는 수단으로도 활용된다
리더에포크 사용하지 않은 경우
peter-test01 토픽의 파티션 수는 1, 리플리케이션 팩터수는 2 min.insync.replicas는 1이다.
리더에포크가 없다는 가정하에 장애 복구 과정
1. 리더는 프로듀서로부터 message1 메세지를 받았고, 0번 오프셋에 저장, 팔로워는 리더에게 0번 오프셋에 대한 가져오기를 요청한다
2. 가져오기 요청을 통해 팔로워는 message1 메세지를 리더로부터 리플리케이션한다
3. 리더는 하이워터마크를 1로 올린다
4. 리더는 프로듀서로부터 다음 메세지인 message2를 받은 뒤 1번 오프셋에 저장한다
5. 팔로워는 다음 메세지인 message2에 대해 리더에게 가져오기 요청을 보내고, 응답으로 리더의 하이워터마크 변화를 감지하고 자신의 하이워터마크도 1로 올린다
6. 팔로워는 1번 오프셋의 message2 메세지를 리더로부터 리플리케이션한다
7. 팔로워는 2번 오프셋에 대한 요청을 리더에게 보내고, 요청을 받은 리더는 하이워터마크를 2로 올린다
8. 팔로워는 2번 오프셋인 message2 메세지까지 까지 리플리케이션을 완료했지만, 아직 리더로부터 하이워터마크를 2로 올리는 내용은 전달받지 못한 상태
9. 예상하지 못한 장애로 팔로워가 다운된다
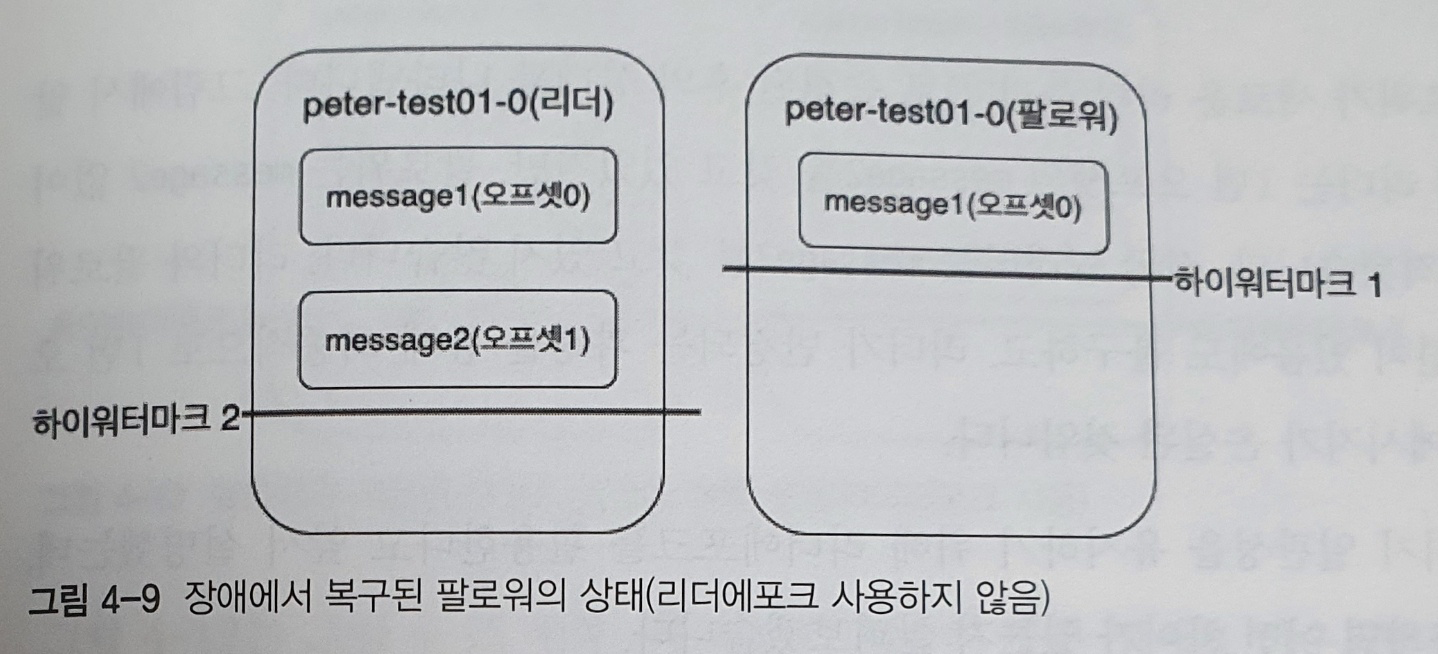
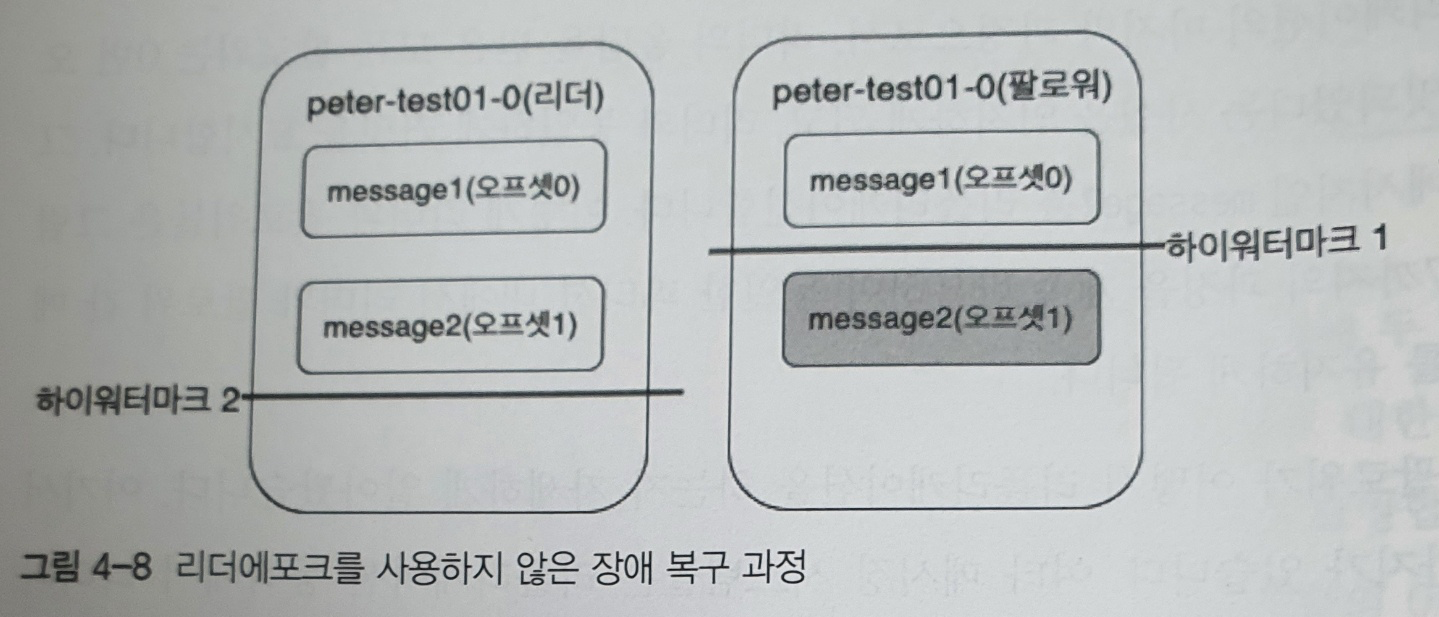
위 그림은 장애가 발생한 팔로워가 종료된 후 장애 처리가 완료된 상태를 나타낸다. 복구된 팔로워는 카프카 프로세스가 시작되면서 내부적으로 메세지 복구 동작을 하게 된다
메세지 복구 과정
1. 팔로워는 자신이 갖고 있는 메세지들 중에서 자신의 워터마크보다 높은 메세지들은 신뢰할 수 없는 메세지로 판단하고 삭제한다
2. 따라서 1번 오프셋의 message2는 삭제된다
3. 팔로워는 리더에게 1번 오프셋의 새로운 메세지에 대한 가져오기 요청을 보낸다
4. 이 순간 리더였던 브로커가 예상치 못한 장애로 다운되면서, 해당 파티션에 유일하게 남아있던 팔로워가 새로운 리더로 승격된다
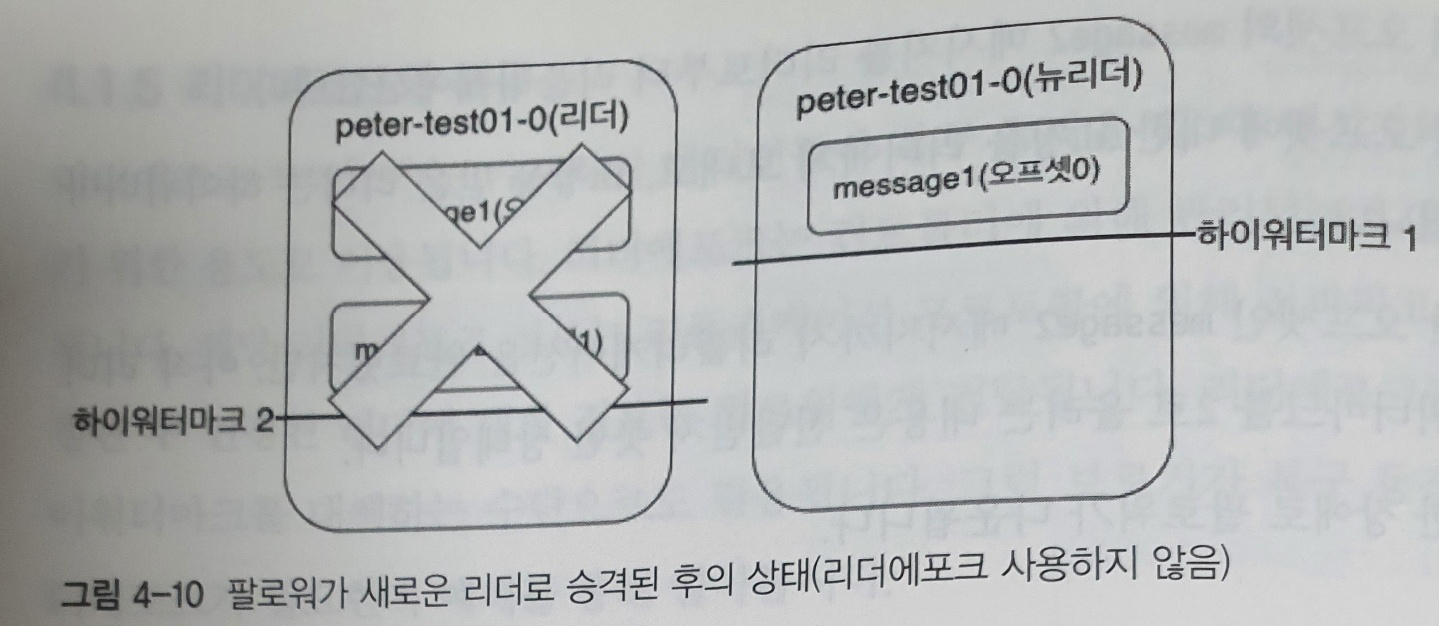
위 그림은 팔로워가 새로운리더로 승격한 후의 상태를 나타낸다. 새로운 리더가 message2 없이 리더로 승격 되었기에 message2 메세지는 유실되게 된다
리더에포크 사용한 경우
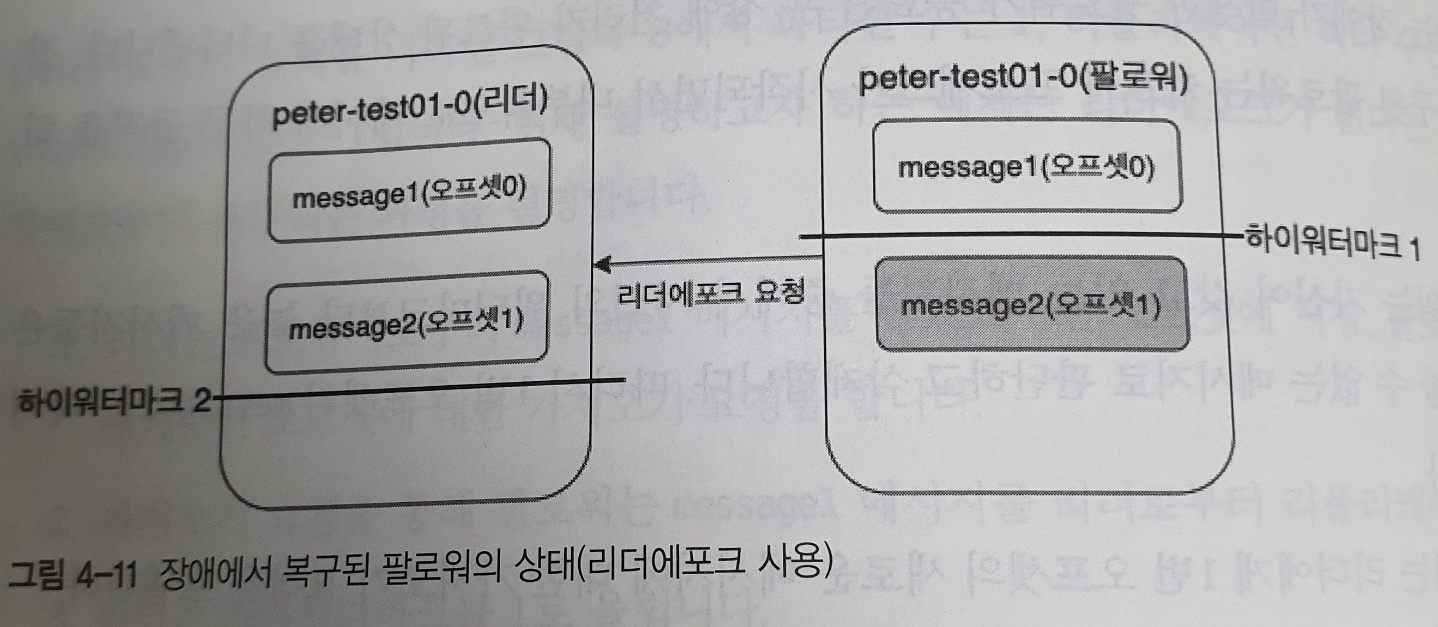
위 그림은 리더에포크를 사용하여 하이워터마크보다 앞에있는 메세지를 무조건 삭제하는 것이 아닌, 리더에게 리더에포크 요청을 보내서 복구한다
리더에포크 복구 과정
1. 팔로워는 복구 동작을 하면서 리더에게 리더에포크 요청을 보낸다
2. 요청을 받은 리더는 리더에포크의 응답으로 1번 오프셋의 message2까지 라고 팔로워에게 보낸다
3. 팔로워는 자신의 하이워터마크보다 높은 1번 오프셋의 message2를 삭제하지 않고, 리더의 응답을 확인한 후 message2까지 자신의 워터마크를 상향조정한다
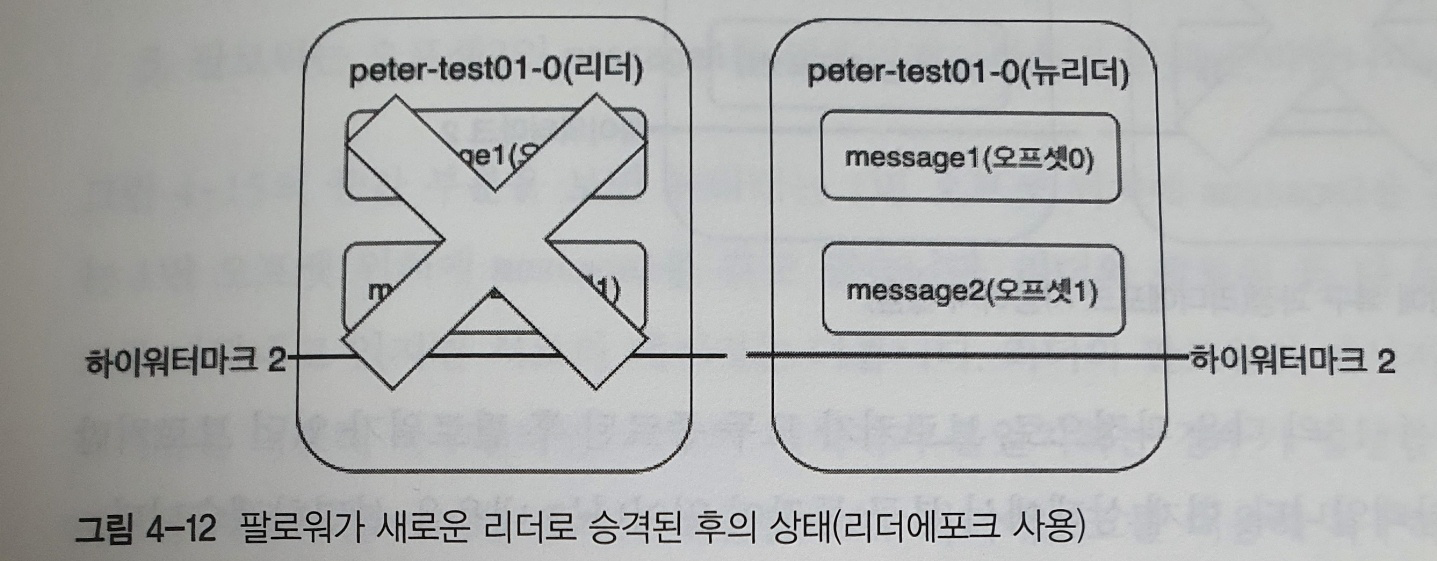
위 그림은 리더가 다운되면서 팔로워가 리더로 승격된 후의 상태를 나타낸다
- 리더에포크를 적용하지 않는 경우에는 팔로워가 message2 메세지를 갖고 있음에도 복구 과정에서 하이워터마크보다 높은 메세지를 삭제하여 메세지가 유실 됐었다
- 하지만 리더에포크를 활용하는 경우에는 삭제 동작을 하기에 앞서 리더에포크 요청과 응답 과정을 통해 팔로워의 하이워터마크를 올릴 수 있으며, 메세지 유실이 발생하지 않는다
리더에포크를 적용하지 않았을 때 발생할 수 있는 예제
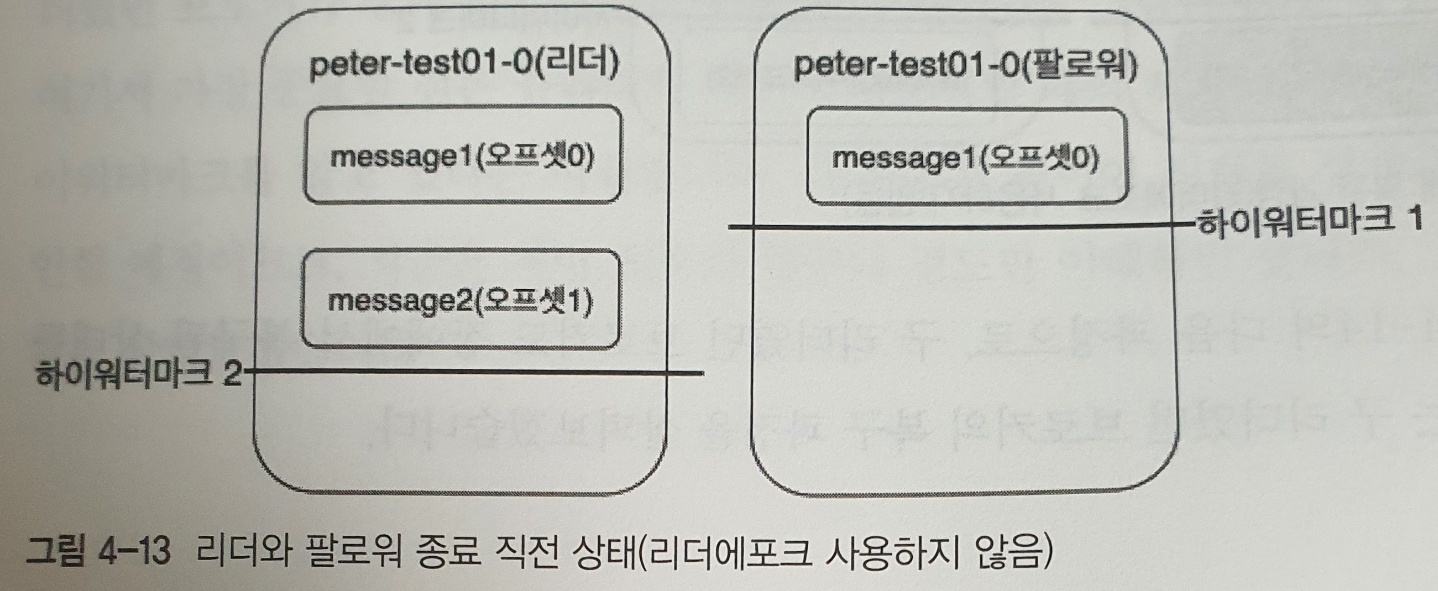
리더와 팔로워 종료직전 상태
- 리더만 오프셋 1까지 저장했고, 팔로워는 아직 1번 오프셋 메세지에 대해 리플리케이션 동작을 완료하지 못한 상태
- 현 시점에서 해당 브로커들의 장애가 발생해 리더와 팔로워 모두가 다운됐다고 가정
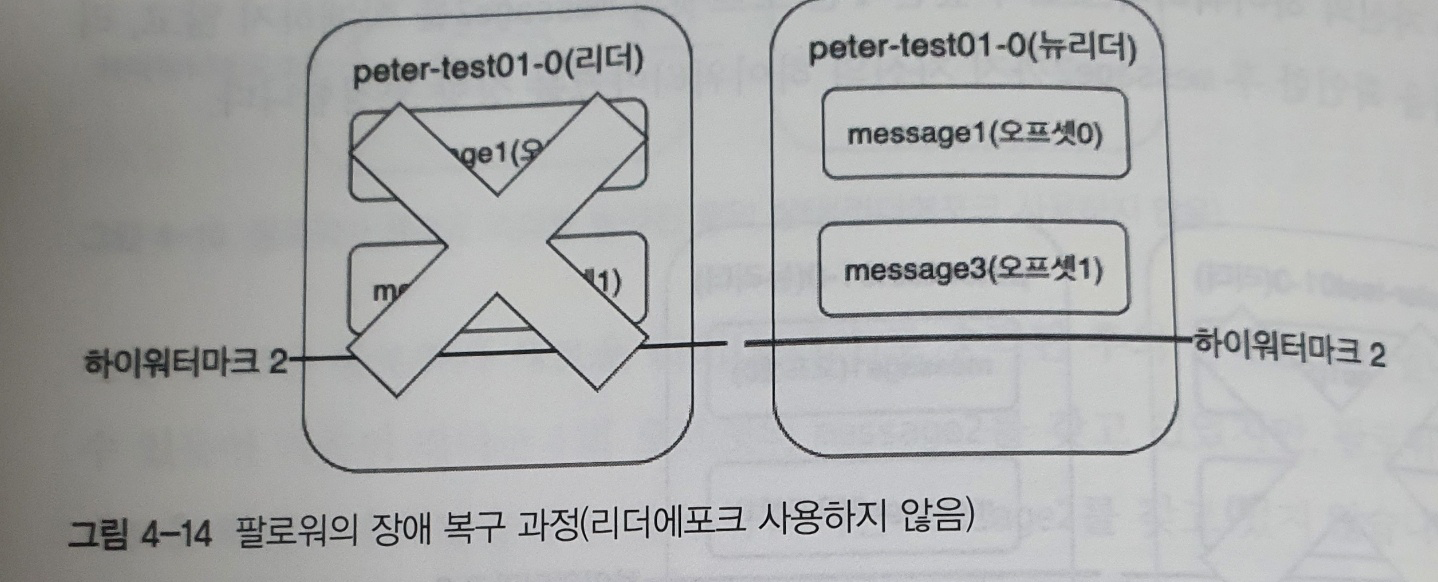
위 그림은 팔로워 모든 브로커가 종료된 후 팔로워 브로커만 장애에서 복구된 상태
팔로워 복구 과정
1. 팔로워였던 브로커가 장애에서 먼저 복구 된다
2. peter-test01 토픽의 0번 파티션에 리더가 없으므로 팔로워는 새로운 리더로 승격된다
3. 새로운 리더는 프로듀서로부터 다음 메세지 message3 을 전달받고 1번 오프셋에 저장한 후, 자신의 하이워터마크를 상향 조정한다
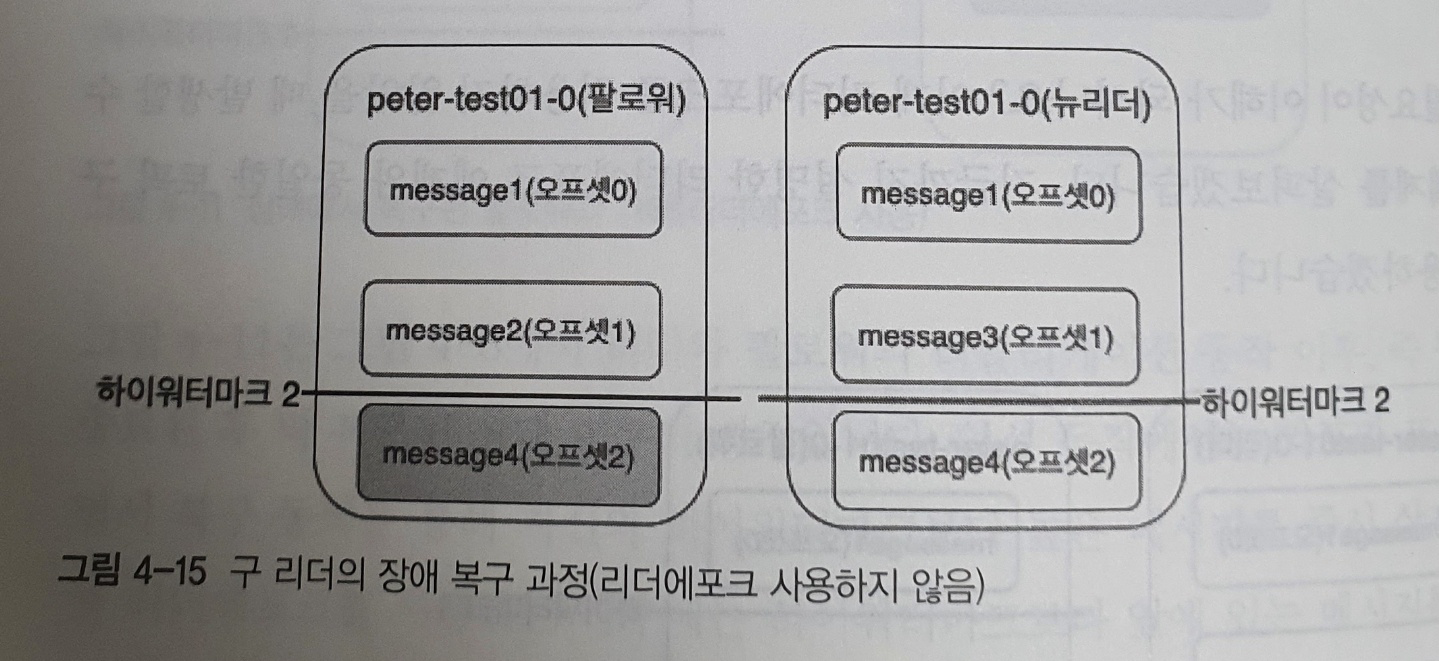
위 그림은 구 리더였던 브로커도 장애에서 복구한 상태를 나타낸다
구 리더 복구 과정
1. 구 리더였던 브로커가 장애에서 복구된다
2. peter-test01 토픽의 0번 파티션에 이미 리더가 있으므로, 복구된 브로커는 팔로워가 된다
3. 리더와 메세지 정합성 확인을 위해 자신의 하이워터마크를 비교해보니 리더와 하이워터마크와 일치하므로, 브로커는 자신이 갖고 있던 메세지를 삭제하지 않는다
4. 리더는 프로듀서로부터 message4 메세지를 받은 후 오프셋2의 위치에 저장한다
5. 팔로워는 오프셋2인 message4를 리플리케이션 하기 위해 준비한다
- 위와 같이 리더와 팔로워가 메세지의 동일한 오프셋 위치만을 이용해 복구된다면, 서로의 메세지가 불일치하는 경우가 발생한다
리더에포크 사용시 구리더 복구 과정
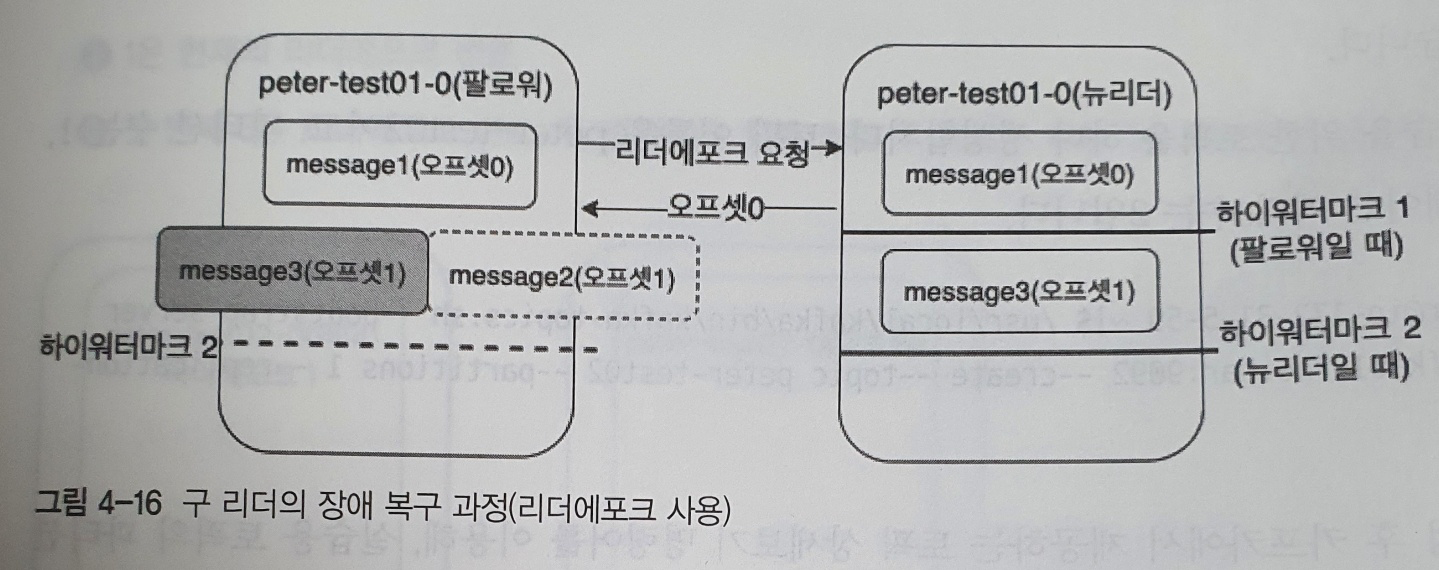
구 리더의 장애 복구 과정
- 위 그림은 팔로워가 먼저 복구되어 뉴리더가 되었고, 리더였던 브로커가 장애에서 복구된 상태를 나타낸다
- 여기서 중요한 점은, 뉴리덕 ㅏ자신이 팔로워일 때의 하이워터마크와 뉴리더일 때의 하이워터마크를 알고 있다는 사실이다
- 구 리더였던 브로커가 장애에서 복구된다
- peter-test01 토픽의 0번 파티션에 이미 리더가 있으므로 자신은 팔로워가 된다
- 팔로워는 뉴리더에게 리더에포크 요청을 보낸다
- 뉴리더는 0번 오프셋까지 유효하다고 응답한다 (팔로워 일때의 워터마크 기준)
- 팔로워는 메세지 일관성을 위해 로컬 파일에서 1번 오프셋인 message2를 삭제한다 (팔로워는 쓰기 권한이 없으므로, 리더에게 message2를 추가할 수 없다)
- 팔로워는 리더로부터 1번 오프셋인 message3을 리플리케이션 하기 위해 준비한다
위 복구 과정에서 어떻게 뉴리더가 message1(오프셋0)까지 신뢰할 수 있다고 응답할 수 있었을까?
- 리더에포크 요청과 응답에는 리더에포크 번호와 커밋된 오프셋 번호를 이용한다
- 아래 실습을 통해 확인
