
카프카 기본 개념과 구조
카프카의 핵심 개념
분산 시스템
분산 시스템이란?
- 네트워크상에서 연결된 컴퓨터들의 그룹
- 높은 성능
- 장애 대응 탁월
- 시스템 확장 용이
- 카프카도 분산 시스템이다
- 최초 구성한 클러스터의 리소스가 한계치에 도달해 더 높은 메세지 처리량이 필요한 경우, 브로커를 추가하는 방식으로 확장이 가능하다
- 브로커는 온라인 상태에서 매우 간단하게 추가 가능
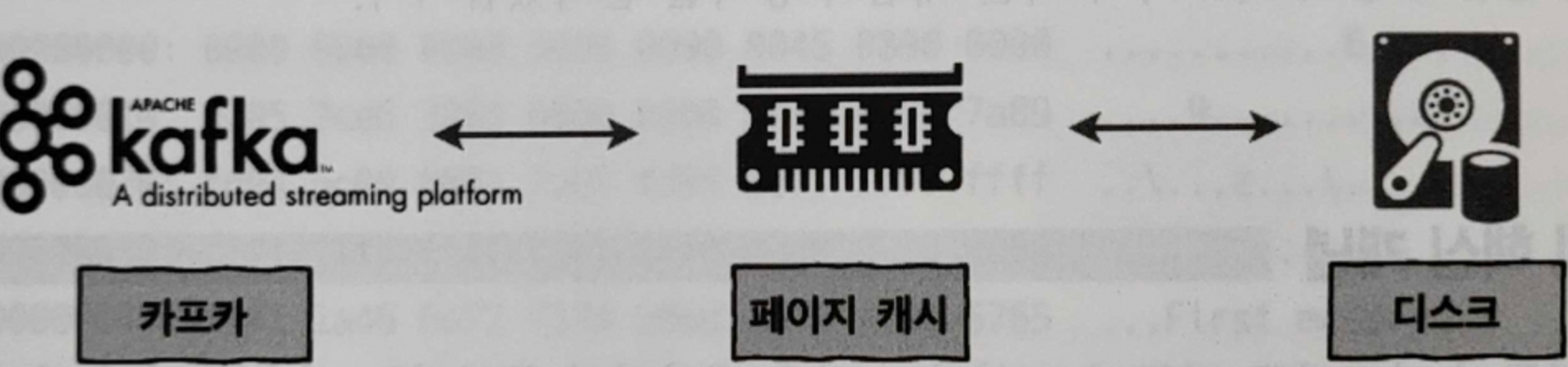
페이지 캐시
페이지 캐시란?
높은 처리량을 얻기위해 직접 디스크에 읽고, 쓰는 대신 물리 메모리 중 어플리케이션의 사용하지 않는 일부 잔여 메모리를 활용한다
- 카프카는 OS의 페이지 캐시를 활용하도록 설계되어있다
- 디스크의 I/O에 대한 접근이 줄어들므로 성능을 높일 수 있다
배치 전송 처리
배치 전송 처리란?
카프카의 프로듀서, 클라이언트들과의 수많은 통신을 묶어서 처리
- 카프카는 배치 전송을 권장
압축 전송
- 카프카는 성능이 좋은 높은 압축 전송 사용을 권장
- 지원하는 압축 타입 : gzip, snappy, lz4, zstd 등
- 배치 전송과 결합해 사용하면 더욱 높은 효과를 얻을 수 있다
- 일반적으로 높은 압축률이 필요한 경우는 gzip 이나 zstd를 권장
- 빠른 응답속도가 필요한 경우 lz4나 snappy를 권장
토픽, 파티션, 오프셋
- 카프카는 토픽 이라는 곳에 데이터를 저장하는데, 이는 메일 전송 시스템에서 이메일 주소 정도의 개념으로 이해하면 쉽다
- 토픽은 병렬 처리를 위해 여러개의 파티션이라는 단위로 나뉜다
- 이와 같은 파티셔닝을 통해 단 하나의 토픽이라도 높은 처리량을 수행할 수있다
- 파티션의 메세지가 저장되는 위치를 오프셋이라고 한다
- 오프셋은 순차적으로 증가하는 숫자(64bit) 형태로 되어있다.
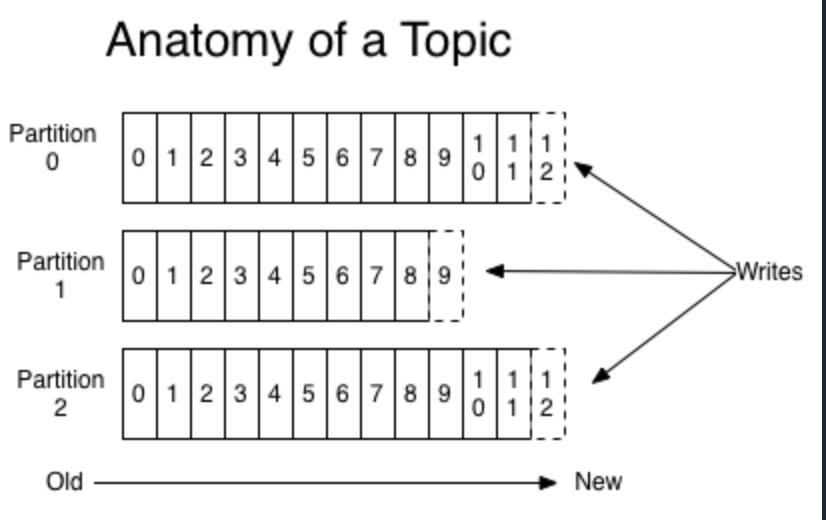
- 위 그림은 하나의 토픽이 3개의 파티션으로 나뉘며 프로듀서로부터 전송되는 메세지들의 쓰기 동작이 각 파티션별로 이뤄짐을 볼 수있다.
- 각 파티션 마다 순차적으로 증가하는 숫자들을 볼 수 있는데, 이 숫자들이 오프셋이다.
- 각 파티션에서의 오프셋은 고유한 숫자를 가진다
- 카프카는 오프셋을 통해 메세지의 순서를 보장하고, 컨슈머에서는 마지막까지 읽은 위치를 알 수도 있다.
고가용성 보장
- 카프카는 분산 시스템이기 때문에 하나의 서버나 노드가 다운되어도 안정적인 서비스가 가능하다
- 고가용성을 보장하기 위해 카프카에서는 리플리케이션 기능을 제공한다
- 카프카의 리플리케이션은 토픽 자체를 복제하는 것이 아니라 토픽의 파티션을 복제한다
- 토픽 생성시 리플리케이션 팩터 수를 지정할 수 있다
- 원본과 리플리케이션을 구분하기 위해 흔히 마스터, 미러 같은 용어를 사용한다
- 카프카에서는 마스터를 리더, 미러를 팔로워로 부른다
- 팔로워의 수가 많다고 딱히 좋은 것은 아니다
- 카프카에서는 리플리케이션 팩터 수를 3으로 구성하도록 권장한다
- 리더는 프로듀서, 컨슈머로부터 오는 모든 읽기와 쓰기 요청을 처리한다
- 팔로워는 오직 리더로부터 리플리케이션 하게 된다
주키퍼의 의존성
주키퍼란?
카프카의 중요한 메타데이터를 저장하고 각 브로커를 관리하는 중요한 역할을 한다
주키퍼는 여러대의 서버를 앙상블(클러스터)로 구성하고, 살아 있는 노드 수가 과반수 이상 유지된다면 지속적인 서비스가 가능한 구조입니다. 따라서 주키퍼는 반드시 홀수로 구성하여야 한다
- 주키퍼는 반드시 홀수로 구성해야 한다
- 지노드(znode) 를 이용해 카프카의 메타 정보가 주키퍼에 기록 된다
- 주키퍼는 지노드를 이용해 브로커의 관리, 토픽 관리, 컨트롤러 관리 등 매우 중요한 역할을 하고 있다
- 카프카에서 주키퍼에 대한 의존성을 제거하려는 움직임이 있다
- 2021년말 2022년 초 무렵에는 주키퍼가 삭제된 카프카 버전이 릴리즈될 예정

우렁총각