평가지표 한 줄 정리
supervised machine learning(ML)에서는 모델을 평가하기 위한 평가지표가 존재하는데 이미 한번씩 정리를 했던 내용인지라 오늘은 그래도 일단 복습한다는 느낌으로 개념을 짧게 정리하고 넘어가려고 한다.
참고로 unsupervised ml은 non-target/label로 예전에 내가 배웠었던 k-means clustering(ex. 생김새로 인종 분류하기 등)이 있다.
회귀모델
rmse & mae
rmse는 예측값과 실제값의 차이인 오차들의 제곱평균(mse)에 루트를 씌운 값이다.
mae는 실제값과 예측값의 차이인 오차들의 절댓값 평균으로 mse보다 이상치에 덜 민감하다는 특징이 있다.
p-value
가설 검정에서 귀무가설을 기각 혹은 채택을 결정할 수 있는 확률을 의미하며 0과 1사이의 값을 가진다. p-value가 높을수록 귀무가설이 참일 확률이 높다고 해석할 수 있다.
R2 score
0과 1 사이의 값을 가지는 선형 회귀 모델에 대한 적합도 측정값이다.
분류모델
accuracy
accuracy는 정확도로 전체 예측 건수에서 정답을 맞힌 건수의 비율을 뜻한다.
recall
recall은 재현율로 실제 true 값 중 올바르게 true로 예측된 비율을 뜻한다.
precision
precision은 정밀도로 true로 예측된 값 중에서 실제 true값의 비율을 뜻한다.
confusion matrix
confusion matrix(오차행렬)은 training을 통해 성능을 측정하기 위해서 실제 값과 예측 값을 비교하기 위한 표이다.
f1 score
f1 score는 precision과 recall의 조화평균 값으로 데이터가 불균형할 때 주로 사용한다.
roc & auc
roc curve와 auc는 다양한 임계값에서 모델의 분류 성능에 대한 측정 그래프이다. auc는 roc curve 아래의 면적을 의미하며 면적이 넓을 수록 학습이 잘 됐다는 것을 뜻한다.
~ 조금 더 정리 후 추가 예정..~
로그 변환 (Log-Transform)
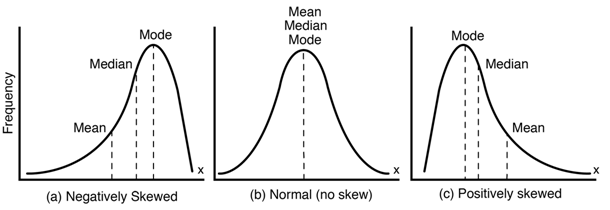
선형 회귀에서는 일반적으로 특성과 target 간에 선형관계를 가정하고, 분포가 정규분포 형태일 때 좋은 성능을 보인다. 타겟 변수의 분포가 skewed한 상태일 경우 예측 성능에 부정적인 영향을 미치므로 분포를 인위적으로 바꿔주는 것이 좋다.
이럴 때 사용하는 것이 바로 로그 변환이다. 위의 그림 중 (c)번의 상태, right-skewed한 상태라면 로그 변환을 사용해서 비대칭한 분포 형태를 정규분포 형태로 변환시켜줄 수 있다.
참고로 로그 변환을 left-skewed한 상태에서 사용한다면 더 심한 left-skewed한 상태가 만들어지니까 사용하기 전에 꼭 데이터의 분포를 살펴보고 사용해줘야 한다.
import numpy as np
df[original] = target
df[transformed_column] = np.log1p(target) # log 변환
df[backToOriginal] = np.expm1(np.log1p(target)) # log 변환했던 값을 원래 값으로 되돌림