
코드 : 실전스프링데이터_JPA 코드
출처 : 실전 스프링 데이터 JPA
프로젝트 환경설정
프로젝트 생성
- 스프링 부트 스타터(https://start.spring.io/)
- Project: Gradle - Groovy Project
- 사용 기능: web, jpa, h2, lombok
SpringBootVersion: 2.7.6
groupId: study
* artifactId: data-jpa
Gradle 전체 설정
plugins {
id 'java'
id 'org.springframework.boot' version '2.7.6'
id 'io.spring.dependency-management' version '1.0.15.RELEASE'
}
group = 'study'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '11'
configurations {
compileOnly {
extendsFrom annotationProcessor
}
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-web'
compileOnly 'org.projectlombok:lombok'
runtimeOnly 'com.h2database:h2'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
tasks.named('test') {
useJUnitPlatform()
}
gradle 의존관계 보기
./gradlew dependencies --configuration compileClasspath
스프링 부트 라이브러리 살펴보기
- spring-boot-starter-web
- spring-boot-starter-tomcat: 톰캣 (웹서버)
- spring-webmvc: 스프링 웹 MVC
- spring-boot-starter-data-jpa
- spring-boot-starter-aop
- spring-boot-starter-jdbc
- HikariCP 커넥션 풀 (부트 2.0 기본)
- hibernate + JPA: 하이버네이트 + JPA
- spring-data-jpa: 스프링 데이터 JPA - spring-boot-starter(공통): 스프링 부트 + 스프링 코어 + 로깅
- spring-boot
- spring-core
- spring-boot-starter-logging
- logback, slf4j
핵심 라이브러리
- 스프링 MVC
- 스프링 ORM
- JPA, 하이버네이트
- 스프링 데이터 JPA
기타 라이브러리
- H2 데이터베이스 클라이언트
- 커넥션 풀: 부트 기본은 HikariCP
- 로깅 SLF4J & LogBack // SLF4J는 인터페이스이고, LogBack은 구현체 중 하나
- 테스트
공통 인터페이스 기능
공통 인터페이스 설정
스프링 데이터 JPA가 구현 클래스 대신 생성
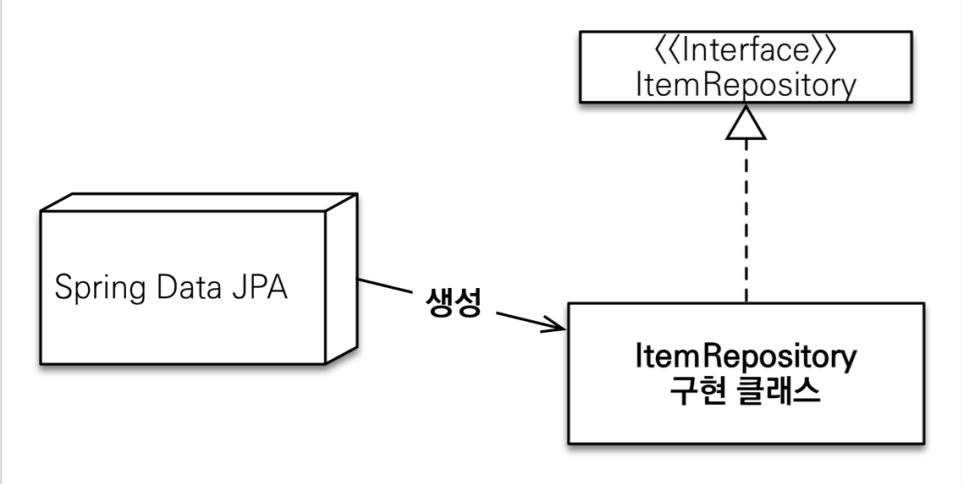
- org.springframework.data.repository.Repository를 구현한 클래스는 스캔 대상
- MemberRepsository 인터페이스가 동작한 이유- 실제 출력해보기(memberRepository.getClass() -> class com.sun.proxy.$ProxyXXX)
- 스프링이 직접 생성하고 의존 관계 주입
- 실제 출력해보기(memberRepository.getClass() -> class com.sun.proxy.$ProxyXXX)
- @Repository 애노테이션 생략 가능
- 컴포넌트 스캔을 스프링 데이터 JPA가 자동으로 처리- JPA 예외를 스프링 예외로 변환하는 과정도 자동으로 처리
공통 인터페이스 분석
- JpaRepository 인터페이스 : 공통 CRUD 제공
- 제네릭은 <엔티티타입, 식별자 타입> 설정
공통 인터페이스 구성
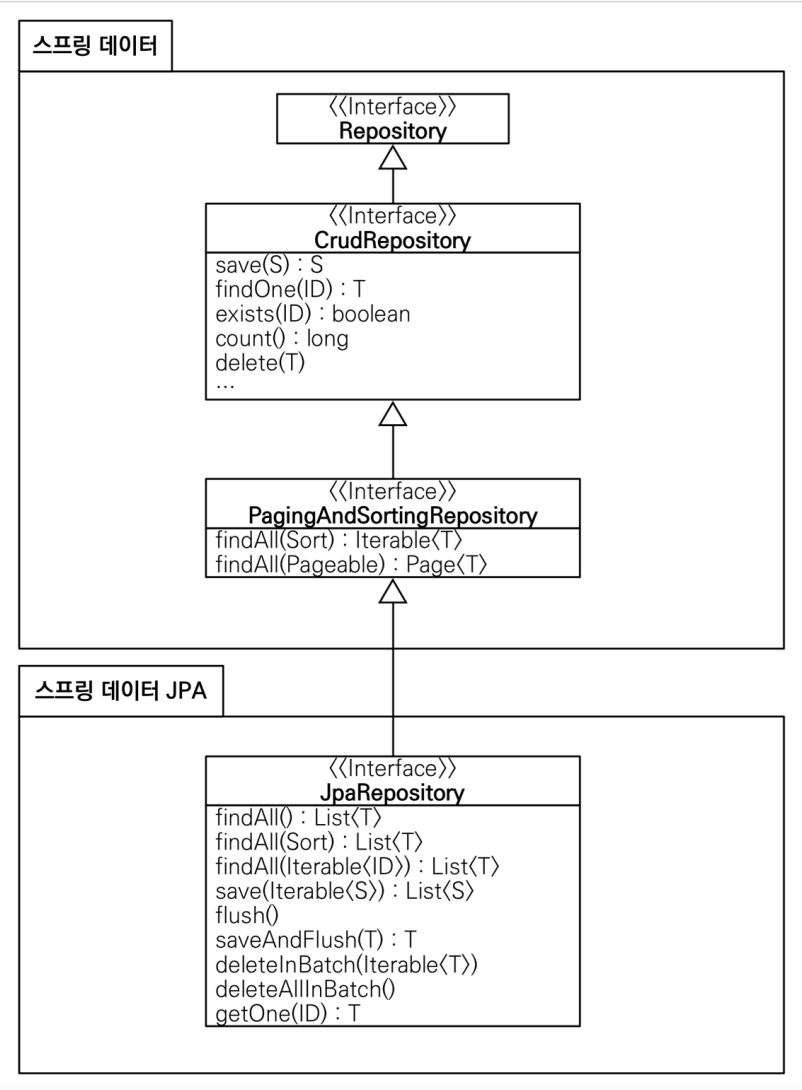
주의
- T findOne(ID) -> Optional findById(ID) 변경
- boolean exists(ID) -> boolean existsById(ID) 변경
제네릭 타입
- T : 엔티티
- ID : 엔티티의 식별자 타입
- S : 엔티티와 그 자식 타입
주요 메서드
- save(S) : 새로운 엔티티는 저장하고 이미 있는 엔티티는 병합
- delete(T) : 엔티티 하나를 삭제, 내부에서 EntitiyManager.remove() 호출
- findById(ID) : 엔티티 하나를 조회, 내부에서 EntityManager.find() 호출
- getOne(ID) : 엔티티를 프록시로 조회, 내부에서 EntityManager.getReference() 호출
- findAll(_) : 모든 엔티티 조회, 정렬이나 페이징 조건을 파라미터로 제공할 수 있음.
도메인에 특화된 메소드는 어떻게 해결할까? --> 쿼리 메소드
쿼리 메소드
쿼리 메소드 기능
- 메소드 이름으로 쿼리 생성
- NamedQuery
- @Query - 리파지토리 메소드에 쿼리 정의
- 파라미터 바인딩
- 반환 타입
- 페이징과 정렬
- 벌크성 수정 쿼리
- @EntityGraph
쿼리 메소드 기능 3가지
- 메소드 이름으로 쿼리 생성
- 메소드 이름으로 JPA NamedQuery 호출
- @Query 어노테이션을 사용해서 리파지토리 인터페이스에 쿼리 직접 정의
메소드 이름으로 쿼리 생성
스프링 데이터 JPA가 제공하는 쿼리 메소드 기능
- 조회 : find ... By, read ... By, qeury...By, get...By
- COUNT : count...By 반환타입 long
- EXISTS : exists...By 반환타입 boolean
- 삭제 : delete...By, remove...By 반환타입 long
- DISTINCT : findDistinct, findMemberDistinctBy
- LIMIT : findFirst3, findFirst, findTop, findTop3
참고 : 이 기능은 엔티티의 필드 명이 변경되면 인터페이스에 정의한 메소드 이름도 함께 변경해야 한다. 그렇지 않으면 애플리케이션을 시작하는 시점에 오류가 발생한다.
--> 애플리케이션 로딩 시점에 오류를 인지할 수 있는 스프링 데이터 JPA의 장점
JPA NamedQuery
참고 : 스프링 데이터 JPA를 사용하면 실무에서 Named Query를 직접 등록해서 사용하는 일은 드물다. 대신 @Query를 사용해서 리파지토리 메서드에 쿼리를 직접 정의한다.
@Entity
@NamedQuery(
name="Member.findByUsername",
query="select m from Member m where m.username = :username")
public class Member {
...
}- 스프링 데이터 JPA는 선언한 "도메인 클래스 + . + 메서드 이름"으로 Named 쿼리를 찾아서 실행
- 만약 실행할 Named 쿼리가 없으면 메서드 이름으로 쿼리 생성 전략을 사용한다.
- 필요하면 전략을 변경할 수 있지만 권장하지 않는다.
@Query, 리파지토리 메소드에 쿼리 정의하기
메서드에 JPQL 쿼리 작성
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query("select m from Member m where m.username= :username and m.age = :age")
List<Member> findUser(@Param("username") String username, @Param("age") int
age);
}@org.springframework.data.jpa.repository.Query어노테이션 사용- 실행할 메서드에 정적 쿼리를 직접 작성하므로 이름 없는 Named Query라 할 수 있음
- JPA Named 쿼리처럼 애플리케이션 실행 시점에 문법 오류를 발견할 수 있음(매우 큰 장점)
@Query, 값, DTO 조회하기
단순히 값 하나를 조회
@Query("select m.username from Member m")
List<String> findUsernameList();DTO로 직접 조회
@Query("select new study.datajpa.dto.MemberDto(m.id, m.username, t.name) " +
"from Member m join m.team t")
List<MemberDto> findMemberDto();*주의 DTO로 직접 조회하려면 JPA의 new명령어를 사용해야 한다.
그리고 다음과 같이 생성자가 맞는 DTO가 필요하다. (JPA와 사용방식이 동일)*
파라미터 바인딩
select m from Member m where m.username = ?0 //위치 기반 select m from Member m where m.username = :name //이름 기반
가독성과 유지보수를 위해 이름 기반 파라미터 바인딩을 사용하자
컬렉션 파라미터 바인딩
Collection 타입으로 in절 지원
@Query("select m from Member m where m.username in :names")
List<Member> findByNames(@Param("names") List<String> names);반환 타입
스프링 데이터 JPA는 유연한 반환 타입 지원
조회 결과가 많거나 없으면?
- 컬렉션
* 결과 없음 : 빈 컬렉션 반환 - 단건 조회
* 결과 없음 :null반환- 결과가 2건 이상 :
javax.persistence.NonUniqueResultException예외 발생
- 결과가 2건 이상 :
순수 JPA 페이징과 정렬
JPA에서 페이징을 어떻게 할 것인가?
스프링 데이터 JPA 페이징과 정렬
페이징과 정렬 파라미터
org.springframework.data.domain.Sort: 정렬 기능org.springframework.data.domain.Pageable: 페이징 기능 (내부Sort포함)
특별한 반환 타입
org.springframework.data.domain.Page: 추가 count 쿼리 결과를 포함하는 페이징org.springframework.data.domain.Slice: 추가 count 쿼리 없이 다음 페이지만 확인 가능 (내부적으로 limit + 1조회)List(자바 컬렉션): 추가 count 쿼리 없이 결과만 반환
페이징과 정렬 사용 예제
Page<Member> findByUsername(String name, Pageable pageable); //count 쿼리 사용
Slice<Member> findByUsername(String name, Pageable pageable); //count 쿼리 사용 안함
List<Member> findByUsername(String name, Pageable pageable); //count 쿼리 사용 안함
List<Member> findByUsername(String name, Sort sort);
Page 인터페이스
public interface Page<T> extends Slice<T> {
int getTotalPages(); //전체 페이지 수
long getTotalElements(); //전체 데이터 수
<U> Page<U> map(Function<? super T, ? extends U> converter); //변환기
}페이지를 유지하면서 엔티티를 DTO로 변환하기
Page<Member> page = memberRepository.findByAge(10, pageRequest);
Page<MemberDto> dtoPage = page.map(m -> new MemberDto());벌크성 수정 쿼리
스프링 데이터 JPA를 사용한 벌크성 수정 쿼리
@Modifying
@Query("update Member m set m.age = m.age + 1 where m.age >= :age")
int bulkAgePlus(@Param("age") int age);- 벌크성 수정, 삭제 쿼리는
@Modifying어노테이션을 사용
* 사용하지 않으면 예외 발생 - 벌크성 쿼리를 실행하고 나서 영속성 컨텍스트 초기화 :
@Modifying(clearAutomatically = true)(이 옵션 기본값이 false)
* 꼭 초기화 하자!
참고 : 벌크 연산은 영속성 컨텍스트를 무시하고 실행하기 때문에, 영속성 컨텍스트에 있는 엔티티의 상태와 DB에 엔티티 상태가 달라질 수 있다.
권장 방안
- 영속성 컨텍스트에 엔티티가 없는 상태에서 벌크 연산을 먼저 실행한다.
- 부득이하게 영속성 컨텍스트에 엔티티가 있으면 벌크 연산 직후 영속성 컨텍스트를 초기화 한다.
@EntityGraph
연관된 엔티티들을 SQL 한번에 조회하는 방법
member -> team은 지연로딩 관계
연관된 엔티티를 한번에 조회하려면 페치 조인이 필요
스프링 데이터 JPA는 JPA가 제공하는 엔티티 그래프 기능을 편리하게 사용하게 도와준다.
이 기능을 사용하면 JPQL 없이 페치 조인을 사용할 수 있다.
EntityGraph
//공통 메서드 오버라이드
@Override
@EntityGraph(attributePaths = {"team"})
List<Member> findAll();
//JPQL + 엔티티 그래프
@EntityGraph(attributePaths = {"team"})
@Query("select m from Member m")
List<Member> findMemberEntityGraph();
//메서드 이름으로 쿼리에서 특히 편리하다.
@EntityGraph(attributePaths = {"team"})
List<Member> findByUsername(String username)사실상 페치 조인의 간편 버전
확장 기능
사용자 정의 리포지토리 구현
스프링 데이터 JPA 리포지토리는 인터페이스만 정의하고 구현체는 스프링이 자동 생성
- 인터페이스의 메서드를 직접 구현하고 싶다면?
* JPA 직접 사용 (EntityManager)- 스프링 JDBC Template 사용
- MyBatis 사용
- 데이터페이스 커넥션 직접 사용
- Querydsl 사용
참고 : 실무에서는 주로 QueryDSL이나 SpringJdbcTemplate을 함께 사용할 때 사용자 정의 리포지토리 기능 자주 사용
참고 : 항상 사용자 정의 리포지토리가 필요한 것은 아니다. 그냥 임의의 리포지토리를 만들어도 된다. 예를들어 MemberQueryRepository를 인터페이스가 아닌 클래스로 만들고 스프링 빈으로 등록해서 그냥 직접 사용해도 된다. 이 경우 스프링 데이터 JPA와는 아무런 관계 없이 별도로 동작한다.
Auditing
엔티티를 생성, 변경할 때 변경한 사람과 시간을 추적하고 싶으면?
등록일
수정일
등록자
수정자
순수 JPA 사용
스프링 데이터 JPA 사용
@EnableJpaAuditing -> 스프링 부트 설정 클래스에 적용해야함
@EntityListeners(AuditingEntityListener.class) -> 엔티티에 적용
사용 어노테이션
@CreatedDate@LastModifiedDate@CreatedBy@LastModifiedBy
참고 : 실무에서 대부분의 엔티티는 등록시간, 수정시간이 필요하지만, 등록자, 수정자는 없을 수도 있다. 그래서 Base 타입을 분리하고, 원하는 타입을 선택해서 상속한다.
참고 : 저장시점에 등록일, 등록자는 물론이고, 수정일, 수정자도 같은 데이터가 저장된다. 데이터가 중복 저장되는 것 같지만, 이렇게 해두면 변경 컬럼만 확인해도 마지막에 업데이트한 유저를 확인 할 수 있으므로 유지보수 관점에서 편리하다. 이렇게 하지 않으면 변경 컬럼이 null일 때 등록 컬럼을 또 찾아야 한다.
Web 확장 - 도메인 클래스 컨버터
HTTP 파라미터로 넘어온 엔티티의 아이디로 엔티티 객체를 찾아서 바인딩
도메인 클래스 컨버터 사용 전
@GetMapping("/members/{id}")
public String findMember(@PathVariable("id") Long id) {
Member member = memberRepository.findById(id).get();
return member.getUsername();
}도메인 클래스 컨버터 사용 후
@GetMapping("/members/{id}")
public String findMember(@PathVariable("id") Member member) {
return member.getUsername();
}- HTTP 요청은 회원
id를 받지만 도메인 클래스 컨버터가 중간에 동작해서 회원 엔티티 객체를 반환 - 도메인 클래스 컨버터도 리파지토리를 사용해서 엔티티를 찾음
주의 : 도메인 클래스 컨버터로 엔티티를 파라미터로 받으면, 이 엔티티는 단순 조회용으로만 사용해야 한다. (트랜잭션이 없는 범위에서 엔티티를 조회했으므로, 엔티티를 변경해도 DB에 반영되지 않는다.)
Web 확장 - 페이징과 정렬
스프링 데이터가 제공하는 페이징과 정렬 기능을 스프링 MVC에서 편리하게 사용할 수 있다.
페이징과 정렬 예제
@GetMapping("/members")
public Page<Member> list(Pageable pageable) {
Page<Member> page = memberRepository.findAll(pageable);
return page;
}- 파라미터로 `Pageable을 받을 수 있다.
Pageable은 인터페이스, 실제는org.springframework.data.domain.PageRequest객체 생성
요청 파라미터
- 예)
/members?page=0&size=3&sort=id,desc&sort=username,desc - page : 현재 페이지, 0부터 시작한다.
- size : 한 페이지에 노출할 데이터 건수
- sort
접두사
- 페이징 정보가 둘 이상이면 접두사로 구분
@Qualifier에 접두사명 추가 "{접두사명}_xxx"- 예제 :
/mebers?member_page=0&order_page=1
Page 내용을 DTO로 변환하기
엔티티를 API로 노출하면 다양한 문제가 발생한다. 그래서 엔티티를 꼭 DTO로 변환해서 반환해야 한다.
Page는 `map()을 지원해서 내부 데이터를 다른 것으로 변경할 수 있다.
스프링 데이터 JPA 분석
스프링 데이터 JPA 구현체 분석
스프링 데이터 JPA가 제공하는 공통 인터페이스의 구현체
org.springframework.data.jpa.repository.support.SimpleJpaRepository
@Repository 적용
JPA 예외를 스프링이 추상와한 예외로 변환
@Transactional
- JPA의 모든 변경은 트랜잭션 안에서 동작
- 스프링 데이터 JPA는 변경(등록, 수정, 삭제) 메서드를 트랜잭션 처리
- 서비스 계층에서 트랜잭션을 시작하지 않으면 리파지토리에서 트랜잭션 시작
- 서비스 계층에서 트랜잭션을 시작하면 리파지토리는 해당 트랜잭션을 전파 받아서 사용
- 그래서 스프링 데이터 JPA를 사용할 때 트랜잭션이 없어도 데이터 등록, 변경이 가능했음
* (사실 트랜잭션이 리파지토리 계층에 걸려있는 것)
@Transactional(readOnly = true)
- 데이터를 단순히 조회만 하고 변경하지 않는 트랜잭션에서
readOnly = true옵션을 사용하면 플러시를 생략해서 약간의 성능 향상을 얻을 수 있음
save() 메서드
매우 중요
- 새로운 엔티티면 저장 (persiste)
- 새로운 엔티티가 아니면 병합 (merge)
새로운 엔티티를 구별하는 방법
새로운 엔티티를 판단하는 기본 전략
- 식별자가 객체일 때
null로 판단 - 식별자가 자바 기본 타입일 때
0으로 판단 Persistable인터페이스를 구현해서 판단 로직 변경 가능
나머지 기능들
Specifications (명세)
실무에서는 잘 사용 안하며 QueryDSL 사용
Query By Example
실무에서 사용하기 어려움 QueryDSL 사용
Projections
엔티티 대신에 DTO를 편리하게 조회할 때 사용
네이티브 쿼리
가급적 네이티브 쿼리는 사용하지 않는게 좋음, 정말 어쩔 수 없을 때 사용
최근 방법 -> 스프링 데이터 Projections 활용
스프링 데이터 JPA 기반 네이티브 쿼리
장점
- 페이지 지원
- 반환 타입(Object [], Tuple, DTO)
단점
- 제약 : Sort 파라미터를 통한 정렬이 정상 동작하지 않을 수 있음
- JPQL처럼 애플리케이션 로딩 시점에 문법 확인 불가
- 동적 쿼리 불가
