
아래 내용은 뇌를 자극하는 알고리즘을 참고하며 공부한 것을 정리한 내용입니다.
오늘은 자료구조 중 가장 간단한 형태인 Linked List에 대해 알아보려 합니다.
Linked List란?
우리는 컴퓨터에 데이터를 저장할때 변수를 사용합니다. 만약 여러 개의 데이터를 다뤄야 하는 경우 필요한 수 만큼의 변수를 선언해야 합니다.
우리가 C에서는 배열을 쓰면 간단하게 사용자가 정한 수의 변수를 한번에 만들 수 있습니다. 하지만 현실에서는 데이터의 개수가 가변적이므로 고정된 개수의 변수를 선언하는 배열은 효율적이지 못합니다.
예를 들면 약 100개의 배열을 선언한 경우 아래와 같은 상황에서 메모리효율이 떨어집니다.
- 배열로 100개의 변수를 선언 했지만 실제 사용 데이터는 10개 미만 : 메모리 낭비
- 배열로 100개의 변수를 선언 했는데 실제 사용 데이터는 100개 초과 : 메모리 부족
따라서 데이터 수에 맞춰 효율적으로 메모리를 활용할 수 있는 자료구조를 사용할 필요가 있습니다.
Linked List는 데이터 목록을 다루는 가장 단순한 자료구조로, 데이터가 순차적으로 연결된 선형 구조로 되어있습니다.
Linked List 구조

Linked List는 노드(Node)라는 요소로 구성되어 있습니다. 노드는 데이터를 저장하는 부분과 다음 노드에 대한 포인터로 이루어져 있습니다.
Linked List는 위 그림과 같이 이 노드들이 일렬로 연결된 자료구조 형태를 말합니다. 이 때 첫 번째 노드를 헤드(Head), 마지막 노드를 테일(Tail)이라고 부릅니다.
Linked List 구조에서는 헤드 노드의 정보만 가지고 있으면 다음 노드를 찾아갈 수 있으며, 데이터의 개수에 맞춰 필요한 수의 메모리만 사용할 수 있는 장점이 있습니다.
장/단점
Linked List는 아래와 같은 장/단점을 가지고 있습니다.
장점
- 단순한 구조로 이루어져 있어서 구현이 편하고 데이터의 추가, 삽입, 삭제가 쉬움
- 현재 노드가 가지고 있는 포인터 정보를 사용하여 추가적인 연산 없이 다음 노드를 가져올 수 있음
단점
- 노드에는 다음 노드를 가르키는 포인터가 필요하기 때문에 메모리가 추가로 필요
- 헤드 노드의 정보만 가지고 있기 때문에 특정 위치에 있는 노드를 탐색하는데 많은 연산이 필요함
주요 연산 구현
Linked List를 사용하기 위해서는 아래의 5가지 기능이 구현되어야 합니다. 아래에서는 각 기능에 대한 설명과 그 기능을 C++로 구현하면 아래와 같습니다.
1. 노드
노드는 데이터와 다음 노드를 가리키는 포인터로 이루어져 있습니다. 구조체를 활용하면 아래와 같이 노드를 간단히 구현할 수 있습니다.
// 노드 구조체 구현
struct Node
{
int data; //노드의 데이터를 저장하는 변수
struct Node* pNextNode; // 다음 노드의 포인터를 가리키는 포인터 변수
};
2. 노드 추가/삽입
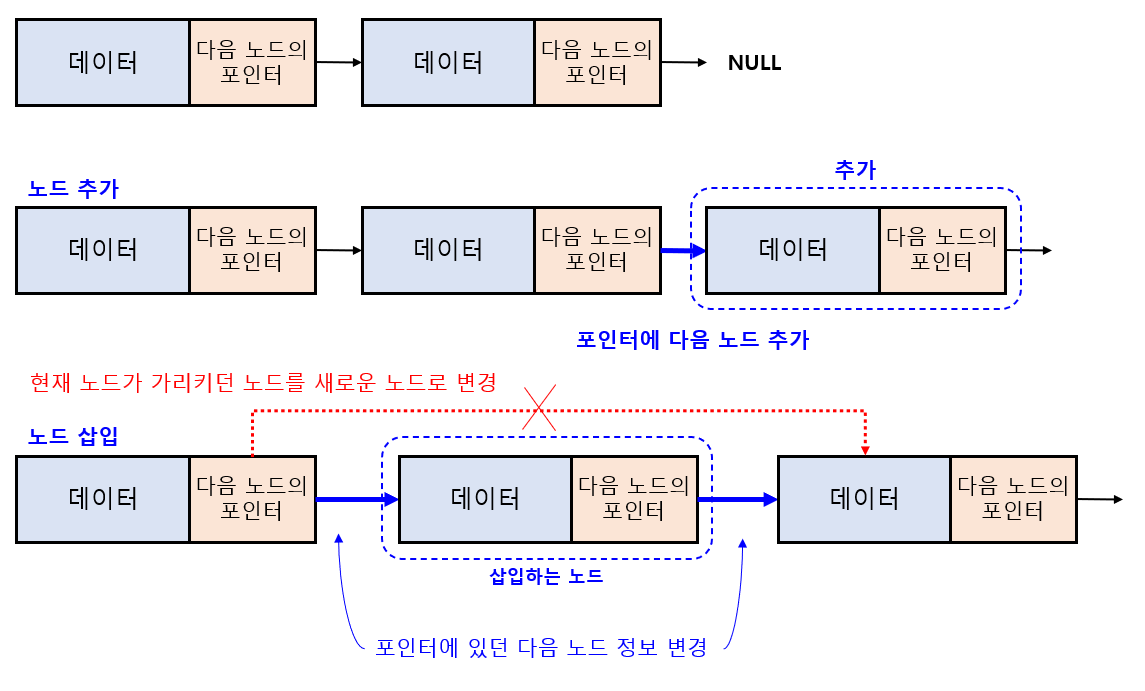
리스트에 노드를 추가하기 위해서는 아래와 같은 작업을 수행하야 합니다.
- 새로운 노드를 생성
- 테일 노드의 포인터에 새로운 노드 주소를 입력
만약 위 그림의 제일 밑의 케이스와 같이 리스트 중간에 새로운 노드를 추가하고 싶으면 아래와 같은 작업을 수행해야 합니다.
- 새로운 노드가 가리키는 포인터의 포인터를 현재 노드가 가리키는 포인터로 입력
- 현재 노드가 가리키는 포인터를 새로운 노드의 주소값으로 변경
위 동작을 C++로 구현하면 아래와 같습니다.
// 1. 새로운 노드 생성
Node* CreateNode(int newData)
{
Node* newNode = new Node; // 동적 할당을 활용해 새로운 노드 생성
newNode->data = newData; // 데이터 추가
newNode->pNextNode = NULL; // 다음 노드의 포인터, 노드를 추가할 때 새로운 노드는 테일 노드가 되므로 NULL포인터 입력
return newNode; // 반환
};
// 2. 리스트 끝에 새로운 노드를 추가
void AddNode(Node** List, Node* newNode)
{
// 리스트에 노드가 없는 경우(새로운 리스트를 생성하는 경우)
if (*List == NULL)
{
// 새로운 노드를 List의 Head 노드로 설정
*List = newNode;
}
else
{
// 테일 노드로 찾아가기
Node* Tail = *List; // 헤드로부터 순서대로 찾기 위해 헤드 노드의 주소값을 받아옴
while (!Tail->pNextNode == NULL)
{
Tail = Tail->pNextNode; // 테일 노드 가 나올 때 까지 다음 노드로 이동
}
Tail->pNextNode = newNode; // 현재 테일 노드의 포인터에 새로운 노드 주소를 입력
}
}
// 3. 리스트 중간에 새로운 노드추가
void InsertNode(Node* currentNode, Node* newNode)
{
// currentNode 뒤에 newNode를 추가
newNode->pNextNode = currentNode->pNextNode; // 새로운 노드의 포인터에는 현재 노드가 가리키는 노드의 주소값 추가
currentNode->pNextNode = newNode; // 현재 노드의 포인터에 새로운 노드의 주소값 추가
}
3. 노드 탐색
Linked List 구조에서 원하는 값을 찾기 위해서는 헤드부터 다음노드로 넘어가면서 원하는 값을 찾아야 합니다.
배열의 경우 인덱스를 입력하면 원하는 값으로 바로 갈 수 있지만, Linked List 구조에서는 헤드노드에 대한 정보만 가지고 있기 때문에 헤드노드부터 순차적으로 찾아가는 수 밖에 없습니다. 이러한 구조적 특징때문에 리스트의 원하는 값을 찾기 위해 많은 연산이 필요한 단점이 있습니다. 최악의 경우(찾으려는 노드가 테일 노드인 경우) 리스트에 있는 노드 개수만큼 탐색해야 원하는 노드를 찾을 수 있습니다.
// 리스트에서 찾고자 하는 값을 저장한 노드의 주소값을 반환
Node* GetNodeTargetData(Node* Head, int targetData)
{
Node* currentNode = Head; // 헤드로부터 순서대로 찾기 위해 헤드 노드의 주소값을 받아옴
while (currentNode->data != targetData) // 찾고자 하는 값이 나올 때 까지 다음 노드로 이동
{
currentNode = currentNode->pNextNode;
if (currentNode == NULL) // 마지막 노드 까지 왔는데 찾지 못한 경우 NULL 포인터 반환
return NULL;
}
return currentNode; // 원하는 데이터를 찾은 경우 해당 노드를 반환
}4. 노드 삭제
리스트 내의 노드를 삭제하기 위해서는 두 가지 작업이 필요합니다.
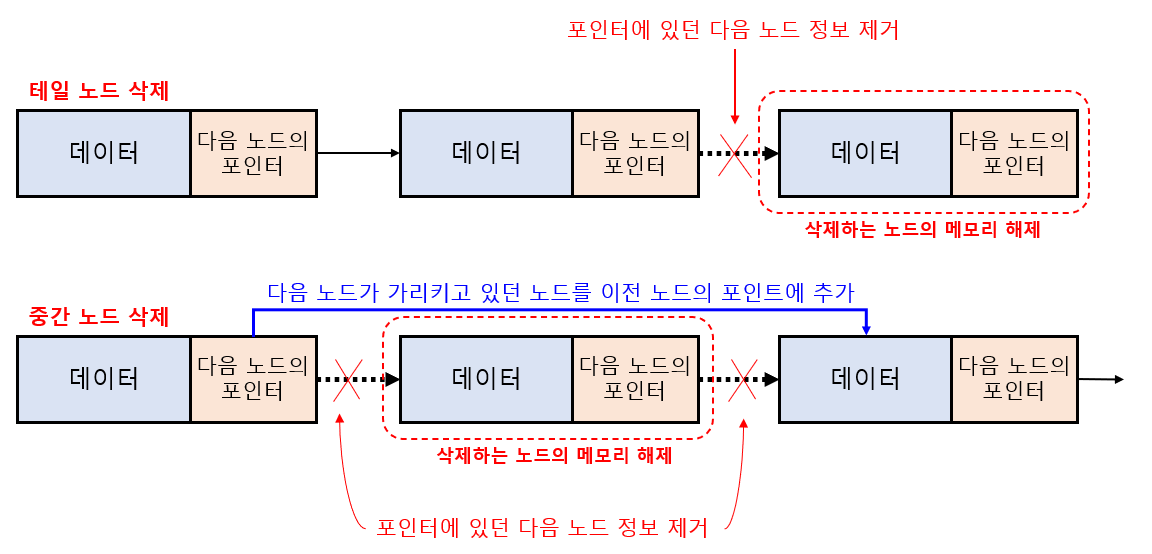
- 삭제 하려는 노드의 이전노드가 삭제하려는 노드의 다음노드를 가리키도록 포인터 변경
- 삭제하려는 노드의 메모리 해제
테일노드 삭제함수와 중간 노드 삭제 함수를 C로 구현하면 아래와 같습니다.
// 노드를 삭제(메모리 해제)
void DeleteNode(Node* deletedNode)
{
delete deletedNode; // 삭제하려는 노드의 메모리 해제
}
// 리스트의 마지막 노드(테일 노드) 제거
void RemoveLastNode(Node* List)
{
Node* preTailNode = List; // 테일 노드의 이전노드
Node* TailNode = preTailNode->pNextNode; // 테일 노드
// 테일 노드의 이전노드 찾기
while (TailNode->pNextNode != NULL)
{
preTailNode = preTailNode->pNextNode;
TailNode = preTailNode->pNextNode;
}
preTailNode->pNextNode = NULL; // 이전 노드를 테일노드로(가리키는 다음 노드를 NULL로)
DeleteNode(TailNode); // 테일 노드의 메모리 해제
}
// 원하는 타겟 노드 삭제
void RemoveTargetNode(Node* List, Node* targetNode)
{
Node* currentNode = List; // 현재 노드부터 지우려는 노드의 이전노드를 찾기
while (currentNode->pNextNode != targetNode)
{
currentNode = currentNode->pNextNode;
}
currentNode->pNextNode = targetNode->pNextNode; // 이전 노드의 포인터를 다음다음 노드로 설정
DeleteNode(targetNode); // 삭제하는 노드의 메모리 해제
}5. 노드 개수 세기
Linked List 구조에서는 헤드노드에 대한 정보만 가지고 리스트에 몇 개의 노드가 있는지에 대한 정보는 가지고 있지 않습니다.
리스트의 노드 개수를 세는 코드를 C++로 구현하면 아래와 같습니다.
// 리스트의 노드 개수 세기
int CountNode(Node* List)
{
int counter = 0;
Node* currentNode = List;
// 현재 노드가 NULL이 될 때 까지 카운트
while (currentNode != NULL)
{
currentNode = currentNode->pNextNode;
counter++;
}
return counter;
}Doubly Linked List
앞에서 소개한 Linked List는 노드가 한방향에 대한 포인터만 가지고 있기 때문에 Singly Linked List라고도 부릅니다. Singly Listed List는 각 노드가 단방향(뒤의 노드)에 대한 정보를 가지고 있기 때문에 특정 노드를 탐색할 때 단방향으로 가야하는 단점이 있습니다.
이러한 단점을 개선하고자 양방향에 대한 정보를 가지고 있는 Linked List 자료구조를 Doubly Linked List라고 합니다. Doubly Linked List의 노드는 다음 노드의 포인터뿐만이 아닌 이전 노드의 포인터 정보도 가지고 있기 때문에 현재 노드에서 앞/뒤 양 쪽 방향에 대해 노드를 탐색할 수 있는 장점이 있습니다. 이러한 점을 이용해 현재 노드의 앞의 값을 가져오는 경우 처음부터 다시 찾아갈 필요 없이 현재 노드에 저장된 포인터를 활용하면 바로 이전노드의 값을 가져올 수 있습니다.

주요 연산 구현
Doubly Linked List에서는 다음노드의 포인터 뿐만이 아닌 이전 노드의 포인터도 가지고 있어야 하기 때문에 Node구조체가 아래와 같이 수정되어야 합니다.
// Doubly Linked List 노드 구조체 구현
struct Node
{
int data; //노드의 데이터를 저장하는 변수
struct Node* pNextNode; // 다음 노드의 포인터를 가리키는 포인터 변수
struct Node* pPreNode; // 이전 노드의 포인터를 가리키는 포인터 변수 (추가)
}; 그 외의 삽입, 삭제 연산을 할 때도 아래와 같이 이전노드에 대한 정보를 입력하는 부분을 추가해야 합니다.
// Doubly Linked List 리스트 중간에 새로운 노드추가
void InsertNode(Node* currentNode, Node* newNode)
{
// currentNode 뒤에 newNode를 추가
newNode->pNextNode = currentNode->pNextNode; // 새로운 노드의 포인터에는 현재 노드가 가리키는 노드의 주소값 추가
currentNode->pNextNode = newNode; // 현재 노드의 포인터에 새로운 노드의 주소값 추가
// 새로운 노드와 그 다음 노드에 이전 노드에 대한 포인터 정보 추가
nextNode = newNode->pNextNode
newNode->pPreNode = currentNode
nextNode->pPreNode = newNode
}
그 외 탐색, 삭제, 노드 개수세는 연산은 Singly Linked List와 동일합니다.
Circular Linked List
마지막으로 살펴볼 Linked List구조는 Circular Linked List입니다. Circular Linked List는 Doubly Linked List에서 헤드와 테일을 연결한 구조입니다. 이름 그대로 머리와 꼬리를 연결하여 아래 그림과 같은 원형으로 만든 Linked List구조입니다.
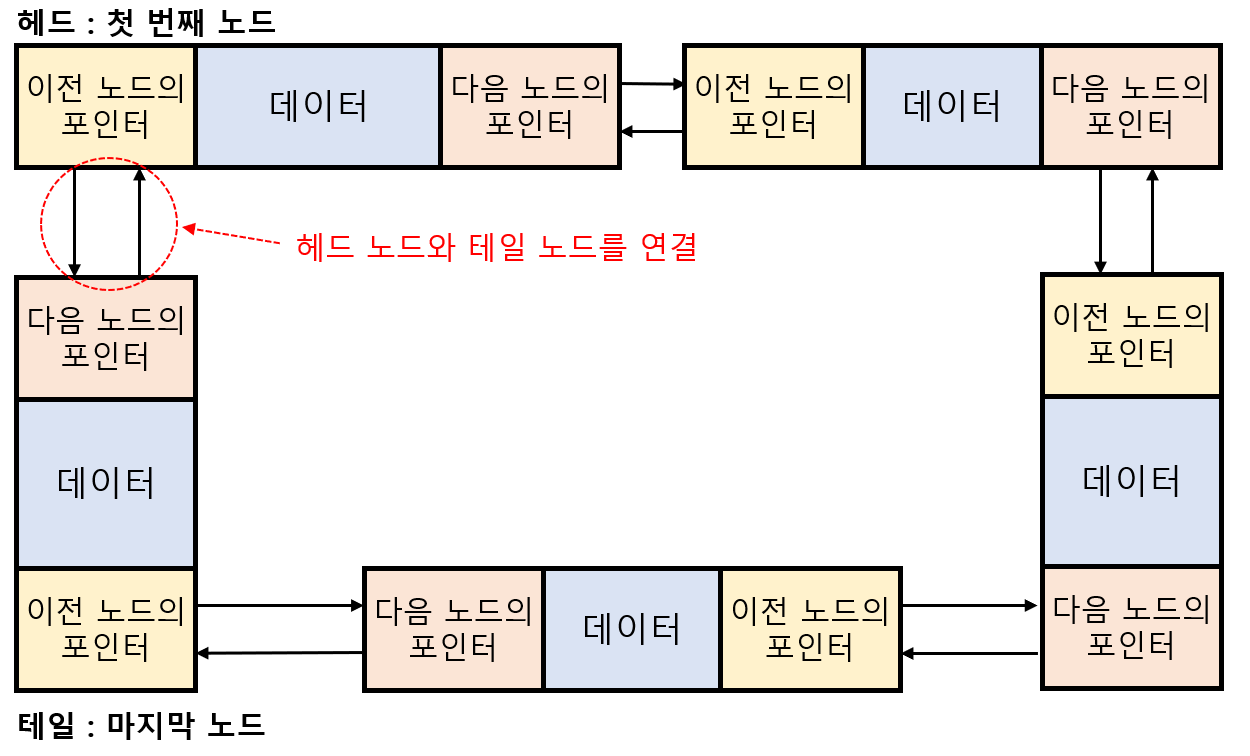
주요 연산 구현
Circular Linked List를 구현할 때 주의해야할 점은 헤드 노드와 테일 노드를 연결하는 것 입니다. 따라서 새로운 노드를 제일 끝에 추가하려면(새로운 테일 노드를 추가) 아래와 같은 수정이 필요합니다.
// Circular Linked List 리스트 끝에 새로운 노드를 추가
void AddNode(Node** List, Node* newNode)
{
// 리스트에 노드가 없는 경우(새로운 리스트를 생성하는 경우)
if (*List == NULL)
{
// 새로운 노드를 List의 Head 노드로 설정
*List = newNode;
}
else
{
// 테일 노드로 찾아가기
Node* Tail = *List; // 헤드로부터 순서대로 찾기 위해 헤드 노드의 주소값을 받아옴
while (!Tail->pNextNode == *List) // 테일 노드는 NULL포인터가 아닌 헤드노드를 다시 찾는 순간으로 수정
{
Tail = Tail->pNextNode; // 테일 노드 가 나올 때 까지 다음 노드로 이동
}
Tail->pNextNode = newNode; // 현재 테일 노드의 포인터에 새로운 노드 주소를 입력
// Circular에서 추가
newNode->pPreNode = Tail; // 새로운 테일 노드의 이전 노드 포인터 업데이트
newNode->pNextNode = *List; // 새로운 테일 노드의 다음 노드 포인터 업데이트(헤드를 가리킴)
*List->pPreNode = newNode; // 헤드 노드의 이전 노드 포인터 업데이트
}
}참고자료
