Pagination vs 무한 스크롤
Pagination
페이지네이션은 페이지 단위로 분할하는 방법입니다.
즉, 아래의 사진과 같이 웹 사이트 내에서 보려는 목록이 많은 경우 페이지 단위로 분할하여 사용자가 필요한 부분만 볼 수 있도록 도와줍니다.

이미지 출처 : 네이버 검색 페이지 결과 일부
무한 스크롤
무한 스크롤은 스크롤을 내릴때마다, 새로운 컨텐츠가 계속해서 로드되는 방식입니다.
흔히 인스타그램에서 피드를 보기 위해서 계속해서 내리면 새로운 컨텐츠가 나오는 형식입니다.
Page vs Slice
Spring에서는 Page와 Slice를 통해 각각 페이지네이션, 무한 스크롤 방식을 위한 정보(총 페이지, 마지막 페이지 여부 등)가 담긴 데이터를 제공해줄 수 있습니다.
Page와 Slice에 공통적으로 필요한 정보가 있습니다.
- page : 페이지 번호
- size : 한 페이지에 불러올 데이터 건수
- sort : 정렬 조건
Pageable의 구현체인 PageRequest를 통해서 page, size, sort를 입력받음을 알 수 있습니다.
No-offset
기존의 페이징은 offset과 limit을 사용해서 페이징할 범위를 정한다. 이 방식은 초반에는 효율이 나쁘지 않지만 뒤로 갈수록 효율이 급격히 떨어진다는 단점이 있다. 왜 이런 현상이 발생하는지 알아보자.
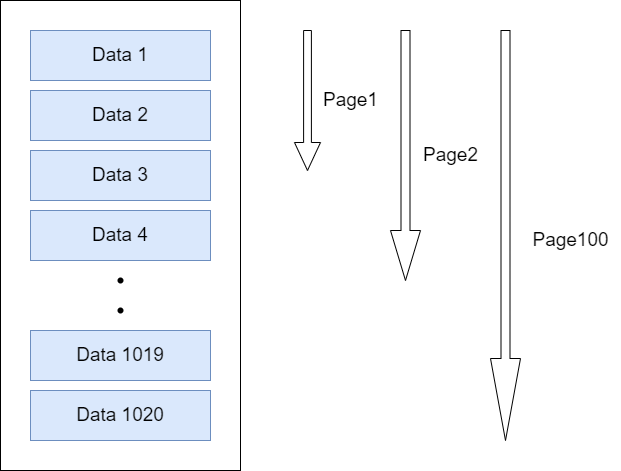
만약 offset이 1000이고 limit이 20이라면 맨 뒤의 20개만 DB에서 가져올 것이라고 생각하지만
실제로는 위의 그림처럼 offset + limit 까지의 데이터를 DB에서 전부 다 가지고 온 후에 limit 만큼만 우리에게 반환해주는 방식으로 동작한다. 1020개의 데이터를 가져왔다면 1000개는 그냥 버리게 되는 것이다.
페이지가 뒤로 갈수록 읽어야 할 행의 개수는 기하급수적으로 늘어날 것이기 때문에 우리는 성능을 최적화 할 수 있는 방안이 필요하다. 이때 사용하는 것이 No-Offset 방식이다.
No-Offset 방식은 조회 시작 부분을 인덱스로 빠르게 찾아서 매번 첫 페이지만 읽도록 하는 방식이다.
구현
테이블 설명
정보게시판을 공감순으로 조회하는 API를 만들려한다. 조회하는 API에 동적쿼리를 넣어 통합검색 또한 함께할거다.
Controller

검색을 위한 condition과 공감인 love, id값을 파라미터로 하여 Controller를 구성하였습니다.
Service

page를 항상 0으로 고정하는 이유는 No-offset 방식이기 때문이다.
기존 offset 방식이 "n페이지 데이터 m개 주세요"와 같은 방식이라면,
No-offset 방식은 "공감수가 k 보다 작은 데이터 m개 주세요"와 같은 방식이다.
따라서 기존에 0페이지, 1페이지, 2페이지로 가져오던 것을 공감순을 기준으로 가져오기에 항상 0번째 페이지를 조회하도록 하는 것이다.
Repository
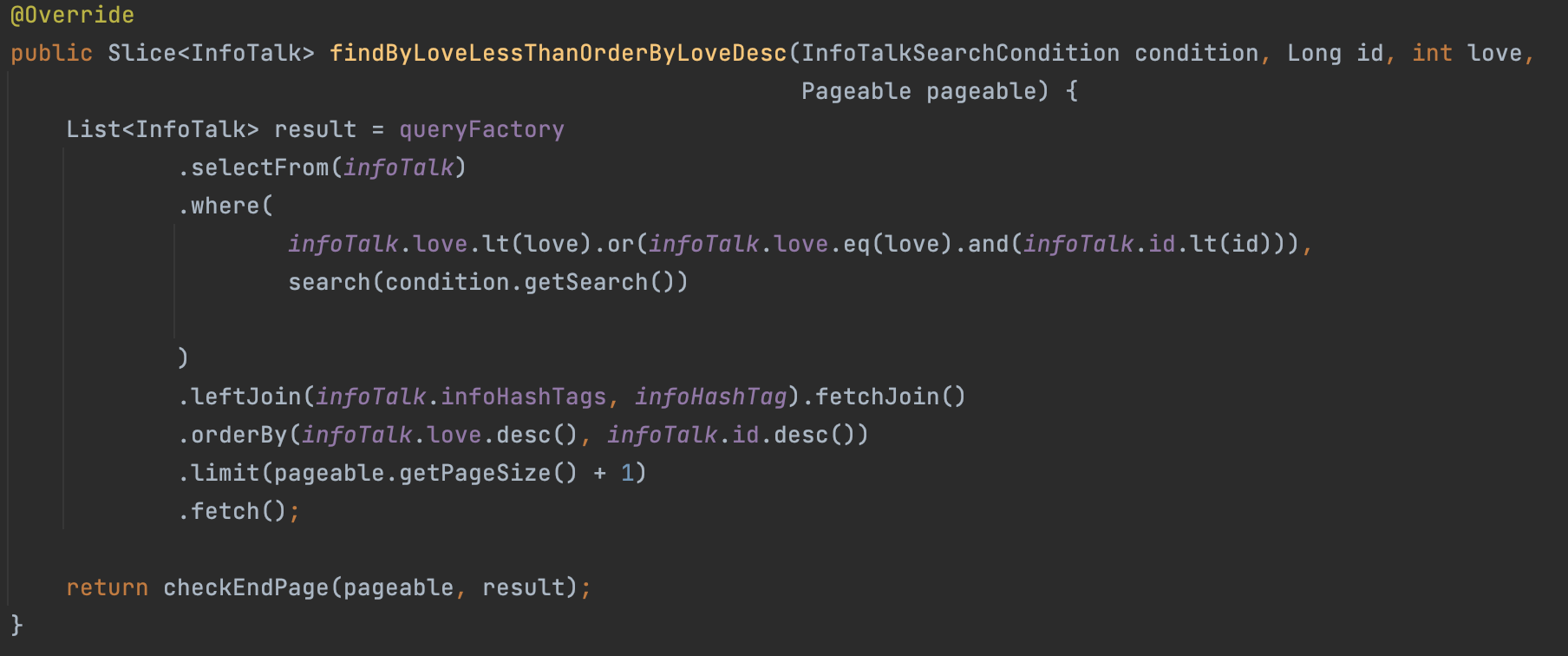

정보게시판 테이블과 해시태그 테이블을 Left Join 한 후 fetchJoin을 통해 N+1문제가 일어나지 않도록 우선 쿼리를 만들었으며, 공감순으로 하되 공감이 같으면 Id 내림차순으로 하여 보다 최신글이 먼저 조회되도록 구성하였다.
동적쿼리로 검색을 하는 부분또한 제목과 내용은 contains을 사용하고 해시태그는 eq을 사용하여 통합검색처리를 하였다.
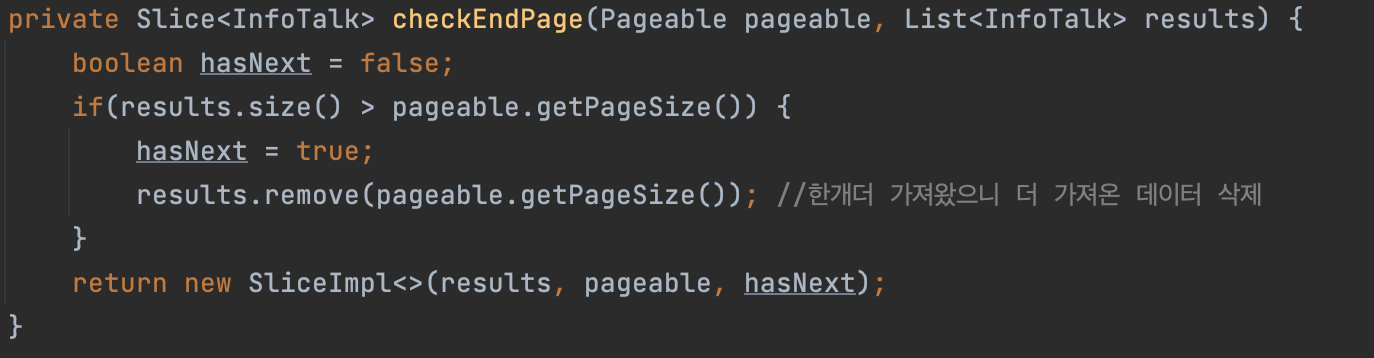
Slice가 무한 스크롤 방식에 최적화된 이유 중 하나가 SliceImpl을 생성할 때, 애초에 파라미터로 다음 페이지가 있는지 여부를 넣어줄 수 있기 때문이다.
클라이언트에게서 요청으로 들어온 pageable 객체의 pageSize에 +1을 해서 limit을 걸었다.
만약 지금 페이지가 마지막 페이지가 아니라면 요청으로 들어온 pageable의 pageSize보다 results의 size가 더 클 것이다. 하지만 만약 현재 페이지가 마지막이라면 +1해서 조회했더라도 result의 size가 더 크지는 않을 것이다.
실제로 반환할때는 result에 확인용으로 추가한 데이터를 remove해준 뒤, 최종적으로 SliceImpl을 반환하면 된다.
