VGG 논문리뷰
Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
1. Introduction
컨볼루션 신경망의 깊이가 성능에 미치는 영향을 고정된 필터로 깊이를 늘려가면서 증명합니다.
The effect of the convolutional network depth on its accuracy in the large-scale image recognition setting.
- increasing depth
- with very small 3x3 convolution filters
2. VGG Configurations
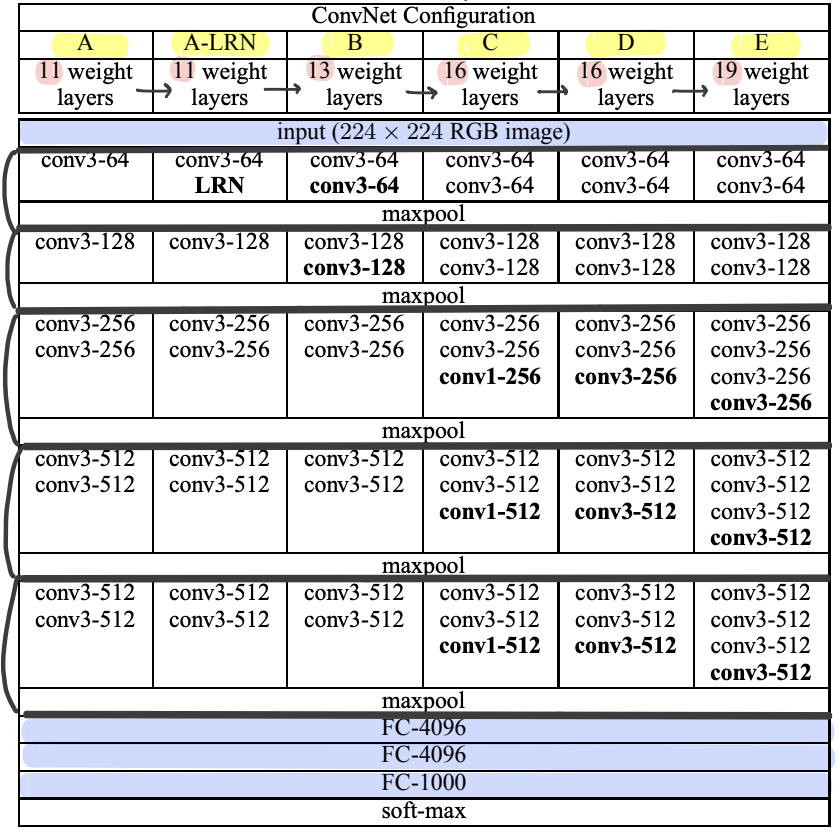
1. Input : 224x224 RGB image
2. 13 Convolution Layers + 3 Fully-connected Layers
- Convolutional Layer (3x3 filter, stride = 1, padding = True) : 레이어 갯수에 변화를 주어가며 정확도에 대한 신경망 깊이의 영향력을 실험했고, 패딩을 적용해 이미지 사이즈 유지
*1x1 Conv Layer (1x1 filter, stride = 1)도 사용 - Pooling Layer (2x2 filter, stride = 2) : max-pooling으로 고정적으로 5개 층 사용
- Fully-Connected Layer (4096 → 4096 → 1000) : 처음 두개 층은 4096개 채널, 마지막 층은 1000개 채널
- Soft-max Layer : 1000개의 채널가져서 이미지 1000개 클래스에 대한 classification 수행
| Configurations | Layer 수 | 이전 네트워크와의 차이점 |
|---|---|---|
| A | 8 conv. and 3 FC layers (11) | |
| A-LRN | 8 conv. and 3 FC layers (11) | LRN 사용 (여기서만 사용) |
| B | 10 conv. and 3 FC layers (13) | conv3 2개추가 |
| C | 13 conv. and 3 FC layers (16) | conv1 3개추가 |
| D (VGG16) | 13 conv. and 3 FC layers (16) | C의 conv1 -> conv3로 수정 |
| E (VGG19) | 16 conv. and 3 FC layers (19) | conv3 3개추가 |
⭐ 3x3 필터를 고정적으로 사용하였다
VGG 모델 이전에는 비교적 큰 Receptive Field를 갖는 11x11필터나 7x7 필터를 사용하였다. 만약 7x7 인풋이미지를 각 다른 크기의 필터를 각각 연산한 결과는 다음과 같다.
[3x3필터로 3번 conv] = [5x5필터로 2번 conv] = [7x7필터로 1번]
-> 각 연산 결과로 같은 크기의 피처맵이 도출되지만 이 논문은 연산과정에서의 차이점을 이용하였다.
- 결정함수의 비선형성 증가 (increasing the non-linearity of the decision function)
3x3필터를 사용했을 때 가장 많이 비선형 함수인 ReLU를 거치게 된다. 1-layer 7x7 필터링의 경우 한 번의 비선형 함수가 적용되는 반면, 3-layer 3x3 필터링은 세 번의 비선형 함수가 적용되기 때문이다. 따라서, 레이어가 증가함에 따라 비선형성이 증가하게 되고 이것은 모델의 특징 식별성 증가로 이어진다.
→ 1x1 필터를 사용하여 non-linear을 강화시켜 3x3필터와 비교하기도 함 (configuration C와 D 참조)
- 학습 파라미터 수의 감소 (decreasing the number of parameters)
Convolutional Network 구조를 학습할 때, 학습 대상인 가중치(weight)는 필터의 크기에 해당한다. 따라서, 7x7필터 1개에 대한 학습 파라미터 수는 49이고 3x3 필터 3개에 대한 학습 파라미터 수는 27(3x3x3)이 된다. 파라미터 수가 크게 감소하는 것을 알 수 있다. 줄어든 파라미터는 오버피팅을 줄여준다는 장점이 있다.
3. Framework
1. Training

1. Krizhevsky et al.(2012)와 같은 방식으로 Training 진행
2. ⭐️Training image 처리
- Rescaling & Cropping
→ isotropically-rescaled
: 인풋 이미지의 작은 변을 지정한 S값으로 줄이고 다른 변도 비율에 맞게 줄여 rescale (S는 224보다 같거나 큰 숫자로 지정함)- single-scale training : S를 256와 384로 고정해 이미지를 줄이고 224x224에 맞추어 랜덤하게 자름 → 먼저 S = 256으로 설정하여 학습시키고 도출된 가중치값을 기반으로 S=384로 설정해 또 학습시킴
- multi-scale trainig: S를 고정시키지 않고 256~512값 중에서 랜덤하게 값을 설정하여 이미지 조정하고 랜덤하게 자름. 보통 객체들은 같은 사이즈가 아니기 때문에 이 방법이 학습 효과가 더 좋다고 함 → scale jittering
- Data augmentation: random horizontal flipping & random RGB color shift
2. Testing

-
Testing image 처리
- Testing image rescaling Training image를 rescaling 할때 S값을 지정한 것처럼 Testing image를 rescaling 할 때 Q값을 지정해 rescaling해주었다. Q값은 S값과 같을 필요는 없고 오히려 여러 Q값을 사용하는 것이 더 좋은 성능을 내기도 한다.
- data augmentation → Multi-crop evaluation
: 하나의 이미지 속에서 여러이미지를 추출하는 것으로 GoogleNet에서 사용한 방식이다. 이 논문에서는 한 이미지에서 150장 이미지를 추출하였다.
- Testing image rescaling Training image를 rescaling 할때 S값을 지정한 것처럼 Testing image를 rescaling 할 때 Q값을 지정해 rescaling해주었다. Q값은 S값과 같을 필요는 없고 오히려 여러 Q값을 사용하는 것이 더 좋은 성능을 내기도 한다.
-
⭐️ FC layer 대신 Fully-convolutional network 으로 적용
Testing할 때는 Training할 때와 다른 CNN구조를 사용한다. FC layer를 사용하면, FC layer의 가중치 개수가 고정되어 있기 때문에 바로 앞 레이어의 피처맵의 크기도 고정되며, 연쇄적으로 각 레이어의 피처맵 크기와 인풋 이미지의 크기 역시 고정된다. 따라서 인풋이미지가 변경되면 size mismatch 에러가 난다. 따라서 FC layer를 Conv. layer로 바꾸어 이 문제를 해결한다.
이 논문에서는 첫번째 FC layer를 합성곱 연산을 통해 도출되는 피처맵 크기와 같은 7x7 conv layer로 바꾸고 마지막 두개 FC layer는 1x1 conv layer로 변경하였다. 이를 통해 모델이 자르지 않은 원본 이미지(uncropped image)에 모두 적용될 수 있다고 한다. 모델을 적용한 결과를 class score map이라고 한다. (Dense evaluation 개념 적용) -
Fixed-size vector 도출
하지만 최종 피처맵이 1x1(fixed-size vector)가 되어야하는데 그렇지 않다는 문제가 생긴다. 따라서 도출된 피처맵을 spatially averaged(sum-pooled)연산을 하여 최종 피처맵을 구한다. 마지막 소프트맥스 함수에 적용할 수 있다.
4. Experiments
- 데이터셋: ILSVRC-2012 dataset (1000개 클래스의 이미지들)
- 성능지표
- top-1 error: proportion of incorrectly classified images (잘못 분류된 이미지의 비율)
- top-5 error : proportion of images such that the ground-truth category is outside the top-5 predicted categories (실측 범주가 상위 5개 예측범주를 벗어난 비율)
- 결과
- Single-scale evaluation
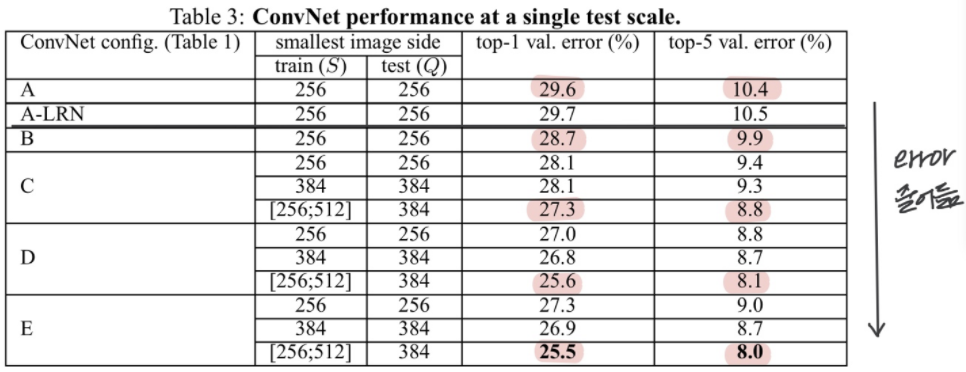
1) LRN을 사용하는 것의 성능 차이가 나지 않아 LRN을 사용하지 않고 실험 진행
2) ⭐️확실히 깊이가 깊어질수록 에러율이 적게 나타남
*B < C : 1x1필터로 층을 더하여 비선형성을 추가한 C의 성능이 좋음
*C < D : 같은 층일 때 1x1 필터를 3x3으로 바꿨을 때 공간 및 위치정보의 특징을 더 잘 추출(capture spatial context)해주기 때문에 D가 더 좋은 성능을 보임
3) 각 모델의 S가 [256;512]인 부분이 가장 오류율이 낮게 나타나는 것을 보아 데이터를 multi-scale training했을 때 가장 좋은 성능을 보임을 알수 있음
- Multi-scale evaluation: effect of scale jittering at test time
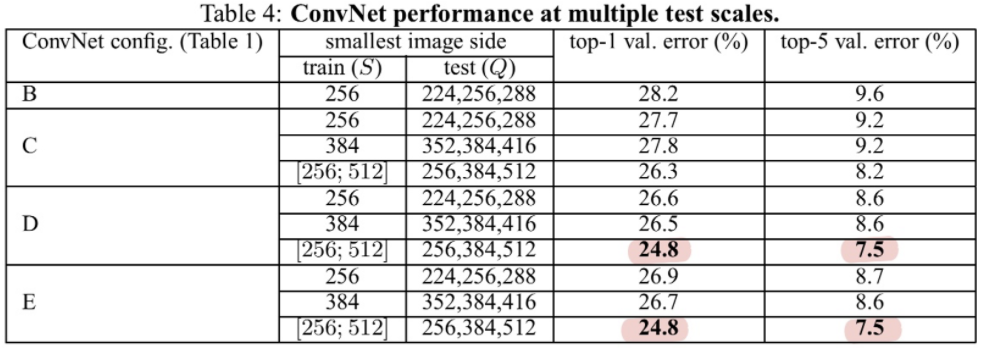
1) 앞의 single-scale evaluation보다 전체적으로 더 좋은 성능을 보이고 있음
2) 여기서도 가장 깊은 네트워크인 D, E의 성능이 가장 높게 나타났고 multi-scale의 결과가 더 좋음
3) Dense ConvNet evaluation과 Multi-crop evaluation을 비교했을 때 multi-crop이 약간 더 좋은 성능을 보였지만, 두 방법을 같이 썼을 때 가장 낮은 오류율을 보였다. 이에 두 가지 방법의 평균을 이용해 두가지 방식을 섞은 새로운 방식인 ConvNet fusion에 대해 오류율 6.8%라는 결과를 보이고 있다.
4) 당시 나왔던 모델들과 비교했을 때 GoogleNet에 이어 두번째로 성능이 좋은 결과를 낼 수 있었음을 보인다.
- Single-scale evaluation
5. Conclusion
representation depth is beneficial for the classification accuracy, and that state-of-the-art performance on the ImageNet challenge dataset can be achieved using a conventional ConvNet architecture with substantially increased depth.
