개발자 역량에서 대용량 데이터 경험이 참 중요하다.
하지만 왠만한 서비스 기업에 들어가지 않거나 그럴만한 서비스를 만들지 못하면 사실상 대용량 데이터 경험이 쉽지 않다.
이번에는 실제 서비스 처럼 대용량 트래픽은 경험해보지 못하지만 최대한 따라잡아보자
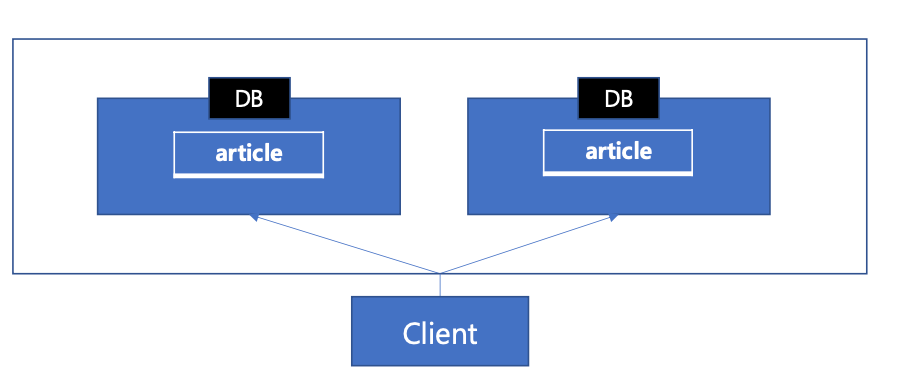
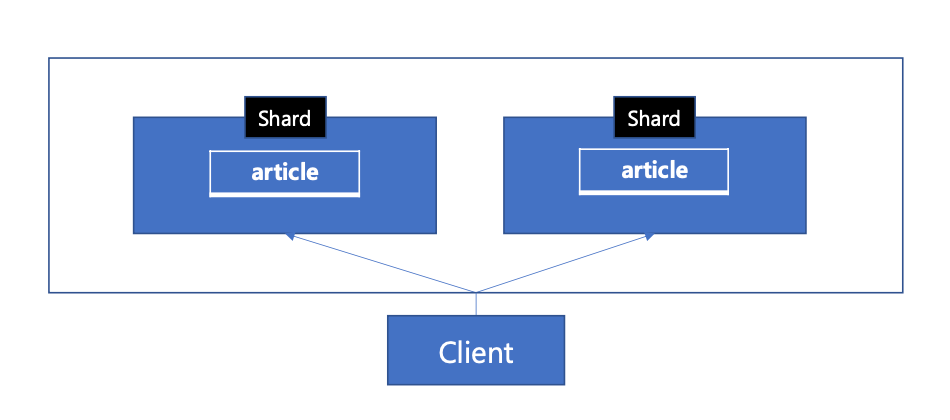
샤딩
- 우리는 샤딩을 이용하여 데이터를 여러 DB에 분산할 수 있다. 각각 샤딩된 데이터 단위를 샤드라고 부른다.
- 샤딩: 데이터를 여러 데이터베이스에 분산하여 저장하는 기술
- 샤드 : 샤딩된 각각의 데이터 단위
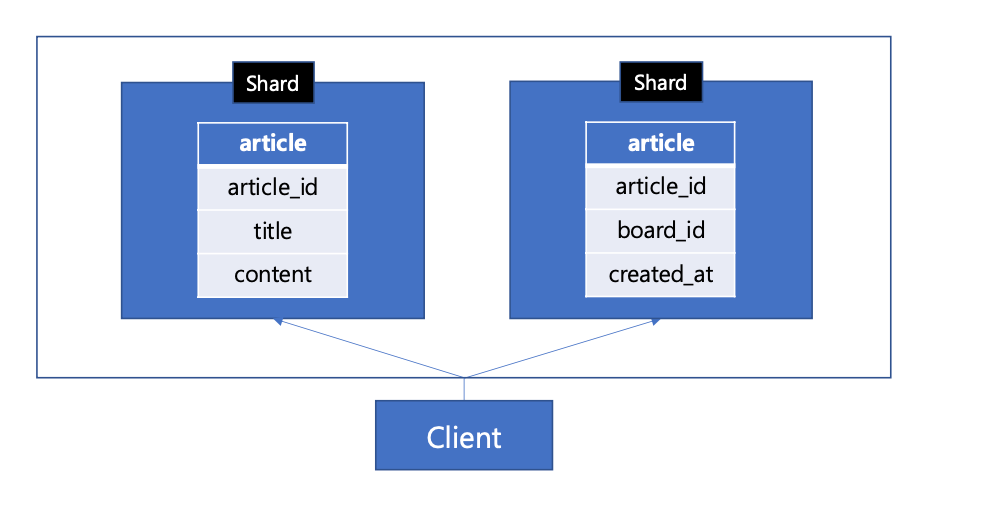
- 수직샤딩: 데이터를 수직으로(컬럼단위)로 분할
- 데이터의 분리로 인해 조인 또는 트랜잭션관리 포인트가 늘어남, 수평적 확장에 제한이 있다.
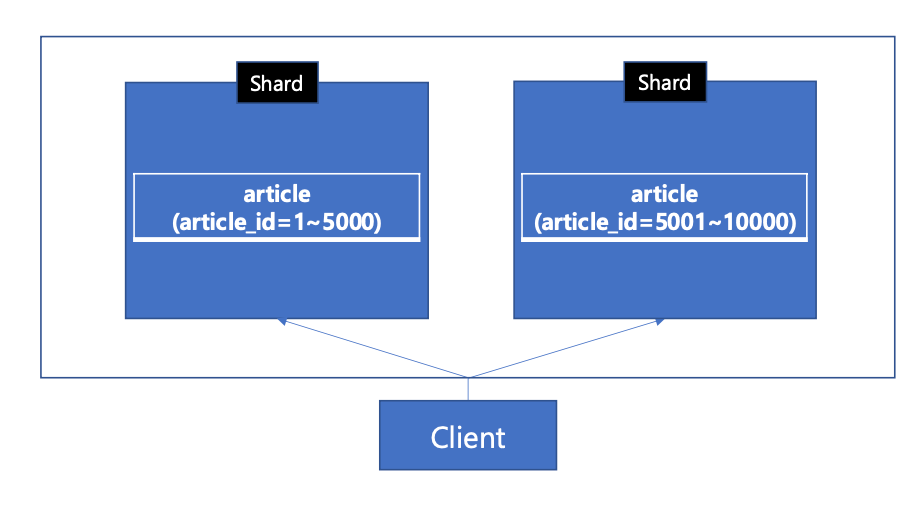
- 수평샤딩: 데이터를 수평(행단위)로 분할
- 분산 저장되므로 성능 및 공간이점이 생기지만 데이터 분리로 조인 또는 트랜잭션 관리가 복잡해질 수 있다.
-
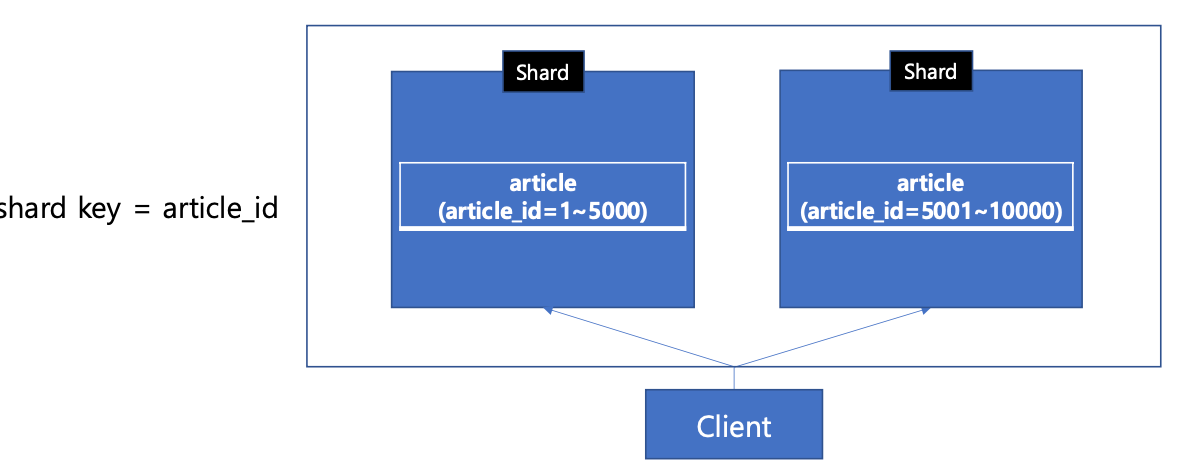
범위기반샤딩: 데이터를 특정값(샤드키)에 따라 분할하는 방법
-
범위 데이터 조회 유리, 하지만 데이터 쏠림현상 발생 가능
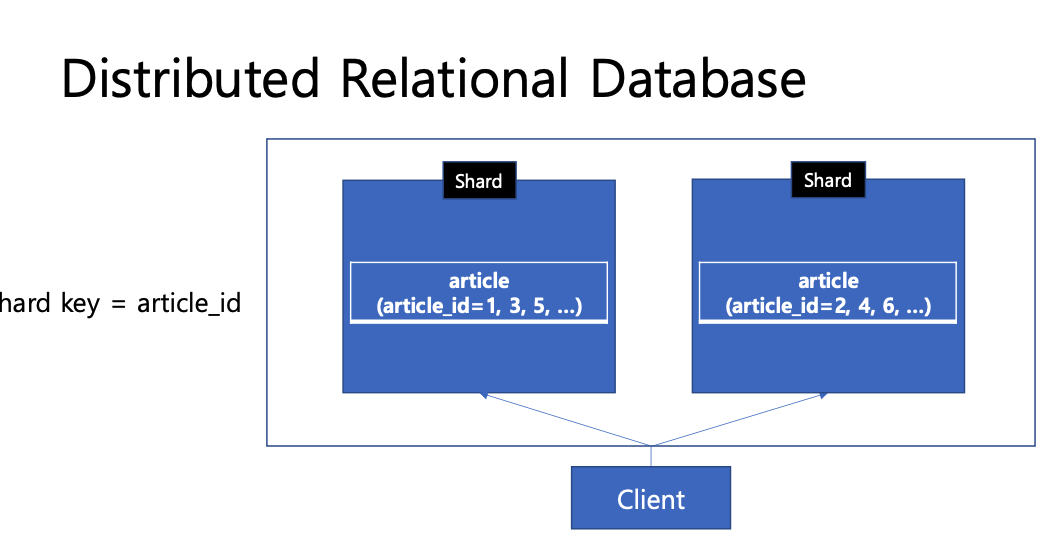
- 해시 샤딩: 데이터를 특정 샤드키의 해시 함수에 따라 분할하는 기법
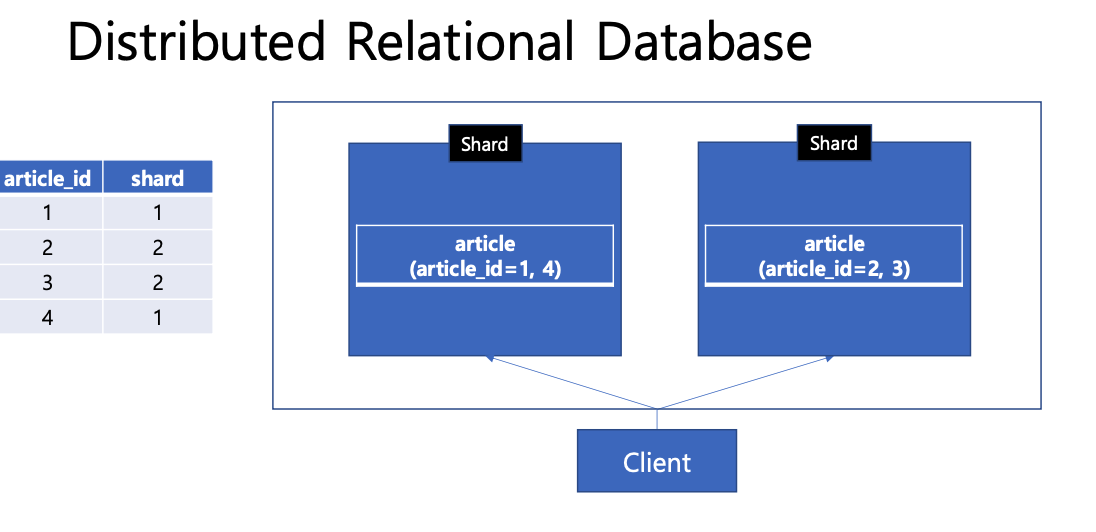
- 디렉토리 기반 샤딩: 매핑 테이블을 이용하여 각 데이터가 저장된 샤드를 관리한다.
물리적 샤딩
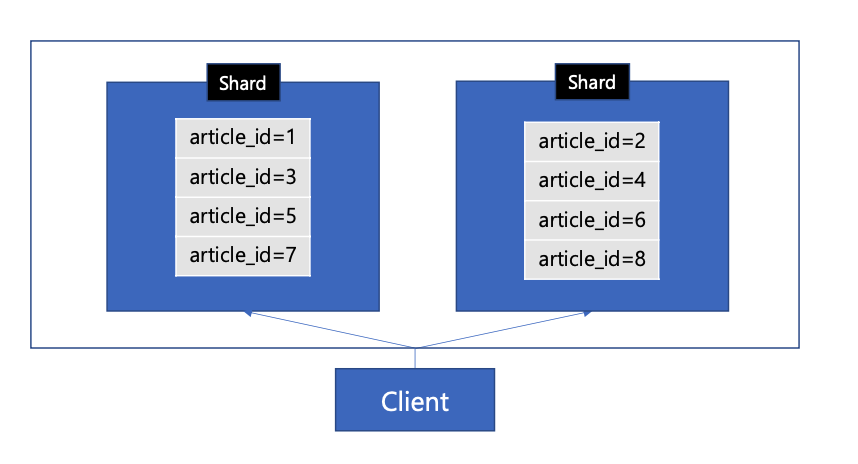
- 물리적 샤드가 2개인 상황에서 데이터가 더 늘어나 샤드를 더늘러야 하면
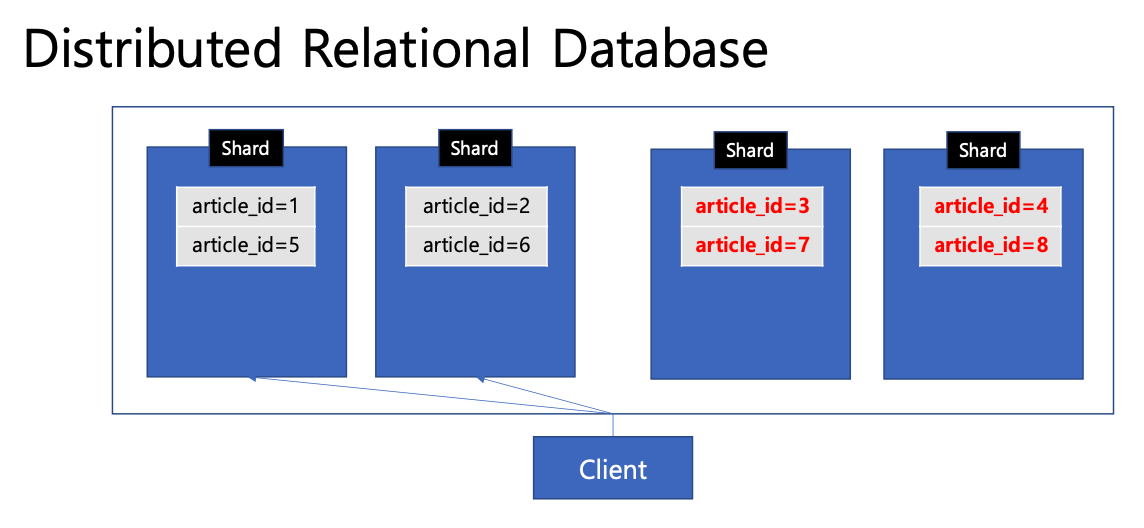
- client는 이제 4개의 샤드로 요청해야 하므로 client의 변경도 필요함
논리적 샤딩
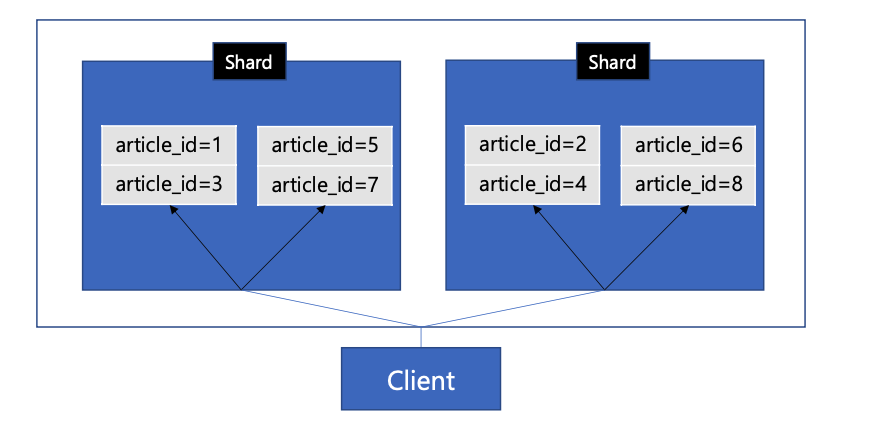
-
실제 물리적인 샤드의 개수와 상관없이, 개념적으로 데이터 분할하는 가상의 샤드가 4개 있다고 가정해 보자.
-
물리적 샤드는 2개지만 client는 4개의 샤드가 있다고 인지함!
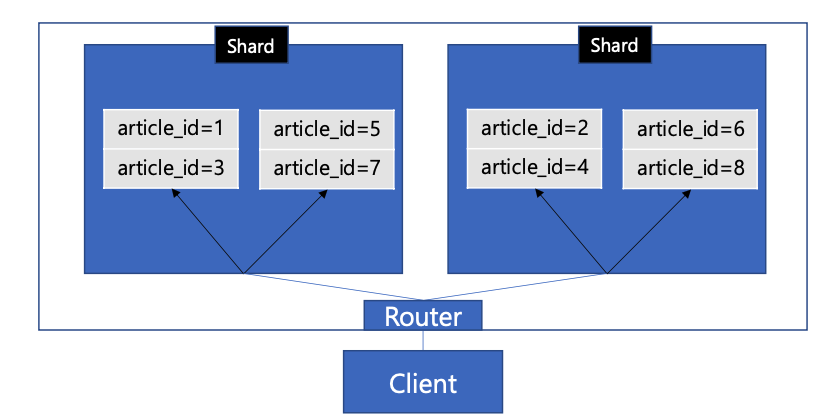
-
client가 요청한 논리적 샤드가 어떤 물리적 샤드에 속하는지 알아야함
-
그러기위해 db 시스템 내부 또는 그 중간에 라우터를 만들 수 있다.
-
클라이언트 -> 라우터에게 요청 -> 라우터는 물리적 샤드로 라우팅
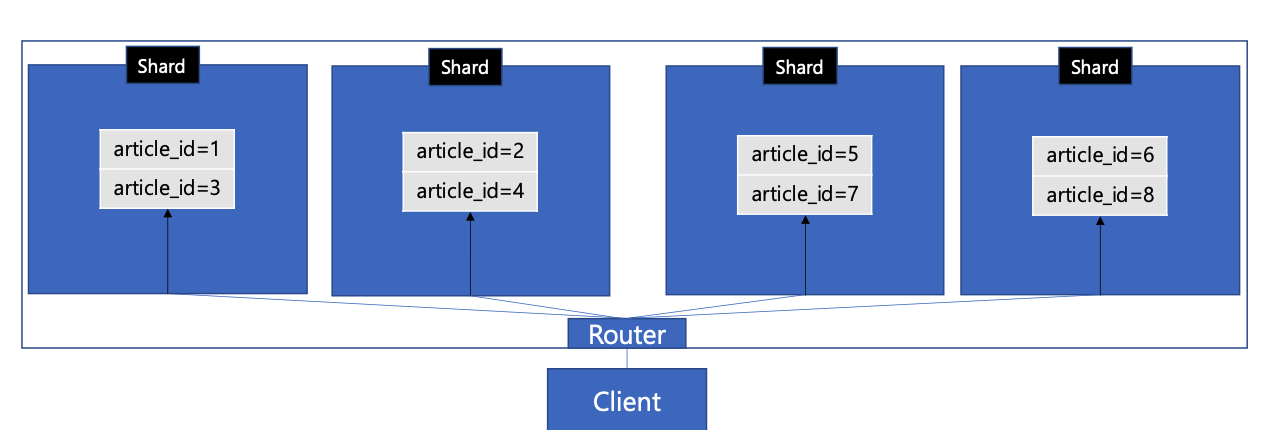
- 물리적으로 늘어나도 라우터 설정만 바꿔주고 client는 변경이 필요 없다
데이터 복제
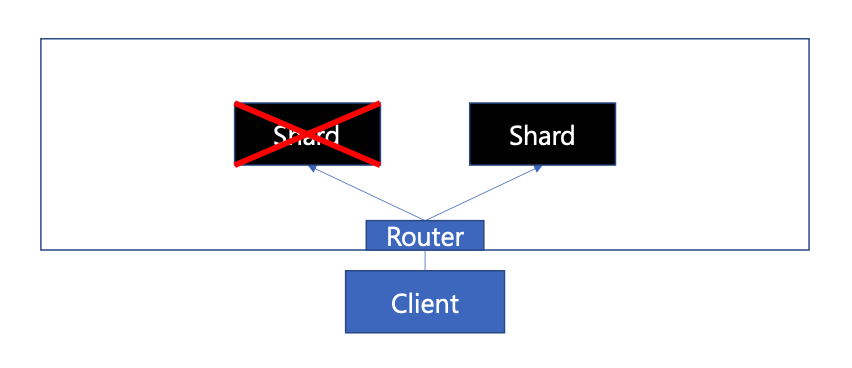
- 한쪽 샤드가 문제가 일어날 경우를 대비해
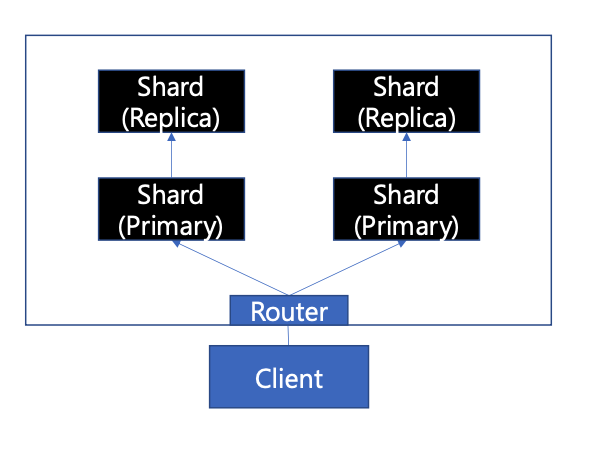
- 이렇게 복제본을 둬 한쪽에 문제가 일어날 경우 대처가 가능하다. 동기적으로 처리시 데이터 일관성을 보장하나 쓰기 성능이 저하되며 비동기적으로 사용할 경우 성능은 유지되지만 데이터 일관성이 떨어질 수 있다.
실습
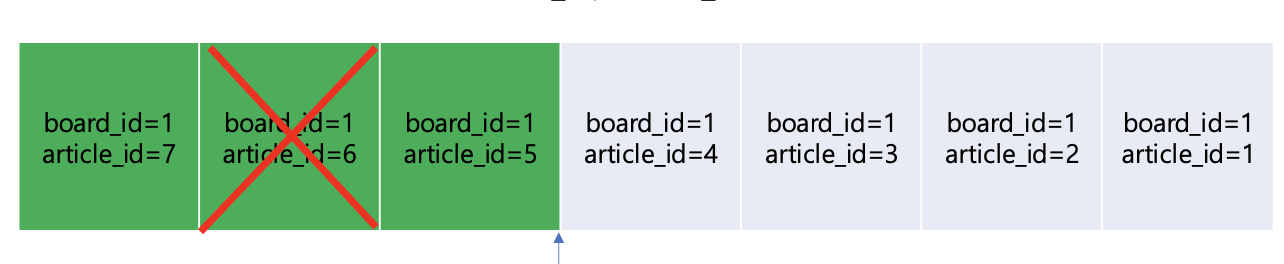
- 게시글이 N개의 샤드로 분산되는 상황을 고려한다.
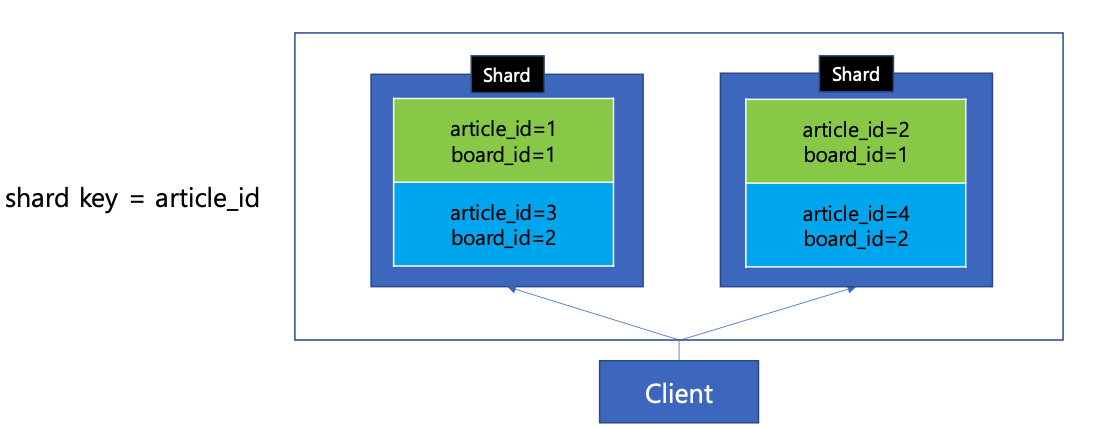
- 게시판 게시글 조회시 모든 샤드에 조회 요청을 해야함
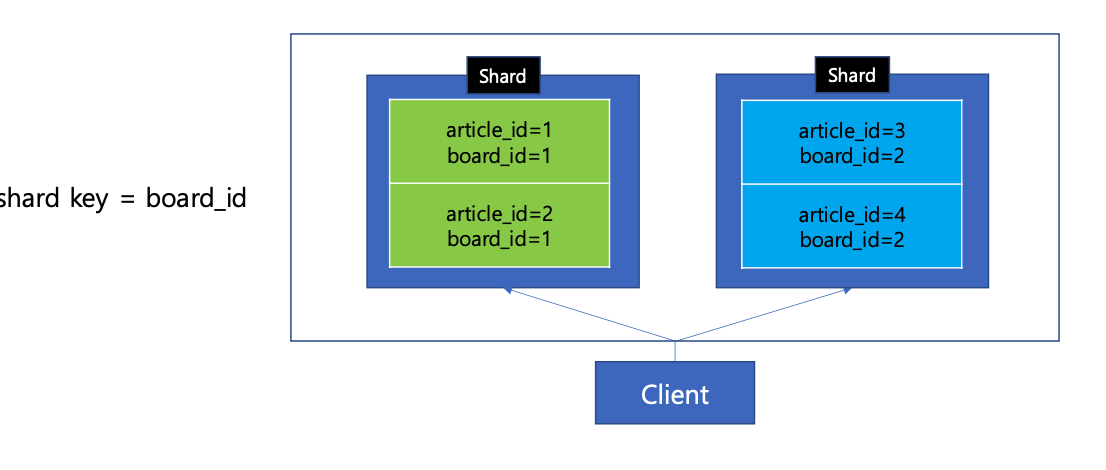
- 이러한 특성상 샤드키는 boardId로 한다. (같은 영역으로 묶기)
-
AutoIncrement는 사용하지 않고 snowflake를 사용한다
-
snowflake는 분산 시스템에서 고유한 오름차순을 위해 고안된 알고리즘
페이징
-
페이징 방식은 크게 두가지로 페이지 번호, 무한 스크룰로 나뉘어진다
-
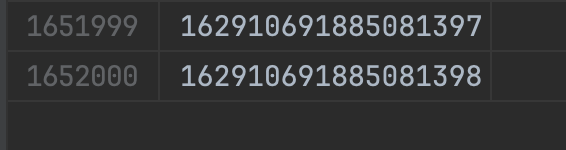
테스트 데이터는 대략 160만건으로 준비했으며 페이지당 30개의 게시글이 출력된다는걸 가정한다.


-
데이터가 그렇게 많지않아 대략 1초정도 걸렸지만 데이터가 더 많았다고 가정할 경우 더 오래 걸릴것이다. explain으로 보면 type=ALL 이란게 있는데 이건 풀스캔을 의미한다.
-
Extras = Using where; Using filesort ->
데이터가 많기 때문에 메모리에서 정렬을 수행할 수 없어서,
파일(디스크)에서 데이터를 정렬하는 filesort 수행.
인덱스
-
B+tree/Hash/LSM tree/R tree/Bitmap 등 다양한 자료구조
-
RDB에서는 주로 B+ tree

-
대규모 트래픽을 처리하기 위한 분산 시스템에서는 동시에 생성될 수 있으므로 인덱스는 create_at 이 아닌 article_id로 진행한다
-
여기서 article_id는 snowflake로 생성됨

-
이제 정렬조건은 article_id로 한다
-
생성한 인덱스를 쿼리에 사용할 수 있어야 한다.


-
인덱스 사용시 확실히 성능개선이 일어난것을 확인할 수 있다.
-
하지만 인덱스를 사용해도, offset이 늘어 날수록 성능은 떨어진다 왜그럴까??
ClusteredIndex
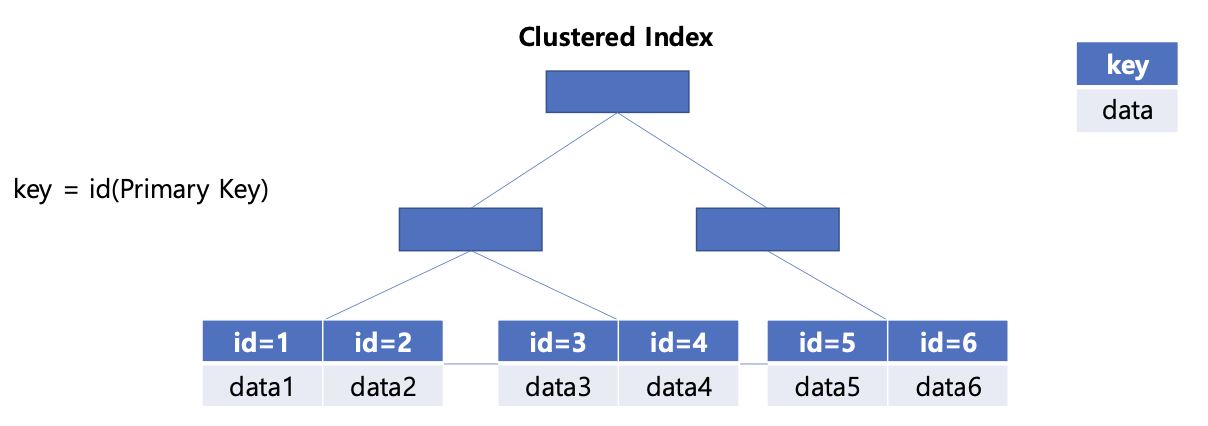
-
Mysql 는 InnoDB이며 테이블마다 ClusteredIndex를 자동으로 생성한다. Primary Key를 기준으로 정렬된 Clustered Index 생성
-
ClusteredIndex 는 leaf node의 값으로 행 데이터 를 가진다
-
즉, primaryKey에 ClsteredIndex가 생성되는것, -> pk로 조회시 ClusteredIndex가 사용되는것!
SecondaryIndex
- 우리가 생성한 인덱스, non-clusteredIndex라고도 불린다
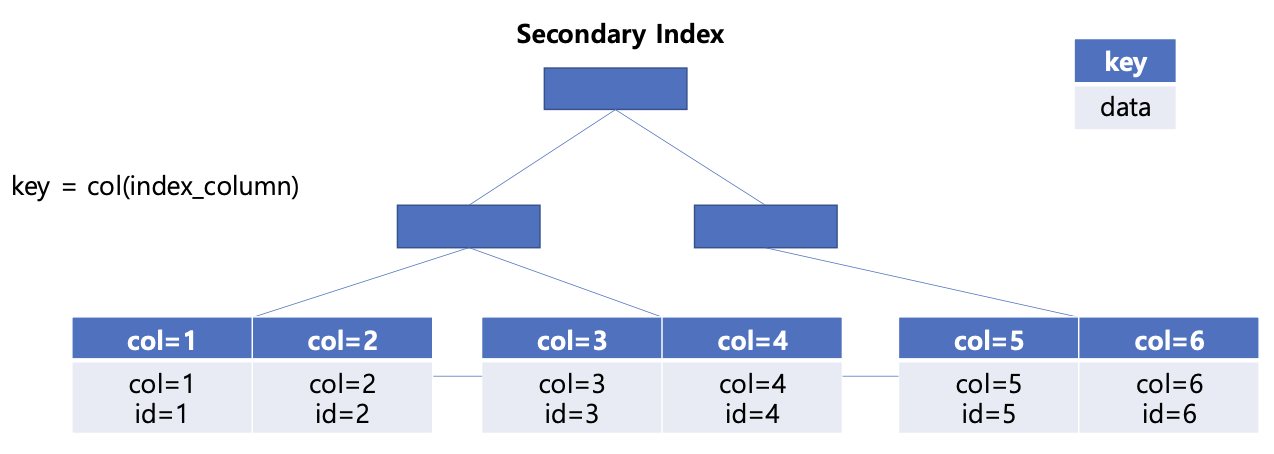
- SecondaryIndex는 데이터에 접근하기 위한 pk 를 가진다
-> ClusteredIndex는 데이터를 가지고 있고 우리가 인덱스를 사용해 조회하면 SecondaryIndex -> ClusteredIndex -> data 순으로 접근함
offset / SecondaryIndex

-
인덱스를 걸어도 offset이 커질수록 느려지는 이유는 다음과 같다-> 해당 offset에 도달
-
인덱스를 만들때 board_id와 article_id를 포함하도록 만들었다. 그럼 데이터 전체를 가져오기보다는 SecondaryIndex에서 필요한 30건에 대해서만 article_Id만 먼저 추출하고 이것만 clusteredIndex 에 데이터 요청을 하면 되지 않을까?

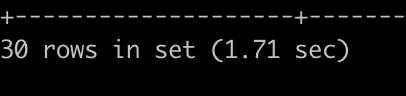
- 인덱스를 걸어도 offset이 커지면 느린상태

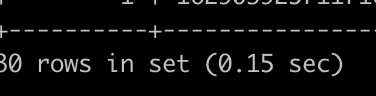
- 전체데이터가 아닌 필요한 데이터만 뽑으니 성능이 빠르다

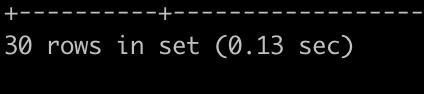
- 필요한 데이터만 뽑은걸 서브 쿼리로 두고 데이터를 조회하면 처음 결과보다 훨씬 빨라졌다.
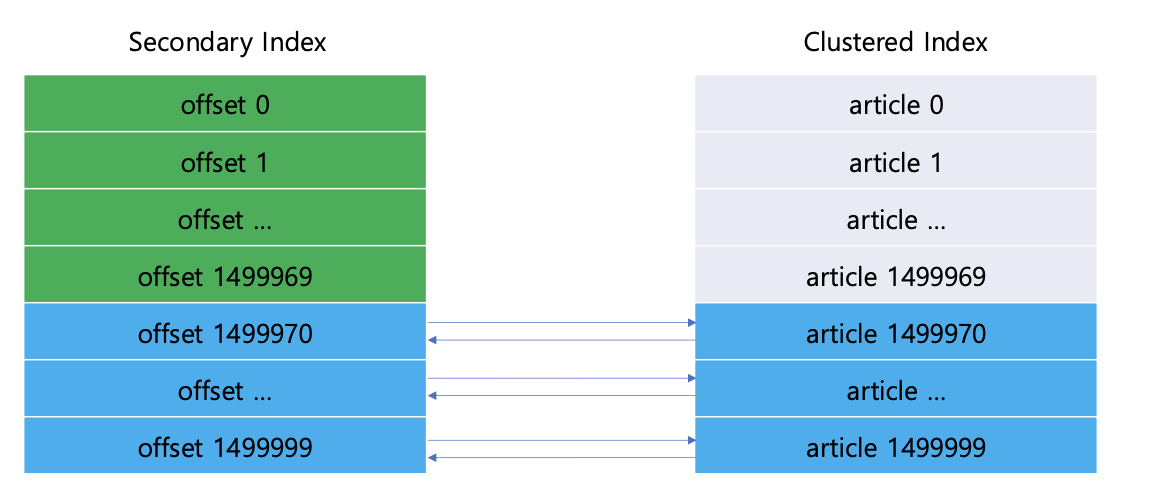
- CoverIndex로 필요한 데이터만 뽑고 그 값에대한 데이터만 요청한것!!
CoveringIndex

-
이렇게 인덱스의 데이터만으로 조회를 수행할 수 있는 인덱스를 Covering Index라고 한다
-
데이터(Clustered Index)를 읽지 않고, 인덱스(Secondary Index) 포함된 정보만으로 쿼리 가능한 인덱스
CoveringIndex 사용법
- 위에서 사용했듯이, 서브쿼리에 진짜 필요한것만 가져오고, 서브쿼리로 가져온걸 기준으로 조회 or

- 이렇게 쿼리에서 요청한 모든 컬럼이 인덱스 자체에 포함되도록
-> 하지만 이방법도 서브쿼리의 offset이 늘어나면 성능이 느려진다. 이정도일때는 테이블 분리를 고려 해본다. 또는 기본 정책을 ~까지만 조회가능 하게 정책으로도 해결 해보자.
무한 스크룰
- 페이지 번호 방식은 뒤로 갈수록 느려지지만 무한 스크룰은 균등한 조회 속도를 가진다

- 무한 스크룰에서는 중간에 삭제되거나 추가 되면 정확한 데이터 조회가 불가능 하기 때문에 항상 마지막 데이터 기준으로 조회한다
PrimaryKey 생성전략
DB auto_increment

-
여러 샤드에서 중복된 키가 발생할 수 있어 분산 데이터 환경에서는 적절하지 않다.
-
그대로 클라이언트 쪽에 노출하면 보안 위험이 존재함
유니크 문자열 or 숫자
-
정렬데이터가 아닌 랜덤 데이터를 삽입하는 방법
-
ClstreredIndex는 정렬된 상태를 유지한다
-
데이터 삽입 필요한 인덱스가 가득차면 B+tree 재구성 및 페이지 분할로 디스크 I/O 증가
-
pk로 조회시 디스크에 랜덤I/o가 발생하기 떄문에 정렬된 순차보다 성능 저하
유니크 정렬 문자열
-
분산환경 pk중복 , 보안문제 해결
-
but, pk가 크면클수록 데이터는 더 많은 공간을 차지, 비교 연산에 의한 정렬 조회 더 많은 비용소모
유니크 정렬 숫자
- 분산환경 pk중복 , 보안문제 해결
- 유니크 정렬 문자열보다 적은 공간 사용
- 다양한 알고리즘 존재
대댓글(2뎁스)
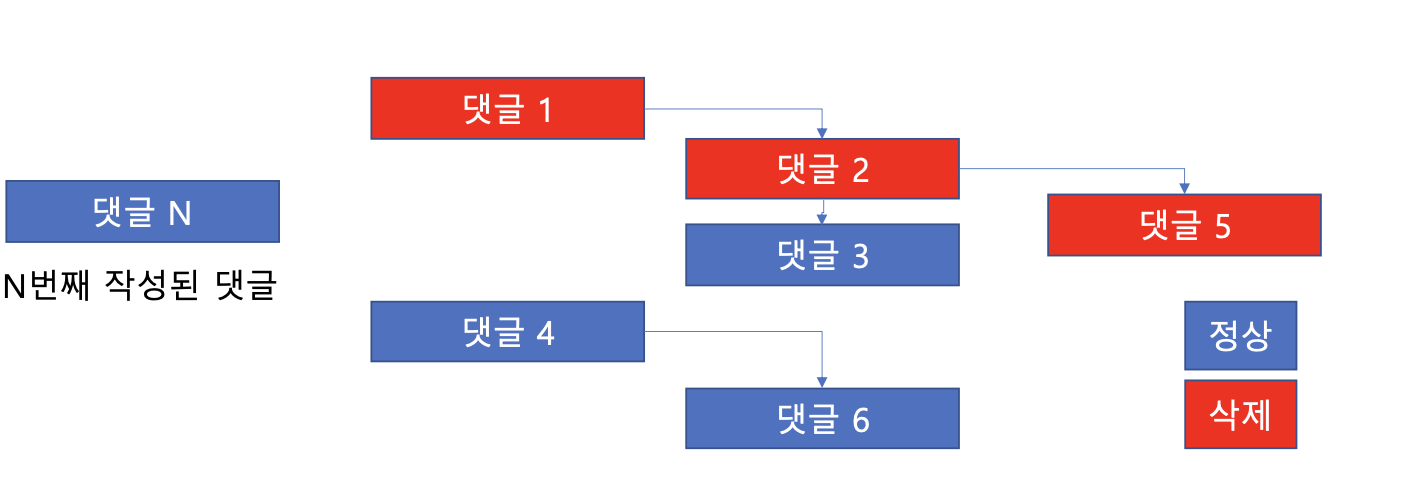
- 부모 댓글 + 자식댓글 (2depth)
- 부모댓글 (삭제) + 자식댓글 존재 = 부모 soft delete
- 부모댓글 (삭제) + 자식없음 or 자식삭제 = 부모 hard delete
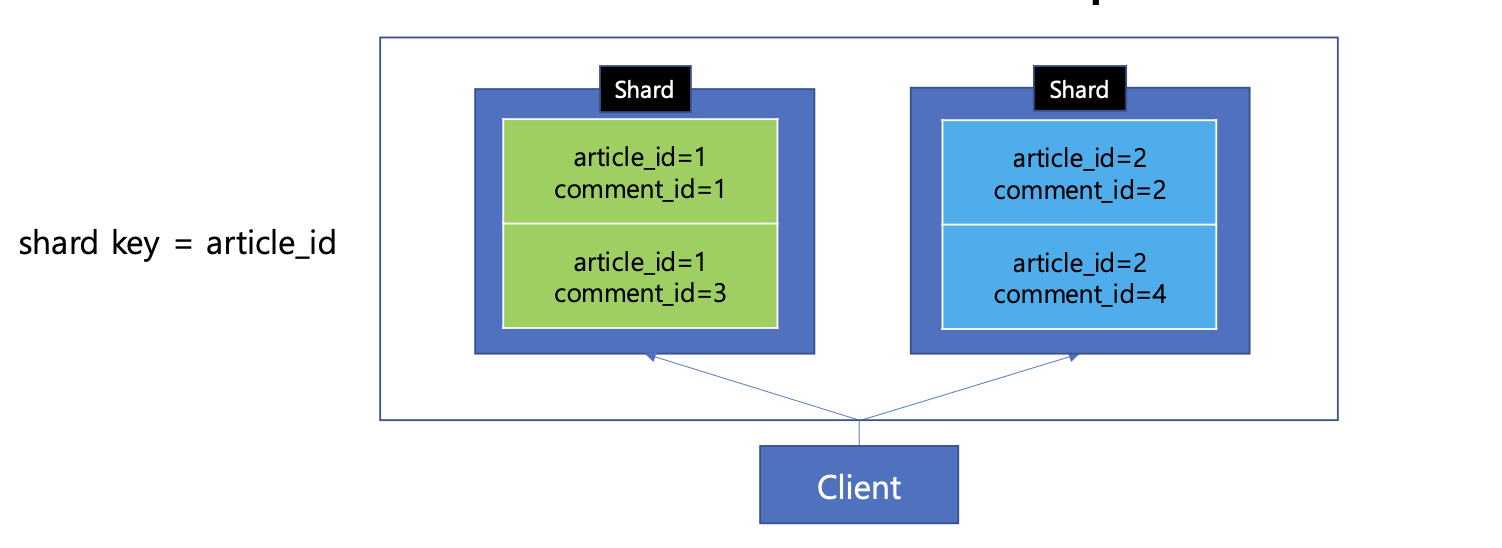
- 단일 샤드에서 조회하기위해 article_id를 기준으로 샤딩한다
-
댓글은 오래된글이 먼저 노출됨
-
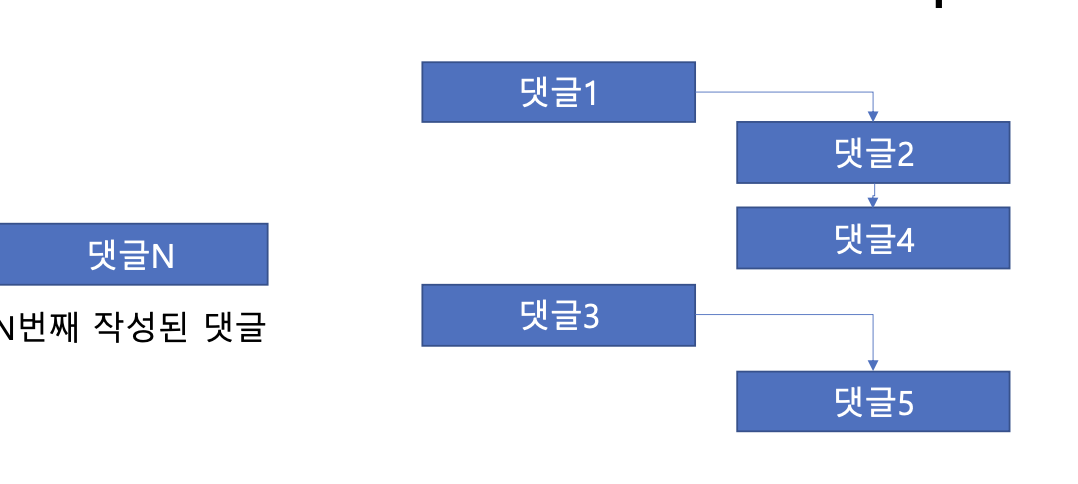
댓글도 게시글처럼 시간에 의한 순서는 comment_id로 명확히 나타낼 수 있다.(created_at은 동시에 일어날 수 있어서 x)
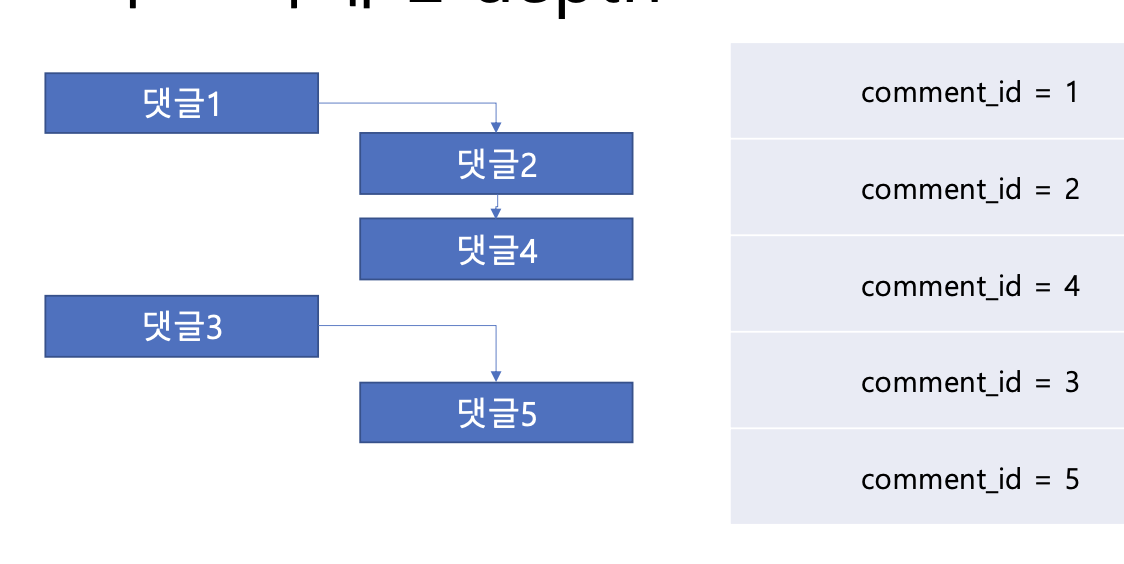
- 하지만, comment_id로 나타낼 경우 계층 관계에 대한 확실한 구별이 어렵다(계층 관계에서 더 늦게 작성된 댓글이 먼저 노출될 수 있다.
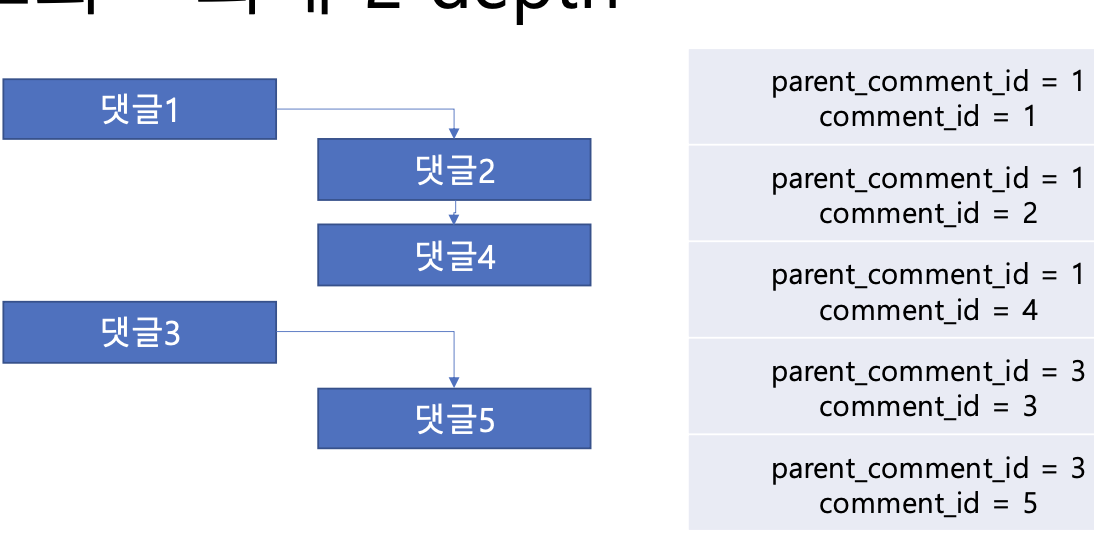
-
최상위 댓글의 parent_comment_id는 자기자신의 comment_id이다
-
계층형 댓글에서의 정렬이 어떠한 구조인지 알 수 있다.
테이블 정렬기준 -> 인덱스생성
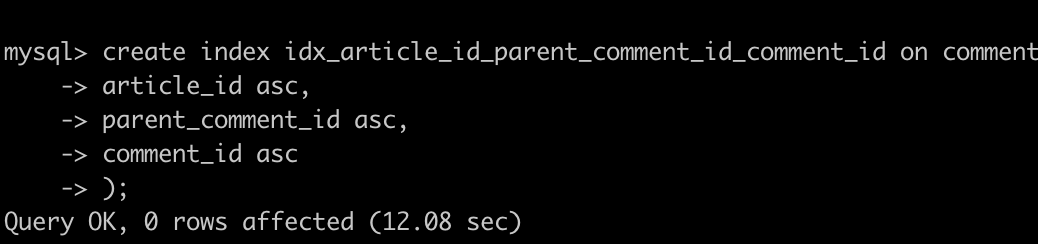
-
article_id 오름차순+parent_comment_id 오름차순, comment_id오름 차순 정렬 구조를 가지고 있으니 이를 기준으로 인덱스를 생성해준다.
-
shardKey = article_id 이기 때문에, 단일 샤드에서 게시글 별로 댓글 목록을 조회할 수 있다.
- 테스트 데이터는 대략 요정도 준비해준다.
2뎁스 조회쿼리
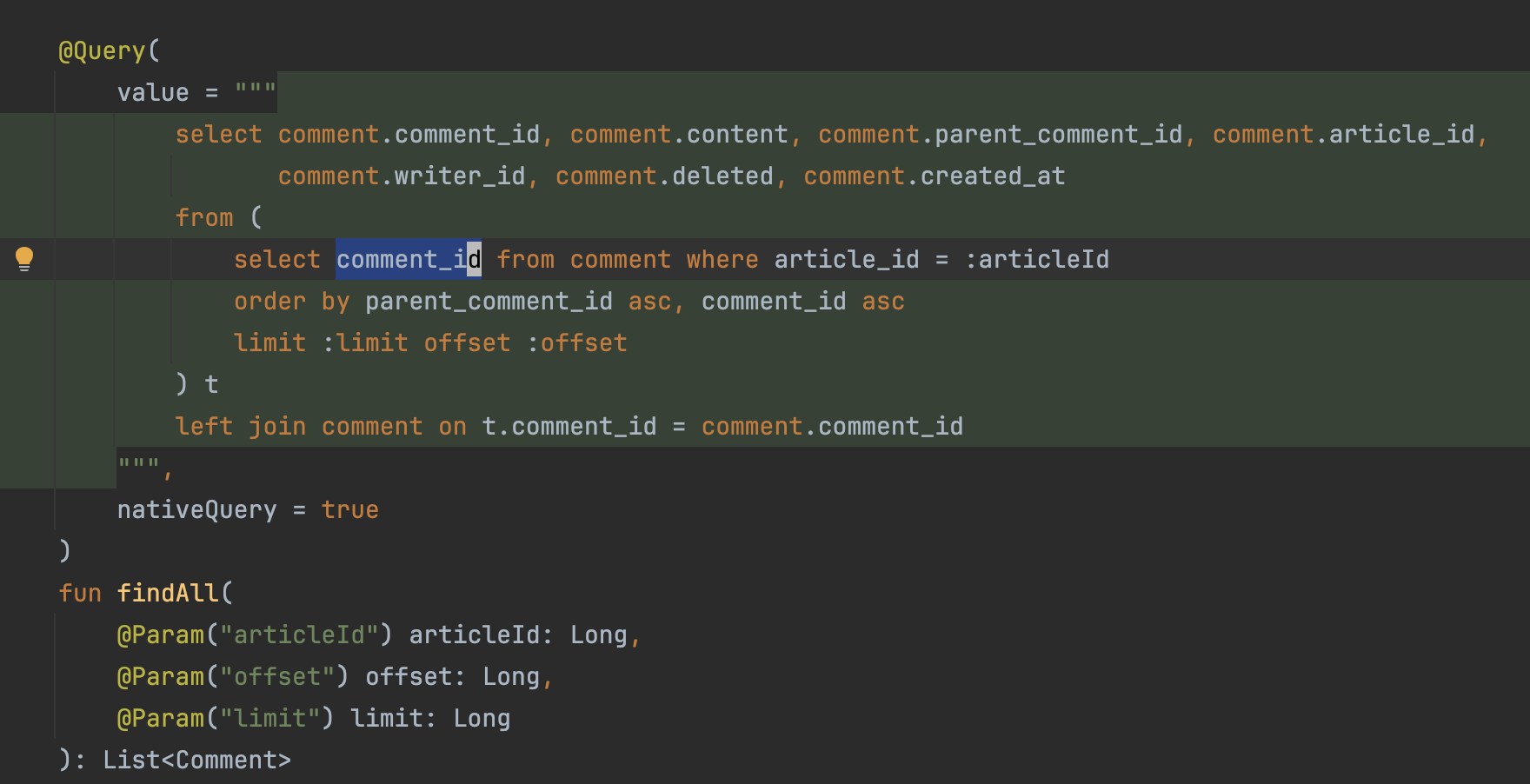
-
N번 페이지 M개의 댓글조회
-
조회 성능 최적화를 위해 comment_id(CoveringIndex) 사용 후 조회
카운트 쿼리
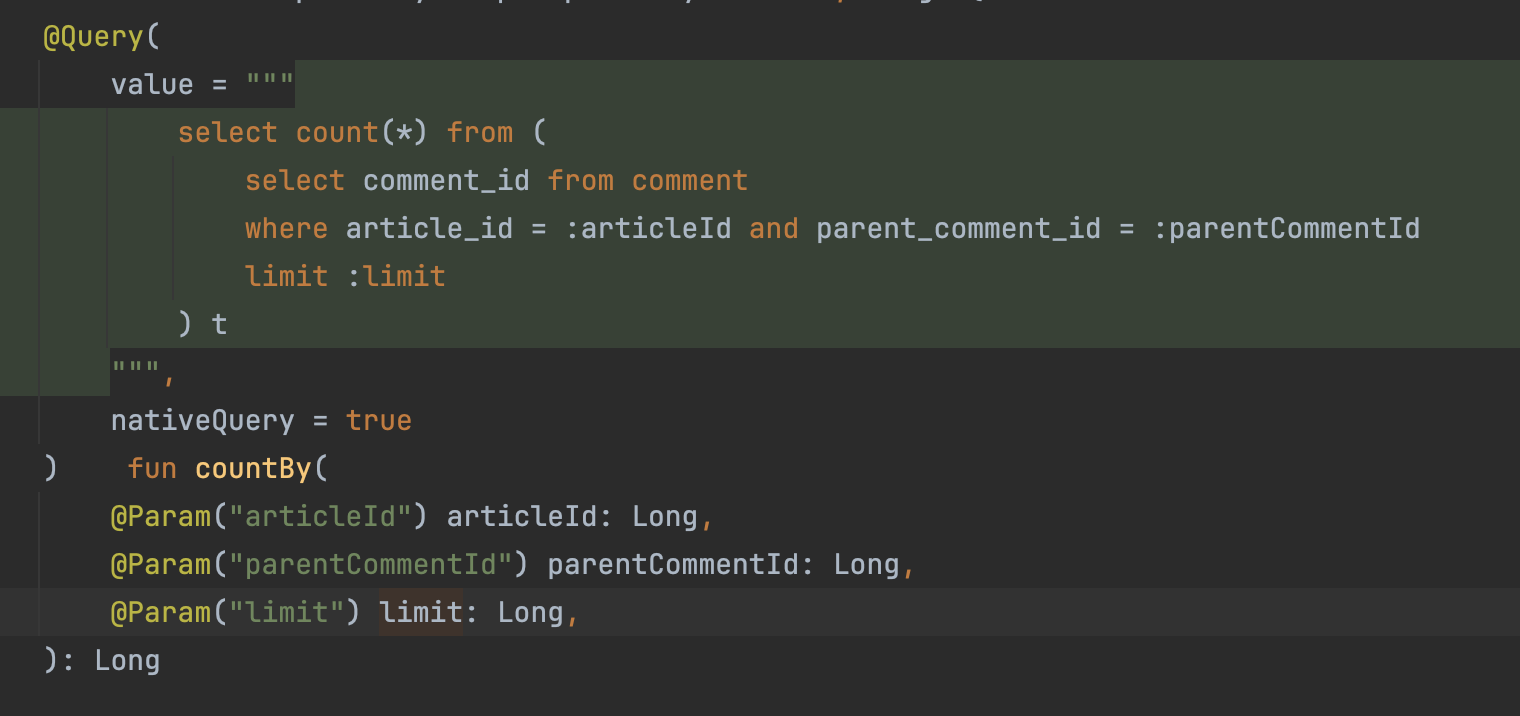
- 카운트 쿼리도 필요한것만 가져와서 그거 기준으로 조회해준다
무한스크룰
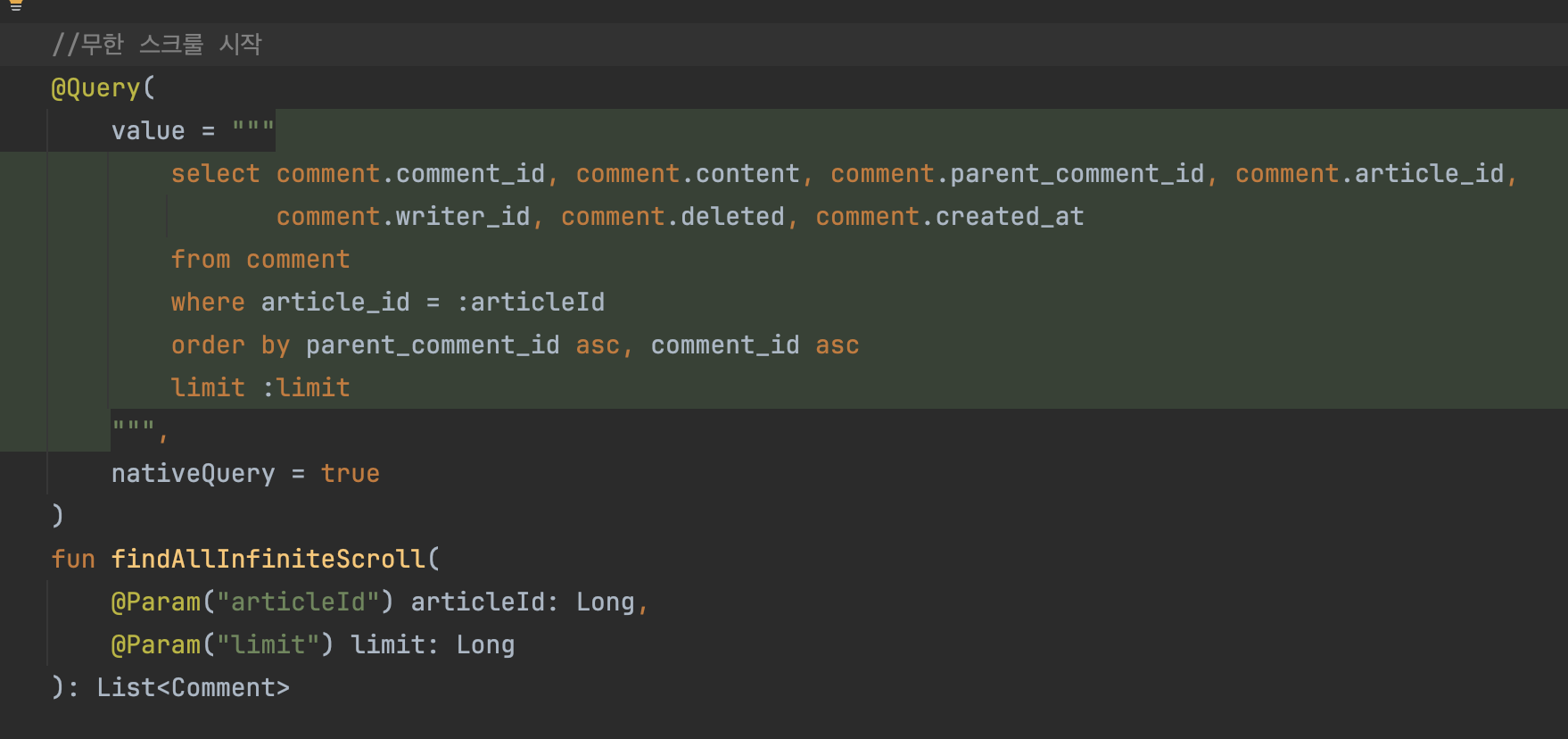
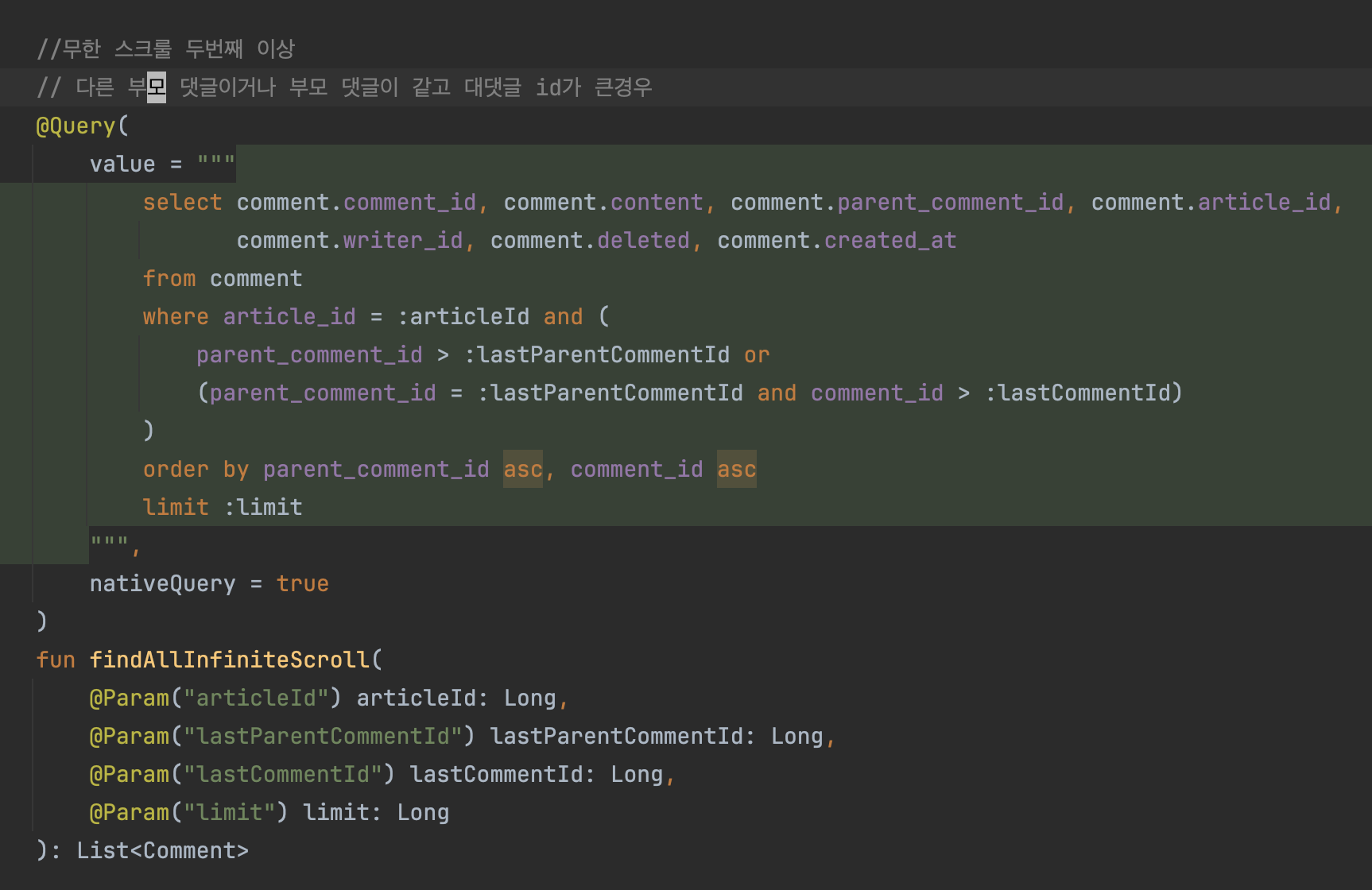
- parent_comment_id와 comment_id 두 개의 컬럼이 정렬에 사용되기 때문에 article과 다르게 기준점이 2개다
