- 자료출처 : PyTorch로 시작하는 딥 러닝 입문
- 자연어 처리는 일반적으로 토큰화, 단어집합 생성, 정수 인코딩, 패딩, 벡터화의 과정을 거친다.
1. 토큰화
- 토큰화 : 주어진 텍스트를 단어 또는 문자단위로 자르는 것
en_text = "A Dog Run back corner near spare bedrooms"1) nltk 토큰화
import nltk
import warnings
warnings.filterwarnings(action='ignore')nltk.download('punkt')from nltk.tokenize import word_tokenize
print(word_tokenize(en_text))['A', 'Dog', 'Run', 'back', 'corner', 'near', 'spare', 'bedrooms']2) 띄어쓰기 토큰화
print(en_text.split())['A', 'Dog', 'Run', 'back', 'corner', 'near', 'spare', 'bedrooms']3) 문자토큰화
print(list(en_text))['A', ' ', 'D', 'o', 'g', ' ', 'R', 'u', 'n', ' ', 'b', 'a', 'c', 'k', ' ', 'c', 'o', 'r', 'n', 'e', 'r', ' ', 'n', 'e', 'a', 'r', ' ', 's', 'p', 'a', 'r', 'e', ' ', 'b', 'e', 'd', 'r', 'o', 'o', 'm', 's']4) 한국어 띄어쓰기 토큰화
kor_text = "사과의 놀라운 효능이라는 글을 봤어. 그래서 오늘 사과를 먹으려고 했는데 사과가 썩어서 슈퍼에 가서 사과랑 오렌지 사왔어"
print(kor_text.split())['사과의', '놀라운', '효능이라는', '글을', '봤어.', '그래서', '오늘', '사과를', '먹으려고', '했는데', '사과가', '썩어서', '슈퍼에', '가서', '사과랑', '오렌지', '사왔어']5) 형태소 토큰화
from konlpy.tag import Mecab
tokenizer = Mecab()
print(tokenizer.morphs(kor_text))['사과', '의', '놀라운', '효능', '이', '라는', '글', '을', '봤', '어', '.', '그래서', '오늘', '사과', '를', '먹', '으려고', '했', '는데', '사과', '가', '썩', '어서', '슈퍼', '에', '가', '서', '사과', '랑', '오렌지', '사', '왔', '어']2. 단어집합 형성
import urllib.request
import pandas as pd
from konlpy.tag import Mecab
from nltk import FreqDist
import numpy as np
import matplotlib.pyplot as plturllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings.txt", filename="ratings.txt")
data = pd.read_table('ratings.txt') # 데이터프레임에 저장
data[:10]| id | document | label | |
|---|---|---|---|
| 0 | 8112052 | 어릴때보고 지금다시봐도 재밌어요ㅋㅋ | 1 |
| 1 | 8132799 | 디자인을 배우는 학생으로, 외국디자이너와 그들이 일군 전통을 통해 발전해가는 문화산... | 1 |
| 2 | 4655635 | 폴리스스토리 시리즈는 1부터 뉴까지 버릴께 하나도 없음.. 최고. | 1 |
| 3 | 9251303 | 와.. 연기가 진짜 개쩔구나.. 지루할거라고 생각했는데 몰입해서 봤다.. 그래 이런... | 1 |
| 4 | 10067386 | 안개 자욱한 밤하늘에 떠 있는 초승달 같은 영화. | 1 |
| 5 | 2190435 | 사랑을 해본사람이라면 처음부터 끝까지 웃을수 있는영화 | 1 |
| 6 | 9279041 | 완전 감동입니다 다시봐도 감동 | 1 |
| 7 | 7865729 | 개들의 전쟁2 나오나요? 나오면 1빠로 보고 싶음 | 1 |
| 8 | 7477618 | 굿 | 1 |
| 9 | 9250537 | 바보가 아니라 병 쉰 인듯 | 1 |
<svg xmlns="http://www.w3.org/2000/svg" height="24px"viewBox="0 0 24 24"
width="24px">
<script>
const buttonEl =
document.querySelector('#df-2ebe9bcd-a7dd-4992-861e-968f16545fbe button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-2ebe9bcd-a7dd-4992-861e-968f16545fbe');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>print('전체 샘플의 수 : {}'.format(len(data)))전체 샘플의 수 : 200000sample_data = data[:100] # 임의로 100개만 저장sample_data['document'] = sample_data['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","")
# 한글과 공백을 제외하고 모두 제거
sample_data[:10]| id | document | label | |
|---|---|---|---|
| 0 | 8112052 | 어릴때보고 지금다시봐도 재밌어요ㅋㅋ | 1 |
| 1 | 8132799 | 디자인을 배우는 학생으로 외국디자이너와 그들이 일군 전통을 통해 발전해가는 문화산업... | 1 |
| 2 | 4655635 | 폴리스스토리 시리즈는 부터 뉴까지 버릴께 하나도 없음 최고 | 1 |
| 3 | 9251303 | 와 연기가 진짜 개쩔구나 지루할거라고 생각했는데 몰입해서 봤다 그래 이런게 진짜 영화지 | 1 |
| 4 | 10067386 | 안개 자욱한 밤하늘에 떠 있는 초승달 같은 영화 | 1 |
| 5 | 2190435 | 사랑을 해본사람이라면 처음부터 끝까지 웃을수 있는영화 | 1 |
| 6 | 9279041 | 완전 감동입니다 다시봐도 감동 | 1 |
| 7 | 7865729 | 개들의 전쟁 나오나요 나오면 빠로 보고 싶음 | 1 |
| 8 | 7477618 | 굿 | 1 |
| 9 | 9250537 | 바보가 아니라 병 쉰 인듯 | 1 |
<svg xmlns="http://www.w3.org/2000/svg" height="24px"viewBox="0 0 24 24"
width="24px">
<script>
const buttonEl =
document.querySelector('#df-36aff935-08b7-43e9-8837-b4c79bc3f5ee button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-36aff935-08b7-43e9-8837-b4c79bc3f5ee');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div># 불용어 정의
stopwords=['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']tokenizer = Mecab()tokenized=[]
for sentence in sample_data['document']:
temp = tokenizer.morphs(sentence) # 토큰화
temp = [word for word in temp if not word in stopwords] # 불용어 제거
tokenized.append(temp)print(tokenized[:10]) # 10개만 출력[['어릴', '때', '보', '고', '지금', '다시', '봐도', '재밌', '어요', 'ㅋㅋ'], ['디자인', '을', '배우', '학생', '외국', '디자이너', '그', '일군', '전통', '을', '통해', '발전', '해', '문화', '산업', '부러웠', '는데', '사실', '우리', '나라', '에서', '그', '어려운', '시절', '끝', '까지', '열정', '을', '지킨', '노라노', '같', '전통', '있', '어', '저', '같', '사람', '꿈', '을', '꾸', '고', '이뤄나갈', '수', '있', '다는', '것', '감사', '합니다'], ['폴리스', '스토리', '시리즈', '부터', '뉴', '까지', '버릴', '께', '하나', '없', '음', '최고'], ['연기', '진짜', '개', '쩔', '구나', '지루', '할거', '라고', '생각', '했', '는데', '몰입', '해서', '봤', '다', '그래', '이런', '게', '진짜', '영화', '지'], ['안개', '자욱', '밤하늘', '떠', '있', '초승달', '같', '영화'], ['사랑', '을', '해', '본', '사람', '라면', '처음', '부터', '끝', '까지', '웃', '을', '수', '있', '영화'], ['완전', '감동', '입니다', '다시', '봐도', '감동'], ['개', '전쟁', '나오', '나요', '나오', '면', '빠', '로', '보', '고', '싶', '음'], ['굿'], ['바보', '아니', '라', '병', '쉰', '인', '듯']]# 단어집합 만들기
vocab = FreqDist(np.hstack(tokenized))
print('단어 집합의 크기 : {}'.format(len(vocab)))단어 집합의 크기 : 664vocab['재밌'] # 빈도수 리턴10vocab_size = 500
# 상위 vocab_size개의 단어만 보존
vocab = vocab.most_common(vocab_size)
print('단어 집합의 크기 : {}'.format(len(vocab)))단어 집합의 크기 : 5003. 각 단어에 정수 부여
word_to_index = {word[0] : index + 2 for index, word in enumerate(vocab)}
word_to_index['pad'] = 1
word_to_index['unk'] = 0encoded = []
for line in tokenized: #입력 데이터에서 1줄씩 문장을 읽음
temp = []
for w in line: #각 줄에서 1개씩 글자를 읽음
try:
temp.append(word_to_index[w]) # 글자를 해당되는 정수로 변환
except KeyError: # 단어 집합에 없는 단어일 경우 unk로 대체된다.
temp.append(word_to_index['unk']) # unk의 인덱스로 변환
encoded.append(temp)print(encoded[:10])[[78, 27, 9, 4, 50, 41, 79, 16, 28, 29], [188, 5, 80, 189, 190, 191, 42, 192, 114, 5, 193, 194, 21, 115, 195, 196, 13, 51, 81, 116, 30, 42, 197, 117, 118, 31, 198, 5, 199, 200, 17, 114, 7, 82, 52, 17, 43, 201, 5, 202, 4, 203, 14, 7, 83, 32, 204, 84], [205, 119, 206, 53, 207, 31, 208, 209, 54, 10, 25, 11], [44, 33, 120, 210, 211, 212, 213, 68, 45, 34, 13, 214, 121, 15, 2, 215, 69, 8, 33, 3, 35], [216, 217, 218, 219, 7, 220, 17, 3], [122, 5, 21, 36, 43, 123, 124, 53, 118, 31, 85, 5, 14, 7, 3], [125, 37, 221, 41, 79, 37], [120, 222, 55, 223, 55, 86, 224, 46, 9, 4, 47, 25], [56], [225, 87, 88, 226, 227, 57, 89]]4. 패딩 (길이 다른 문장 동일 길이로 바꿔주기)
max_len = max(len(l) for l in encoded)
print('리뷰의 최대 길이 : %d' % max_len)
print('리뷰의 최소 길이 : %d' % min(len(l) for l in encoded))
print('리뷰의 평균 길이 : %f' % (sum(map(len, encoded))/len(encoded)))
plt.hist([len(s) for s in encoded], bins=50)
plt.xlabel('length of sample')
plt.ylabel('number of sample')
plt.show()리뷰의 최대 길이 : 63
리뷰의 최소 길이 : 1
리뷰의 평균 길이 : 13.900000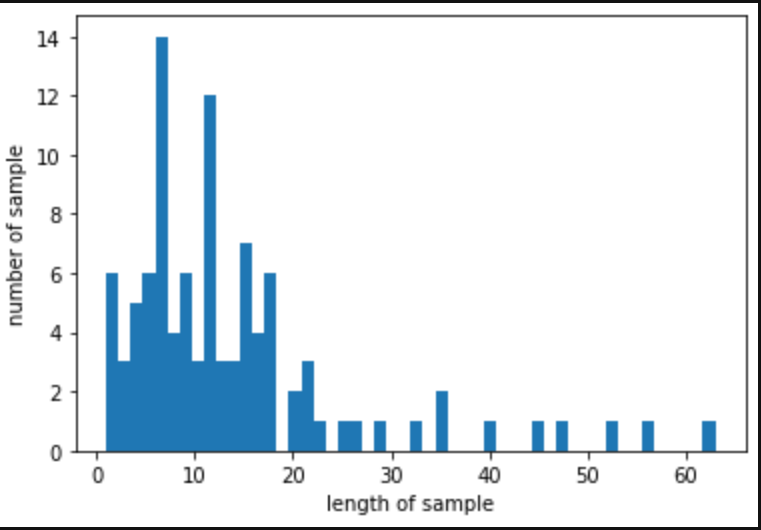
# 가장 긴 63으로 모두 맞춰주기
for line in encoded:
if len(line) < max_len: # 현재 샘플이 정해준 길이보다 짧으면
line += [word_to_index['pad']] * (max_len - len(line)) # 나머지는 전부 'pad' 토큰으로 채운다.print('리뷰의 최대 길이 : %d' % max(len(l) for l in encoded))
print('리뷰의 최소 길이 : %d' % min(len(l) for l in encoded))
print('리뷰의 평균 길이 : %f' % (sum(map(len, encoded))/len(encoded)))리뷰의 최대 길이 : 63
리뷰의 최소 길이 : 63
리뷰의 평균 길이 : 63.000000print(encoded[:3]) # 상위 3개 샘플[[78, 27, 9, 4, 50, 41, 79, 16, 28, 29, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [188, 5, 80, 189, 190, 191, 42, 192, 114, 5, 193, 194, 21, 115, 195, 196, 13, 51, 81, 116, 30, 42, 197, 117, 118, 31, 198, 5, 199, 200, 17, 114, 7, 82, 52, 17, 43, 201, 5, 202, 4, 203, 14, 7, 83, 32, 204, 84, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [205, 119, 206, 53, 207, 31, 208, 209, 54, 10, 25, 11, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
나무를 심는 사람