- 자료출처 : PyTorch로 시작하는 딥 러닝 입문
MINIST 데이터 분류하기
- 소프트맥스 회귀 사용
- MINST는 0부터 9까지 이미지로 구성된 손글씨 데이터셋이다.
- 손글씨로 적힌 숫자 이미지가 들어오면 그 이미지가 무슨 숫자인지 맞출 때 활용
- 토치비전(torchvision)을 활용한다. 토치비전은 데이터셋과 모델, 전처리 도구들을 포함한다.
1. 분류기 구현을 위한 사전 설정
import torch
import torchvision.datasets as dsets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import matplotlib.pyplot as plt
import random
import warnings
warnings.filterwarnings(action='ignore')# GPU 연산 가능여부 파악
USE_CUDA = torch.cuda.is_available() # GPU를 사용가능하면 True, 아니라면 False를 리턴
device = torch.device("cuda" if USE_CUDA else "cpu") # GPU 사용 가능하면 사용하고 아니면 CPU 사용
print("다음 기기로 학습합니다:", device)다음 기기로 학습합니다: cpu# 랜덤 시드 고정
random.seed(777)
torch.manual_seed(777)
if device == 'cuda':
torch.cuda.manual_seed_all(777)# 하이퍼파라미터(hyperparameters)
training_epochs = 15
batch_size = 1002. MINST 분류기 구현하기
# MNIST dataset
mnist_train = dsets.MNIST(root='MNIST_data/',
train=True,
transform=transforms.ToTensor(),
download=True)
mnist_test = dsets.MNIST(root='MNIST_data/',
train=False,
transform=transforms.ToTensor(),
download=True)# dataset loader
data_loader = DataLoader(dataset=mnist_train,
batch_size=batch_size, # 배치 크기는 100
shuffle=True,
drop_last=True)- DataLoader(dataset 로드할 대상, 배치사이즈, 셔플여부, 마지막 배치를 버릴지 여부)
- drop_last를 하는 이유는 마지막 배치가 과대평가되는 현상을 막기 위해서다.
(1,000개의 데이터를 128개로 나눴을 때 마지막 배치는 104개가 과대평가 될 확률이 높다)
# 모델 설계 : to()는 연산을 어디서 수행할 지 정한다.
# bias는 기본값이 True이므로 표시할 필요는 없지만 명시적으로 표시해줌
# MNIST data image of shape 28 * 28 = 784
linear = nn.Linear(784, 10, bias=True).to(device)# 비용 함수와 옵티마이저 정의
criterion = nn.CrossEntropyLoss().to(device) # 내부적으로 소프트맥스 함수를 포함하고 있음.
optimizer = torch.optim.SGD(linear.parameters(), lr=0.1)for epoch in range(training_epochs): # 앞서 training_epochs의 값은 15로 지정함.
avg_cost = 0
total_batch = len(data_loader)
for X, Y in data_loader:
# 배치 크기가 100이므로 아래의 연산에서 X는 (100, 784)의 텐서가 된다.
X = X.view(-1, 28 * 28).to(device)
# 레이블은 원-핫 인코딩이 된 상태가 아니라 0 ~ 9의 정수.
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = linear(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.9f}'.format(avg_cost))
print('Learning finished')Epoch: 0001 cost = 0.535899699
Epoch: 0002 cost = 0.359200478
Epoch: 0003 cost = 0.331210256
Epoch: 0004 cost = 0.316642910
Epoch: 0005 cost = 0.306912184
Epoch: 0006 cost = 0.300341636
Epoch: 0007 cost = 0.295203745
Epoch: 0008 cost = 0.290808439
Epoch: 0009 cost = 0.287419200
Epoch: 0010 cost = 0.284378737
Epoch: 0011 cost = 0.281997472
Epoch: 0012 cost = 0.279780537
Epoch: 0013 cost = 0.277854115
Epoch: 0014 cost = 0.276023209
Epoch: 0015 cost = 0.274494976
Learning finished# 테스트 데이터를 사용하여 모델을 테스트한다.
with torch.no_grad(): # torch.no_grad()를 하면 gradient 계산을 수행하지 않는다.
X_test = mnist_test.test_data.view(-1, 28 * 28).float().to(device)
Y_test = mnist_test.test_labels.to(device)
prediction = linear(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print('Accuracy:', accuracy.item())
# MNIST 테스트 데이터에서 무작위로 하나를 뽑아서 예측을 해본다
r = random.randint(0, len(mnist_test) - 1)
X_single_data = mnist_test.test_data[r:r + 1].view(-1, 28 * 28).float().to(device)
Y_single_data = mnist_test.test_labels[r:r + 1].to(device)
print('Label: ', Y_single_data.item())
single_prediction = linear(X_single_data)
print('Prediction: ', torch.argmax(single_prediction, 1).item())
plt.imshow(mnist_test.test_data[r:r + 1].view(28, 28), cmap='Greys', interpolation='nearest')
plt.show()Accuracy: 0.8841999769210815
Label: 5
Prediction: 5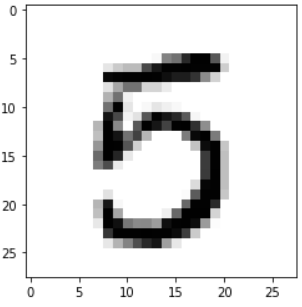
손글씨 이미지 5를 정확히 예측한 것을 볼 수 있다.

나무를 심는 사람
여전히 부지런하시네옇ㅎㅎㅎ 오랜만에 들어와봤어옄ㅋㅋㅋ