관계 데이터 모델 : 구조/표현, 연산, 제약조건으로 이루어짐
연산의 종류 : "관계대수", "관계 해석"
관계 대수
- 집합 연산자(∩,∪, - )를 사용하여 연산
- 입력(릴레이션) -> 출력(릴레이션) (릴레이션의 연산을 통해 새로운 릴레이션 생성)
- 입력과 출력 릴레이션의 종류가 같으면 연산이 관계에 대해서 ‘닫혀 있음’
- 연산의 결과에 또 연산을 할 수 있어, 관계 대수 표현식을 형성
- 순서 / 절차적 언어
SELECT
- 검색X, 조건에 맞는 결과들만 선택하는 연산
- 횡적인 부분 집합을 필터 함
- 교환법칙 성립, 연속적으로 SELECT 가능,

PROJECT
- 수직적 분할, 필요한 열만 선택
- 중복 튜플이 제거되어 나옴
- 교환 법칙 성립X

RENAME
릴레이션 이름을S로 변경, 애트리뷰트 이름을 B1, B2, …, Bn으로 변경

UNION
- 이진 연산이다.
- 중복된 튜플은 제거되어 나온다.
- 두 피연산자는 같은 종류의 릴레이션이어야 한다 -> 타입 호환성 (UNION 호환성)
- 애트리뷰트 개수가 같아야 한다. 도메인이 타입 호환적
INTERSECTION ‘∩’
- 타입 호환성 필요
- 교환 법칙 성립
SET DIFFERENCE ‘ – ‘
- 타입 호환성 필요
- 교환 법칙 X
CARTESIAL PRODUCT ‘X'
- 두 릴레이션에서 만들어질 수 있는 짝의 집합
- 결과 테이블의 애트리뷰트 개수는 두 릴레이션의 애트리뷰트 개수의 합
- 결과 테이블의 튜플의 개수는 두 릴레이션의 튜플의 개수의 곱
- 타입 호환적일 필요없음
JOIN ‘⋈’
- 조건에 맞는 R과 S의 튜플들만 가져온다.
- 애트리뷰트의 개수는 두 릴레이션의 애트리뷰트의 개수의 합
- 조건을 ‘세타’라고도 부름. 그래서 세타 조인이라고 부름.

EQUIJOIN
가장 일반적으로 사용되는 ‘=’ 조건의 조인
NATURAL JOIN
EQUIJOIN에서 같은 값이 나오는 애트리뷰트를 한번만 표시할 수 있는 연산
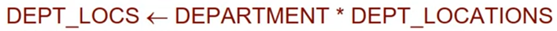
관계 연산의 완전 집합
이것만 있으면 원하는 모든 정보를 가져올 수 있다. (5가지)
SELECT, PROJECT, UNION, DIFFERENCE, CARTESIAN PRODUCT, (RENAME)
DIVISION
Z가 X,Y로 이루어져 있다면 R에서 S(X)를 가진 Y들을 구함.
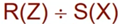
집계 함수
SUM, AVERAGE, MAXIMUM, MINIMUM, COUNT


집계 함수와 그룹화로
그룹 별로 집계 함수 계산됨
(F 왼쪽에 그룹화하고 싶은 애트리뷰트, F 오른쪽에 집계 함수)

OUTER JOIN
JOIN 조건을 만족하는 튜플이 없더라도 NULL값으로 채워져서 나온다.
(오른쪽 OUTER JOIN) 일치하는 값이 없어도 R의 값이NULL로 채워져 나온다.

관계 해석
- 조건 제시법으로 연산
- 튜플 또는 애트리뷰트의 범위를 갖는 변수로 표현된다.
- 해석식은 순서가 없음(비 절차적 언어) – 관계 대수와의 중요한 차이점!
- 튜플 관계해석 : 변수의 범위가 튜플

- 도메인 관계해석 : 변수의 범위가 도메인
-> SQL은 99% 관계해석 + 1% 관계 대수 형태로 이루어짐

꾸준하게 공부하고 기록하는 개발자