0. References
- Paper: https://arxiv.org/abs/2109.01652
- Appendix 에 있는 다양한 instruction format 을 참고할 것!
- Google Research, ICRL 2022
- Instruction Tuning 기법에 대한 초기 논문 중 하나로 (arXiv 시기는 2021), Google 에서 많이 사용하고 있는 (PaLM 등에서 사용됨)
FLAN기법에 대한 소개
1. Introduction
📌 Contributions:
- GPT 와 같은 모델이 few-shot 성능은 높은 대신에 zero-shot 성능은 아직 부족한데, Instruction tuning 기법을 통해 unseen task 에 대한
zero-shot성능을 높인 연구- 타겟 task 와 관련이 없더라도, 다양한 cluster 의 NLP task 데이터셋을 Instruction tuning 에 사용하면 타겟 task 의 성능도 향상됨
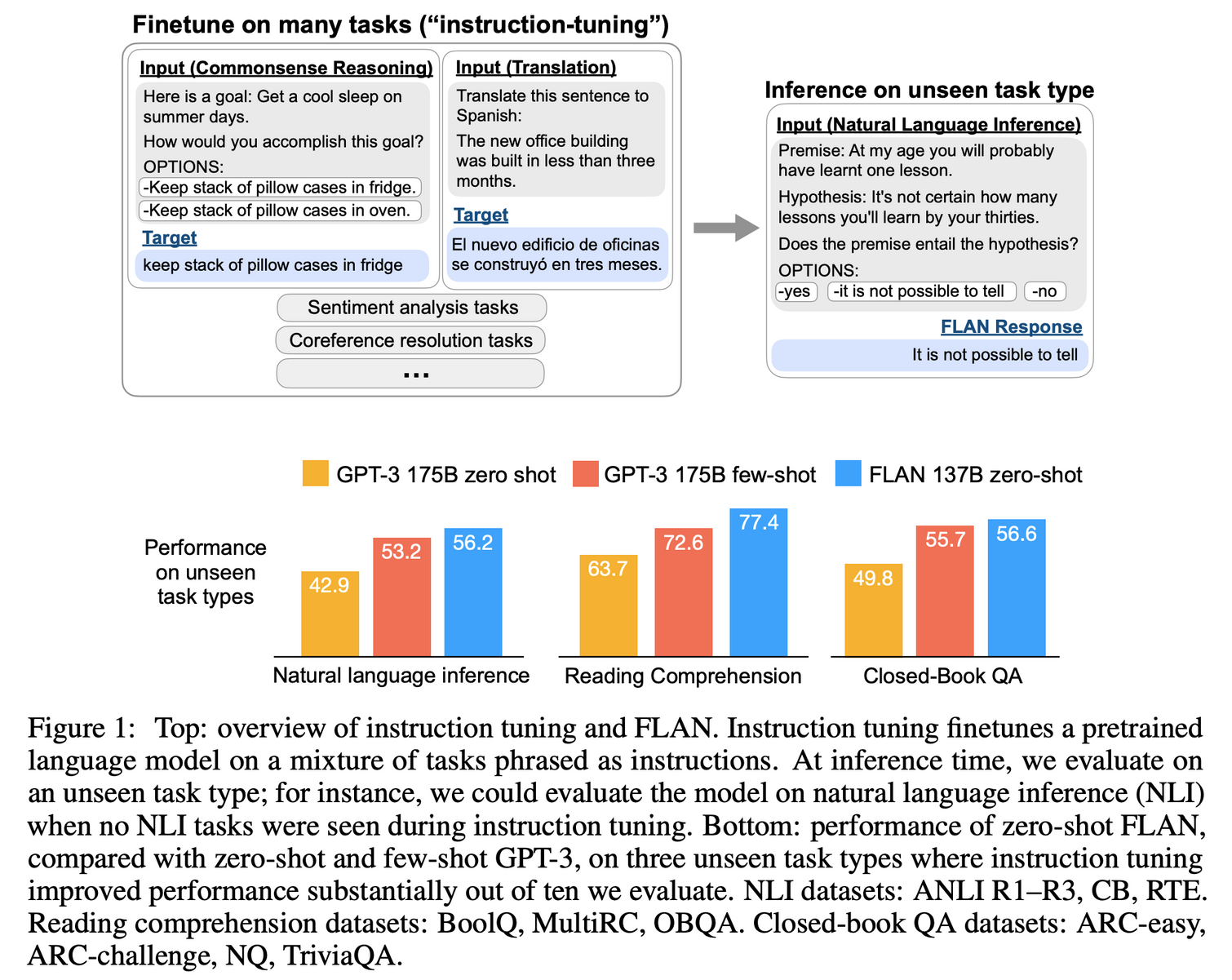
- GPT-3 가 출현하면서 few-shot 형태는 성능이 꽤 올랐지만, zero-shot 성능은 여전히 좋지 못함
- MRC, QA, NLI 같은 task
- 이는 별다른 task 포맷이 아닌 pre-training 학습 시 사용한 데이터 포맷에서, 별도 examples 없이 prompt 로만 수행하는 것이 어려운 task 이기 때문
- 모델이 instructions 형태로 된 task 를 supervised 로 학습하면, 이후 unseen task 에 대해서도 instructions 을 따르는 방식으로 추론하게 될 것이라 기대
- 다양한 NLP task 가 instruction 형태로 설명될 수 있다는 점에서 착안
- Is the sentiment of this movie review positive or negative?
- Translate how are you into Chinese
- 60여개의 NLP datasets 을 섞어서 instruction 형태로 fine-tuning 진행
FLAN: Finetuned Language Net.- 단, 평가할 때 task 별로 클러스터링 하여, 평가하려는 task 와 관련 없는 task 들로만 FLAN 을 적용한 것으로 테스트 진행 (즉, NLI task 평가할 때는 NLI 와 유사한 클러스터의 데이터셋은 빼고 학습함)
- 결론: task clustering 수가 많아질 수록 성능이 향상
2. FLAN
2.1 Tasks & Templates
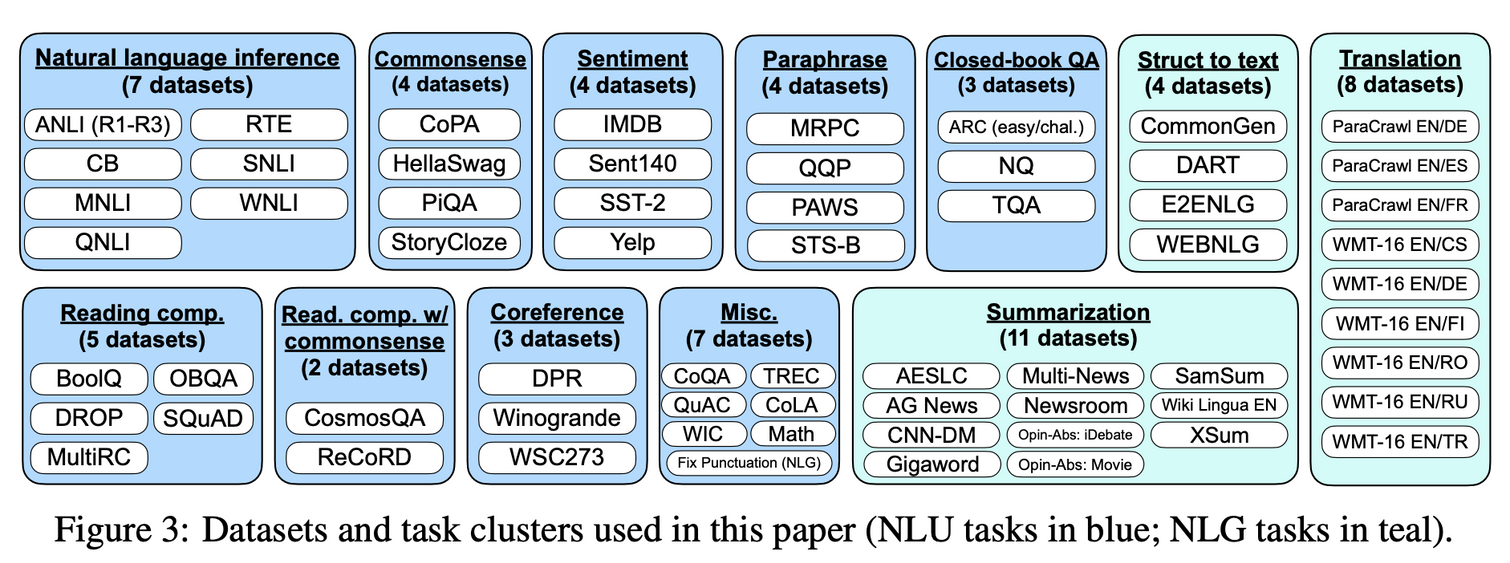
- Research Community 에 존재하는 공개 datasets 을 가져와서 instructional format 으로 transform
Tensorflow Datasets에서 이용할 수 있는 62개의 데이터셋을 합침- 파랑색: NLU
- 민트색: NLG - Generation
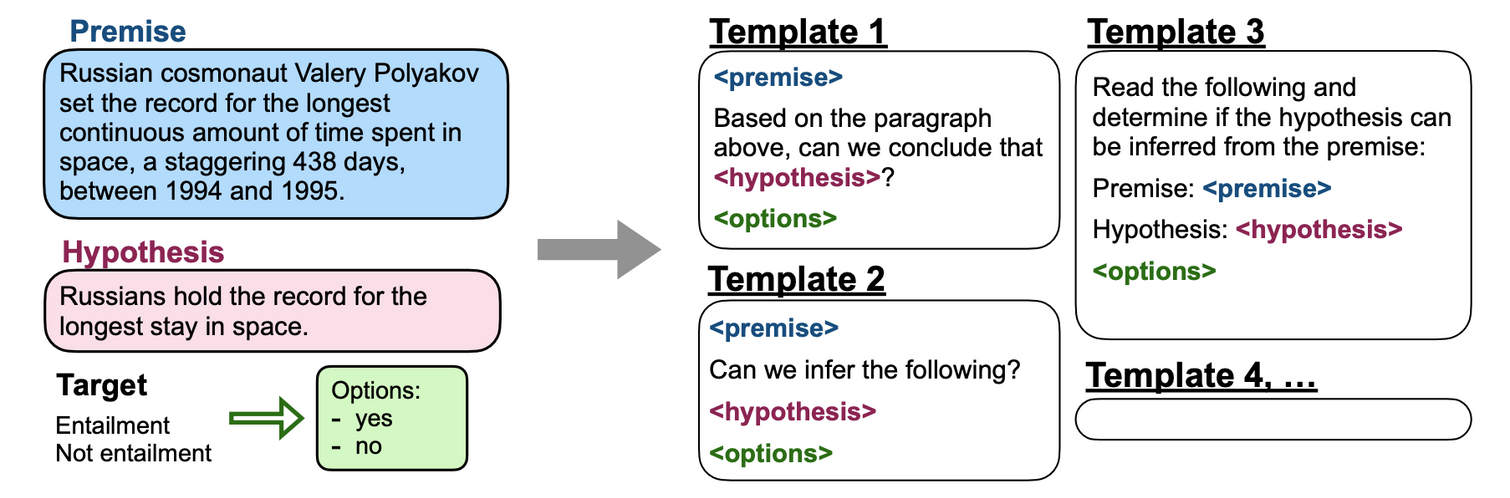
- 각각의 NLP task 에 대해 몇 가지 templates 를 만들어 놓고, randomly 선택하여 데이터를 생성
- 동일한 데이터에 대해서도 templates 에 따라 다른 형태의 prompt 가 조합될 수 있음
- Templates 모음: https://github.com/google-research/FLAN/blob/main/flan/templates.py
2.2 Classification with options
- Decoder only 스타일이기 때문에 generation task 에서는 별도의 수정 없이 적용이 가능함
- Classification task 에서는 기존에 GPT-3 에서 사용하던 방식과 달라졌는데, GPT-3 에서는
yes와no에 대한 결과만 고려하여 둘 중 더 높은 prob 를 모델이 선택한 것으로 간주하였음- 그러나, 이러한 방식은
yes를 표현하는 다양한 표현들의 확률을 낮추게 되어 imperfect 함 - 그래서
Options라는 suffix 를 추가 토큰으로 주어, 나올 수 있는 output list 를 넣어줌 (prompts 에서 expected output format 을 넣어주는 것과 유사) - 이는 모델이 대답할 케이스들을 미리 알게하는 효과
- 그러나, 이러한 방식은
2.3 Training details
- Google 의 LaMDA-PT 라는 별도 모델을 실험에 사용
- 기존 LaMDA 모델은 dialog 에 대하여 finetuned 되었기 때문에 그대로 사용하지 않음
- FLAN 방식을 적용할 때에 다양한 dataset 에 대하여 각 dataset 별로 최대 30k 개를 넘지 않게끔 sampling
- 데이터 비율에 맞게 mixing scheme 을 적용하였고, maximum 을 3k 로 하여 이를 초과하는 경우 추가적인 sampling weight 를 받지 않게함
- 총 30k steps 학습 하였고, batch size 8192, Adafactor 사용 (lr = 3e-5)
- Sequence Length 는 Input: 1024, Output: 256 사용
- Input, Output 은 EOS 토큰으로 구분
- TPUv3 with 128 cores 로 60 hours 걸림
3. Results
- Instruction tuning 이 효율적인 영역과 그렇지 않은 영역이 존재
효율적인 영역: tasks naturally verbalized as instruction- NLI, QA, translation, struct-to-text
효율적이지 않은 영역: instructions would be largely redundant (formatted as finishing an incomplete sentence or paragraph)- commonsense reasoning, coreference resolution
- 기존 LM 과 비교하여 크게 성능 향상이 없는 듯함
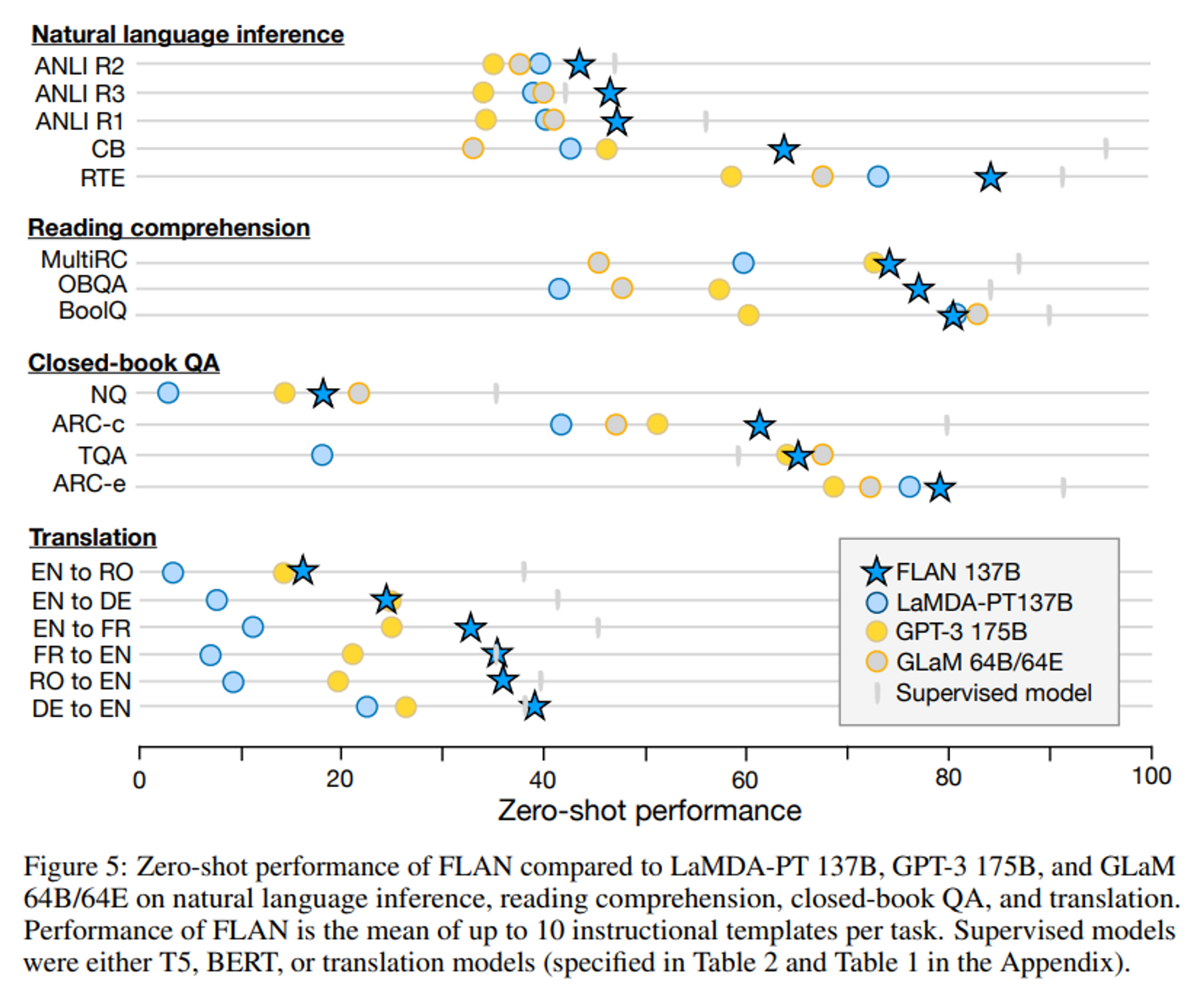
3.1 Natural language inference (NLI)
- given premise 에 대하여 hypothesis 가 true 인 지 아닌 지
- Does [premise] mean that [hypothesis]?
4. Analysis
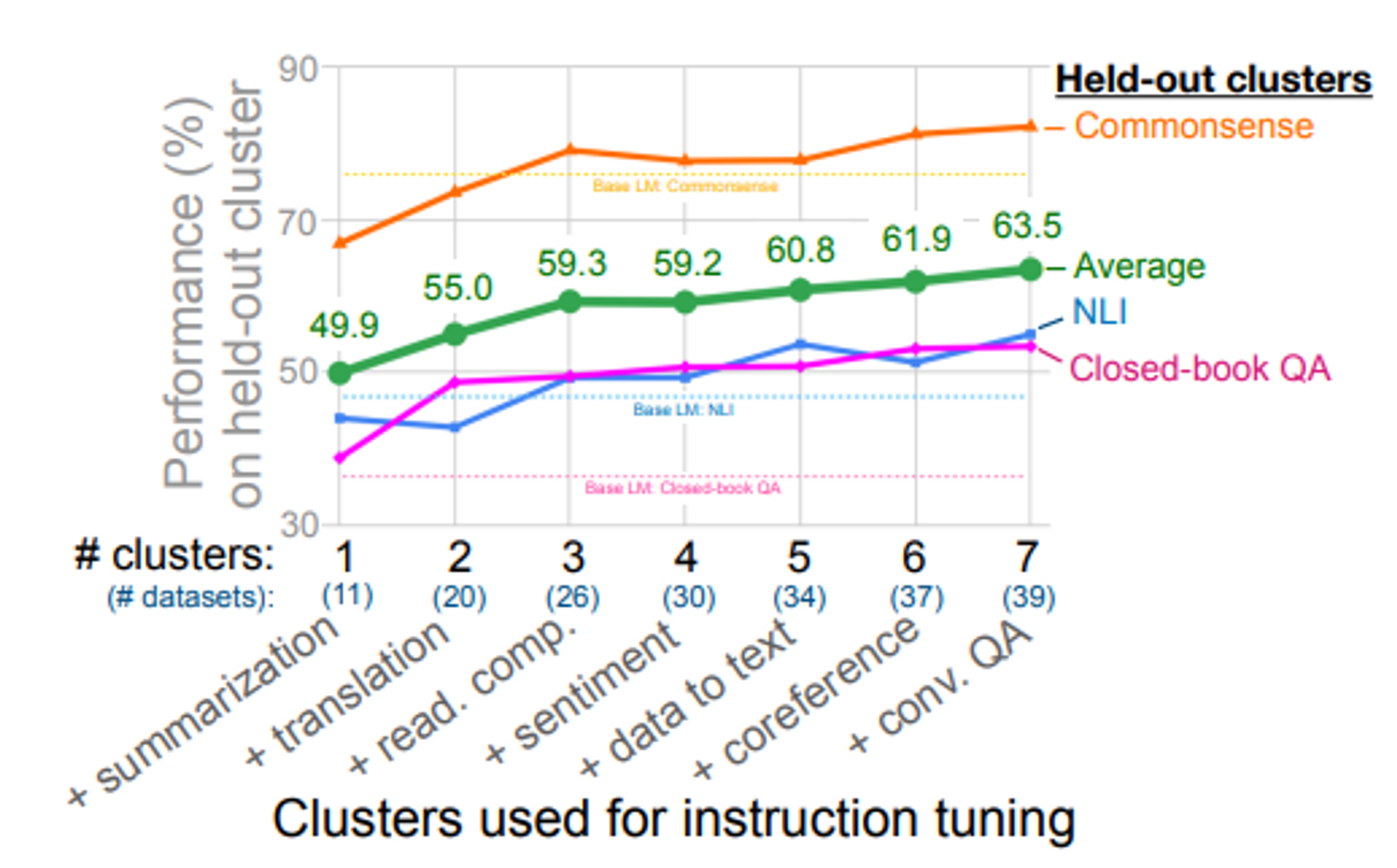
4.1 Cluster 수에 따른 결과
- evaluation 할 때 타겟이 되는 cluster 는 학습에 반영하지 않음
- cluster 수가 늘어나면 unseen task 에 대한 성능이 증가하는 것을 확인
결론: 내가 타겟으로 하는 task 와 관련이 없더라도, 다양한 cluster 의 NLP 데이터셋을 사용할수록 타겟하는 task 의 성능이 오름
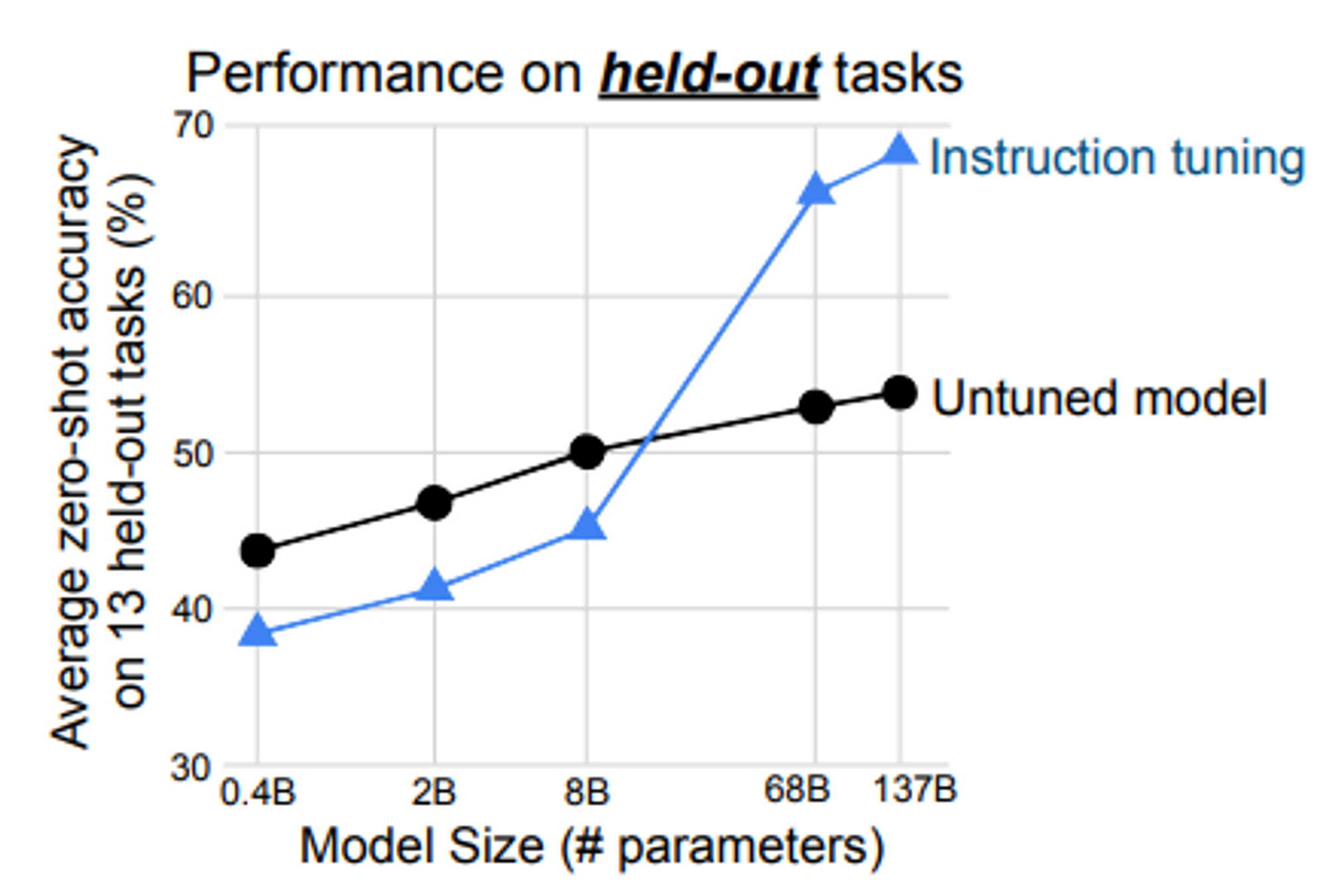
4.2 Scaling laws
- 참고: Scaling Laws for Natural Language Models
- OpenAI 의 Scaling laws 를 동일하게 따름
- 즉, 모델의 크기가 커지만 instruction tuning 성능도 오르는 것을 확인
주의: 8B 보다 작은 크기의 모델은 instruction tuning 방식을 적용하면 성능을 오히려 해침 (모델 capacity 가 작아서 instruction tuning 이 캐피에 너무 큰 영향을 주는 것으로 해석)
- 이는 NLP held-out tasks 에 한해서 나온 zero-shot 결과로, 일반적인 instruction tuning (SFT) 기법을 8B 이하의 모델에 적용하는 것이 좋지 않다는 것을 의미하는 것은 아님
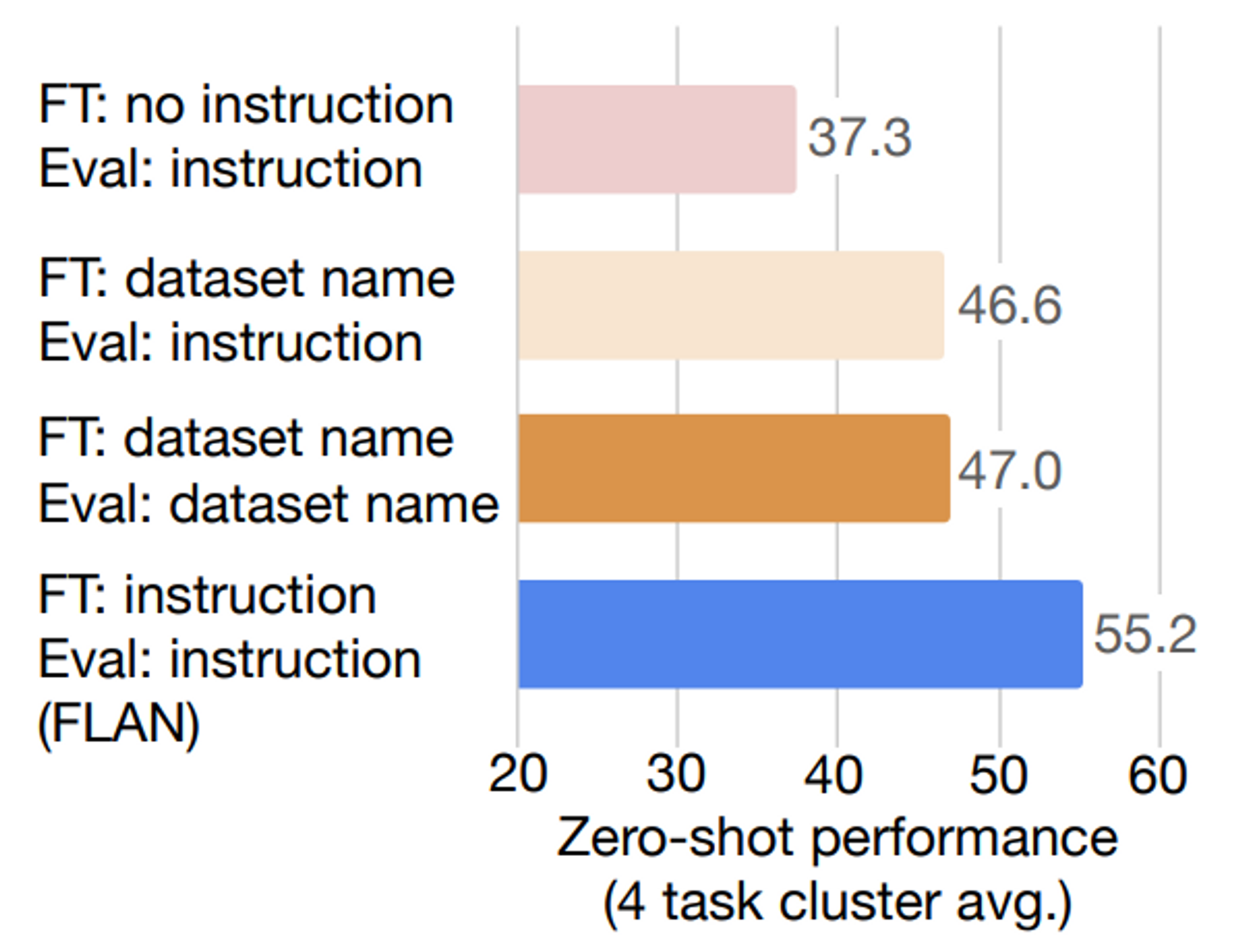
4.3 Role of Instructions
- Instruction template 이 얼마나 영향을 주는 지에 대한 실험
- no instruction: 별도 instruction 없음
- input: The dog runs
- dataset name: task 의 이름을 앞에 기입
- input: [Translation: WMT'14 to French] The dog runs
- instruction: FLAN 방식
- input: Please translate this sentence to French: The dog runs
- no instruction: 별도 instruction 없음
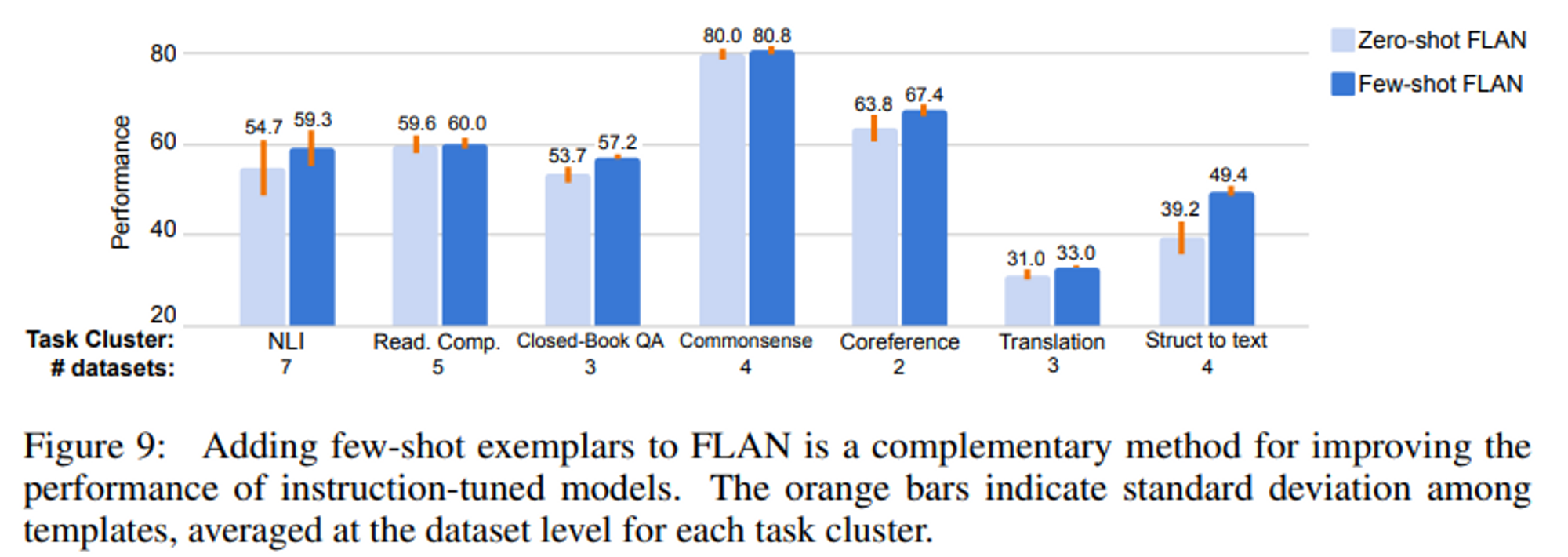
4.4 Instructions with few-shot
- few-shot 에서도 template 잘 동작함
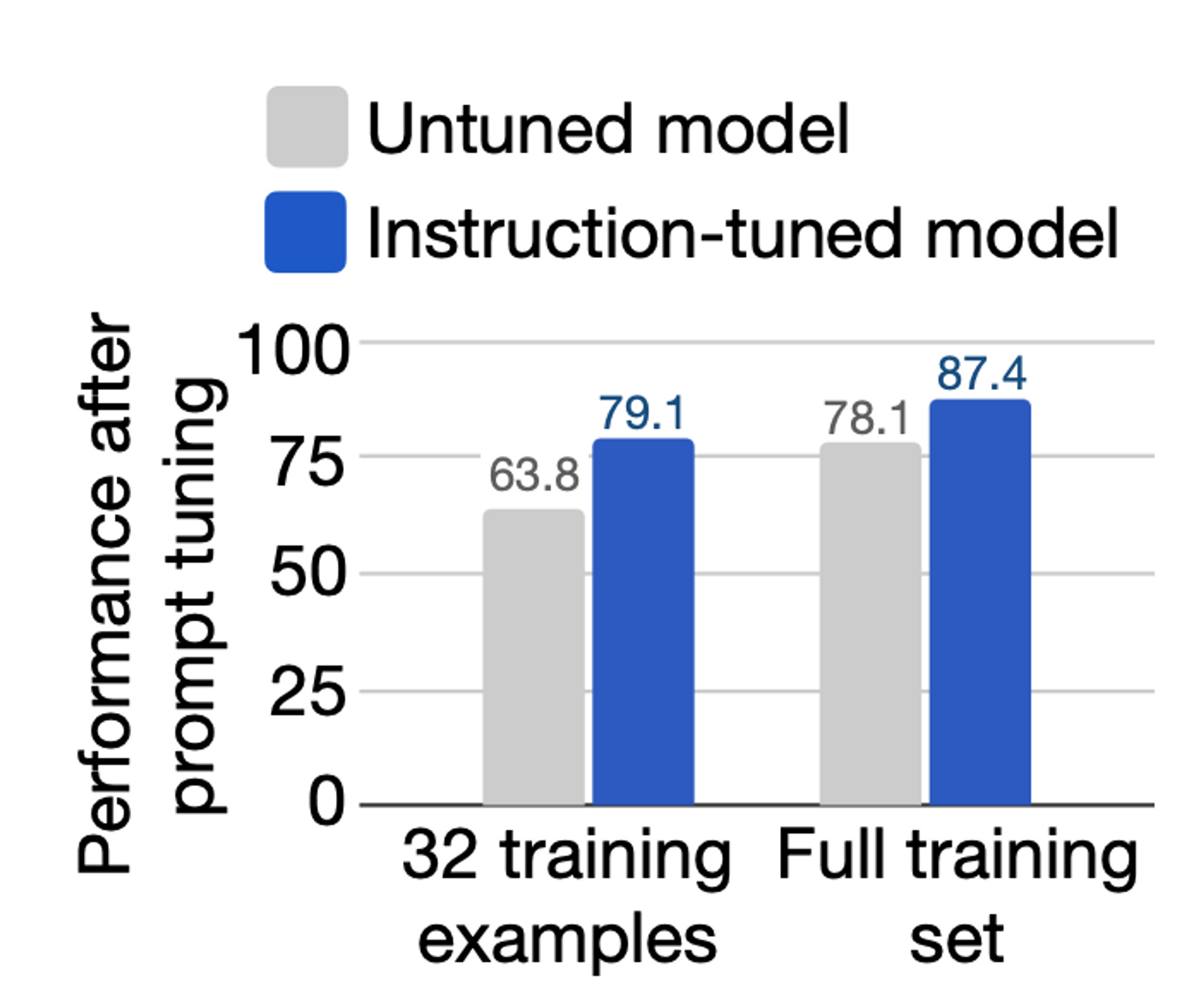
4.5 Instruction tuning facilitates prompt tuning
- prompt tuning 하여 성능을 개선할 때에도 일반 LM 보다는 instruction-tuned model 이 성능이 더 좋음
5. Appendix
5.1 Datasets
- NLI
- ANLI, CB, MNLI, QNLI, SNLI, WNLI, RTE
- Reading Comprehension
- BoolQ Clark, DROP, MultiRC, OBQA, SQuADv1, v2
- Commonsense reasoning
- COPA, HellaSwag, PiQA, StroyCloze
- Sentiment analysis
- IMDB, SENTIMENT140, SST-2, Yelp
- Closed-book QA
- ARC, NQ, TriviaQA
- Paraphrase detection
- MRPC, QQP, Paws Wiki
- Coreference resolution
- DPR, Winogrande, WSC273
- Reading compreshension with commonsense
- CosmosQA, ReCoRD
- Struct to text
- CommonGen, DART, E2ENLG, WebNLG
- Translation
- En-FR from WMT’ 14, En–De, En–Tr, En–Cs, En–Fi, En–Ro, and En–Ru from WMT’16, En–Es from Paracrawl
- Summarization
- AESLC, CNN-DM, Gigaword, MultiNews, Newsroom, Samsum, XSum, AG News, Opinion Abstracts, Wiki Lingua English
- Additional datasets
- Conversational QA: QuAC, CoQA
- Evaluating context-sentence word meanings: WiC
- Question classification: TREC
- Linguistic acceptability: CoLA
- Math questions

ML/DL Engineer 입니다. 유용한 정보들을 기록해두려 합니다.