딥 러닝을 이해하기 위해서는 선형 회귀(Linear Regression)와 로지스틱 회귀(Logistic Regression)를 이해할 필요가 있다.
핵심 키워드
- 선형 회귀(Linear regression)
- 가설(Hypothesis)
- 비용 함수(Cost Function) : 평균 제곱 오차(Mean Squared Error, MSE)
- 옵티마이저(Optimizer) - 경사 하강법(Gradient Descent)
1. 회귀(Regression)
"regression toward the mean" - Sir Francis Galton(1822 ~ 1911)
→ 평균을 향한 회귀
→ 우리는 이를 줄여서 회귀라고 부릅니다.
Sir Francis Galton는 "데이터들은 전체 평균으로 되돌아가려는 특징, 속성이 있다" 라고 하였고 이것이 회귀의 기본 개념이다.
2. 선형 회귀(Linear Regression)의 개념
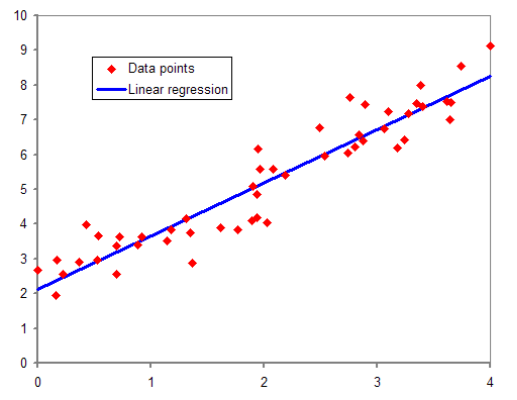
- 시험 공부하는 시간을 늘릴 수록 성적이 잘나옵니다.
- 하루에 걷는 횟수를 늘릴 수록 몸무게는 줄어듭니다.
- 집의 평수가 클수록 집의 매매가격은 비싼 경향이 있습니다.
이는 수학적으로 생각해보면 어떤 변수 x의 값에 따라서 특정 변수의 y의 값이 영향을 받고 있다고 볼 수 있습니다.
이때 독립적으로 변할 수 있는 변수 x를 독립 변수, x의 값에 의해서 종속적으로 결정되는 변수 y를 종속 변수라고도 합니다.
선형 회귀는 한 개 이상의 독립 변수 x와 y의 선형 관계를 모델링합니다.
만약, 독립 변수 x가 1개라면 단순 선형 회귀라고 합니다.
2.1 단순 선형 회귀 분석(Simple Linear Regression Analysis)
독립 변수가 x 한 개인 경우에 사용합니다.
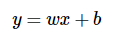
- 독립변수 x와 곱해지는 값 w를 머신 러닝에서는 가중치(weight), 별도로 더해지는 값 b를 편향(bias)이라고 합니다.
- 직선의 방정식에서는 각각 직선의 기울기와 절편을 의미합니다.
2.2 다중 선형 회귀 분석(Multiple Linear Regression Analysis)
독립 변수 x가 1개가 아니라 여러개인 경우에 사용합니다.
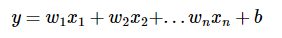
- 집의 매매 가격은 단순히 집의 평수가 크다고 결정되는 게 아니라 집의 층의 수, 방의 개수, 지하철 역과의 거리와도 영향이 있습니다.
- 이러한 다수의 요소를 가지고 집의 매매 가격을 예측해보고 싶을 때 y는 여전히 1개이지만 x는 여러개가 됩니다.
3. 선형 회귀(Linear Regression) 분석의 과정
먼저 단순 선형 회귀 예제를 통해서 문제를 풀어보고 개념들에 대해 설명하겠습니다.
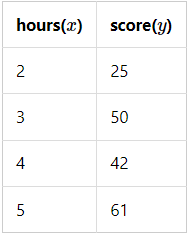
문제
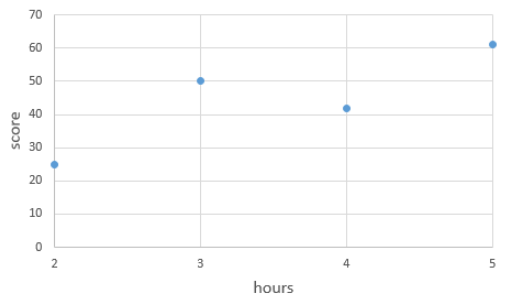
- 어떤 학생의 공부 시간에 따라서 다음과 같은 점수를 얻었다는 데이터가 있습니다.
- 알고있는 데이터를 이용해서 이 학생이 6시간, 7시간, 8시간을 공부하였을 때의 성적을 예측해보고 싶습니다.
표로 나타내면 다음과 같습니다.
이를 좌표평면으로 나타내면 다음과 같습니다.
3.1 가설(Hypothesis)
x와 y의 관계를 유추하기 위해서 수학적으로 식을 세워보게 되는데 머신 러닝에서는 이러한 식을 가설(Hypothesis)이라고 합니다.
- H(x) = wx + b
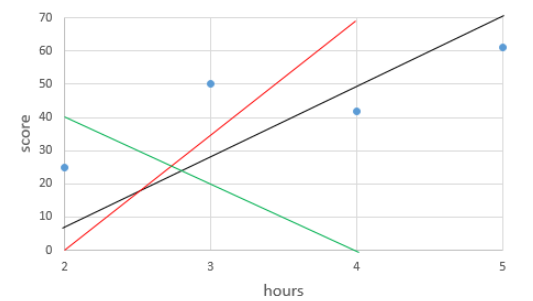
위의 그림은 w와 b의 값에 따라서 그려지는 직선의 모습을 보여줍니다.
- 선형 회귀 분석은 최적의 가설을 찾는 일입니다.
- 즉, 주어진 데이터로부터 y와 x의 관계를 가장 잘 나타내는 직선을 그리는 일을 말합니다.
- 그리고 어떤 직선인지 결정하는 것은 w와 b의 값이므로 선형 회귀에서 해야할 일은 결국 적절한 w와 b를 찾아내는 일이 됩니다.
3.2 비용 함수(Cost function) : 평균 제곱 오차(Mean Sqared Error, MSE)
앞서 주어진 데이터에서 x와 y의 관계를 w와 b를 이용하여 식을 세우는 일을 가설이라고 했습니다.
이제 해야할 일은 문제에 대한 규칙을 가장 잘 표현하는 w와 b를 찾는 일입니다.
머신 러닝은 w와 b를 찾기 위해서 실제값과 가설로부터 얻은 예측값의 오차를 계산하는 식을 세우고, 이 값을 최소화하는 최적의 w와 b를 찾아냅니다.
이때 실제값과 예측값에 대한 오차에 대한 식을 목적 함수(Objective function) 또는 비용 함수(Cost function) 또는 손실 함수(Loss function) 라고 부릅니다.
- 엄밀히 말하면 함수의 값을 최소화하거나, 최대화하거나 하는 목적을 가진 함수를 목적 함수라고 합니다.
- 값을 최소화하려고 하면 이를 비용 함수 또는 손실 함수라고 합니다.
비용 함수는 단순히 실제값과 예측값에 대한 오차를 표현하면 되는 것이 아니라, 예측값의 오차를 줄이는 일에 최적화 된 식이어야 합니다.
회귀 문제의 경우에는 주로 평균 제곱 오차(Mean Squared Error, MSE)가 사용됩니다.
3.2.1 평균 제곱 오차(Mean Sqared Error, MSE)
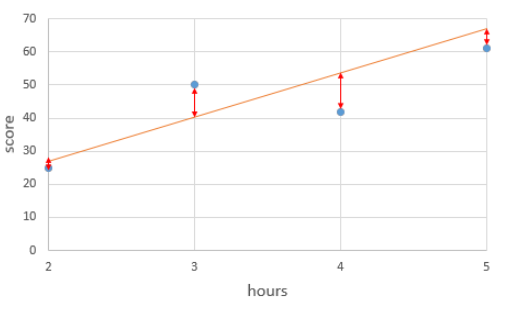
위의 그래프에 임의의 w의 값 13과 임의의 b의 값 1을 가진 직선을 그렸습니다. 임의로 그린 직선으로 정답이 아닙니다.
이제 이 직선으로부터 서서히 w와 b의 값을 바꾸면서 정답인 직선을 찾아내야 합니다.
y와 x의 관계를 가장 잘 나타내는 직선을 그린다는 것은 위의 그림에서 모든 점들과 위치적으로 가장 가까운 직선을 그린다는 것과 같습니다.
오차는 주어진 데이터에서 각 x에서의 실제값 y와 위의 직선에서 예측하고 있는 H(x)값의 차이를 말합니다.
즉 위의 그림에서 ↕는 각 점에서의 오차의 크기를 보여줍니다.
오차를 줄여가면서 w와 b의 값을 찾아내기 위해서는 전체 오차의 크기를 구해야 합니다.
오차의 크기를 측정하기 위한 가장 기본적인 방법은 각 오차를 모두 더하는 방법이 있습니다.
위의 y = 13x + 1 직선이 예측한 예측값을 각각 실제값으로부터 오차를 계산하여 표를 만들어보면 아래와 같습니다.
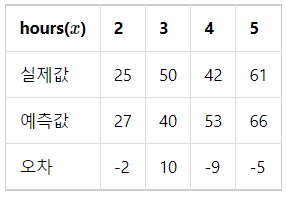
그런데 수식적으로 단순히 '오차 = 실제값 - 예측값' 이라고 정의한 후에 모든 오차를 더하면 음수 오차도 있고, 양수 오차도 있으므로 오차의 절대적인 크기를 구할 수가 없습니다.
그래서 모든 오차를 제곱하여 더하는 방법을 사용합니다.
이를 수식으로 표현하면 아래와 같습니다.
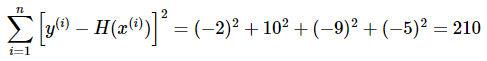
이때 데이터의 개수인 n으로 나누면, 오차의 제곱합에 대한 평균을 구할 수 있는데 이를 평균 제곱 오차(Mean Squered Error, MSE)라고 합니다.
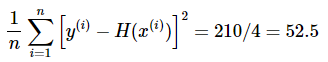
평균 제곱 오차를 w와 b에 의한 비용 함수(Cost function)로 재정의해보면 다음과 같습니다.
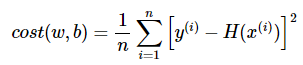
모든 점들과의 오차가 클 수록 평균 제곱 오차는 커지며, 오차가 작아질 수록 평균 제곱 오차는 작아집니다.
그러므로 이 평균 제곱 오차 즉 Cost(w,b)를 최소가 되게 만드는 w와 b를 구하면 결과적으로 y와 x의 관계를 가장 잘 나타내는 직선을 그릴 수 있습니다.
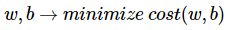
3.3 옵티마이저(Optimizer) : 경사하강법(Gradient Descent)
머신 러닝, 딥 러닝의 학습은 결국 비용 함수를 최소화하는 매개 변수인 w와 b를 찾기 위한 작업을 수행합니다.
이때 사용되는 알고리즘을 옵티마이저(Optimizer) 또는 최적화 알고리즘이라고 부릅니다.
그리고 이 옵티마이저를 통해 적절한 w와 b를 찾아내는 과정을 머신 러닝에서 훈련(training) 또는 학습(learning)이라고 부릅니다.
여기서는 가장 기본적인 옵티마이저 알고리즘인 경사 하강법(Gradient Descent)에 대해서 설명합니다.
경사 하강법을 이해하기 위해서 cost와 기울기 w와의 관계를 이해해보겠습니다.
w는 머신 러닝 용어로는 가중치라고 불리지만, 직선의 방정식 관점에서 보면 직선의 기울기를 의미하고 있습니다.
아래의 그래프는 기울기 w가 지나치게 높거나, 낮을 때 어떻게 오차가 커지는 모습을 보여줍니다.
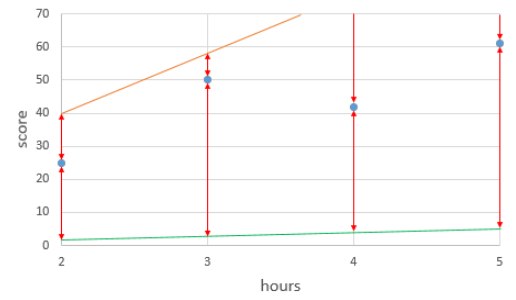
위의 그림에서 주확색선은 기울기 w가 20일 때 , 초록색선은 기울기 w가 1일 때를 보여줍니다.
각각 y= 20x, y=x에 해당되는 직선입니다.
↕는 각 점에서의 실제값과 두 직선의 예측값과의 오차를 보여줍니다.
기울기가 지나치게 크면 실제값과 예측값의 오차가 커지고, 기울기가 지나치게 작아도 실제값과 예측값의 오차가 커집니다.
사실 b또한 마찬가지인데 b가 지나치게 크거나 작으면 오차가 커집니다.
설명의 편의를 위해 편향 b가 없이 단순히 가중치 w만을 사용한 y = wx라는 가설 H(x)를 가지고, 경사 하강법을 수행한다고 하겠습니다.
이에 따라 w와 cost의 관계를 그래프로 표현하면 다음과 같습니다.
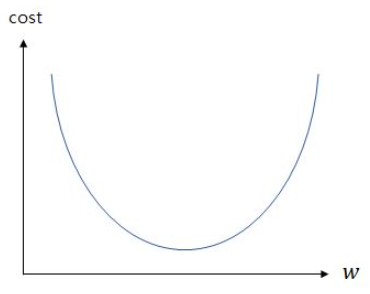
기울기 w가 무한대로 커지면 커질 수록 cost의 값 또한 무한대로 커지고, 반대로 기울기 w가 무한대로 작아져도 cost의 값은 무한대로 커집니다.
위의 그래프에서 cost가 가장 작을 때는 볼록한 부분의 맨 아래 부분입니다.
기계가 해야할 일은 cost가 가장 최소값을 가지게 하는 w를 찾는 일이므로, 볼록한 부분의 맨 아래 부분의 w의 값을 찾아야 합니다.
3.3.1 경사 하강법(Gradient descent)
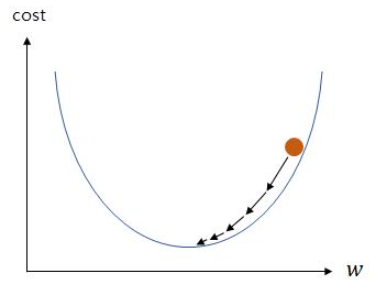
기계는 임의의 랜덤값 w값을 정한 뒤에, 맨 아래의 볼록한 부분을 향해 점차 w의 값을 수정해나갑니다.
위의 그림은 w값이 점차 수정되는 과정을 보여줍니다.
경사 하강법은 미분의 개념인 한 점에서의 순간 변화율 또는 다른 표현으로는 접선의 기울기의 개념을 사용합니다.
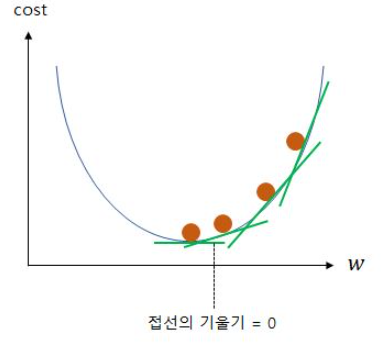
위의 그림에서 초록색 선은 w가 임의의 값을 가지게 되는 네 가지의 경우에 대해서, 그래프 상으로 접선의 기울기를 보여줍니다.
주목할 것은 맨 아래의 볼록한 부분으로 갈수록 접선의 기울기가 점차 작아진다는 점입니다.
그리고 맨 아래의 볼록한 부분에서는 결국 접선의 기울기가 0이 됩니다. 그래프 상으로 초록색 선이 수평이 되는 지점입니다.
즉, cost가 최소화가 되는 지점은 접선의 기울기가 0이 되는 지점이며, 또한 미분값이 0이 되는 지점입니다.
경사 하강법의 아이디어는 다음과 같습니다.
- 비용 함수(Cost function)를 미분하여 현재 w에서의 접선의 기울기를 구합니다
- 접선의 기울기가 낮은 방향으로 w의 값을 변경합니다.
- 다시 미분합니다.
위의 과정을 접선의 기울기가 0인 곳을 향해 w의 값을 변경하는 작업을 반복하는 것입니다.
비용 함수(Cost function)은 아래와 같았습니다.
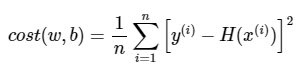
이제 비용(cost)를 최소화하는 w를 구하기 위해 w를 업데이트하는 식은 다음과 같습니다.
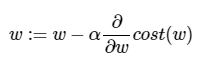
- α(알파)는 learning rate(학습률)을 나타냅니다
- 주로 0.001등과 같이 작은 수를 통해 W의 변화량을 조절하는 목적으로 사용됩니다.
- ∂(델)은 편미분을 나타냅니다.
현재 w에서 현재w에서의 접선의 기울기를 빼는 행위가 어떤 의미가 있는지 알아보겠습니다.
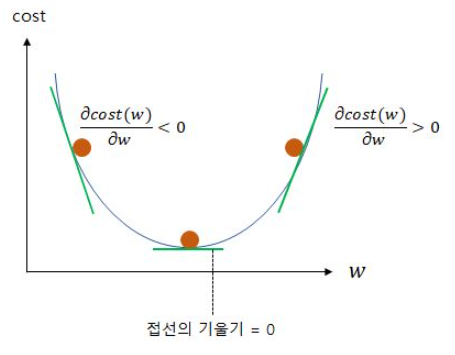
위의 그림은 접선의 기울기가 음수일 때, 0일 때, 양수일 때를 보여줍니다.
접선의 기울기가 음수일 때의 수식은 아래와 같이 표현 할 수 있습니다.
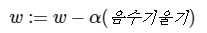
기울기가 음수면 '음수를 빼는 것'은 곧 '해당 값을 양수로 바꾸고 더하는 것'과 같습니다.
결국 음수 기울기를 빼면 w의 값이 증가하게 되는데 이는 결과적으로 접선의 기울기가 0인 방향으로 w의 값이 조정됩니다.
기울기가 양수일 때의 수식은 아래와 같습니다.
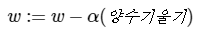
기울기가 양수면 w의 값이 감소하게 되는데 이는 결과적으로 기울기가 0인 방향으로 w의 값이 조정됩니다.
결국, 아래의 수식은 접선의 기울기가 음수거나, 양수일 때 모두 접선의 기울기가 0인 방향으로 w의 값을 조정합니다.
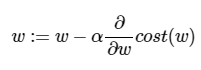
학습률(learning rate, α)는 w의 값을 변경할 때, 얼마나 크게 변경할지를 결정하며 0과 1사이의 값을 가지도록 합니다.
학습률은 w를 그래프의 한 점으로 보고 접선의 기울기가 0일 때까지 경사를 따라 내려간다는 관점에서는 얼마나 큰 폭으로 이동할지를 결정합니다.
직관적으로 생각하기에 학습률 α의 값을 무작정 크게 하면 접선의 기울기가 최소값이 되는 w를 빠르게 찾을 수 있을 것 같지만 그렇지 않습니다.
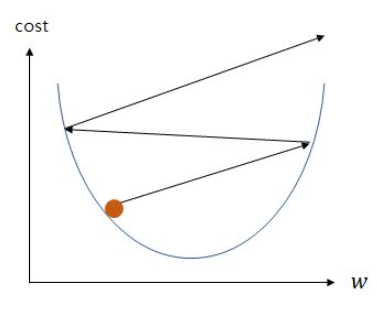
위의 그림은 학습률 α가 지나치게 높은 값을 가질 때, w의 값이 발산하는 상황을 보여줍니다.
반대로 학습률 α가 지나치게 낮은 값을 가지면 학습 속도가 느려지므로 적당한 α의 값을 찾아내는 것도 중요합니다.
정리
- 가설, 비용 함수, 옵티마이저는 머신 러닝 분야에서 사용되는 포괄적 개념입니다.
- 풀고자하는 각 문제에 따라 가설, 비용 함수, 옵티마이저는 전부 다를 수 있으며 선형 회귀에 가장 적합한 비용 함수와 옵티마이저가 알려져 있는데 여기서 언급된 평균 제곱 오차(MSE)와 경사 하강법(Gradient descent)이 이에 해당됩니다.
4. 코드를 이용한 간단한 실습
사용할 데이터는 다음과 같습니다.
공부한 시간이 x, 공부한 시간에 따른 성적이 y라고 할 때 x와 y가 약 10배의 차이를 가지는 데이터입니다.
x = [1, 2, 3, 4, 5, 6, 7, 8, 9]
y = [11, 22, 33, 44, 53, 66, 77, 87, 95]4.1 TensorFlow를 이용한 선형 회귀 구현
- 임의의 w와 b의 초기값을 정합니다.
- 학습률을 0.01로 지정합니다.
- 훈련 횟수를 300으로 지정합니다.
- tensorflow의 GradientTape을 통해 지속적인 변수의 값의 변화를 저장합니다.
- 결과로 나온 w와 b값을 통한 가설을 세워 예측을 해봅니다.
import tensorflow as tf
x = [1, 2, 3, 4, 5, 6, 7, 8, 9] # 공부하는 시간
y = [11, 22, 33, 44, 53, 66, 77, 87, 95] # 각 공부하는 시간에 맵핑되는 성적
# w와 b의 초기값을 임의로 지정
w = tf.Variable(10.0)
b = tf.Variable(1.0)
learning_rate = 0.01 # 학습률
# 훈련 횟수는 300번으로 지정했습니다.
for i in range(300):
# GradientTape은 보통 with와 같이 쓰이는데
# with 안의 변수들의 변화되는 정보를 tape에 기록하고
# 이후에 tape의 gradient 메서드를 호출하여 경사도(미분)값을 구합니다.
with tf.GradientTape() as tape:
hypothesis = w * x + b # 가설
cost = tf.reduce_mean(tf.square(hypothesis - y)) # 비용
W_grad, b_grad = tape.gradient(cost, [w, b])
# assign_sub() 메서드는 해당 값을 빼서 다시 할당 해줍니다.
# python의 A -= B와 동일합니다.
w.assign_sub(learning_rate * W_grad)
b.assign_sub(learning_rate * b_grad)
print(f"w: {w.numpy()} | b: {b.numpy()} | cost: {cost:.6f}")
# w: 10.669668197631836 | b: 0.8915395140647888 | cost: 1.061446
# 예측 함수
def predict(w, b, x):
return w * x + b
print(predict(w.numpy(), b.numpy(), 9.5))
# 102.253387391567234.2 keras를 이용한 선형 회귀 구현
케라스로 모델을 만드는 기본적인 형식은 다음과 같습니다.
- Sequential로 model이라는 이름의 모델을 만들고, add를 통해 입력과 출력 벡터의 차원과 같은 필요한 정보들을 추가해갑니다.
- activation은 어떤 함수를 사용할 것인지를 의미하는데 선형 회귀를 사용할 경우에는 linear라고 기재합니다.
- 옵티마이저로 기본 경사 하강법을 사용하고 싶다면 sgd라고 기재합니다.
- sgd 는 정확히는 확률적 경사 하강법(Stochastic Gradient Descent)으로, 전체 데이터가 아닌 일부 데이터의 모음을 사용하는 방법입니다.
학습률은 0.01로 정하였습니다.
손실 함수로는 평균 제곱 오차(MSE)를 사용합니다.
전체 데이터에 대한 훈련 횟수는 300으로 합니다.
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
x = [1, 2, 3, 4, 5, 6, 7, 8, 9] # 공부하는 시간
y = [11, 22, 33, 44, 53, 66, 77, 87, 95] # 각 공부하는 시간에 맵핑되는 성적
model = Sequential()
# 출력 y의 차원은 1. 입력 x의 차원(input_dim)은 1
# 선형 회귀이므로 activation은 'linear'
model.add(Dense(1, input_dim=1, activation='linear'))
# sgd는 경사 하강법을 의미. 학습률(learning rate, lr)은 0.01.
sgd = optimizers.SGD(lr=0.01)
# 손실 함수(Loss function)은 평균제곱오차 mse를 사용합니다.
model.compile(optimizer=sgd, loss='mse', metrics=['mse'])
# 주어진 x와 y데이터에 대해서 오차를 최소화하는 작업을 300번 시도합니다.
model.fit(x, y, epochs=300)
# model.predict()은 학습이 완료된 모델이 입력된 데이터에 대해서 어떤 값을 예측하는지 보여줍니다.
print(model.predict([9.5]))
# [[98.556465]]최종적으로 선택된 오차를 최소화하는 직선은 다음과 같습니다.
plt.plot(x, model.predict(x), 'b', x, y, 'k.')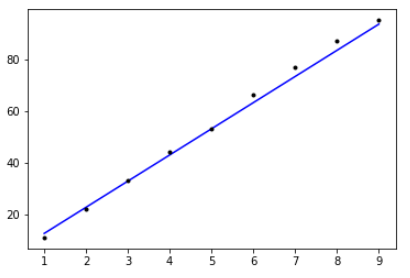
4.3 사이킷런(scikit-learn)을 이용한 선형 회귀 구현
사이킷런을 이용해 구현하는 방법은 단순합니다.
- 필요한 모델을 선언합니다.
- 해당 모델에 데이터를 넣습니다.
- 하이퍼 파라미터의 조정이 필요할 시 하이퍼 파라미터를 조정합니다.
import numpy as np
from sklearn.linear_model import LinearRegression
x = [1, 2, 3, 4, 5, 6, 7, 8, 9] # 공부하는 시간
# x = [[1], [2], [3], [4], [5], [6], [7], [8], [9]] # 공부하는 시간
y = [11, 22, 33, 44, 53, 66, 77, 87, 95] # 각 공부하는 시간에 맵핑되는 성적
# 모델은 선형 회귀인 LinearRegression
model = LinearRegression()
# 모델에 데이터를 넣어 훈련을 시킵니다.
# fit() 메서드는 선형 회귀 모델에 필요한 두 가지 변수를 전달합니다.
# 기울기 : model.coef_
# 절편 : model.intercept_
# 주의 할 점은 x 데이터를 넣을 때 .reshape(-1, 1)을 해준 점입니다.
# LinearRegression은 다중 선형 회귀 분석에도 사용되므로
# x의 변수가 하나가 아니라 여러개일 때 분석을 실시하기 위한 경우를 위해
# x는 2차원 array 형태여야 하기 때문입니다.
# x = [[1], [2], [3], [4], [5], [6], [7], [8], [9]]
x = np.array(x).reshape(-1, 1)
model.fit(x, y)
# model.predict()은 학습이 완료된 모델이 입력된 데이터에 대해서 어떤 값을 예측하는지 보여줍니다.
# 마찬가지로 2차원 array로 넣어줍니다.
print(model.predict([[9.5]]))
# [102.29722222]