문제
Pivot the Occupation column in OCCUPATIONS so that each Name is sorted alphabetically and displayed underneath its corresponding Occupation. The output column headers should be Doctor, Professor, Singer, and Actor, respectively.
Note: Print NULL when there are no more names corresponding to an occupation.
Input Format
The OCCUPATIONS table is described as follows:

Occupation will only contain one of the following values: Doctor, Professor, Singer or Actor.
Sample Input
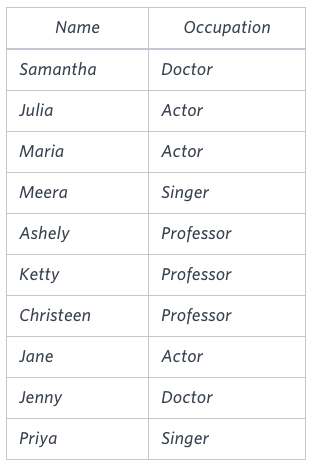
Sample Output
Jenny Ashley Meera Jane
Samantha Christeen Priya Julia
NULL Ketty NULL MariaExplanation
The first column is an alphabetically ordered list of Doctor names.
The second column is an alphabetically ordered list of Professor names.
The third column is an alphabetically ordered list of Singer names.
The fourth column is an alphabetically ordered list of Actor names.
The empty cell data for columns with less than the maximum number of names per occupation (in this case, the Professor and Actor columns) are filled with NULL values.
해석
pivot Table : 개별 항목을 집계 하는 그룹화된 값 테이블
즉, 요구사항으로 보았을 때 피봇 테이블을 사용하여 요구사항에 맞는 컬럼값을 가지도록 테이블을 만들고 이를 서브쿼리로 SELECT 해줘야 함을 알 수 있다
Sample Output: row 는 이름순으로, col 은 순차적으로 Doctor, Professor, Singer, Actor 이다- 문제의 요구사항에서 Occupation 에 해당하는 직업군은 위 네가지로 한정된다고 명시되어 있다
- 피봇 테이블이라는 힌트가 나왔을 때 집계 함수를 사용하여
group by를 사용해야 함을 알 수 있다
문제 풀이
1. 먼저 피봇 테이블을 생성한다
MySql, Oracle, teradata등에서 사용되는 row_number() 내장 함수를 사용하여 집계 테이블을 생성
SQL문
SELECT *,
ROW_NUMBER() OVER (PARTITION BY OCCUPATION ORDER BY NAME)
FROM OCCUPATIONS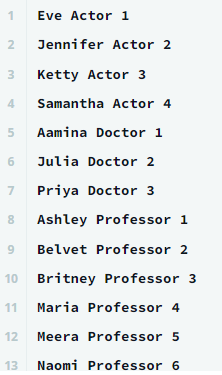
- Partition By : grouping을 통해 row_number를 계산하는데 활용
- Order By : 그루핑된 테이블에서 이름을 기준으로 정렬
2. 피봇 테이블을 참조하는 테이블에서 만약 ROW 가 있을때 ROW의 순서대로 이름이 출력되도록 한다
- EX ) 위 그림에서 ACTOR의 ROW는 1,2,3,4 / DOCTOR의 경우 1,2,3 이다. 이때
MIN()을 사용하여 각 ROW 별로 이름을 출력해준다 MIN()을 사용하는 이유는 만약 해당 칼럼이 없을때 NULL 이 반환되어야 하기 때문
최종 코드
SELECT MIN(CASE WHEN OCCUPATION = 'DOCTOR' THEN NAME END),
MIN(CASE WHEN OCCUPATION = 'PROFESSOR' THEN NAME END),
MIN(CASE WHEN OCCUPATION = 'SINGER' THEN NAME END),
MIN(CASE WHEN OCCUPATION = 'ACTOR' THEN NAME END)
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY OCCUPATION ORDER BY NAME) AS R
FROM OCCUPATIONS ) AS TMP
GROUP BY TMP.R- 최종적으로 group by 를 사용하여 피봇을 기준으로 그룹화시킨다

139개의 댓글

Yes i am totally agreed with this article and i just want say that this article is very nice and very informative article.I will make sure to be reading your blog more. You made a good point but I can't help but wonder, what about the other side? !!!!!!Thanks what is my ip number

Thanks for taking the time to discuss that, I feel strongly about this and so really like getting to know more on this kind of field. Do you mind updating your blog post with additional insight? It should be really useful for all of us. restroom rentals

Kudos meant for giving you newly released tweets regarding the headache, That i will enjoy look over even more. iptv uk
What a fantabulous post this has been. Never seen this kind of useful post. I am grateful to you and expect more number of posts like these. Thank you very much. 도박꾼
Believe it or not, it is the type of information I’ve long been trying to find. It matches to my requirements a lot. Thank you for writing this information. slot gacor hari ini
Believe it or not, it is the type of information I’ve long been trying to find. It matches to my requirements a lot. Thank you for writing this information. turbox500
Believe it or not, it is the type of information I’ve long been trying to find. It matches to my requirements a lot. Thank you for writing this information. slot gacor
It's which means that amazing together with inspiring. We really enjoy any designs together with whoever should get it all during the post shall be grinning. 아이디판매
Your blog is too much amazing. I have found with ease what I was looking. Moreover, the content quality is awesome. Thanks for the nudge! vviavi slot
Use the 1XBONO25 code to get a 100% bonus up to $130 at 1xBet. Whether you're a fan of sports betting or love casino games, this offer gives you more to play with from your first deposit. como liberar el bono de 1xbet
Your blog is too much amazing. I have found with ease what I was looking. Moreover, the content quality is awesome. Thanks for the nudge! situs judi
Le code promo 1xBet 2025: 1XNEW25, saississez-le lors de votre inscription pour recevoir un bonus jusqu'à $130 sur le sport. Vous pourrez aussi obtenir jusqu'à $1,500 et 150 tours gratuits sur le casino. 1xBet propose jusqu'à $130 de freebets selon le montant de votre premier dépôt sur les paris sportifs. Parmi eux, le bonus de bienvenue, réservé aux nouveaux inscrits sur la plateforme. Cette plateforme est classée parmi les leaders en Afrique et à travers le monde. Elle vous offre les meilleures options pour vos paris, y compris la diffusion en direct des matchs sans frais supplémentaires. 1xbet 2025
Your blog is too much amazing. I have found with ease what I was looking. Moreover, the content quality is awesome. Thanks for the nudge! slot slot online
Use the 1win promo code MAX500WIN to get a 500% bonus on your first deposits. New players can enjoy up to $1025 in rewards across the first four deposits. Don’t wait—claim your bonus and start playing today! 1win promo code
I definitely enjoying every little bit of it. It is a great website and nice share. I want to thank you. Good job! You guys do a great blog, and have some great contents. Keep up the good work. situs slot terpercaya
I definitely enjoying every little bit of it. It is a great website and nice share. I want to thank you. Good job! You guys do a great blog, and have some great contents. Keep up the good work. slot online
I definitely enjoying every little bit of it. It is a great website and nice share. I want to thank you. Good job! You guys do a great blog, and have some great contents. Keep up the good work. situs toto alternatif
I definitely enjoying every little bit of it. It is a great website and nice share. I want to thank you. Good job! You guys do a great blog, and have some great contents. Keep up the good work. سایت بت لانا کازینو
This is a great post. I like this topic.This site has lots of advantage.I found many interesting things from this site. It helps me in many ways.Thanks for posting this again. 카지노 솔루션
I felt very happy while reading this site. This was really very informative site for me. I really liked it. This was really a cordial post. Thanks a lot!. 토토솔루션
I definitely enjoying every little bit of it. It is a great website and nice share. I want to thank you. Good job! You guys do a great blog, and have some great contents. Keep up the good work. toto
I definitely enjoying every little bit of it. It is a great website and nice share. I want to thank you. Good job! You guys do a great blog, and have some great contents. Keep up the good work. tototogel
I definitely enjoying every little bit of it. It is a great website and nice share. I want to thank you. Good job! You guys do a great blog, and have some great contents. Keep up the good work. toto
I definitely enjoying every little bit of it. It is a great website and nice share. I want to thank you. Good job! You guys do a great blog, and have some great contents. Keep up the good work. toto
I definitely enjoying every little bit of it. It is a great website and nice share. I want to thank you. Good job! You guys do a great blog, and have some great contents. Keep up the good work. 토토사이트 경찰조사 후기
Thanks for the blog filled with so many information. Stopping by your blog helped me to get what I was looking for. Now my task has become as easy as ABC. 토토커뮤니티
Thanks for the blog filled with so many information. Stopping by your blog helped me to get what I was looking for. Now my task has become as easy as ABC. 홈페이지 제작

My partner and i astonished with all the examination an individual built to get this distinct distribute extraordinary. Great action! 알리 프로모션코드
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work. slot asia hoki
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work. geishatoto
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work. toto
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like y our style. Thanks a million and please keep up the effective work. slot hoki asia
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work. Slot Gacor 777
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. judi bola parlay
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. 안전놀이터
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. 홈페이지 제작
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. 토토커뮤니티
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. Ostéopathe Rezé sportif
The website is looking bit flashy and it catches the visitors eyes. Design is pretty simple and a good user friendly interface. Hgh
Thanks for taking the time to discuss this, I feel strongly that love and read more on this topic. If possible, such as gain knowledge, would you mind updating your blog with additional information? It is very useful for me. Peptite
I am impressed. I don't think Ive met anyone who knows as much about this subject as you do. You are truly well informed and very intelligent. You wrote something that people could understand and made the subject intriguing for everyone. Really, great blog you have got here. 7meter
I have read your blog it is very helpful for me. I want to say thanks to you. I have bookmark your site for future updates. warungbetting daftar situs slot gacor situs slot gacor demo pragmatic

I high appreciate this post. It’s hard to find the good from the bad sometimes, but I think you’ve nailed it! would you mind updating your blog with more information?
Positive site, where did u come up with the information on this posting? I'm pleased I discovered it though, ill be checking back soon to find out what additional posts you include. 안산 셔츠룸
I would like to say that this blog really convinced me to do it! Thanks, very good post. daftar situs toto
I would like to say that this blog really convinced me to do it! Thanks, very good post. 토토커뮤니티
I would like to say that this blog really convinced me to do it! Thanks, very good post. 해외축구중계
I would like to say that this blog really convinced me to do it! Thanks, very good post. 토토사이트추천
I would like to say that this blog really convinced me to do it! Thanks, very good post. 토토사이트추천
i never know the use of adobe shadow until i saw this post. thank you for this! this is very helpfulagenolx.
i never know the use of adobe shadow until i saw this post. thank you for this! this is very helpfulagenolx.
This is my first time i visit here. I found so many interesting stuff in your blog especially its discussion. From the tons of comments on your articles, I guess I am not the only one having all the enjoyment here keep up the good work GullyBet deposit methods
Thanks for posting this info. I just want to let you know that I just check out your site and I find it very interesting and informative. I can't wait to read lots of your posts. pass prop firm
Nice post! This is a very nice blog that I will definitively come back to more times this year! Thanks for informative post.GullyBet payment options
I am incapable of reading articles online very often, but I’m happy I did today. It is very well written, and your points are well-expressed. I request you warmly, please, don’t ever stop writing. togel
I have read all the comments and suggestions posted by the visitors for this article are very fine,We will wait for your next article so only.Thanks! bandar toto macau
I have read all the comments and suggestions posted by the visitors for this article are very fine,We will wait for your next article so only.Thanks! olxtoto slot
I have read all the comments and suggestions posted by the visitors for this article are very fine,We will wait for your next article so only.Thanks! togel online
I have read all the comments and suggestions posted by the visitors for this article are very fine,We will wait for your next article so only.Thanks! live sgp
I have read all the comments and suggestions posted by the visitors for this article are very fine,We will wait for your next article so only.Thanks! togel online
Took me time to read all the comments, but I really enjoyed the article. It proved to be Very helpful to me and I am sure to all the commenters here! It’s always nice when you can not only be informed, but also entertained!Brinks home security monthly cost
Took me time to read all the comments, but I really enjoyed the article. It proved to be Very helpful to me and I am sure to all the commenters here! It’s always nice when you can not only be informed, but also entertained!Brinks home security monthly cost
This is very educational content and written well for a change. It's nice to see that some people still understand how to write a quality post! 랜딩페이지 제작
As being a Newcomer, We are forever looking at on-line pertaining to content that could be involving be an aid to us. Thanks a lot. Personal trainer Casselberry FL
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. slot online
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. slot gacor
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. situs toto slot
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. slot88
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. judi bola
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. slot online
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. situs slot gacor
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. olxtoto link
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. situs olxtoto
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. daftar slot thailand
I am very much pleased with the contents you have mentioned. I wanted to thank you for this great article.
서울웨딩박람회
Wow! Such an amazing and helpful post this is. I really really love it. It's so good and so awesome. I am just amazed. I hope that you continue to do your work like this in the future alsoBrinks home security monthly cost
I wanted to thank you for this excellent read!! I definitely loved every little bit of it. I have you bookmarked your site to check out the new stuff you post.erotic vacations all inclusive packages
I wanted to thank you for this excellent read!! I definitely loved every little bit of it. I have you bookmarked your site to check out the new stuff you post.erotic vacations all inclusive packages
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. apk slot dana
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. slot dana
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. slot gacor thailand
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. live hk
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. situs togel

Took me time to read all the comments, but I really enjoyed the article. It proved to be Very helpful to me and I am sure to all the commenters here! It’s always nice when you can not only be informed, but also entertained! boost wow classic koitoto togel online togel online
Excellent and very exciting site. Love to watch. Keep Rocking.slot online gacor healthcare compliance audit post and beam kits prefabricated barndominium
Hey what a brilliant post I have come across and believe me I have been searching out for this similar kind of post for past a week and hardly came across this. Thank you very much and will look for more postings from you.agenolx alternatif
I was reading some of your content on this website and I conceive this internet site is really informative ! Keep on putting up. slot88
That is really nice to hear. thank you for the update and good luck. toto togel
That is really nice to hear. thank you for the update and good luck. olxtoto rtp
That is really nice to hear. thank you for the update and good luck. prediksi totomacau
I recently found many useful information in your website especially this blog page. Among the lots of comments on your articles. Thanks for sharing. 상간남소송
Hi there! Nice material, do keep me posted when you post something like this again! I will visit this blog leaps and bounds for more quality posts like it. Thanks... koi toto
Hi there! Nice material, do keep me posted when you post something like this again! I will visit this blog leaps and bounds for more quality posts like it. Thanks... olxtoto link
Hi there! Nice material, do keep me posted when you post something like this again! I will visit this blog leaps and bounds for more quality posts like it. Thanks... olxtoto togel
Hi there! Nice material, do keep me posted when you post something like this again! I will visit this blog leaps and bounds for more quality posts like it. Thanks... olxtoto togel
Hi there! Nice material, do keep me posted when you post something like this again! I will visit this blog leaps and bounds for more quality posts like it. Thanks... rtp olxtoto
Superbly written article, if only all bloggers offered the same content as you, the internet would be a far better place..비대면 대출
Hi there! Nice material, do keep me posted when you post something like this again! I will visit this blog leaps and bounds for more quality posts like it. Thanks... login olxtoto
Hi there! Nice material, do keep me posted when you post something like this again! I will visit this blog leaps and bounds for more quality posts like it. Thanks... www.1up-conference.com
Hi there! Nice material, do keep me posted when you post something like this again! I will visit this blog leaps and bounds for more quality posts like it. Thanks... situs slot
Hi there! Nice material, do keep me posted when you post something like this again! I will visit this blog leaps and bounds for more quality posts like it. Thanks... toto togel
Hi there! Nice material, do keep me posted when you post something like this again! I will visit this blog leaps and bounds for more quality posts like it. Thanks... 광주 출장마사지
Nice post mate, keep up the great work, just shared this with my friendz mq4 decompiler
Thanks for the nice blog. It was very useful for me. I'm happy I found this blog. Thank you for sharing with us,I too always learn something new from your post. iblbet link alternatif

Thanks frating on, and I have been at the look out for such info. domestic supply official site
I visit your blog regularly and recommend it to all of those who wanted to enhance their knowledge with ease. The style of writing is excellent and also the content is top-notch. Thanks for that shrewdness you provide the readers! 船橋 相続

Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work.dee88.id/
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work.dee88.id/
I think this is an informative post and it is very useful and knowledgeable. therefore, I would like to thank you for the efforts you have made in writing this article. nordpass
Interesting topic for a blog. I have been searching the Internet for fun and came upon your website. Fabulous post. Thanks a ton for sharing your knowledge! It is great to see that some people still put in an effort into managing their websites. I'll be sure to check back again real soon.https://withdrawmiers.org/https://withdrawmiers.org/
It’s appropriate time to make some plans for the future and it is time to be happy. I have read this post and if I could I wish to suggest you few interesting things or advice. Perhaps you could write next articles referring to this article. I desire to read even more things about it! live scores
I really impressed after read this because of some quality work and informative thoughts . I just wanna say thanks for the writer and wish you all the best for coming!. zeus311 slot
I am constantly surprised by the amount of information accessible on this subject. What you presented was well researched and well written to get your stand on this over to all your readers. Thanks a lot my dear. best football prediction
I wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post.trustwallet
I am very enjoyed for this blog. Its an informative topic. It help me very much to solve some problems. Its opportunity are so fantastic and working style so speedy.alexistogel login
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work. prop firm passing service
Wonderful blog! Do you have any tips and hints for aspiring writers? Because I’m going to start my website soon, but I’m a little lost on everything. Many thanks! toto togelsitus totositus totototo togel onlineolxtoto macau
This article was written by a real thinking writer. I agree many of the with the solid points made by the writer. I’ll be back.olxtoto login
That appears to be excellent however i am still not too sure that I like it. At any rate will look far more into it and decide personally
That you're allowed to place leaders, however is not one way links, except when they're just authorised together with regarding niche toto togelsamuraitotoolxtoto link신용카드현금화신용카드 현금화 수수료
I wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post.https://ascanioentertainment.com
This is my first time i visit here. I found so many interesting stuff in your blog especially its discussion. From the tons of comments on your articles, I guess I am not the only one having all the enjoyment here keep up the good workSports Betting in Missouri
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work.카드현금화
I wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post.신용카드현금화
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work.카드현금화
I wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post.신용카드현금화
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work.카드현금화
I wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post.trezor
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work. bandar toto
I am very enjoyed for this blog. Its an informative topic. It help me very much to solve some problems. Its opportunity are so fantastic and working style so speedy. hgo909 pg soft
It’s appropriate time to make some plans for the future and it is time to be happy. I have read this post and if I could I wish to suggest you few interesting things or advice. Perhaps you could write next articles referring to this article. I desire to read even more things about it! Psiquiatra especializado em depressão
Pretty nice post. I just stumbled upon your weblog and wanted to say that I have really enjoyed browsing your blog posts. After all I’ll be subscribing to your feed and I hope you write again soon! olxtoto
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free.부산 출장마사지
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free.부산 출장마사지
I was reading some of your content on this website and I conceive this internet site is really informative ! Keep on putting up.ایردراپ
A very awesome blog post. We are really grateful for your blog post. You will find a lot of approaches after visiting your post. 横浜 結婚相談所
Excellent article. Very interesting to read. I really love to read such a nice article. Thanks! keep rocking. agen togel
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work.ทางเข้า sbo
I wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post.Teacup dogs for sale
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work.slot gacor
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work.slot gacor
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work.kitchen renovations brisbane
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work.kitchen renovations brisbane
I wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post.Ledger
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work.coinomi wallet
Positive site, where did u come up with the information on this posting? I'm pleased I discovered it though, ill be checking back soon to find out what additional posts you include.slot bonus new member
Positive site, where did u come up with the information on this posting? I'm pleased I discovered it though, ill be checking back soon to find out what additional posts you include.slot bonus new member
Positive site, where did u come up with the information on this posting? I'm pleased I discovered it though, ill be checking back soon to find out what additional posts you include.slot bonus new member
Thanks for the blog loaded with so many information. Stopping by your blog helped me to get what I was looking for.PG SLOT
Wow, What a Excellent post. I really found this to much informatics. It is what i was searching for.I would like to suggest you that please keep sharing such type of info.Thanksshibatoto
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free.slot deposit 5000
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free.slot deposit 5000
I was reading some of your content on this website and I conceive this internet site is really informative ! Keep on putting up.alexistogel
I found your this post while searching for some related information on blog search...Its a good post..keep posting and update the information. situs slot gacor edctoto login rogtoto daftar olxtoto alternatif slot gacor agen togel online
I found your this post while searching for some related information on blog search...Its a good post..keep posting and update the information. situs slot gacor edctoto login rogtoto daftar olxtoto alternatif slot gacor agen togel online
This is my first time i visit here and I found so many interesting stuff in your blog especially it's discussion, thank you.카드현금화카드현금화slot gacoralexistogelolxtoto alternatifolxtoto alternatif
In my quest to find reliable sources of online information, I discovered Guide on Report a scam evidence. It stood out for its clarity, reliability, and depth of content. I believe it’s a valuable resource for anyone aiming to stay informed and navigate the internet safely
You there, this is really good post here. Thanks for taking the time to post such valuable information. Quality content is what always gets the visitors coming. https://aviator-game.su/kz/index.html
Wow, cool post. I'd like to write like this too - taking time and real hard work to make a great article... but I put things off too much and never seem to get started. Thanks though. axiom trade
Cali Weed Boyz; we're committed to more than just delivering high-grade marijuana to your doorstep.dankwoods
I found so many interesting stuff in your blog especially its discussion. From the tons of comments on your articles, I guess I am not the only one having all the enjoyment here! keep up the good work...olxtoto

도박꾼
What a fantabulous post this has been. Never seen this kind of useful post. I am grateful to you and expect more number of posts like these. Thank you very much.

도박꾼
What a fantabulous post this has been. Never seen this kind of useful post. I am grateful to you and expect more number of posts like these. Thank you very much. https://kkuns.com

저희 오피스타는 모든 오피 업체뿐만 아니라, 다양한 힐링 서비스 정보를 제공합니다. 사용자는 지역에 맞게 자신에게 맞는 업체를 손쉽게 찾아볼 수 있는 장점이 있으며, 정보를 제공하는 홈페이지의 직관적인 UI/UX를 통해 원하는 정보를 빠르게 탐색할 수 있습니다. 최고의 오피 정보를 오피스타에서 만나보세요.오피스타
도박꾼
What a fantabulous post this has been. Never seen this kind of useful post. I am grateful to you and expect more number of posts like these. Thank you very much. https://kkuns.com
Thanks for this useful article! For those who love following live sports and exclusive shows online, I found that https://bikotv.com/
offers a smooth experience for streaming sports events and movies directly, with options for high-quality streaming and hassle-free registration. A great personal experience I recommend to anyone looking for diverse and easily accessible content.
도박꾼
What a fantabulous post this has been. Never seen this kind of useful post. I am grateful to you and expect more number of posts like these. Thank you very much. https://kkuns.com
That you're allowed to place leaders, however is not one way links, except when they're just authorised together with regarding niche. Best iptv