
문제
풀이 방식 BFS
입력받기
기본적인 BFS 알고리즘에 대해 이해하고 있다면 구현에서는 전혀 고민할 것이 없다.
오히려 구현보다 더 시간을 썼던 것이 input하는 방식이였다.
Python 에서의 그래프 입력
graph = [list(map(int,input().split())) for _ in range(n)]JAVA 에서의 그래프 입력
BufferedReader bf = new BufferedReader(new InputStreamReader(System.in)); String[] graphSize = bf.readLine().split(" "); n = Integer.parseInt(graphSize[0]); m = Integer.parseInt(graphSize[1]); arr = new int[n][m]; // 배열값 세팅 for(int i=0; i<n; i++){ StringTokenizer st = new StringTokenizer(bf.readLine()); for(int j=0; j<m; j++){ arr[i][j] = Integer.parseInt(st.nextToken()); } }
보통 알고리즘을 알기전의 자바를 사용하시는 분들이라면 Scanner 를 이용하여 STDIN 을 input 하는 것이 정석이겠지만 Scanner 와 BufferedReader에는 속도차이가 꽤나 존재한다.
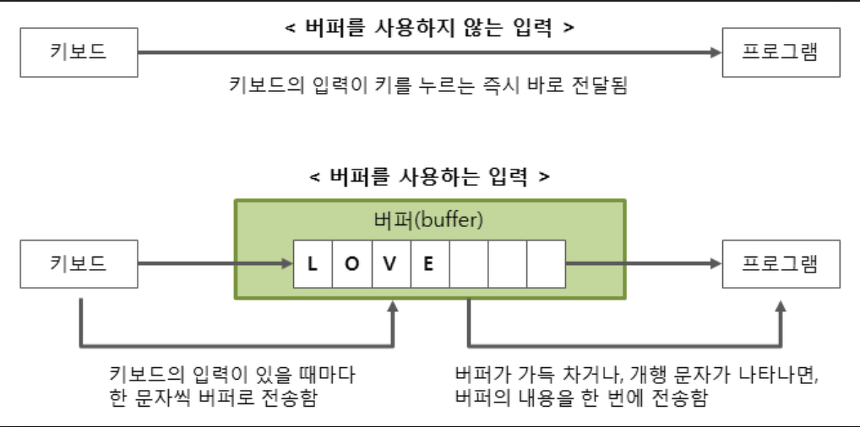
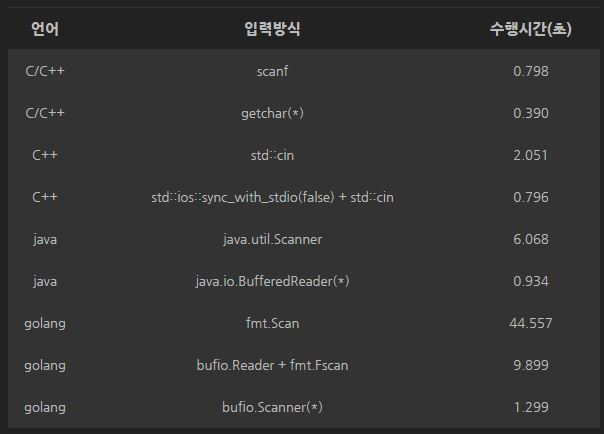
- 출처
- 사용자가 요청할 때마다 데이터를 읽어 오는 것이 아닌 일정한 크기의 데이터를 한번에 읽어와 버퍼에 보관 한 후, 사용자의 요청이 있을 때 버퍼에서 데이터를 읽어오는 방식으로 동작
- 위 그림을 본다면 알겠지만 Scanner 와는 수행시간에 확연한 차이를 보임
Scanner에서는 데이터 타입을 미리 지정할 수 있기때문에 캐스팅이 필요하지 않다는 장점, 사용성에서 더 좋음
알고리즘에서는 시간복잡도 와의 싸움이 중요하기 때문에 BufferedReader 사용을 추천!
문제 풀이
BFS 알고리즘이란 ?
그래프 탐색: 어떤것들이 연속해서 이어질때, 모두 확인하는 방법
Graph : Vertex(어떤것) +Edge(이어지는것)
FLOW : 시작점에서 연결된 Vertex 찾기 → 찾은 Vertex를 Queue에 저장 → Queue 에서 뽑아와 이를 반복 ↺
큐를 사용하는 이유?
큐 자료구조는 줄을 서는 것과 같이 처음 들어온것이 나갈때도 처음으로 나가는 FIFO 의 자료구조입니다. BFS에서 처음 들어온 순서, 즉 루트로 부터 가장 밑의 노드까지 들린다고 하였을때 큐의 동작 방식이 가장 유용하기 때문에 사용합니다.
자바에서 큐를 사용할때에는 구현체로
Linked List를 주로 활용하여 구현합니다. 각 노드들을 지정한 타입에 맞게 추가하여poll을 통하여 꺼내 올 수 있습니다
큐에서 사용할 좌표 클래스 Point 만들기
static int[][] arr;
static final int[] dx = {-1,1,0,0};
static final int[] dy = {0,0,-1,1};
static int n,m;
static class Point{
// Point 객체를 생성해준다, int 배열로서 확인하여도 되지만 객체지향적 프로그래밍을 하기위해 따로 클래스로 정의
private int x;
private int y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
public int getX() {
return x;
}
public int getY() {
return y;
}
}-
빠르게 구현을 목표로 하자면 int[] 를 통하여 0번째는 x, 1번째는 y라고 주석을 통해 설명하여 구현할 수도 있습니다. 정답은 없지만 자바의 강점을 살리는 코딩을 하고 싶어 따로 객체를 지정해주었습니다
-
객체를 지정하게 되면 이후 새로운 값이 추가되거나 유지보수적인 측면에서 생산성을 기대할 수 있습니다
-
좌표 클래스는 따로 Setter 를 지정하지 않고 사용합니다. 오직 생성자를 통해서만 객체를 만들때 x,y 를 설정하고 이후에는 변경할 수 없도록 합니다
-
dx, dy 는 각 좌표간 상,하,좌,우 를 이동하였을 때의 벡터좌표입니다. static final 을 통하여 전역에서 변경없이 고정으로 사용할 수 있도록 합니다
BFS 함수
public static int getSize(int x, int y){
Queue<Point> queue = new LinkedList<>();
// 시작 위치를 큐에 담는다
queue.add(new Point(x,y));
// 그래프에서 시작위치를 0 으로 바꾸어 방문처리를 한다
arr[x][y] = 0;
int ret = 1; // 현재 칠해진 도화지를 1부터 시작
while (queue.size()>0){
Point now = queue.poll();
int currX = now.getX();
int currY = now.getY();
// 시작점에서 상,하,좌,우로 이동하면서 이어지는 부분을 찾는다
for (int i = 0; i < 4; i++) {
// 이동후의 좌표 nx,ny를 미리 구한다, Array out of range 를 피하기 위해
int nx = currX + dx[i];
int ny = currY + dy[i];
if (nx<0 || ny<0 || nx >= n || ny >= m){
// 만약 그래프의 범위를 벗어난다면 continue
continue;
}
// 만약 해당 지점이 1이라면 큐에 담고 방문처리, 카운트 +1
if (arr[nx][ny]==1){
ret++;
arr[nx][ny] = 0;
queue.add(new Point(nx,ny));
}
}
}
return ret;
}- 테스트 케이스가 여러개라면 별도의 visited 배열을 생성하여 방문처리를 하였겠지만 테스트케이스가 하나이기 때문에 임의로 방문한 곳일 경우 0 으로 바꾸어 방문처리를 합니다
- 시작위치 x,y 를 받아와 큐를 생성하고 큐에 넣습니다
- 시작위치의 경우 재방문하지 않도록 0으로 값을 바꾸어 줍니다
- BFS 함수가 호출되었다는 것은 이미 1이 하나이상 존재한다는 뜻이기 때문에 ret 을 1로 초기화 해줍니다
- 큐가 비어있지 않을때 동안 반복하면서 현재위치에서 상하좌우를 움직여 1을 만날 경우에 큐에 삽입해줍니다
- 만약 이동후의 좌표가 전체 맵의 범위를 벗어난다면 다음 이동좌표를 판단합니다
- 이동 후 1을 만날 경우 ret 를 1증가시켜주고 방문처리를 위해 해당 위치를 0으로 지정합니다
- ret 반환
메인
public static void main(String[] args) throws IOException {
BufferedReader bf = new BufferedReader(new InputStreamReader(System.in));
String[] graphSize = bf.readLine().split(" ");
n = Integer.parseInt(graphSize[0]);
m = Integer.parseInt(graphSize[1]);
arr = new int[n][m];
// 배열값 세팅
for(int i=0; i<n; i++){
StringTokenizer st = new StringTokenizer(bf.readLine());
for(int j=0; j<m; j++){
arr[i][j] = Integer.parseInt(st.nextToken());
}
}
// 임의로 최대값을 설정
int count = 0;
int maxVal = 0;
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
// 만약 해당 위치좌표가 1 이라면 시작
if(arr[i][j] == 1){
int currSize = getSize(i,j);
// 현재 최대값을 초기화
maxVal = Math.max(maxVal, currSize);
count++;
}
}
}
System.out.println(count+"\n"+maxVal);
}- 맵의 좌표를 순회하면서 1인 경우에만 BFS를 수행하도록 합니다
- 보통 최대값을 -inf 로 지정하는 경우도 있지만 최대값이 0 일 수도 있기 때문에 0으로 지정합니다
- bfs 가 수행될 때 마다 카운트를 1 증가시킵니다
기존의 파이썬으로만 알고리즘을 해왔던 탓에 자바로 코딩테스트를 준비하려니 요긴하게 쓰고 있었던 라이브러리들과 자료구조 사용 방식의 차이로 인하여 미루고 미뤄왔던 자바로 코딩하기를 시작한지 한달이 되어가고 있다
기존 네이버 블로그를 운영할때는 문제 풀이를 중점적으로 하였다면 자바프로그래밍에 중점을 두고 알고리즘 포스트를 올려볼까 합니다
서버쪽 공부, 알고리즘, 프로젝트, CS 공부까지 어느하나 놓을 수가 없어서 각각 시간을 배정하여 공부중에 있습니다
