소모임 클론 프로젝트를 진행 중 self join 쿼리를 수행하고 조회한 결과를 객체에 매핑하는 과정에서 발생한 문제를 정리해 보려 한다.
먼저 조회에 사용된 테이블 구성은 다음과 같다.
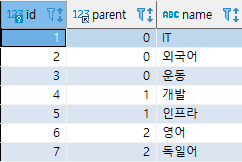
category 테이블
- 사용자가 설정할 수 있는 관심사들의 모음이다.
- id, parent, name을 갖는다. parent는 자신의 상위 관심사를 나타낸다.
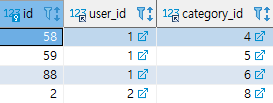
interest 테이블
- 사용자의 관심사가 등록되는 테이블이다.
- id, user_id, category_id를 갖는다. category_id는 하위 관심사에 해당하는 id이다.
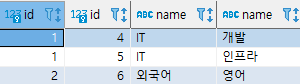
구현하려는 기능은 사용자의 관심사 정보를 조회하는 기능으로 작성한 쿼리는 다음과 같다.
select parent.id, child.id, parent.name, child.name
from category child
join category parent on child.parent = parent.id and child.id in
(select i.category_id from interest i where i.user_id = 1);DBeaver를 통해 쿼리를 수행하면 user_id가 1인 사용자의 상위 관심사를 포함한 정보를 얻을 수 있다.
쿼리를 확인한 후 spring boot, mybatis 환경에서 해당 쿼리를 수행해서 결과를 리턴하는 api를 만들고 테스트를 진행했다.

UserInterest 객체에 결과를 저장하도록 처리했고 다음과 같이 선언되어 있다.
@Getter
@Setter
@Builder
public class UserInterest {
private Long parentId;
private Long categoryId;
private String parentName;
private String categoryName;
}이해하기 어려운 결과가 나왔다. 원인을 찾기 위해 데이터를 담는 객체의 타입도 바꿔보고 쿼리도 다시 살피고 해봤으나 도저히 알 수가 없었다. 결국은 디버깅을 하게 됐다. InterestMapper의 해당 메서드를 호출하는 위치에 bp를 시작으로 쿼리 수행 후resultset 상태, 도메인 객체에 매핑된 상태 위주로 포인트가 될만한 부분에 bp를 걸면서 천천히 확인을 했고 결국 객체에 데이터가 담길 때 문제가 있음을 확인했다.

이정도 콜스택을 따라가보니 데이터를 담을 객체를 생성하고 결과를 가져오는 메소드를 찾았다.
private Object createUsingConstructor(...) throws SQLException {
boolean foundValues = false;
for (int i = 0; i < constructor.getParameterTypes().length; i++) {
String columnName = rsw.getColumnNames().get(i);
Object value = typeHandler.getResult(rsw.getResultSet(), columnName);
...
}
return foundValues ? objectFactory.create(resultType, constructorArgTypes, constructorArgs) : null;
}코드를 생략해뒀지만 매핑하려는 클래스의 생성자를 사용해서 객체를 생성해 주는 메서드이다. for 문으로 생성자의 파라미터 길이만큼 반복하면서 값을 하나씩 채워준다. typeHandler.getResult 메서드에는 ResultSet과 columnName이 전달되는데 이때 columnName은 조회 대상이 되는 columnName이 들어간다. 여기서는 [id, id, name, name] 순서로 값을 채운다.
첫 번째 id는 parentId에 1이 잘 채워졌다. 
두 번째 id도 1이 나왔고 categoryId에 채워졌다. 
ResultSet 상태를 더 살펴보기로 한다. 조회된 데이터는 정상이다. ResultSetImpl 객체에서 확인할 수 있었다.
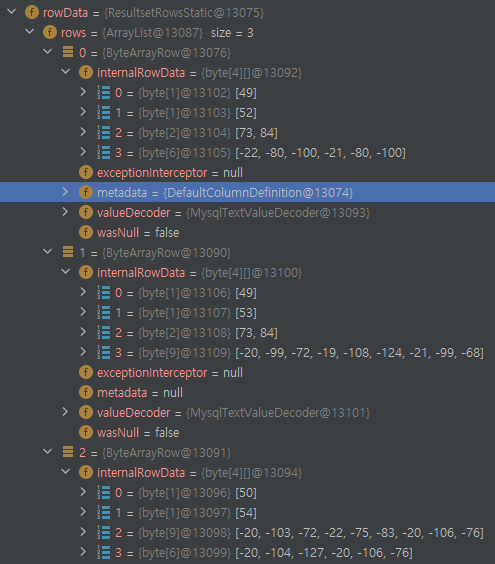
좀 더 들어가서 ResultSet에서 실제 Long 값을 가져오는 부분을 확인했다. columnIndex라는 값을 사용해서 값을 가져오는데 실제 columnIndex - 1 위치의 칼럼의 값을 가져온다.

지금까지 내용을 보면 첫 번째 두 번째 모두 ResultSet의 첫 번째 칼럼을 가져왔다고 생각해 볼 수 있겠다. 이제는 columnIndex에 집중해서 살펴보고자 한다.
다시 돌아가서 createUsingConstructor 메서드에 bp를 걸고 쿼리를 수행했다. ResultSetWrapper 객체 내부를 확인하니 resultSet이 있고 그 안에는 ResultSetImpl 객체에 해당하는 delegate가 있다. delegate 안에서 자세한 정보를 확인할 수 있었다.
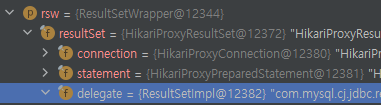
columnDefinition이 눈에 띈다. columnDefinition은 현재 비어있지만 칼럼을 읽으면서 갱신될 느낌이다.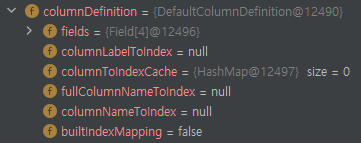
createUsingConstructor 메서드에서 호출되는 getResult를 따라가면 위에 이미지에서 본 getLong을 호출하는 getLong을 만날 수 있다.
@Override
public long getLong(String columnName) throws SQLException {
return getLong(findColumn(columnName));
}여기서 findColumn을 통해 columnIndex를 얻게 된다. findColumn을 따라가면 columnDefinition에서 index를 찾아오는 코드를 확인할 수 있다.(위에 언급한 useColumnNamesInFindColumn도 같이 사용된다.)
Integer index = this.columnDefinition.findColumn(columnName, this.useColumnNamesInFindColumn, 1);다시 findColumn을 따라가면 columnDefinition을 초기화하게 되는데 조회된 칼럼을 기준으로 columnIndex를 얻도록 데이터를 초기화한다.
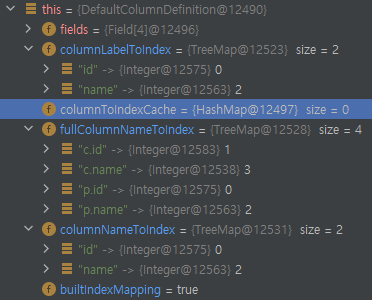
columnDefinition은 columnIndex를 담는 4개의 map을 갖는데 Cache 용도의 map만 HashMap이고 나머지는 TreeMap으로 구성되어 있다. findColumn 메서드는 columnToIndexCache - columnLabelToIndex - columnNameToIndex - fullColumnNameToIndex 순서로 index를 찾고 존재하는 칼럼이면 columnToIndexCache에 해당 칼럼 정보를 추가한다.
각 map들을 보면 가장 우선순위가 낮은 fullColumnNameToIndex만 실제 조회하려는 칼럼이 구분돼 있는 걸 알 수 있다. 이 내용만으로도 우선순위가 앞쪽에 있는 map을 통해서 columnIndex를 가져오게 되고, 내가 쿼리에 지정한 p.id, c.id와 p.name, c.name은 서로 구분이 불가능하단 것을 알 수 있다.
그래서 쿼리에서 조회되는 컬럼에 별칭을 붙여 컬럼을 구분 짓도록 변경을 했고
select parent.id as parent_id, child.id, parent.name as parent_name, child.name
from category child
join category parent on child.parent = parent.id and child.id in
(select i.category_id from interest i where i.user_id = 1);columnDefiniton을 확인하니 columnLabelToIndex 내용이 앞선 상황과 바뀐 것을 확인할 수 있었다.
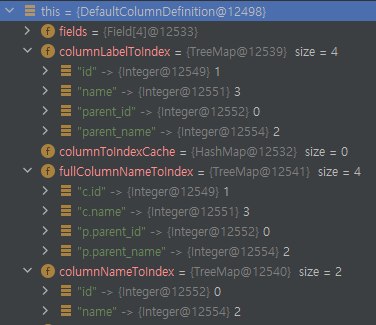
데이터도 역시 정상이었다.

시간은 걸렸지만 mysql jdbc에서 조회된 데이터를 채우기 위해 어떤 방식으로 클래스 정보를 사용해 객체를 만들고 데이터를 매핑하는지, 데이터를 얻기 위해 칼럼 정보를 어떻게 관리하는지 알 수 있는 시간이 되었다.
