
Reactor 공부 개꿀팁...(인텔리제이 사용)
- 메소드 위에 마우스 올려서 마블다이어그램 확인할 때 창 분리해서 볼 수 있다.
Project Reactor
Reactor
- 리액티브 스트림즈(Reactive Streams)를 구현한 구현체 중 하나
- 리액티브한 애플리케이션으로 동작하는데 있어 핵심적인 역할을 담당하는 리액티브 프로그래밍을 위한 라이브러리
Reactor 특징
Non-Blocking
- 요청 쓰레드가 차단이 되지 않는다.
- Non-Blocking 통신을 완벽하게 지원하는 Reactor는 MSA 구조에 적합한 라이브러리다.
Publisher 타입
-
Mono[0|1]
- 0과 1의 의미는 0건 또는 1건의 데이터를 emit 할 수 있음을 의미
-
Flux[N]
- N의 의미는 여러 건의 데이터를 emit할 수 있음을 의미
Backpressure
- Subscriber의 처리 속도가 Publihser의 emit 속도를 따라가지 못할 때 적절하게 제어하는 전략을 의미
- Publihser가 이미 받은 데이터들을 아직 처리 못하고 있는데 Subscriber가 계속 데이터를 보내주면 처리 못한 데이터가 쌓이다가 오버플로우가 발생할 수 있다.
Reactor 구성 요소
public class HelloReactorExample {
public static void main(String[] args) throws InterruptedException {
Flux // Reactor Sequence의 시작점, Reactor Sequence가 여러 건의 데이터를 처리함을 의미
.just("Hello", "Reactor") // 원본 데이터 소스로부터(Original Data Source) 데이터를 emit하는 Publisher의 역할
.map(message -> message.toUpperCase()) // 발행자로부터 받은 데이터를 처리
// 여기서는 just() 연산자가 방출하는 영어 문자열을 대문자로 변환한다.
.publishOn(Schedulers.parallel()) // Reactor Sequence에서 쓰레드 관리자 역할을 하는 Scheduler를 지정
// publishOn()에서 스케줄러를 지정하면, 다운스트림 스레드가 publishOn() 기준으로 Downstream의 쓰레드가 Scheduler에서 지정한 유형의 쓰레드로 변경된다.
// 즉, 이 코드에서는 리액터 시퀀스상에서 두 개의 스레드가 실행된다.
.subscribe(System.out::println, // subscribe()는 총 세 개의 람다 표현식을 매개변수로 가지며, 첫 번째 매개변수는 Publisher가 emit한 데이터를 전달 받아서 처리하는 역할을 한다.
error -> System.out.println(error.getMessage()), // 두 번째 매개변수는 Reqctor 시퀀스에서 오류가 발생했을 때 오류를 수신하고 처리하는 역할을 한다.
() -> System.out.println("# onComplete")); // 세 번째 매개변수는 리액터 시퀀스가 종료된 후 일부 후처리를 수행하는 역할을 한다.
Thread.sleep(100L); // Reactor에서 Scheduler로 지정한 쓰레드는 모두 데몬 쓰레드이기 때문에 주 쓰레드인 main 쓰레드가 종료되면 동시에 종료된다.
// 따라서 데몬 쓰레드 작업이 다 끝나고 main 쓰레드가 끝나도록 0.1초 동작 지연을 넣어준 것이다.
}
}- Reactor에서 Scheduler로 지정한 쓰레드는 모두 데몬 쓰레드이기 때문에 주 쓰레드인 main 쓰레드가 종료되면 동시에 종료된다.
마블 다이어그램(Marble Diagram)
구슬 모양의 동그라미는 하나의 데이터를 의미하며, 다이어그램 상에서 시간의 흐름에 따라 변화하는 데이터의 흐름을 표현한다.
복잡한 데이터의 흐름을 마블 다이어그램을 통해 좀 더 쉽게 이해할 수 있다.
Mono의 마블 다이어그램
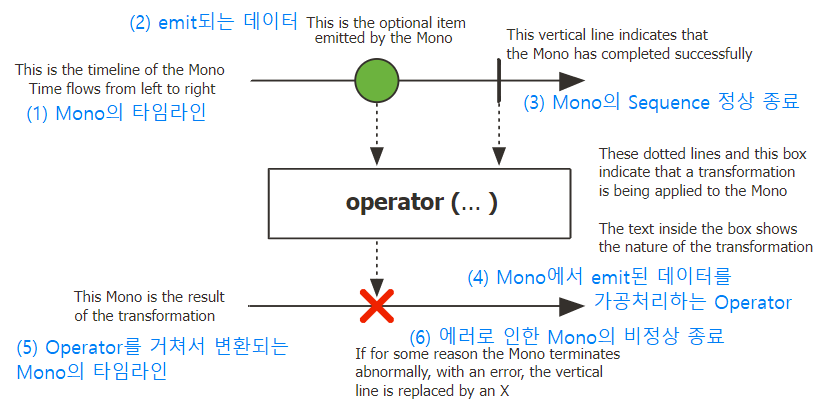
Reactor의 데이터 타입 중 하나인 Mono를 마블 다이어그램으로 표현한 것이다.
-
Mono는 0건 또는 1건의 데이터만 emit하는 Reactor 타입이다.
-
|는 정상 종료,X는 에러로 인한 비정상 종료를 의미한다.
Flux의 마블 다이어그램
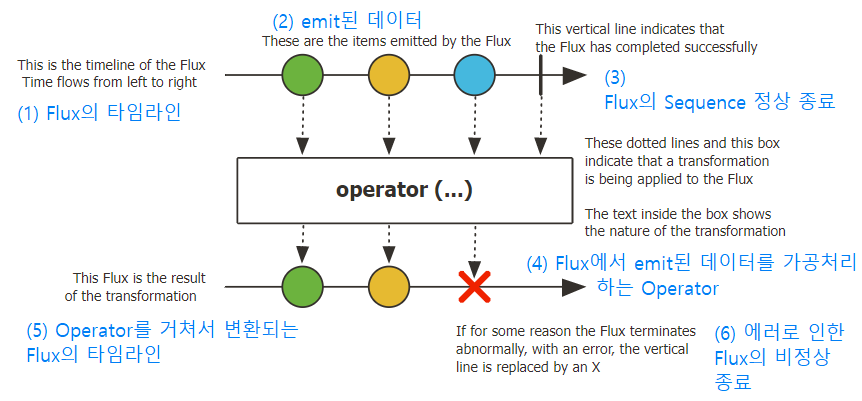
- Flux는 여러 개(0 ~ N)의 데이터를 emit하는 Reactor 타입이다.
Operator의 마블 다이어그램 예시
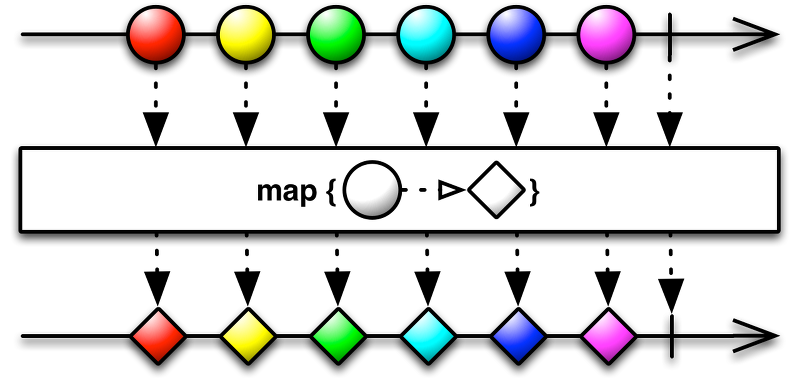
map() Operator는 입력으로 들어오는 데이터를 개발자가 구현하는 동작대로 변환해서 Downstream으로 전달하는 역할을 한다.
import reactor.core.publisher.Flux;
public class MarbleDiagramExample {
public static void main(String[] args) {
Flux
.just("Green-Circle", "Orange-Circle", "Blue-Circle") // 세 개의 문자열을 emit
.map(figure -> figure.replace("Circle", "Diamond")) // Circle -> Diamond
.subscribe(System.out::println); // map() Operator 내부에서 변환된 문자열을 출력
}
}
//출력
Green-Diamond
Orange-Diamond
Blue-Diamond스케줄러(Scheduler)
- 쓰레드를 관리하는 관리자의 역할을 한다.
- Reactor Sequence 상에서 처리되는 동작들을 하나 이상의 쓰레드에서 동작하도록 별도의 쓰레드를 제공해 준다.
Reactor의 Scheduler는 복잡한 멀티쓰레딩 프로세스를 단순하게 해준다.
스케줄러 주요 기능
작업 분배
- 리액터 시퀀스에서 처리되는 작업들을 스레드 풀 내의 여러 스레드에 분배한다.
백프레셔 처리
- 발행자와 구독자 사이의 속도 차이를 조율하고, 이로 인한 과부하를 방지한다.
작업 실행 시점 조절
- 작업들을 지연시키거나, 반복 실행 등의 스케줄링 전략을 제공한다.
Scheduler 전용 Operator
subscribeOn()
- 구독 직 후 실행되는 Operator 체인의 실행 쓰레드를 Scheduler에서 지정한 쓰레드로 변경한다.
doOnSubscribe()Operator는 구독 발생 직 후에 트리거 되는 Operator로써 구독 직 후에 실행되는 쓰레드와 동일한 쓰레드에서 실행된다. 만약 구독 직 후에 어떤 동작을 수행하고 싶다면doOnSubscribe()에 로직을 작성하면 된다.
@Slf4j
public class SchedulersExample02 {
public static void main(String[] args) throws InterruptedException {
Flux
.range(1, 10)
---------------------------------------------------------------------------------------------------------------------------------------------------
.doOnSubscribe(subscription -> log.info("# doOnSubscribe")) // 구독 직후에 어떤 동작을 수행하고 싶다면 doOnSubscribe()에 로직을 작성
.subscribeOn(Schedulers.boundedElastic()) // Operator 체인의 실행 쓰레드를 Scheduler에서 지정한 쓰레드(boundedElastic)로 변경
---------------------------------------------------------------------------------------------------------------------------------------------------
.filter(n -> n % 2 == 0)
.map(n -> n * 2)
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(100L);
}
}
//실행결과
14:07:17.781 [main] DEBUG reactor.util.Loggers - Using Slf4j logging framework
14:07:17.821 [boundedElastic-1] INFO com.codestates.example.schedulers.SchedulersExample02 - # doOnSubscribe
14:07:17.822 [boundedElastic-1] INFO com.codestates.example.schedulers.SchedulersExample02 - # onNext: 4
14:07:17.825 [boundedElastic-1] INFO com.codestates.example.schedulers.SchedulersExample02 - # onNext: 8
14:07:17.825 [boundedElastic-1] INFO com.codestates.example.schedulers.SchedulersExample02 - # onNext: 12
14:07:17.825 [boundedElastic-1] INFO com.codestates.example.schedulers.SchedulersExample02 - # onNext: 16
14:07:17.825 [boundedElastic-1] INFO com.codestates.example.schedulers.SchedulersExample02 - # onNext: 20Reactor Sequence에서 발생하는 signal의 전파 흐름
publishOn()
-
publishOn()을 추가할 때 마다 추가한publishOn()을 기준으로 Downstream쪽 쓰레드가publishOn()에서 Scheduler로 지정한 쓰레드로 변경된다. -
전달 받은 데이터를 가공 처리하는 Operator 앞에 추가해서 실행 쓰레드를 별도로 추가한다.
publishOn()은 Operator 앞에 여러번 추가할 경우 별도의 쓰레드가 추가로 생성되지만subscribeOn()은 여러 번 추가해도 하나의 쓰레드만 추가로 생성한다.
@Slf4j
public class SchedulersExample03 {
public static void main(String[] args) throws InterruptedException {
Flux
.range(1, 10)
.subscribeOn(Schedulers.boundedElastic())
.doOnSubscribe(subscription -> log.info("# doOnSubscribe"))
.publishOn(Schedulers.parallel()) // 필터 기능 쓰레드 변경
.filter(n -> n % 2 == 0)
.doOnNext(data -> log.info("# filter doOnNext")) // doOnNext()는 doOnNext() 바로 앞에 위치한 Operator가 실행될 때, 트리거 되는 Operator
.publishOn(Schedulers.parallel()) // map Operator 쓰레드 변경
.map(n -> n * 2)
.doOnNext(data -> log.info("# map doOnNext"))
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(100L);
}
}
//출력
14:30:44.118 [main] DEBUG reactor.util.Loggers - Using Slf4j logging framework
14:30:44.159 [main] INFO com.codestates.example.schedulers.SchedulersExample03 - # doOnSubscribe
14:30:44.170 [parallel-2] INFO com.codestates.example.schedulers.SchedulersExample03 - # filter doOnNext
14:30:44.170 [parallel-2] INFO com.codestates.example.schedulers.SchedulersExample03 - # filter doOnNext
14:30:44.170 [parallel-2] INFO com.codestates.example.schedulers.SchedulersExample03 - # filter doOnNext
14:30:44.170 [parallel-2] INFO com.codestates.example.schedulers.SchedulersExample03 - # filter doOnNext
14:30:44.170 [parallel-1] INFO com.codestates.example.schedulers.SchedulersExample03 - # map doOnNext
14:30:44.170 [parallel-2] INFO com.codestates.example.schedulers.SchedulersExample03 - # filter doOnNext
14:30:44.170 [parallel-1] INFO com.codestates.example.schedulers.SchedulersExample03 - # onNext: 4
14:30:44.173 [parallel-1] INFO com.codestates.example.schedulers.SchedulersExample03 - # map doOnNext
14:30:44.173 [parallel-1] INFO com.codestates.example.schedulers.SchedulersExample03 - # onNext: 8
14:30:44.173 [parallel-1] INFO com.codestates.example.schedulers.SchedulersExample03 - # map doOnNext
14:30:44.173 [parallel-1] INFO com.codestates.example.schedulers.SchedulersExample03 - # onNext: 12
14:30:44.173 [parallel-1] INFO com.codestates.example.schedulers.SchedulersExample03 - # map doOnNext
14:30:44.173 [parallel-1] INFO com.codestates.example.schedulers.SchedulersExample03 - # onNext: 16
14:30:44.173 [parallel-1] INFO com.codestates.example.schedulers.SchedulersExample03 - # map doOnNext
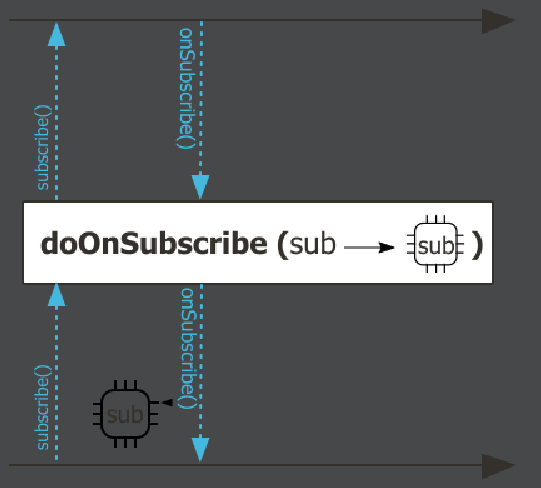
14:30:44.173 [parallel-1] INFO com.codestates.example.schedulers.SchedulersExample03 - # onNext: 20subscribeOn()예시 코드와 다르게 # doOnSubscribe 출력문이 main쓰레드로 되어 있는 것을 확인할 수 있었다. 왜 그런것일까?
A: subscribeOn() 오퍼레이터와 doOnSubscribe() 오퍼레이터의 순서가 영향이 있다. 아래 그림과 같이 doOnSubscribe() 오퍼레이터는 다운스트림에서 업스트림으로 가는 사이에 동작한다.
이와 같이 다양한 오퍼레이트의 마블 다이어그램을 참고하면 동작 과정을 이해하는데 도움이 될 것 같다.
(인텔리제이에서 오퍼레이트 위에 마우스 올리면 확인 가능)
핵심 포인트
-
Reactor에서의 Scheduler는 쓰레드를 관리하는 관리자 역할을 한다.
-
Scheduler는 한마디로 Reactor Sequence 상에서 처리되는 동작들을 하나 이상의 쓰레드에서 동작하도록 별도의 쓰레드를 제공해 준다.
-
subscribeOn()은 주로 데이터 소스에서 데이터를 emit하는 원본 Publisher의 실행 쓰레드를 지정하는 역할을 한다. -
publishOn()은 전달 받은 데이터를 가공 처리하는 Operator 앞에 추가해서 실행 쓰레드를 별도로 추가하는 역할을 한다.
Operators
상황별로 분류된 Operator 목록
새로운 Sequence를 생성(Creating)하고자 할 경우
기존 Sequence에서 변환 작업(Transforming)이 필요한 경우
Sequence 내부의 동작을 확인(Peeking)하고자 할 경우
Sequence에서 데이터 필터링(Filtering)이 필요한 경우
에러를 처리(Handling errors)하고자 할 경우
중요 Operator
새로운 Sequence를 생성(Creating)하고자 할 경우
fromStream()
- Java의 Stream을 입력으로 전달 받아 emit하는 Operator
- 전달 받은 Stream이 포함하고 있는 데이터를 차례대로 emit한다.
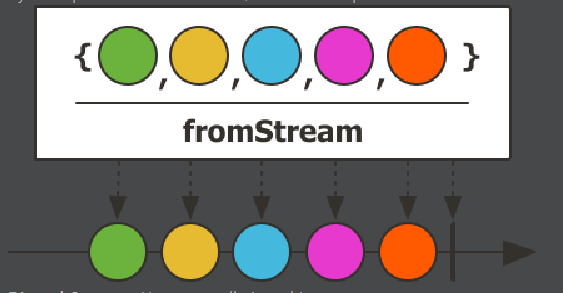
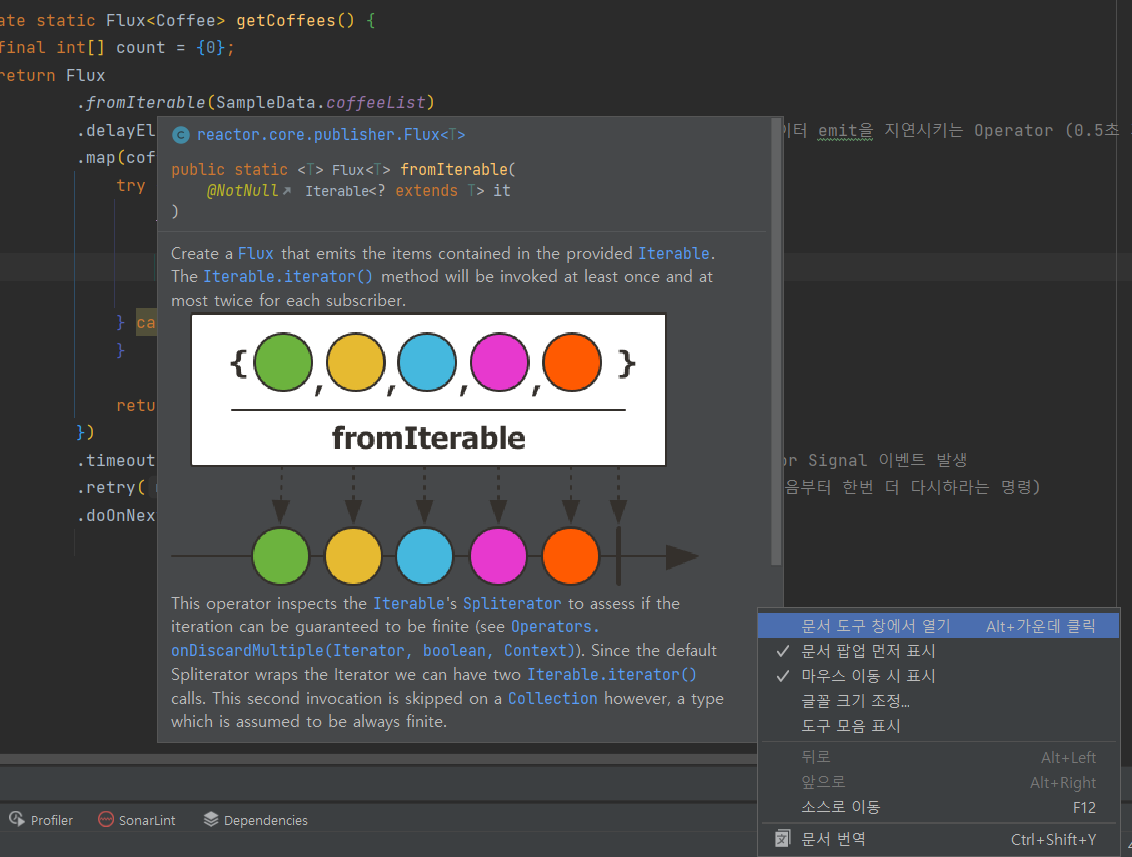
fromIterable()
- Java의Iterable을 입력으로 전달 받아 emit하는 Operator
- List, Map, Set 등의 컬렉션을
fromIterable()의 파라미터로 전달할 수 있다.
- List, Map, Set 등의 컬렉션을
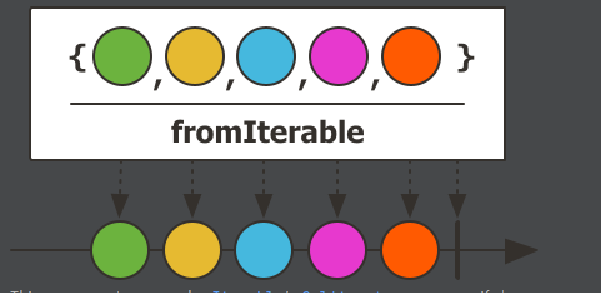
create()
-
사용자가 정의한(프로그래밍) 방식으로 Signal 이벤트를 발생시키는 Operator
FluxSink= 데이터 emit 등의 기능을 개발자가 직접 코드를 구현해서 처리함을 의미
-
한 번에 여러 건의 데이터를 비동기적으로 emit할 수 있다.(= multhreaded source)

@Slf4j
public class CreateExample {
private static List<Integer> source= Arrays.asList(1, 3, 5, 7, 9, 11, 13, 15, 17, 19);
public static void main(String[] args) {
Flux.create((FluxSink<Integer> sink) -> { // FluxSink = 데이터 emit 등의 기능을 개발자가 직접 코드를 구현해서 처리함을 의미
sink.onRequest(n -> { // Subscriber에서 데이터를 요청하면 onRequest()의 파라미터인 람다 표현식이 실행된다.
for (int i = 0; i < source.size(); i++) {
sink.next(source.get(i)); // next() 메서드로 List source의 원소를 emit
}
sink.complete(); // Sequence를 종료
});
sink.onDispose(() -> log.info("# clean up")); // onDispose() = Sequence가 완전히 종료되기 직전에 호출되며, sequence 종료 직전 후처리 작업을 할 수 있다.
}).subscribe(data -> log.info("# onNext: {}", data));
}
}기존 Sequence에서 변환 작업(Transforming)이 필요한 경우
flatMap()
-
내부로 들어오는 데이터 한 건당 하나의 Sequence가 생성
- ex. Upstream에서 3개의 데이터를 emit하고, flatMap() 내부에서 2개의 데이터를 emit하는 Sequence가 있다면 Downstream으로 emit되는 데이터는 총 6개(3 x 2)가 된다.
-
flatMap()내부에서 정의하는 Sequence를 Inner Sequece라고 부른다.
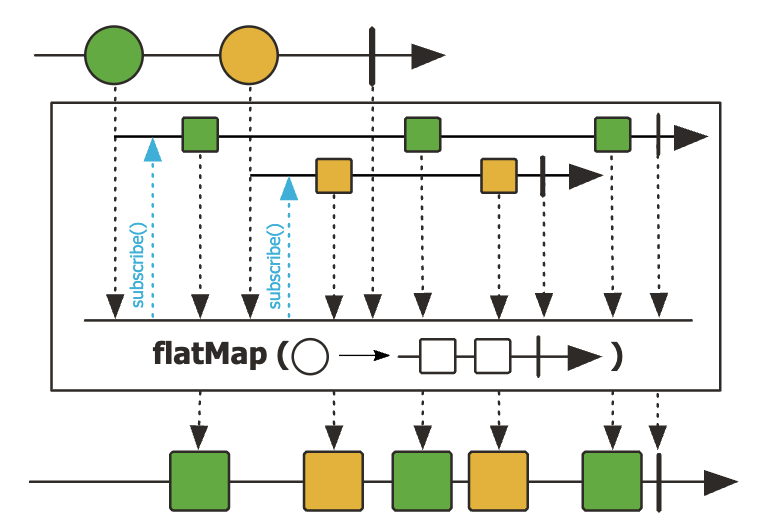
@Slf4j
public class FlatMapExample01 {
public static void main(String[] args) throws InterruptedException {
Flux
.range(2, 6) // 2부터 6개 호출 (즉, 2~7 호출)
.flatMap(dan -> Flux
.range(1, 9) // 1부터 9개 호출 (1~9 호출)
.publishOn(Schedulers.parallel()) // flatMap() 내부의 Inner Sequence를 처리할 쓰레드를 할당 // 여러 개의 쓰레드가 비동기적으로 동작하게 만드는 것
.map(num -> dan + " x " + num + " = " + dan * num)) // 구구단 형식으로 문자열 구성
.subscribe(log::info);
Thread.sleep(100L);
}
}
//출력
23:58:05.791 [main] DEBUG reactor.util.Loggers - Using Slf4j logging framework
23:58:05.906 [parallel-4] INFO com.codestates.example.operators.FlatMapExample01 - 5 x 1 = 5
23:58:05.907 [parallel-4] INFO com.codestates.example.operators.FlatMapExample01 - 5 x 2 = 10
23:58:05.908 [parallel-4] INFO com.codestates.example.operators.FlatMapExample01 - 5 x 3 = 15
23:58:05.909 [parallel-4] INFO com.codestates.example.operators.FlatMapExample01 - 5 x 4 = 20
23:58:05.911 [parallel-4] INFO com.codestates.example.operators.FlatMapExample01 - 5 x 5 = 25
23:58:05.911 [parallel-4] INFO com.codestates.example.operators.FlatMapExample01 - 5 x 6 = 30
23:58:05.911 [parallel-4] INFO com.codestates.example.operators.FlatMapExample01 - 5 x 7 = 35
23:58:05.911 [parallel-4] INFO com.codestates.example.operators.FlatMapExample01 - 5 x 8 = 40
23:58:05.911 [parallel-4] INFO com.codestates.example.operators.FlatMapExample01 - 5 x 9 = 45
23:58:05.918 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 3 x 1 = 3
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 4 x 1 = 4
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 4 x 2 = 8
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 4 x 3 = 12
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 4 x 4 = 16
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 4 x 5 = 20
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 4 x 6 = 24
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 4 x 7 = 28
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 4 x 8 = 32
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 4 x 9 = 36
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 6 x 1 = 6
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 6 x 2 = 12
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 6 x 3 = 18
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 6 x 4 = 24
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 6 x 5 = 30
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 6 x 6 = 36
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 6 x 7 = 42
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 6 x 8 = 48
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 6 x 9 = 54
23:58:05.919 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 7 x 1 = 7
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 7 x 2 = 14
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 7 x 3 = 21
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 7 x 4 = 28
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 7 x 5 = 35
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 7 x 6 = 42
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 7 x 7 = 49
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 7 x 8 = 56
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 7 x 9 = 63
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 2 x 1 = 2
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 2 x 2 = 4
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 2 x 3 = 6
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 2 x 4 = 8
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 2 x 5 = 10
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 2 x 6 = 12
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 2 x 7 = 14
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 2 x 8 = 16
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 2 x 9 = 18
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 3 x 2 = 6
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 3 x 3 = 9
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 3 x 4 = 12
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 3 x 5 = 15
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 3 x 6 = 18
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 3 x 7 = 21
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 3 x 8 = 24
23:58:05.920 [parallel-2] INFO com.codestates.example.operators.FlatMapExample01 - 3 x 9 = 27flatMap()Operator에서 추가 쓰레드를 할당할 경우, 작업의 처리 순서를 보장하지 않는다
concat()
- 입력으로 전달하는 Publisher의 Sequence를 연결해서 차례대로 데이터를 emit하는 Operator다.
- 하나의 Sequence로 이어 붙인다
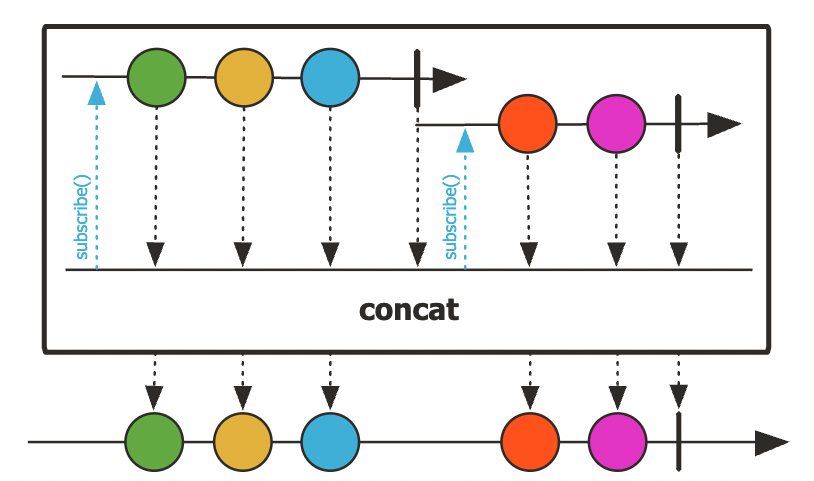
zip()
- 입력으로 전달되는 여러 개의 Publisher Sequence에서 emit된 데이터를 결합하는 Operator다.
결합= 각 Publisher가 emit하는 데이터를 하나씩 전달 받아서 새로운 데이터를 만든 후에 Downstream으로 전달한다는 의미
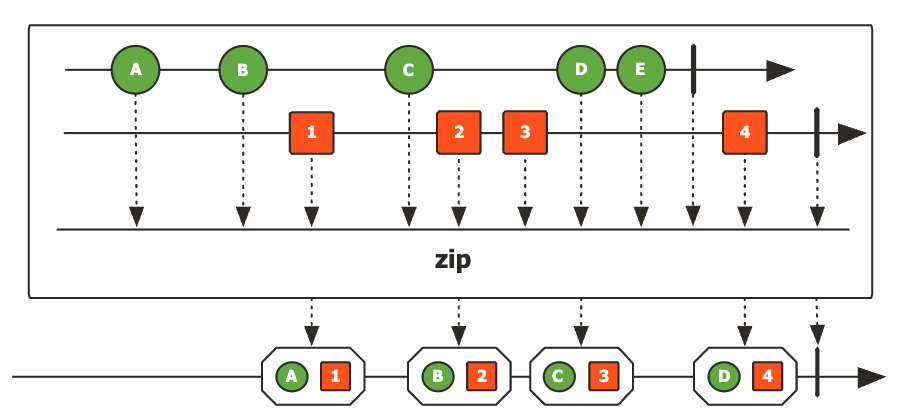
각각의 Sequence에서 emit되는 데이터 중에서 같은 차례(index)의 데이터들이 결합된다.
- 각 Sequence에서 emit되는 데이터의 시점이 다르기 때문에 결합되어야 하는 데이터(같은 index)가 emit이 될 때까지 기다렸다가 결합한다.
@Slf4j
public class ZipExample01 {
public static void main(String[] args) throws InterruptedException {
Flux<Long> source1 = Flux.interval(Duration.ofMillis(200L)).take(4); // 0.2초마다 한번씩 데이터를 emit (0,1,2,3)
Flux<Long> source2 = Flux.interval(Duration.ofMillis(400L)).take(6); // 0.4초마다 한번씩 데이터를 emit (0,1,2,3,4,5)
Flux
.zip(source1, source2, (data1, data2) -> data1 + data2) // 결합시키는데 source2의 남는 데이터(4,5)는 폐기 됨
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(3000L);
}
}Sequence 내부의 동작을 확인(Peeking)하고자 할 경우
doOnNext()
- 데이터 emit 시 트리거 되어 부수 효과(side-effect)를 추가할 수 있는 Operator
- 리턴값이 없음
- 주로 로깅(로그를 기록 또는 출력하는 작업)에 사용
부수 효과(side-effect)
- 어떤 동작을 실행하되 리턴 값이 없는 것을 의미
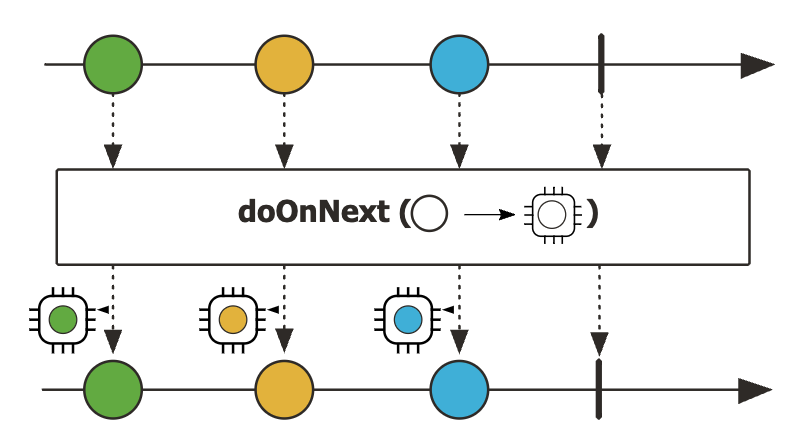
- 실제 emit된 데이터를 가지고 무언가 처리 작업을 하지만 Downstream으로 전달되는 것은 emit된 데이터이지 doOnNext() Operator에서 처리된 작업의 결과 값은 아니다.
@Slf4j
public class DoOnNextExample { // emit되는 데이터의 유효성 검증
public static void main(String[] args) {
Flux
.fromIterable(SampleData.coffeeList)
.doOnNext(coffee -> validateCoffee(coffee))
.subscribe(data -> log.info("{} : {}", data.getKorname(), data.getPrice()));
}
private static void validateCoffee(Coffee coffee) {
if (coffee == null) {
throw new RuntimeException("Not found coffee");
}
// 유효성 검증에 필요한 로직을 필요한 만큼 추가할 수 있다.
}
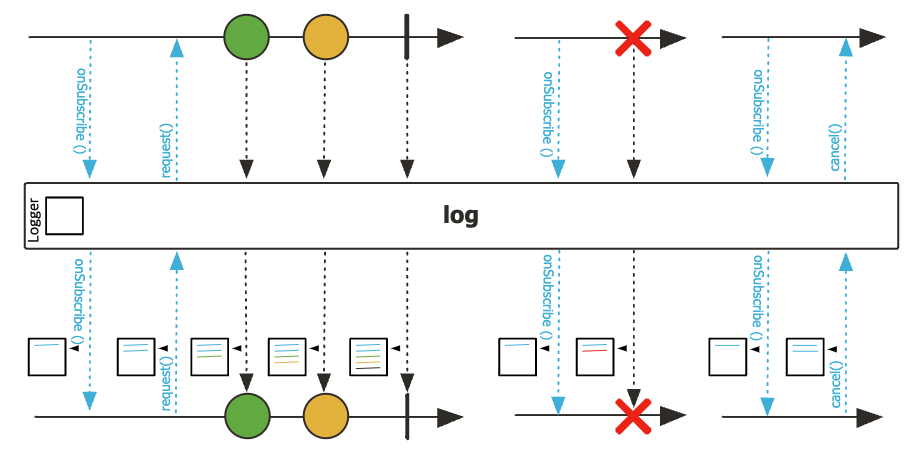
}log()
- Publisher에서 발생하는 Signal 이벤트를 로그로 출력해주는 역할
public class LogExample {
public static void main(String[] args) {
Flux
.fromStream(Stream.of(200, 300, 400, 500, 600))
.log()
.reduce((a, b) -> a + b)
.log()
.subscribe(System.out::println);
}
}
//출력
> Task :LogExample.main()
00:46:57.906 [main] DEBUG reactor.util.Loggers - Using Slf4j logging framework
// onSubscribe Signal 이벤트 두번 발생
00:46:57.971 [main] INFO reactor.Flux.Stream.1 - | onSubscribe([Synchronous Fuseable] FluxIterable.IterableSubscription)
00:46:57.973 [main] INFO reactor.Mono.Reduce.2 - | onSubscribe([Fuseable] MonoReduce.ReduceSubscriber)
// request Signal 이벤트 두번 발생
00:46:57.974 [main] INFO reactor.Mono.Reduce.2 - | request(unbounded)
00:46:57.974 [main] INFO reactor.Flux.Stream.1 - | request(unbounded)
00:46:57.974 [main] INFO reactor.Flux.Stream.1 - | onNext(200)
00:46:57.974 [main] INFO reactor.Flux.Stream.1 - | onNext(300)
00:46:57.974 [main] INFO reactor.Flux.Stream.1 - | onNext(400)
00:46:57.974 [main] INFO reactor.Flux.Stream.1 - | onNext(500)
00:46:57.974 [main] INFO reactor.Flux.Stream.1 - | onNext(600)
00:46:57.975 [main] INFO reactor.Flux.Stream.1 - | onComplete()
00:46:57.975 [main] INFO reactor.Mono.Reduce.2 - | onNext(2000)
2000
00:46:57.975 [main] INFO reactor.Mono.Reduce.2 - | onComplete()에러를 처리(Handling errors)하고자 할 경우
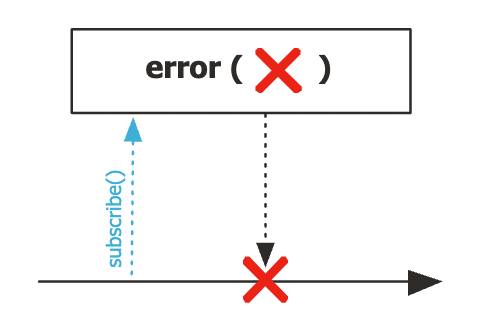
error()
- onError Signal 이벤트를 발생 시키는 Operator
@Slf4j
public class ErrorExample {
public static void main(String[] args) {
Mono.justOrEmpty(findVerifiedCoffee()) // justOrEmpty() Operator는 파라미터로 전달되는 데이터소스가 null 이어도 에러가 발생하지 않는다.
.switchIfEmpty(Mono.error(new RuntimeException("Not found coffee"))) // switchIfEmpty() => 만약 null이면 괄호안 수행
.subscribe(
data -> log.info("{} : {}", data.getKorname(), data.getPrice()), // 만약 정상적인 coffee 객체를 받으면, 받은 데이터 출력
error -> log.error("# onError: {}", error.getMessage())); // error 객체를 전달 받아서 에러 메시지를 출력
}
private static Coffee findVerifiedCoffee() {
// 데이터베이스에서 Coffee 정보를 조회할 때 null값이 리턴됐다고 가정
return null;
}
}
//출력
> Task :ErrorExample.main()
01:14:54.256 [main] DEBUG reactor.util.Loggers - Using Slf4j logging framework
01:14:54.269 [main] ERROR com.codestates.example.operators.ErrorExample - # onError: Not found coffeetimeout()
- 입력으로 주어진 시간동안 emit되는 데이터가 없으면 onError Signal 이벤트를 발생
timeout()Operator는retry()Operator와 함께 사용하는 경우가 많다.
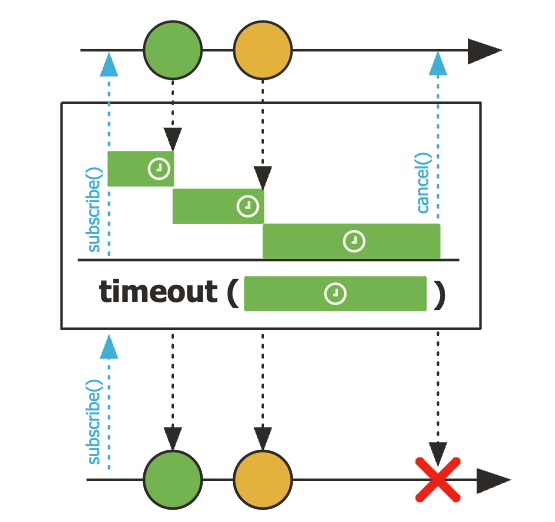
retry()
- Sequence 상에서 에러가 발생할 경우, 입력으로 주어진 숫자만큼 재구독해서 Sequence를 다시 시작
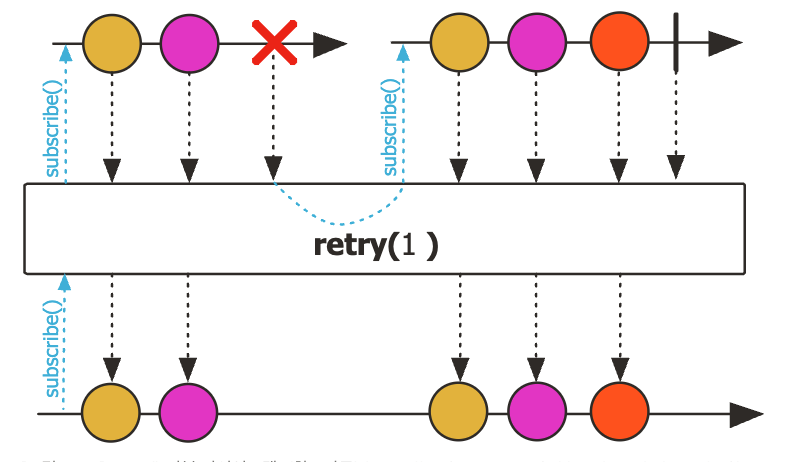
@Slf4j
public class TimeoutRetryExample { // 일정 시간 내에 데이터가 emit 되지 않으면 다시 시도하는 예제
public static void main(String[] args) throws InterruptedException {
getCoffees()
.collect(Collectors.toSet()) // emit된 데이터를 Set<Coffee>으로 변환 // timeout이 되기전에 이미 emit된 데이터가 있으므로 재구독 후, 다시 emit된 데이터에 동일한 데이터가 있으므로 중복을 제거하기 위함
.subscribe(bookSet -> bookSet
.stream()
.forEach(data ->
log.info("{} : {}", data.getKorname(), data.getPrice())));
Thread.sleep(12000);
}
private static Flux<Coffee> getCoffees() {
final int[] count = {0};
return Flux
.fromIterable(SampleData.coffeeList)
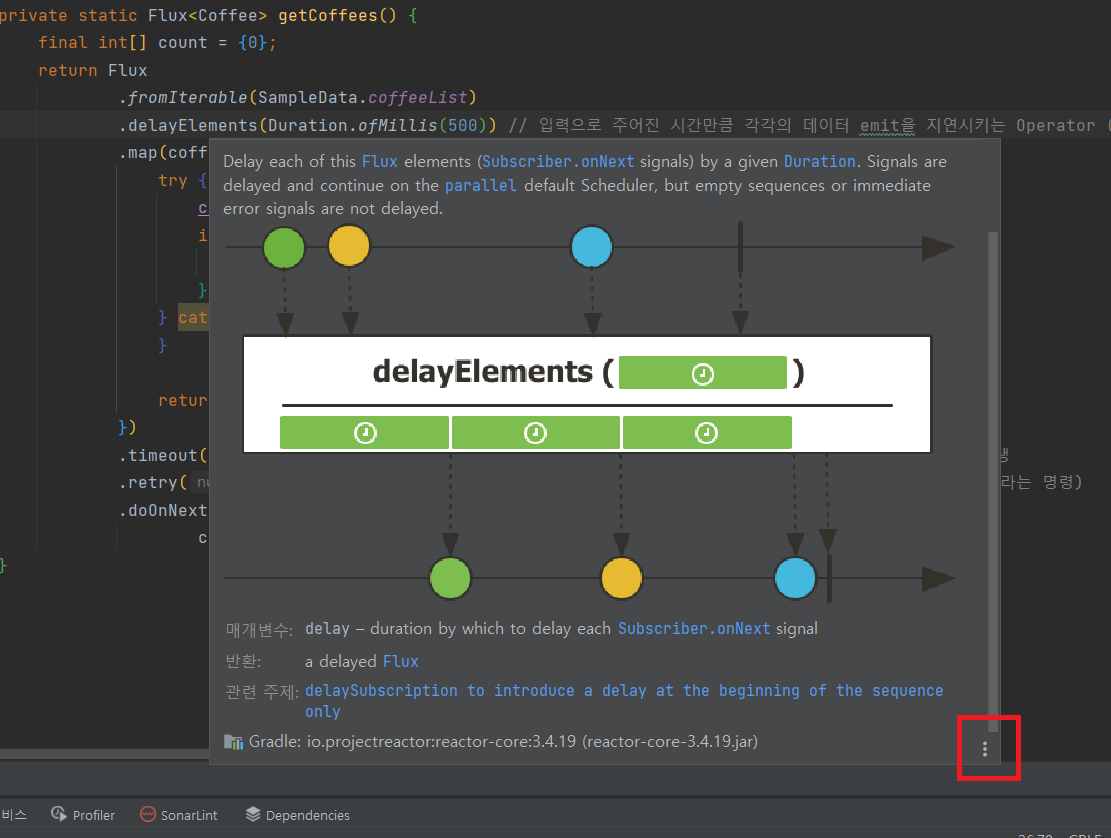
.delayElements(Duration.ofMillis(500)) // 입력으로 주어진 시간만큼 각각의 데이터 emit을 지연시키는 Operator (0.5초 지연)
.map(coffee -> {
try {
count[0]++;
if (count[0] == 4) { // 4번째 emit일 때
Thread.sleep(2000); // 2초 지연
}
} catch (InterruptedException e) {
}
return coffee;
})
.timeout(Duration.ofSeconds(2)) // 2초안에 데이터가 emit되지 않으면 onError Signal 이벤트 발생
.retry(1) // 에러나면 1회 재구독을 해서 Sequence를 다시 시작 (처음부터 한번 더 다시하라는 명령)
.doOnNext(coffee -> log.info("# getCoffees > doOnNext: {}, {}",
coffee.getKorname(), coffee.getPrice()));
}
}
//출력
> Task :TimeoutRetryExample.main()
03:11:54.666 [main] DEBUG reactor.util.Loggers - Using Slf4j logging framework
03:11:55.294 [parallel-2] INFO com.codestates.example.operators.TimeoutRetryExample - # getCoffees > doOnNext: 아메리카노, 2500
03:11:55.802 [parallel-4] INFO com.codestates.example.operators.TimeoutRetryExample - # getCoffees > doOnNext: 카페라떼, 3500
03:11:56.313 [parallel-6] INFO com.codestates.example.operators.TimeoutRetryExample - # getCoffees > doOnNext: 바닐라 라떼, 4500
03:11:58.826 [parallel-8] DEBUG reactor.core.publisher.Operators - onNextDropped: com.codestates.example.operators.Coffee@4d42eba7
03:11:58.841 [parallel-10] INFO com.codestates.example.operators.TimeoutRetryExample - # getCoffees > doOnNext: 아메리카노, 2500
03:11:59.352 [parallel-12] INFO com.codestates.example.operators.TimeoutRetryExample - # getCoffees > doOnNext: 카페라떼, 3500
03:11:59.864 [parallel-2] INFO com.codestates.example.operators.TimeoutRetryExample - # getCoffees > doOnNext: 바닐라 라떼, 4500
03:12:00.377 [parallel-4] INFO com.codestates.example.operators.TimeoutRetryExample - # getCoffees > doOnNext: 카라멜 마끼아또, 5500
03:12:00.890 [parallel-6] INFO com.codestates.example.operators.TimeoutRetryExample - # getCoffees > doOnNext: 에스프레소, 5000
03:12:00.891 [parallel-6] INFO com.codestates.example.operators.TimeoutRetryExample - 카라멜 마끼아또 : 5500
03:12:00.891 [parallel-6] INFO com.codestates.example.operators.TimeoutRetryExample - 아메리카노 : 2500
03:12:00.891 [parallel-6] INFO com.codestates.example.operators.TimeoutRetryExample - 바닐라 라떼 : 4500
03:12:00.891 [parallel-6] INFO com.codestates.example.operators.TimeoutRetryExample - 카페라떼 : 3500
03:12:00.891 [parallel-6] INFO com.codestates.example.operators.TimeoutRetryExample - 에스프레소 : 5000핵심 포인트
-
Reactor의 Operator는 그 종류가 너무 많기 때문에 한번에 모든 Operator의 사용법을 익히는 것은 사실상 불가능하다. 상황별로 자주 사용되는 Operator의 사용법을 익히고, 그때 그때 필요한 상황에 해당 Operator를 찾아서 사용하는 것이 좋다.
-
flatMap()처럼 내부에서 정의하는 Sequence를 Inner Sequece라고 한다. -
flatMap()Operator에 추가 쓰레드를 할당할 경우, 작업의 처리 순서를 보장하지 않는다. -
create()Operator는 프로그래밍 방식으로 Signal 이벤트를 발생시키는 Operator로써 한 번에 여러 건의 데이터를 비동기적으로 emit할 수 있다. -
Reactor의
concat()Operator는 논리적으로 하나의 Sequence로 이어 붙인 후, 이어 붙인 Sequecne에서 시간 순서대로 데이터를 차례대로 emit한다. -
zip()Operator는 입력으로 주어진 Sequence의 emit 시점이 매번 다르더라도 동일 index 상의 emit 시점이 늦은 데이터가 emit될 때까지 대기했다가 데이터가 모두 emit되면 해당 데이터를 모두 전달 받는다. -
함수형 프로그래밍 세계에서 부수 효과(side-effect)는 어떤 동작을 실행하되 리턴 값이 없는 것을 의미한다.
-
timeout()Operator는 입력으로 주어진 시간동안 emit되는 데이터가 없으면 onError Signal 이벤트를 발생시킨다. -
retry()Operator는 Sequence 상에서 에러가 발생할 경우, 입력으로 주어진 숫자만큼 재구독해서 Sequence를 다시 시작한다.
