
Section1 - [Java] 심화(Effective)
애너테이션(Annotation)
소스 코드가 컴파일되거나 실행될 때에 컴파일러 및 다른 프로그램에게 필요한 정보를 전달해주는 문법 요소
public class ExampleClass implements ExampleInterface {
@Override // <<이게 애너테이션
public void example() {
}
}- @로 시작하며, 클래스, 인터페이스, 필드, 메서드 등에 붙여서 사용할 수 있다.
애너테이션의 종류
JDK에서 기본적으로 제공하는 애너테이션은 아래의 두 가지
-
표준 애너테이션 : JDK에 내장되어 있는 일반적인 애너테이션
-
메타 애너테이션 : 다른 애너테이션을 직접 정의해서 사용하는 애너테이션
(cf. JDK 말고 다른 프로그램에서 제공하는 애너테이션도 있음)
표준 애너테이션
@Override
선언한 메서드가 상위 클래스의 메서드를 오버라이딩하거나 추상 메서드를 구현하는 메서드라는 것을 컴파일러에게 알려주는 역할을 수행
- 메서드 앞에만 붙일 수 있음
- 실수로 메서드의 이름 잘못 작성해서 오버라이딩 안되는 상황 방지
- "오버라이딩 및 구현이 잘 안되면 에러를 발생시켜서 나에게 알려줄래?”라고 부탁하는 것
@Deprecated
기존에 사용하던 기술이 다른 기술로 대체되어 기존 기술을 적용한 코드를 더 이상 사용하지 않도록 유도하는 경우에 사용 함
- 기존의 코드를 다른 코드와의 호환성 문제로 삭제하기 곤란해 남겨두어야만 하지만 더 이상 사용하는 것을 권장하지 않을 때 사용
@SuppressWarnings
컴파일 경고 메시지가 나타나지 않도록 함
- 경고가 발생할 것이 충분히 예상됨에도 묵인해야 할 때 주로 사용
@FunctionalInterface
컴파일러가 함수형 인터페이스의 선언이 바르게 선언되었는지 확인 함
메타 애너테이션
애너테이션의 적용 대상 및 유지 기간을 지정하는 데에 사용
- 애너테이션을 정의하는 데에 사용
@Target
애너테이션을 적용할 “대상"을 지정하는 데 사용
| 대상 타입 | 적용범위 |
|---|---|
| ANNOTATION_TYPE | 애너테이션 |
| CONSTRUCTOR | 생성자 |
| FIELD | 필드(멤버변수, 열거형 상수) |
| LOCAL_VARIABLE | 지역변수 |
| METHOD | 메서드 |
| PACKAGE | 패키지 |
| PARAMETER | 매개변수 |
| TYPE | 타입(클래스, 인터페이스, 열거형) |
| TYPE_PARAMETER | 타입 매개변수 |
| TYPE_USE | 타입이 사용되는 모든 대상 |
import static java.lang.annotation.ElementType.*;
//import문을 이용하여 ElementType.TYPE 대신 TYPE과 같이 간단히 작성할 수 있다.
@Target({FIELD, TYPE, TYPE_USE}) // 적용대상이 FIELD, TYPE
public @interface CustomAnnotation { } // CustomAnnotation을 정의
@CustomAnnotation // 적용대상이 TYPE인 경우
class Main {
@CustomAnnotation // 적용대상이 FIELD인 경우
int i;
}@Documented
애너테이션에 대한 정보가 javadoc으로 작성한 문서에 포함되도록 하는 애너테이션 설정
cf. 자바에서 제공하는 표준 애너테이션과 메타 애너테이션 중 @Override와 @SuppressWarnings를 제외하고는 모두 @Documented가 적용되어 있다.
@Documented
@Target(ElementType.Type)
public @interface CustomAnnotation { }@Inherited
하위 클래스가 애너테이션을 상속받도록 함
@Inherited // @SuperAnnotation이 하위 클래스까지 적용
@interface SuperAnnotation{ }
@SuperAnnotation
class Super { }
class Sub extends Super{ } // Sub에 애너테이션이 붙은 것으로 인식@Retention
특정 애너테이션의 지속 시간을 결정하는 데 사용
애너테이션과 관련한 유지 정책(retention policy)의 종류 3가지
| 유지 정책 | 설명 |
|---|---|
| SOURCE | 소스 파일에 존재, 클래스파일에는 존재하지 않음 |
| CLASS | 클래스 파일에 존재, 실행시에 사용불가, 기본값 |
| RUNTIME | 클래스 파일에 존재, 실행시에 사용가능 |
- 유지정책 = 애너테이션이 유지되는 기간을 지정하는 속성
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
//오버라이딩이 제대로 되었는지 컴파일러가 확인하는 용도
//클래스 파일에 남길 필요 없이 컴파일시에만 확인하고 사라짐 (실행 시에는 사용되지 않음)
public @interface Override(){ }@Repeatable
애너테이션을 여러 번 붙일 수 있도록 허용한다.
@Repeatable(Works.class) // Work 애너테이션을 여러 번 반복해서 쓸 수 있게 한다.
@interface Work{
String value();
}위와 같이 선언하면 아래와 같이 하나의 대상에 여러번 적용하는 것이 가능하다.
@Work("코드 업데이트")
@Work("메서드 오버라이딩")
class Main{
... 생략 ...
}cf. @Repeatable 애너테이션은 일반적인 애너테이션과 달리 같은 이름의 애너테이션이 여러번 적용될 수 있기 때문에, 이 애너테이션들을 하나로 묶어주는 애너테이션도 별도로 작성해야 한다.
@interface Works { // 여러개의 Work애너테이션을 담을 컨테이너 애너테이션 Works
Work[] value();
}
@Repeatable(Works.class) // 컨테이너 애너테이션 지정
@interface Work {
String value();
}솔직히 뭐 할 때 어떻게 쓸지 감이 잘오지 않지만 일단은 이런게 있다는 정도만 알고 넘어가겠다.
사용자 정의 애너테이션
사용자가 직접 애너테이션을 정의해서 사용하는 것
@interface 애너테이션명 { // 인터페이스 앞에 @기호만 붙이면 애너테이션을 정의할 수 있다.
타입 요소명(); // 애너테이션 요소를 선언
}cf. 애너테이션은 java.lang.annotation 인터페이스를 상속받기 때문에 다른 클래스나 인터페이스를 상속 받을 수 없다.
람다(Lambda)
함수형 프로그래밍 기법을 지원하는 자바의 문법요소
- 메서드를 하나의 ‘식(expression)’으로 표현한 것으로, 코드를 매우 간결하면서 명확하게 표현할 수 있다는 큰 장점이 있다.
람다식의 기본 문법
- 람다식에서는 기본적으로 반환타입과 이름을 생략할 수 있다
//기존 메서드 표현 방식
void sayhello() {
System.out.println("HELLO!")
}
//위의 코드를 람다식으로 표현한 식
() -> System.out.println("HELLO!")// 기존 방식
void example3(String str) {
System.out.println(str);
}
// 람다식
(String str) -> { System.out.println(str);}- 특정 조건이 충족되면 람다식을 더욱 축약하여 표현할 수 있다.
- 메서드 바디에 문장이 실행문이 하나만 존재할 때 중괄호와 return 문을 생략할 수 있다. 이 경우, 세미콜론까지 생략해야 한다.
- 매개변수 타입을 함수형 인터페이스를 통해 유추할 수 있는 경우에는 매개변수의 타입을 생략할 수 있다.
//기존 방식
int sum(int num1, int num2) {
return num1 + num2;
}
// 실행문이 하나만 존재할 때 람다식
(int num1, int num2) -> num1 + num2
// 함수형 인터페이스를 통해 유추할 수 있는 경우 람다식
(num1, num2) -> num1 + num2이 외에도 매개변수가 하나인 경우 소괄호 생략할 수 있는 등의 조건들이 있는데, 추가적인 축약 표현은 검색을 통해 공부하고 사용하자.
함수형 인터페이스
람다식을 사용하기 위한 문법 요소
- 람다식은 객체이며, 이름이 없기 때문에 익명 객체라 할 수 있다.
- 익명 객체는 익명 클래스를 통해 만들 수 있다.
- 익명 클래스 = 객체의 선언과 생성을 동시에 하여 오직 하나의 객체를 생성하고, 단 한번만 사용되는 일회용 클래스
- 기존의 인터페이스 문법을 활용하여 람다식을 다룰 수 있다.
람다식과 인터페이스의 메서드가 1:1로 매칭되어야 하기 때문에 함수형 인터페이스에는 단 하나의 추상 메서드만 선언될 수 있다.
public class LamdaExample1 {
public static void main(String[] args) {
ExampleFunction exampleFunction = (num1, num2) -> num1 + num2;
System.out.println(exampleFunction.sum(10,15));
}
@FunctionalInterface // 컴파일러가 인터페이스가 바르게 정의되었는지 확인
interface ExampleFunction { //함수형 인터페이스
int sum(int num1, int num2);
}
// 출력값
25인터페이스 타입으로 선언된 참조변수에 람다식을 할당해 위와 같이 사용할 수 있다.
매개변수와 리턴값이 없는 람다식
@FunctionalInterface
public interface MyFunctionalInterface {
void accept();
}@FunctionalInterface
interface MyFunctionalInterface {
void accept();
}
public class MyFunctionalInterfaceExample {
public static void main(String[] args) throws Exception {
MyFunctionalInterface example = () -> System.out.println("accept() 호출");
example.accept();
}
}
// 출력값
accept() 호출매개변수가 있는 람다식
@FunctionalInterface
public interface MyFunctionalInterface {
void accept(int x);
}public class MyFunctionalInterfaceExample {
public static void main(String[] args) throws Exception {
MyFunctionalInterface example;
example = (x) -> {
int result = x * 5;
System.out.println(result);
};
example.accept(2);
example = (x) -> System.out.println(x * 5);
example.accept(2);
}
}
// 출력값
10
10
리턴값이 있는 람다식
@FunctionalInterface
public interface MyFunctionalInterface {
int accept(int x, int y);
}public class MyFunctionalInterfaceExample {
public static void main(String[] args) throws Exception {
MyFunctionalInterface example;
example = (x, y) -> {
int result = x + y;
return result;
};
int result1 = example.accept(2, 5);
System.out.println(result1);
example = (x, y) -> { return x + y; };
int result2 = example.accept(2, 5);
System.out.println(result2);
example = (x, y) -> x + y;
//return문만 있을 경우, 중괄호 {}와 return문 생략가능
int result3 = example.accept(2, 5);
System.out.println(result3);
example = (x, y) -> sum(x, y);
//return문만 있을 경우, 중괄호 {}와 return문 생략가능
int result4 = example.accept(2, 5);
System.out.println(result4);
}
public static int sum(int x, int y){
return x + y;
}
}
//출력값
7
7
7
7자바에서 기본적으로 제공하는 함수형 메서드
자바에서는 빈번하게 사용되는 함수형 인터페이스를 기본적으로 제공한다.
함수형 인터페이스 API DOC에서 제공되는 인터페이스 확인이 가능하다.
메서드 레퍼런스
- 메서드 참조는 람다식에서 불필요한 매개변수를 제거할 때 주로 사용
- 람다식으로 간단해진 익명 객체를 더 간단하게 만들기
입력값과 출력값의 반환타입을 쉽게 유추할 수 있는 경우 메서드 참조를 이용해 아래와 같이 간단히 표현이 가능하다.
정적 메서드와 인스턴스 메서드 참조
// 정적 메서드
클래스 :: 메서드
// 인스턴스 메서드 (먼저 객체를 생성해야함)
참조 변수 :: 메서드//Calculator.java
public class Calculator {
public static int staticMethod(int x, int y) {
return x + y;
}
public int instanceMethod(int x, int y) {
return x * y;
}
}import java.util.function.IntBinaryOperator;
public class MethodReferences {
public static void main(String[] args) throws Exception {
IntBinaryOperator operator;
/*정적 메서드
클래스이름::메서드이름
*/
operator = Calculator::staticMethod;
System.out.println("정적메서드 결과 : " + operator.applyAsInt(3, 5));
/*인스턴스 메서드
인스턴스명::메서드명
*/
Calculator calculator = new Calculator();
operator = calculator::instanceMethod;
System.out.println("인스턴스 메서드 결과 : "+ operator.applyAsInt(3, 5));
}
}
/*
정적메서드 결과 : 8
인스턴스 메서드 결과 : 15
*/생성자 참조
- 생성자를 참조한다는 것은 객체 생성을 의미
//생성자 참조 문법
클래스 :: new- 생성자가 오버로딩 되어 여러 개가 있을 경우 컴파일러는 함수형 인터페이스의 추상 메서드와 동일한 매개 변수 타입과 개수를 가지고 있는 생성자를 찾아 실행
//Member.java
public class Member {
private String name;
private String id;
public Member() {
System.out.println("Member() 실행");
}
public Member(String id) {
System.out.println("Member(String id) 실행");
this.id = id;
}
public Member(String name, String id) {
System.out.println("Member(String name, String id) 실행");
this.id = id;
this.name = name;
}
public String getName() {
return name;
}
public String getId() {
return id;
}
}import java.util.function.BiFunction;
import java.util.function.Function;
public class ConstructorRef {
public static void main(String[] args) throws Exception {
Function<String, Member> function1 = Member::new;
Member member1 = function1.apply("kimcoding");
System.out.println(member1.getId());
BiFunction<String, String, Member> function2 = Member::new;
Member member2 = function2.apply("kimcoding", "김코딩");
System.out.println(member2.getName()+member2.getId());
}
}
/*출력
Member(String id) 실행
kimcoding
Member(String name, String id) 실행
kimcoding김코딩
*/생성자 참조는 두 가지 방법(Function,BiFunction) 모두 동일하지만, 실행되는 Member 생성자가 다른 것을 볼 수 있다.
스트림(Stream)
배열, 컬렉션의 저장 요소를 하나씩 참조해서 람다식으로 처리할 수 있도록 해주는 반복자
-
List, Set, Map, 배열 등 다양한 데이터 소스로부터 스트림을 만들 수 있고, 이를 표준화된 방법으로 다룰 수 있다.
-
스트림은 데이터 소스를 다루는 풍부한 메서드를 제공한다.
스트림(Stream)의 도입 배경
지금까지 자료구조(배열과 컬렉션)를 for문 과 Iterator를 통해 데이터 가공을 했지만 아래 2가지 한계점이 있다.
- 코드가 길고 복잡해질 수 있다.
- Iterator 를 사용한 반복 처리
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
public class PrintNumberOperator {
public static void main(String[] args) {
// 각 숫자를 배열화
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
// Iterator 생성
Iterator<Integer> it = list.iterator();
// 리스트를 순회하며 값 출력
while (it.hasNext()) {
int num = it.next();
System.out.print(num);
}
}
}
//출력값
12345- 스트림을 사용한 반복 처리
import java.util.Arrays;
import java.util.List;
import java.util.stream.Stream;
public class PrintNumberOperatorByStream {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> stream = list.stream();
stream.forEach(System.out::print);
}
}
//출력값
12345List선언을 제외하면 4줄 -> 2줄로 매우 간단해진 것을 볼 수 있다.
스트림을 사용하면 선언형 프로그래밍(Declarative Programming) 방식으로 데이터를 처리할 수 있다.
"어떻게"코드를 작성할 지 보다 "무엇"을 작성할지에 집중할 수 있는 것이다.
(즉, 내부의 동작 원리를 모르더라도 어떤 코드가 어떤 역할을 하는 지 직관적으로 이해할 수 있다. )
import java.util.List;
public class DeclarativePrograming {
public static void main(String[] args){
// List에 있는 숫자들 중에서 4보다 큰 짝수의 합계 구하기
List<Integer> numbers = List.of(1, 3, 6, 7, 8, 11);
int sum =
numbers.stream()
.filter(number -> number > 4 && (number % 2 == 0)) //4보다 크면서 짝수인 수를 걸러줌
.mapToInt(number -> number)// 걸러진 값들을 int 타입의 정수로 바꿔줌
.sum();
System.out.println("선언형 프로그래밍을 사용한 합계 : " + sum);
}
}
//출력값
선언형 프로그래밍을 사용한 합계 : 14람다식을 사용하여 데이터를 처리하고 있다.
- 데이터 소스를 각기 다른 방식으로 다뤄야한다는 불편함이 있다.
- 스트림을 사용하면, 데이터 소스가 무엇이냐에 관계없이 같은 방식으로 데이터를 가공/처리 할 수 있다.
(배열이냐 컬렉션이냐에 관계없이 하나의 통합된 방식으로 데이터를 다룰 수 있게 되었다는 뜻)
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Stream;
public class StreamOperator {
public static void main(String[] args) {
// ArrayList
List<String> fruitList = new ArrayList<>();
fruitList.add("바나나 ");
fruitList.add("사과 ");
fruitList.add("오렌지 ");
// 배열
String[] fruitArray = {"바나나 ", "사과 ", "오렌지 "};
// 각각 스트림 생성
Stream<String> ListStream = fruitList.stream();
Stream<String> ArrayStream = Arrays.stream(fruitArray);
// 출력
ListStream.forEach(System.out::print);
ArrayStream.forEach(System.out::print);
}
}
//출력값
바나나 사과 오렌지 바나나 사과 오렌지forEach() 메서드 = 데이터 소스의 각 요소들을 순회하면서 람다식 안에 정의된 어떤 명령을 실행하는 데 사용하는 최종연산자
스트림의 특징
스트림의 4 가지의 특징
-
스트림 처리 과정은 생성, 중간 연산, 최종 연산 세 단계의 파이프라인으로 구성될 수 있다.
- ex. 스트림 생성 -> 필터링, 매핑, 정렬 -> 총합, 평균, 카운팅
-
스트림은 원본 데이터 소스를 변경하지 않는다(read-only).
-
스트림은 일회용이다(onetime-only).
-
스트림은 내부 반복자이다.
- 컬렉션 내부에 데이터 요소 처리 방법(람다식)을 주입시켜서 요소를 반복처리하는 방식 (데이터를 가져와
for문,Iterator등에 넣어 사용하는 외부 반복자(External Iterator)의 반대)
- 컬렉션 내부에 데이터 요소 처리 방법(람다식)을 주입시켜서 요소를 반복처리하는 방식 (데이터를 가져와
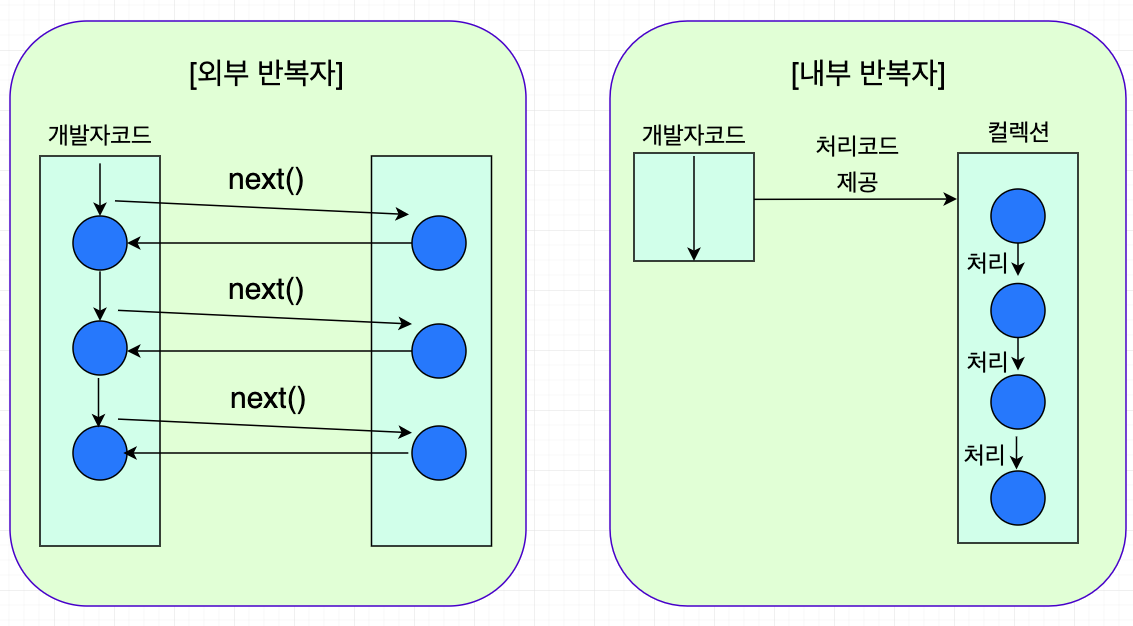
스트림의 생성
배열, 컬렉션, 임의의 수, 특정 범위의 정수 등에 따라 스트림의 생성 방법에 조금씩 차이가 있다.
배열 스트림 생성
Arrays 클래스의 stream() 메서드 또는 Stream 클래스의 of() 메서드를 사용
// Arrays.stream()
Stream<String> stream = Arrays.stream(arr);
// Stream.of()
Stream<String> stream = Stream.of(arr);
배열로 스트림을 생성할 시에는 둘 중에 더 편한 메서드를 임의로 선택(큰차이x)
int, long , double 과 같은 기본형 배열을 데이터 소스로 스트림을 생성하는 메서드도 있다. (필요하면 검색 ㄱ)
숫자와 관련된 경우 intStream을 사용하자.
import java.util.Arrays;
import java.util.stream.IntStream;
public class StreamCreator {
public static void main(String[] args) {
// int형 배열로 스트림 생성
int[] intArr = {1,2,3,4,5,6,7};
IntStream intStream = Arrays.stream(intArr);
// 숫자와 관련된 경우 intStream을 사용하는 것을 권장
System.out.println("sum=" + intStream.sum());
// System.out.println("average=" + intStream.average());
//최종 연산(sum) 후에 스트림이 닫히기 때문에 다시 average 같은 메서드 쓰면 오류 남.
}
}
//출력값
sum=28컬렉션 스트림 생성
Collection 으로부터 확장된 하위클래스(List, Set)룰 규횬헌 컬렉션 클래스들 모두 stream() 메서드를 사용하여 스트림을 생성
import java.util.Arrays;
import java.util.List;
import java.util.stream.Stream;
public class StreamCreator {
public static void main(String[] args) {
// 요소들을 리스트
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7);
Stream<Integer> stream = list.stream();
stream.forEach(System.out::print);
}
}
//출력값
1234567임의의 수 스트림 생성
//무한 스트림
IntStream ints = new Random().ints();
//스트림 생성의 범위를 5개로 제한
IntStream ints = new Random().ints(5); //stram사이즈를 5로 제한
IntStream ints = new Random().ints().limit(5); // max사이즈를 5로 할당
//특정 범위의 정수 (랜덤X)
IntStream intStream = IntStream.rangeClosed(1, 10);// 1이상 10이하
IntStream intStream = IntStream.range(1, 10); // 1이상 10미만스트림의 중간 연산
스트림의 중간 연산자의 결과는 스트림을 반환하기 때문에 여러 개의 연산자를 연결하여 데이터 처리를 수행할 수 있다.
공식 스펙 문서에서 다양한 중간 연사자 확인 가능.
주로 사용하는건 필터링(filtering), 매핑(maping), 정렬(sorting) 이다.
Stream
.of(1,2,3,4) // 데이터 소스
.filter(n -> n % 2 == 0)) // 중간 연산
.map(n -> n*2)// 중간 연산
.sum(); //최종 연산위 기본 구조를 다시 생각하며 아래 내용을 보자.
필터링(filter() , distinct() )
조건에 맞는 데이터들만을 정제하는 역할
-
distinct(): 중복된 데이터가 존재하는 경우, 중복을 제거하기 위해 사용 -
filter(): 조건에 맞는 데이터만을 정제하여 더 작은 컬렉션을 만듦- 매개값으로 조건(Predicate)이 주어짐
- 조건이 참이 되는 요소만 필터링
- 조건은 람다식을 사용하여 정의할 수 있음
import java.util.Arrays;
import java.util.List;
public class FilteringExample {
public static void main(String[] args) throws Exception {
List<String> names = Arrays.asList("김현진", "이지은", "박현수", "김현진", "박현수");
names.stream()
.distinct() //중복 제거
.forEach(element -> System.out.println(element));
System.out.println();
names.stream()
.filter(element -> element.startsWith("김")) // 김씨 성을 가진 요소만 필터링
.forEach(element -> System.out.println(element));
System.out.println();
names.stream()
.distinct() //중복제거
.filter(element -> element.startsWith("김")) // 김씨 성을 가진 요소만 필터링
.forEach(element -> System.out.println(element));
}
}
// 출력값
김현진
이지은
박현수
김현진
김현진
김현진매핑 map()
원하는 필드만 추출하거나 특정 형태로 변환할 때 사용
- filter() 메서드와 마찬가지로 값을 변환하기 위한 조건을 람다식으로 정의한다.
//요소들을 하나씩 대문자로 변환
.map(element -> element.toUpperCase())
// 각 요소에 2를 곱한 값을 반환
list.stream().map(number -> number * 2).forEach(System.out::println);이중배열일 때 어떻게 해야할까?
//기존방식
Arrays.stream(namesArray)
.map(inner -> Arrays.stream(inner))
.forEach(System.out::println);
//이중배열
Arrays.stream(namesArray)
.map(inner -> Arrays.stream(inner))
.forEach(names -> names.forEach(System.out::println));
위와 같이 할 수 있지만 가독성이 떨어지고 번거롭다.
이럴 때 flatMap()를 쓰자.
// flatMap()
Arrays.stream(namesArray).flatMap(Arrays::stream).forEach(System.out::println);flatMap()은 중첩 구조를 제거하고 단일 컬렉션(Stream<String>)으로 만들어주는 역할을 한다.
(cf. “평평하게”한다는 의미에서 플래트닝(flattening)이라고 함)
정렬 sorted()
정렬을 할 때 사용하는 중간 연산자
sorted(정렬방식)정렬방식을 넣지 않으면 기본 정렬(오름차순)로 됨.
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
public class IntermediateOperationExample {
public static void main(String[] args) {
List<String> animals = Arrays.asList("Tiger", "Lion", "Monkey", "Duck", "Horse", "Cow");
// 인자값에 Comparator 인터페이스에 규정된 메서드 사용
animals.stream().sorted(Comparator.reverseOrder()).forEach(System.out::println);
// Comparator.reverseOrder() = 역순으로 정렬
}
}
// 출력값
Tiger
Monkey
Lion
Horse
Duck
CowComparator 인터페이스에 정의된 메소드는 공식문서에서 확인 가능.
기타
-
skip(): 스트림의 일부 요소들을 건너뛴다.- ex. 앞의 5개의 숫자를 건너뛰고 숫자 6부터 출력
-
limit(): 스트림의 일부를 자른다.- ex. 앞에서부터 5개의 숫자만 출력
- ex. 앞에서부터 5개의 숫자만 출력
-
peek():forEach()와 마찬가지로, 요소들을 순회하며 특정 작업을 수행peek는 여러번 사용 가능forEach()(최종연산자)는 한번만 가능- 디버깅 용도로 종종 사용
- ex. 요소들 순회하며 print 찍을 때 사용
스트림의 최종 연산
숫자와 관련된 기본적인 집계의 경우에는 대부분 최종 연산자다.
기본 집계(sum() , count() , average(), max() , min())
import java.util.Arrays;
public class TerminalOperationExample {
public static void main(String[] args) {
// int형 배열 생성
int[] intArray = {1,2,3,4,5};
// 카운팅
long count = Arrays.stream(intArray).count();
System.out.println("intArr의 전체 요소 개수 " + count);
// 합계
long sum = Arrays.stream(intArray).sum();
System.out.println("intArr의 전체 요소 합 " + sum);
// 평균
double average = Arrays.stream(intArray).average().getAsDouble();
System.out.println("전체 요소의 평균값 " + average);
// 최대값
int max = Arrays.stream(intArray).max().getAsInt();
System.out.println("최대값 " + max);
// 최소값
int min = Arrays.stream(intArray).min().getAsInt();
System.out.println("최소값 " + min);
// 배열의 첫 번째 요소
int first = Arrays.stream(intArray).findFirst().getAsInt();
System.out.println("배열의 첫번째 요소 " + first);
}
}
// 출력값
intArr의 전체 요소 개수 5
intArr의 전체 요소 합 15
전체 요소의 평균값 3.0
최대값 5
최소값 1
배열의 첫번째 요소 1getAsInt();는 기본타입이 래퍼 클래스 형태로 사용되는 연산자의 출력값을 기본형(int)으로 값을 바꾸기 위해 추가한 것이다.
OptionalInt average = Arrays.stream(intArr).average();
래퍼 클래스 형태로 하려면 위와 같이 Optional 붙여야 한다.
매칭(allMatch(), anyMatch(), noneMatch() )
3가지 match() 메서드
allMatch(): 모든 요소들이 조건을 만족하는 지 여부를 판단noneMatch(): 모든 요소들이 조건을 만족하지 않는 지 여부를 판단anyMatch(): 하나라도 조건을 만족하는 요소가 있는 지 여부를 판단
조건식 람다 Predicate 를 매개변수로 넘겨 스트림의 각 데이터 요소들이 특정한 조건을 충족하는 지 만족시키지 않는지 검사하여, 그 결과를 boolean 값으로 반환
import java.util.Arrays;
public class TerminalOperationExample {
public static void main(String[] args) throws Exception {
// int형 배열 생성
int[] intArray = {2,4,6};
// allMatch()
boolean result = Arrays.stream(intArray).allMatch(element-> element % 2 == 0);
System.out.println("요소 모두 2의 배수인가요? " + result);
// anyMatch()
result = Arrays.stream(intArray).anyMatch(element-> element % 3 == 0);
System.out.println("요소 중 하나라도 3의 배수가 있나요? " + result);
// noneMatch()
result = Arrays.stream(intArray).noneMatch(element -> element % 3 == 0);
System.out.println("요소 중 3의 배수가 하나도 없나요? " + result);
}
}
// 출력값
요소 모두 2의 배수인가요? true
요소 중 하나라도 3의 배수가 있나요? true
요소 중 3의 배수가 하나도 없나요? false요소 소모 reduce()
스트림의 요소를 줄여나가면서 연산을 수행하고 최종적인 결과를 반환
reduce(초기값, 람다식)
import java.util.Arrays;
public class TerminalOperationExample {
public static void main(String[] args) throws Exception {
int[] intArray = {1,2,3,4,5};
// sum()
long sum = Arrays.stream(intArray).sum();
System.out.println("intArray 전체 요소 합: " + sum);
// 초기값이 없는 reduce()
int sum1 = Arrays.stream(intArray)
.map(element -> element * 2)
.reduce((a , b) -> a + b) // a: 누적 값, b: 새롭게 더해질 값
.getAsInt();
System.out.println("초기값이 없는 reduce(): " + sum1);
// 초기값이 있는 reduce()
int sum2= Arrays.stream(intArray)
.map(element -> element * 2)
.reduce(7, (a ,b) -> a + b);
System.out.println("초기값이 있는 reduce(): " + sum2);
}
}
// 출력값
intArray 전체 요소 합: 15
초기값이 없는 reduce(): 30
초기값이 있는 reduce(): 37
요소 수집 collect()
요소들을 수집하는 최종 처리 메서드
-
스트림의 요소들을 List, Set, Map 등 다른 타입의 결과로 수집하고 싶은 경우 사용
-
요소 그룹핑, 분할 등 다른 기능들도 제공 (공식문서에서 확인 가능)
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class TerminalOperationExample {
public static void main(String[] args) {
// Student 객체로 구성된 배열 리스트 생성
List<Student> totalList = Arrays.asList(
new Student("김코딩", 100, Student.Gender.Male),
new Student("박해커", 80, Student.Gender.Male),
new Student("이자바", 90, Student.Gender.Female),
new Student("나미녀", 60, Student.Gender.Female)
);
// 스트림 연산 결과를 Map으로 반환
Map<String, Integer> maleMap = totalList.stream()
.filter(s -> s.getGender() == Student.Gender.Male)
.collect(Collectors.toMap(
student -> student.getName(), // Key
student -> student.getScore() // Value
));
// 출력
System.out.println(maleMap);
}
}
class Student {
public enum Gender {Male, Female};
private String name;
private int score;
private Gender gender;
public Student(String name, int score, Gender gender) {
this.name = name;
this.score = score;
this.gender = gender;
}
public String getName() {
return name;
}
public int getScore() {
return score;
}
public Gender getGender() {
return gender;
}
}
// 출력값
{김코딩=100, 박해커=80}