데이터베이스란?
데이터베이스. 코딩에 대해 하나도 모르던 시절부터 많이도 들어온 단어다. 어렴풋한 이미지는 있었지만 정확히 뭐냐고 물어보면 아마 "어... 데이터가 많은 거?"라고 대답했겠지.
사실 그렇게 틀린 것도 아니다. 오라클이 내린 데이터베이스의 정의를 먼저 확인해보자.
-
데이터베이스란 컴퓨터에 저장된 정보의 베이스, 기지로 곧
데이터의 집합이다. 조금 더 길게 표현하자면 "컴퓨터 시스템에 저장된 정보나 데이터를 모아 놓은 집합" 이라고도 할 수 있겠다. -
체계적인 테이블 모양으로 정리된 데이터베이스를 다루는 시스템, 즉 소프트웨어가 바로
DBMS다.
DBMS의 종류로는 Oracle, MySQL, MS-SQL, Maria DB 등이 있다. -
프로그래밍 언어
SQL을 사용해 데이터를 조작할 수 있다.
데이터란?
그러면 이 데이터란 어떤 놈일까? 정보란 어떤 놈일까?
A공원에 강아지들이 산책을 많이 하러 나온다고 생각해 보자. 아침에는 리트리버가 지나가고 점심 때에는 닥스훈트와 치와와가, 저녁에는 리트리버와 허스키가 산책을 한다. 리트리버는 나오면 2시간이 지나야 들어가지만 치와와나 닥스훈트는 45분이면 들어간다. 허스키는 1시간 20분동안 산책한다.
이런 것들을 정리해 표현하자면 이렇게 할 수 있을 것이다:
| A공원을_산책하는_강아지 | |||
|---|---|---|---|
| 견종 | 이름 | 시간 | 횟수 |
| 리트리버 | 코코 | 2시간 | 2회 |
| 닥스훈트 | 소세지 | 45분 | 1회 |
| 치와와 | 깡깡이 | 45분 | 1회 |
| 허스키 | 쫑이 | 1시간 20분 | 1회 |
이런 테이블이 있다면,SQL을 사용해 이렇게 출력할 수도 있을 것이다:
SELECE 견종 FROM A공원을_산책하는_강아지 WHERE 시간="2시간"
= "A공원을_산책하는_강아지" 테이블에서 산책 시간이 2시간인 견종을 출력해라.결과는 이렇겠지.
| 견종 |
| 리트리버 |
단순히 말로 설명된 정보보다 깔끔하고 체계적인 것을 확인할 수 있다.
그럼 엑셀이랑 뭐가 다른데?
표로 작성된다는 점에서 비슷하다. 둘 다 정보를 편리하게 저장, 수정할 수 있다. 그러나 데이터베이스는 엑셀과 달리 정보를 조작하는 방법이 다르고, 대량의 복잡한 정보를 다룬다. 또 여러 사람이 접속해 데이터를 요청하고 수정할 수 있기도 하다.
데이터베이스를 다루는 소프트웨어인 DBMS(관리 시스템), 그 중에서도 거의 RDBMS가 사용된다.
이 R이란 'relational'로, 관계형 데이터베이스 관리 시스템을 뜻하는데, 각 테이블끼리의 관계성을 표현할 수 있다.
RDBMS
one-to-many
다시 A공원으로 돌아오자.
A공원에서 산책하는 강아지들 중 리트리버는 보호자가 세 명인데 요일별로 돌아가면서 산책을 나온다. 닥스훈트는 보호자가 한 명이지만 치와와는 두 명인데 항상 함께 산책한다. 허스키는 보호자 두 명이 돌아가며 산책한다.
이것을 테이블로 만들면 아래와 같다:
| A공원을_산책하는_보호자 | ||
|---|---|---|
| 강아지 이름 | 보호자 | 요일 |
| 코코 | 엄마 보호자 | 월, 수, 금 |
| 코코 | 아빠 보호자 | 토, 일 |
| 코코 | 딸 보호자 | 화, 목 |
| 소세지 | 할아버지 보호자 | 매일 |
| 깡깡이 | 아빠 보호자 | 매일 |
| 깡깡이 | 아들 보호자 | 매일 |
| 쫑이 | 여자 보호자 | 월~목 |
| 쫑이 | 남자 보호자 | 금, 토, 일 |
아까의 테이블 "A공원을_산책하는_강아지"와 "A공원을_산책하는_보호자"에는 연관성이 있다. 이 연관성을 표현하면 다음과 같다.
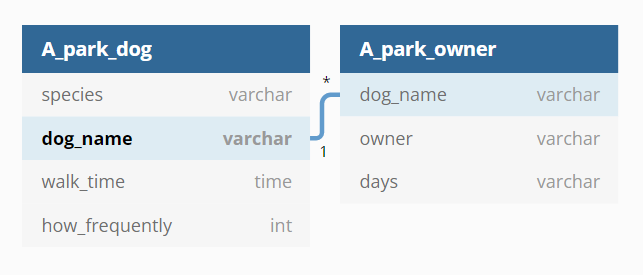
사실 이름도 얼마든지 중복될 수 있으므로 이름으로 엮어서는 안 되고
고유한 id같은 것을 부여해야 하지만,(그리고 자동으로 부여되지만) 지금은 편의상 이렇게 진행한다."A공원을_산책하는_강아지" 테이블의 dog_name으로 "A공원을_산책하는_보호자"의 dog_name을 확인하면, 함께 산책하는 보호자와 그 보호자가 언제 산책하는지를 알 수 있게 된다.
각 테이블의 dog_name이 연결된 것이 보이는가? "A공원을_산책하는_강아지" 테이블의 dog_name은 산책 나오는 강아지들을 목록으로 만든 것이므로 중복되지 않는, 고유한 데이터다. "A공원을_산책하는_보호자"의 dog_name은 한 강아지가 여러 보호자를 가질 수 있으므로 중복될 수 있다.
양 테이블의 dog_name에 1과 *이 있는 것이 보일 것이다. 이렇게 연결되어 연관성을 표현하는 것이 테이블의 관계성을 표현하는 RDBMS라고 할 수 있다.
그러면 이 1과 *는 무엇일까? 상기 언급한 바와 같이 "A공원을_산책하는_강아지" 테이블의 dog_name은 중복되지 않는다.(정확히 따지자면 될 수 있지만, 지금은 이렇게 생각하자) 견종과 산책 시간, 횟수 등은 얼마든지 중복될 수 있지만 이렇게 고유한 속성을 가짐으로서 각 데이터는 구분될 수 있다. 반대로 "A공원을_산책하는_보호자"에서의 dog_name은 한 강아지가 여러 보호자를 가질 수 있다. 얼마든지 중복될 수 있는 것이다.
"A공원을_산책하는_강아지" 테이블의 dog_name은 한 강아지일 수밖에 없기 때문에 1이고, "A공원을_산책하는_보호자" 테이블의 dog_name은 여럿일 수 있기 때문에 *, 즉 N이다.
이런 관계를 1대다 관계, one-to-many 관계라고 한다.
강아지로 시작해서 갑자기 이상한 게 튀어나왔다!
관계란 바로 데이터 사이의 관계성을 가시적으로 표현한 것이다. 컴퓨터는 이런 관계성을 통해 데이터를 묶어서 관리할 수 있다. 만약 강아지의 이름에 안 좋은 기운이 있다고 해서(ㅋㅋ) 이름을 바꾼다고 생각해 보자.
"A공원을_산책하는_보호자" 테이블의 모든 dog_name을 바꾸는 것보다, "A공원을_산책하는_강아지" 테이블의 dog_name을 수정해 바뀐 이름이 "A공원을_산책하는_보호자" 테이블에 알아서 적용되게 하는 게 훨씬 나을 것이다. 특히 이렇게 연결되는 데이터가 많으면 많을수록 그렇다!
이외에도 RDBMS에서는 다양한 관계성을 표현할 수 있다.
one-to-one
| A공원을_산책하는_강아지 | |||
|---|---|---|---|
| 견종 | 이름 | 시간 | 횟수 |
| 리트리버 | 코코 | 2시간 | 2회 |
| 닥스훈트 | 소세지 | 45분 | 1회 |
| 치와와 | 깡깡이 | 45분 | 1회 |
| 허스키 | 쫑이 | 1시간 20분 | 1회 |
다시 이 테이블만 생각해 보자. 강아지들이 가장 좋아하는 보호자를 한 명 고르고 싶다. 그러면 이런 테이블이 완성될 것이다.
| 강아지가_가장_좋아하는_보호자 | |
|---|---|
| 이름 | 보호자 |
| 코코 | 엄마 보호자 |
| 소세지 | 할아버지 보호자 |
| 깡깡이 | 아들 보호자 |
| 쫑이 | 여자 보호자 |
두 테이블 간에는 강아지의 이름이라는 연관성이 있다. 이것을 다이어그램으로 표현하면 다음과 같다.
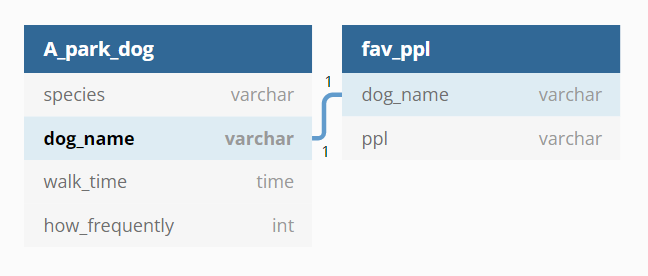
강아지가 "가장" 좋아하는 보호자이므로 데이터는 1개만 나올 수 있을 것이고, A공원에 산책하러 오는 강아지의 목록에서도 강아지는 1개의 데이터로 저장된다. 이렇게 A_park_dog과 fav_ppl의 강아지는 각각 1:1 대응된다. 이런 관계를 1대1, one-to-one 관계라고 표현한다. 테이블의 양쪽에 연결된 1, 1이 그것을 표현한다.
이런 관계로는 이름과 학번, 주민등록번호와 핸드폰번호 등이 있다.
many-to-many
다대다 관계는 살짝 쉽게 말해보자면 한 정보가 여러 테이블에 여러 결과를 가지는 것이라고도 할수 있을 것이다.
강아지로 돌아와 보자. (강아지 안 키운다)
강아지들이 좋아하는 간식을 조사했다. 개껌, 육포, 북어 큐브, 오리 목뼈 등이 있는데, 한 강아지가 여러 간식을 좋아할 수 있고, 같은 간식이 여러 강아지들의 사랑을 받을 수도 있다.
| 강아지_간식 | ||
|---|---|---|
| id | 이름 | 가격 |
| A01 | 육포 | 5,000 |
| A02 | 북어 큐브 | 7,500 |
| B07 | 오리 목뼈 | 20,000 |
| B11 | 개껌 | 1,700 |
| C03 | 말린 고구마 | 12,000 |
| 강아지 목록 | ||
|---|---|---|
| id | 이름 | 견종 |
| 01L | 코코 | 리트리버 |
| 02G | 소세지 | 닥스훈트 |
| 03H | 깡깡이 | 치와와 |
| 04P | 쫑이 | 허스키 |
| 05N | JB | 퍼그 |
잠시 id는 무시하고, 이 두 테이블을 가지고 강아지가 좋아하는 간식이라는 테이블을 만들어 보자.
| 강아지와_강아지가_좋아하는_간식 | |||
|---|---|---|---|
| 강아지 이름 | 견종 | 간식 이름 | 간식 가격 |
| 코코 | 리트리버 | 육포 | 5,000 |
| 코코 | 리트리버 | 개껌 | 1,700 |
| 코코 | 리트리버 | 북어 큐브 | 7,500 |
| 소세지 | 닥스훈트 | 말린 고구마 | 12,000 |
| 소세지 | 닥스훈트 | 오리 목뼈 | 20,000 |
| 깡깡이 | 치와와 | 개껌 | 1,700 |
| 쫑이 | 허스키 | 육포 | 5,000 |
| 쫑이 | 허스키 | 말린 고구마 | 12,000 |
| JB | 퍼그 | 오리 목뼈 | 20,000 |
모든 데이터를 전부 합쳤다. 강아지의 id와 간식의 id까지 있으면 훨씬 한번에 알아보기 어려운 테이블이 되어 있을 것이다. 강아지 이름도 여러 번 나오고 간식 이름도 여러 번 나온다. 데이터들이 의미없이 중복되고 있는 것이다.
이렇게 데이터가 중복될 경우, 지금은 괜찮지만 데이터가 아주 많을 경우(전국의 강아지들이 좋아하는 간식을 조사했다고 생각해 보자!) 비효율적일 뿐더러 보기 편하지도 않을 것이다. 또 만약 간식의 이름이 바뀌었다면? 강아지가 좋아하는 간식이 바뀌었다면? 어떤 테이블에는 데이터가 수정되고 어떤 테이블에서는 그렇지 않다면, 데이터의 일관성이 깨지므로 지양해야 한다.
그러면 어떻게 해야 효율적인 테이블을 만들 수 있을까?
| 강아지와_강아지가_좋아하는_간식 | |
|---|---|
| 강아지 이름 | 간식 이름 |
| 코코 | 육포 |
| 코코 | 개껌 |
| 코코 | 북어 큐브 |
| 소세지 | 말린 고구마 |
| 소세지 | 오리 목뼈 |
| 깡깡이 | 개껌 |
| 쫑이 | 육포 |
| 쫑이 | 말린 고구마 |
| JB | 오리 목뼈 |
위의 테이블이 가진 관계성을 표현한 다이어그램은 다음과 같아진다.

이렇게 하면 "강아지와_강아지가_좋아하는_간식" 테이블에서 dog_name은 여러 번 사용될 수 있지만 dogs 테이블의 데이터 1개를 참조해 온 것이므로 one-to-many 관계를 가지고 있고, 간식 이름도 마찬가지인 것을 알 수 있다.
이런 식으로 테이블을 분리해 중복을 최소화하고 데이터를 구조화하는 것을 정규화라고 한다. 이에 대해서는 다음 포스트에서 이어가도록 하겠다.
