HTTP? 인터넷의 멀티미디어 배달부.
http : Hypertext Transfer Protocol
웹 서버와 웹 클라이언트(브라우저)가 리소스를 주고 받기 위해 정한 통신 규약.
uri : uniform resource identifier
"통합 자원 식별자". 서버의 리소스를 식별하기 위한 이름.
- url : ... locator
가장 흔한 형태. 특정 서버의 한 리소스에 대한 구체적인 위치를 서술한다.
URL
http://www.naver.com/index.html //네이버 홈페이지의 URL- urn : ... name
어떤 리소스에 대한 고유한 이름으로 접근한다. 많이 채택되지 않음.
urn:ietf:rfc:2141- 따라서, 보통 uri와 url을 동일한 의미로 받아들여진다..
미디어 타입
인터넷은 수많은 데이터 타입을 다루기 때문에, 웹에서 주고받는 객체 각각에 MIME 타입이라는 데이터 포맷 라벨을 붙인다. 원래 각기 다른 전자메일 시스템에서 메시지가 오갈 때 겪는 문제를 해결하기 위해 설계되었다. 이메일에서 워낙 잘 작동했기 때문에, http에서도 멀티미디어 콘텐츠를 기술하고 라벨링하기 위해 채택되었다.
예시)
content-type : imgae/jpeg <-- MIME 타입TCP 커넥션
HTTP 네트워크 프로토콜 스택
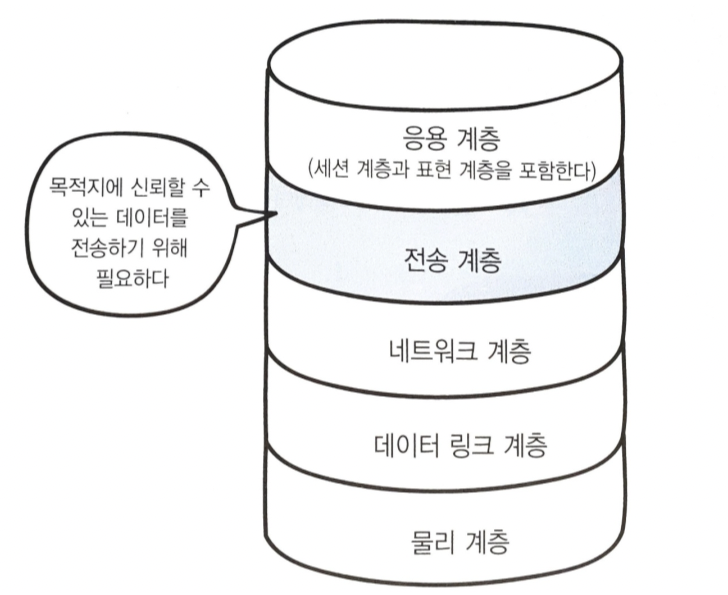
- http : 응용 계층
- tcp : 전송 계층
- ip : 네트워크 계층
TCP/IP는 TCP와 IP가 층을 이루는, 패킷 교환 네트워크이다. TCP/IP는 각 네트워크와 하드웨어의 특성을 숨기고, 어떤 종류의 컴퓨터나 네트워크든 서로 신뢰성 있는 의사소통을 가능하게 한다.
tcp(transmission control protocol). 전송 제어 프로토콜
- HTTP 요청과 응답은 TCP커넥션을 통해 옮겨진다.
- IP(internet protocol)주소와 포트번호를 사용해 클라이언트와 서버 사이에 TCP/IP 커넥션을 맺는다.
URL
http://207.200.83.29:80/index.html
http://www.naver.com:80/index.html
http://www.naver.com/index.html- 첫 번째 URL은 ip주소와 포트번호 80으로 이루어져 있다.
- 두 번째 URL은 숫자로 된 ip주소가 없고, 도메인 혹은 호스트 명을 갖고 있다. 호스트 명은 ip주소에 대한 기억하기 쉬운 형태의 별명이다. 도메인 이름 서비스(DNS)라는 장치를 통해 손쉽게 ip주소로 변경된다.
- 마지막 URL은 포트번호가 없다. 포트번호가 없다면 기본값 80이라고 가정한다.
http를 사용한 TCP/IP통신의 순서
브라우저에 www.naver.com을 쳤을 때 일어나는 일.
1) 브라우저는 www.naver.com(URL)에서 호스트 명을 추출한다.
2) 호스트명을 ip로 변환한다.
3) URL에서 포트번호를 추출한다. (없다면 80)
4) 웹 브라우저는 앞서 얻은 ip주소와 포트번호를 가지고, 웹 서버와 TCP커넥션을 맺는다.
5) 웹 브라우저는 서버에 http요청을 보낸다.
6) 서버는 웹 브라우저에 http응답객체를 돌려보낸다.
7) 커넥션이 닫히면 웹브라우저는 화면에 html 및 기타 리소스(css, js 등)를 랜더링 시작한다.
8) 페이지에 추가 리소스(예: 이미지, 비디오 또는 기타 파일)가 포함된 경우, 브라우저는 추가 HTTP 요청을 실행하여 리소스를 검색합니다.
9) 모든 리소스가 검색되고 페이지 렌더링이 완료되면 브라우저는 사용자에게 최종 결과를 표시합니다.
