당뇨병 예측 머신러닝
다항논리회귀를 통한 당뇨병 예측을 학습시켜보려 합니다.
이 과정은 Colab을 이용해 만들었습니다.
캐글 등록
먼저 캐글에서 데이터셋을 가져올 계획이기 때문에 캐글의 이름과 key를 등록해주겠습니다.
import os
os.environ['KAGGLE_USERNAME'] = 'username' # username
os.environ['KAGGLE_KEY'] = 'userkey' # key데이터셋 다운로드 및 압축풀기
캐글에 존재하는 데이터중 당뇨병과 관련된 데이터셋을 선택해 다운로드 받고 압축을 해제해줍니다.
캐글에서 터미널에서 사용하는 명령어를 사용하려면 앞에
!를 붙여야합니다
!kaggle datasets download -d kandij/diabetes-dataset!unzip diabetes-dataset.zip사용 모듈 import
이번학습에 사용하게 될 모듈들을 불러오겠습니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScalerSequential: 신경망 모델을 구성하기 위해 사용, 레이어를 선형으로 쌓아 구성하는 방식
Dense: 신경망 레이어 중 하나, fully connected 레이어를 생성합니다.
Adam: 경사 하강법 알고리즘을 기반으로 하며, 학습률을 자동으로 조정하면서 효율적인 학습을 수행합니다.
SGD: 확률적 경사 하강법, 각 학습 단계에서 미니 배치의 샘플에 대해 경사 하강법을 수행하여 모델을 업데이트합니다.
numpy: 수치 계산을 위한 라이브러리로, 다차원 배열과 행렬 연산을 지원합니다.
pandas: 데이터 처리와 분석을 위한 라이브러리로, 표 형식의 데이터를 다루는 데 유용합니다.
pyplot: 데이터 시각화를 위한 라이브러리로, 그래프나 도표를 생성하고 표시할 수 있습니다.
seaborn: Matplotlib 기반의 데이터 시각화 라이브러리로, 통계적 그래프를 생성하는 데 특화되어 있습니다.
train_test_split: 데이터를 학습 데이터와 테스트 데이터로 나누는 데 사용되는 함수, 데이터 세트를 무작위로 분할하여 모델의 성능을 평가하고 일반화하는 데에 유용합니다.
StandardScaler: 주어진 데이터의 평균과 표준편차를 이용하여 데이터를 표준화하는 작업을 수행합니다.
csv파일 확인
df = pd.read_csv('diabetes2.csv')
df.head(5)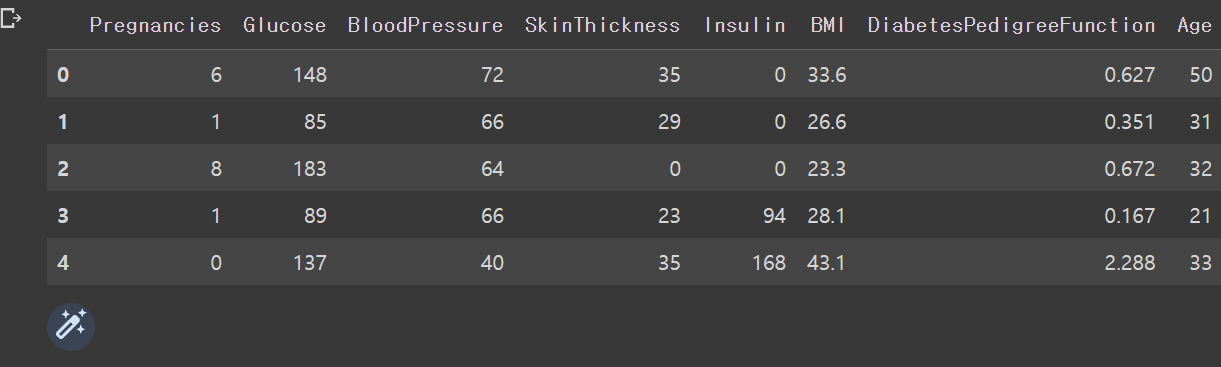
캐글에서 해당 코드를 작성하고 실행했을 때 위와 같이 나오는 것을 볼 수 있습니다.
x데이터 선정 및 변환
x_data = df.drop(columns=['Outcome'], axis=1)
x_data = x_data.astype(np.float32)Outcome열을 제외한 나머지 열들을 선택해 x데이터에 할당했습니다. 사진에는 잘려서 안보이지만 당뇨병인지 아닌지를 outcome열에 0과 1로 나타내고 있습니다.
그리고 부동소수점 형식인 np.float32 타입으로 변환해주었는데 이는 모델 학습을 위한 데이터 형식을 맞추기 위해서입니다.
y데이터 선정 및 변환
y_data = df[['Outcome']]
y_data = y_data.astype(np.float32)y데이터에는 반대로 outcome만 할당을 해줬습니다.
데이터 표준화
scaler = StandardScaler()
x_data_scaled = scaler.fit_transform(x_data)StandardScaler는 데이터의 평균을 0으로 표준편차를 1로 만들기위해 사용합니다. 이는 데이터를 동일한 스케일로 맞추어 비교함으로 모델의 성능을 향상시킵니다.
x_data_scaled는 스케일링이 적용된 x_data입니다. 위의 설명대로 평균이 0이 되고 표준 편차가 1이 되도록 변환된 데이터입니다.
데이터 학습
model = Sequential([
Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.01), metrics=['acc'])
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=50 # epochs 복수형으로 쓰기!
)Sequential은 Keras에서 모델을 생성하는 클래스로, 여기에 순차적으로 레이어를 추가하여 모델을 구성합니다.
Dense는 fully connected 레이어를 의미하며, 1은 출력 뉴런의 개수입니다.
activation='sigmoid'는 활성화 함수로 시그모이드 함수를 사용한다는 의미입니다. 시그모이드 함수는 이진 분류 문제에서 확률 값을 출력하기 위해 주로 사용됩니다.
model.compile은 모델의 손실 함수, 옵티마이저, 그리고 평가 지표(metrics)를 설정합니다. 여기서는 binary_crossentropy를 손실 함수로 사용하고, Adam 옵티마이저를 사용하며, acc를 평가 지표로 설정합니다.
model.fit은 모델을 학습시키는 함수입니다. x_train과 y_train은 학습 데이터로 사용되며, validation_data에는 검증 데이터인 x_val과 y_val을 설정합니다. 학습은 주어진 epochs 횟수만큼 반복됩니다.
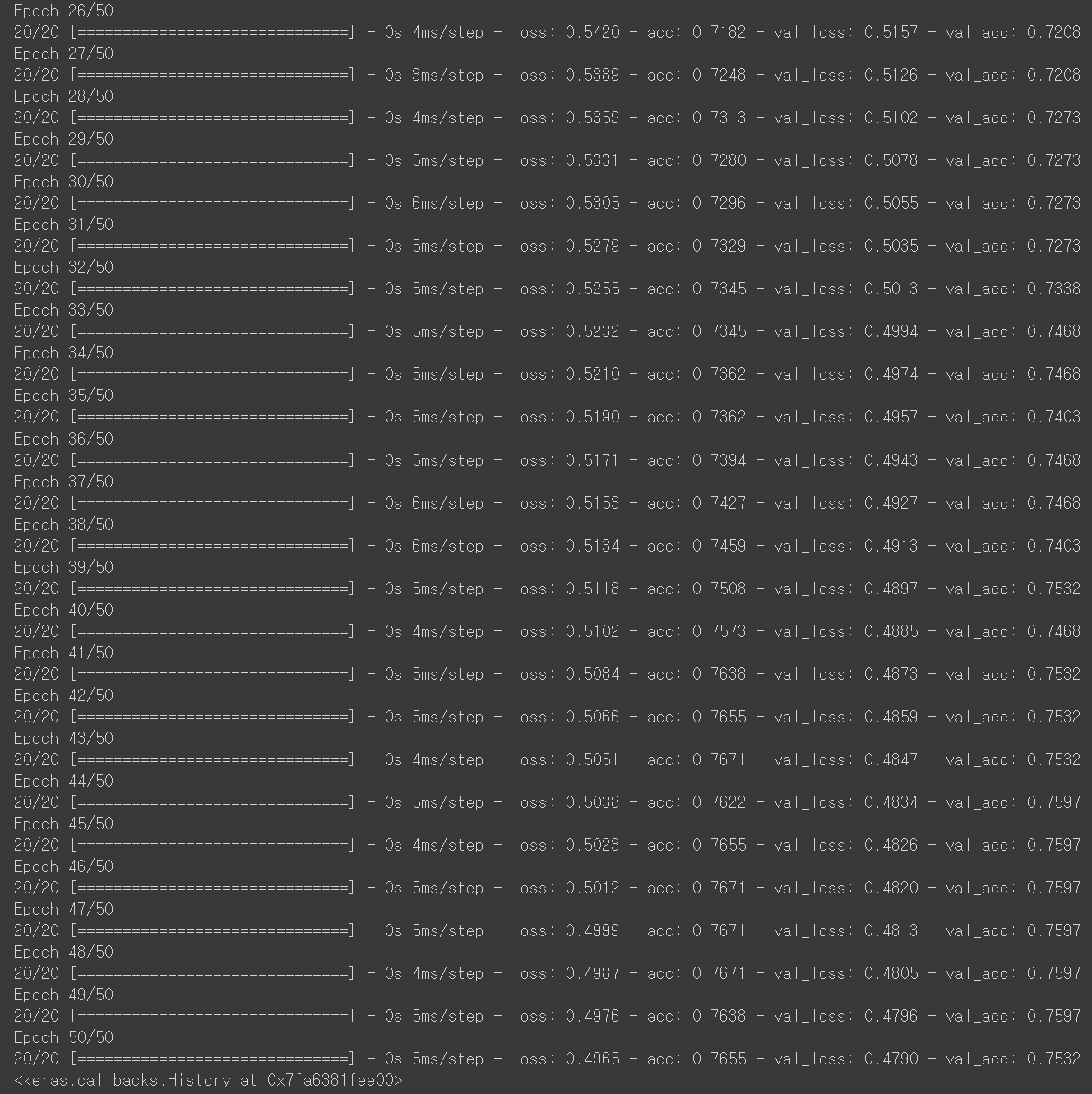
위 사진은 데이터 학습 코드를 적용해서 나온 결과물입니다.
마지막에 이르러서 정확도가 0.7 즉 70%의 정답률을 보여줬는데 epoch와 learnig rate를 조정하다보면 최적화 된 결과물을 만들 수 있지 않을까 생각합니다.
