[230201] 멋쟁이사자처럼 AI SCHOOL 8기 plotly를 활용한 일별 주가 시각화_박조은강사님' 복습
멋사 AI SCHOOL 8기
📝Today I learned
🚀 TIL 목차 🚀
1) plotly란?
2) plotly 예제 따라하기
- 라이브러리 로드
- 일별 수익률 선그래프
- 일별 수익률 막대그래프
- facet_col를 이용해 서브플롯 그리기
- hover 표현하기
- range slider 표현하기
3) 금융 데이터에 적용하기 좋은 그래프
- Candlestick
- OHLC(Open-High-Low-Close)
4) 디즈니 데이터로 실습하기
- 데이터 불러오기
- 전일비 선그래프
- 히스토그램(marginal box)
5) 여러 종목 데이터로 실습하기
- areaplot
- scatterplot
- scatterplot matrix
- box
- violin
- strip
- 4분위수
plotly를 활용한 일별 주가 시각화
1) plotly란?
🔹 plotly
-
파이썬의 대표적인 인터렉티브 시각화 도구
-
한글 폰트를 따로 지정하지 않아도 됨
-
high-level interface : 사람이 이용하기 쉬움
2) plotly 예제 따라하기
🔹 라이브러리 로드
# plotly 설치하기
!pip install plotly --upgradeimport plotly
import plotly.express as px🤔 plotly는 라이브러리인데 plotly express는 뭔가요?
👉 The plotly.express module (usually imported as px) contains functions that can create entire figures at once, and is referred to as Plotly Express or PX.
(출처 : Plotly Express in Python)
🔹 일별 수익률 선그래프
# px에서 내장하고 있는 data.stocks 데이터 불러오기
# 2018-01-01을 기준으로 수익률의 증가감소 데이터
df = px.data.stocks()
df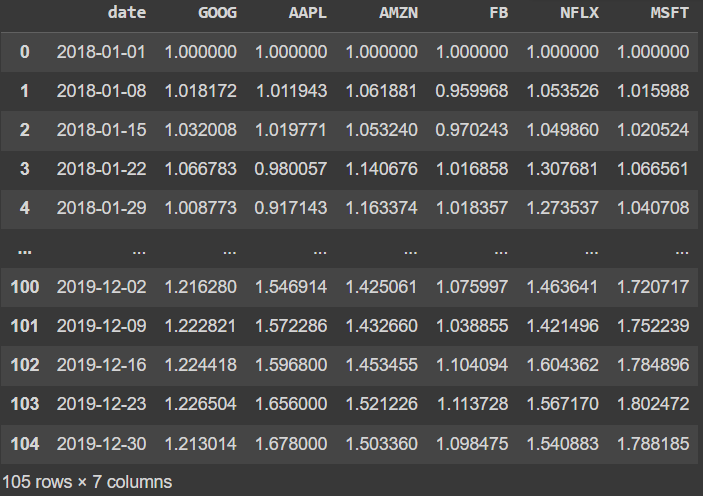
# px.line으로 구글 주가 선 그래프 그리기
px.line(df, x='date', y='GOOG', height=300, width=600)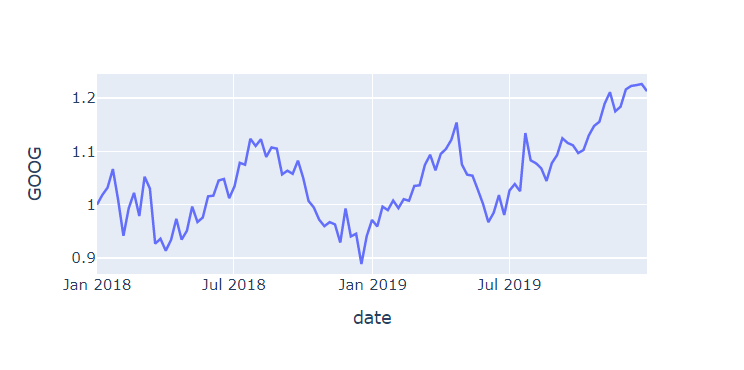
🔹 일별 수익률 막대그래프
# 시작 기준일 수익률을 0으로 만들기
df_1 = df.set_index("date") - 1
df_1.head()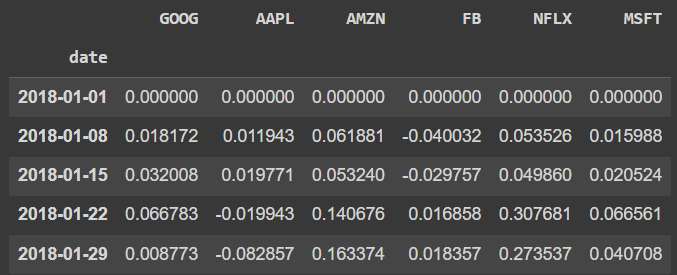
# Pandas API와 비교해보기
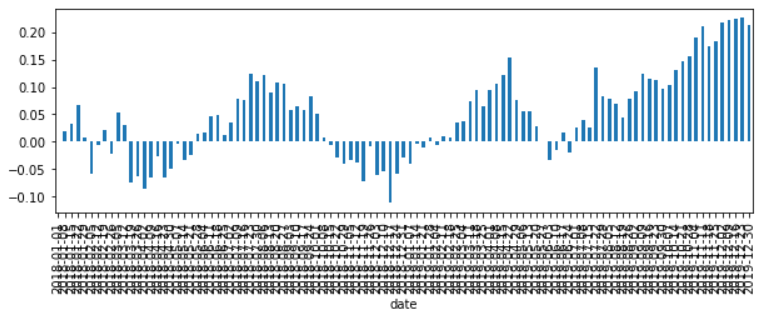
df_1["GOOG"].plot.bar(figsize=(10, 3));👉 Pandas API는 x축의 텍스트가 겹쳐져 알아보기 어려움.
# plotly express API
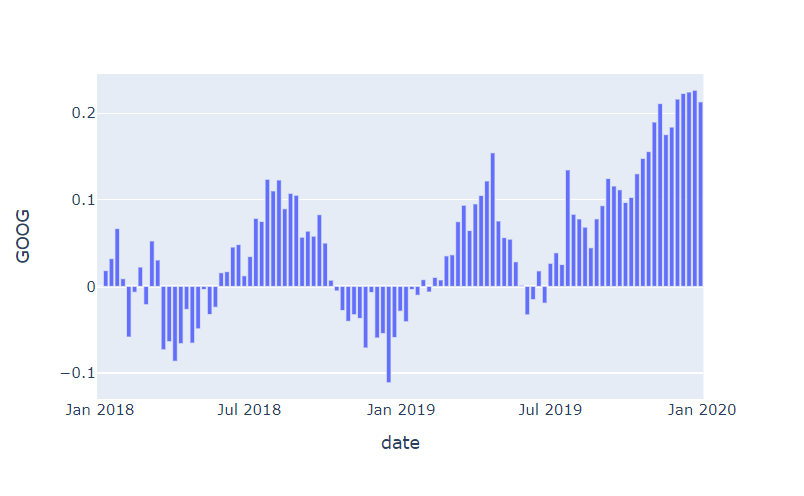
px.bar(df_1, x=df_1.index, y="GOOG", height=400)👉 x축의 모든 텍스트가 표현되지 않아 비교적 깔끔.
🔹 facet_col를 이용해 서브플롯 그리기
- 서브플롯 : 여러 개의 그래프를 하나의 figure에 모아 그리는 것이 아니라 그래프 하나당 figure 하나씩 나눠서 그리는 것
# plotly에서 facet_col을 이용해 서브플롯을 그리려면 column의 name이 꼭 있어야 한다.
# df_1.columns 의 name을 "company"로 지정하기
df_1.columns.name = "company"
df_1.columns
# facet_col을 통해 서브플롯 그리기
# px.area 활용
px.area(df_1, facet_col="company", facet_col_wrap=2, width=800)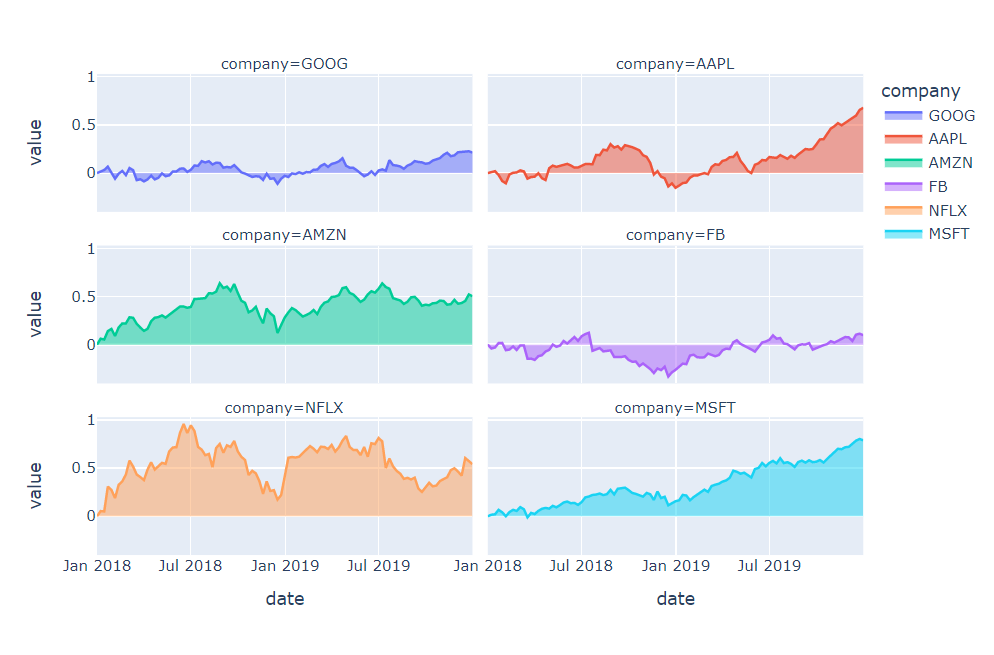
🔹 hover 표현하기
# hover_data={"date": "|%Y-%m-%d"}
# hover에 뜨는 시간 텍스트를 원하는 형식으로 표현
px.line(df, x="date", y="GOOG", hover_data={"date": "|%Y-%m-%d"})🤔 날짜 형식에서 '|' 표시는 왜 하는 건가요?
👉 그냥 plotly에서 만든 규칙이다!
🔹 range slider 표현하기
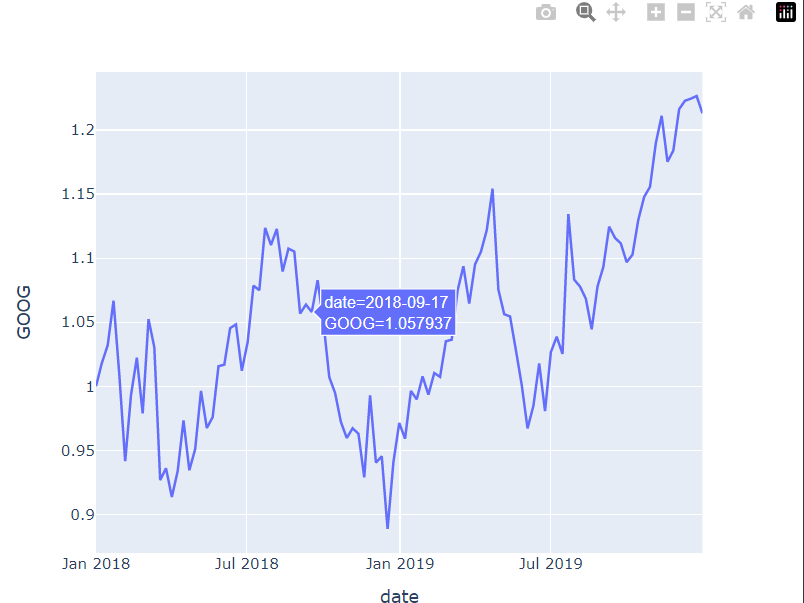
# range slider를 통해 그래프가 보여지는 범위를 조절하여 그래프를 자세히 볼 수 있음
# rrangeslider_visible=False를 하면 range slider를 안 보이게 할 수 있음
fig = px.line(df_1["GOOG"], title= "구글 주가")
fig.update_xaxes(rangeslider_visible=True)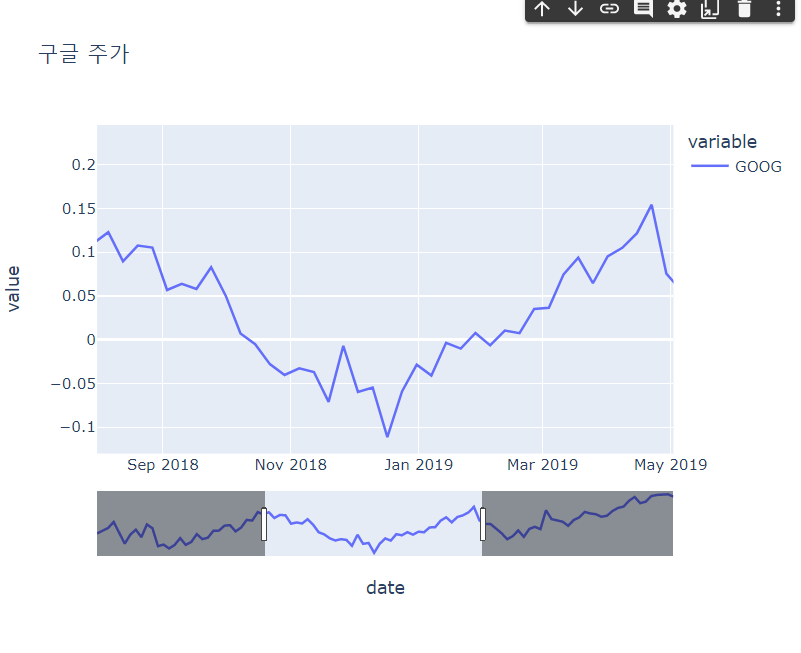
3) 금융 데이터에 적용하기 좋은 그래프
🔹 Candlestick
: 주식 상장 종목의 시작가, 최고가, 최저가, 종가를 표현한 금융 차트
: 박스의 위아래 끝은 시작가와 종가를, 선의 위아래 끝은 최고가와 최저가를 나타냄.
: 시작가보다 종가가 높은 상승마감이면 초록색, 그 반대의 상황이면 빨간색
(반대로 한국은 상승이면 빨간색, 하락이면 파란색)
# 라이브러리 로드
import pandas as pd
import plotly.graph_objects as go
from datetime import datetime
# 애플의 주가정보 불러오기
df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/finance-charts-apple.csv')
df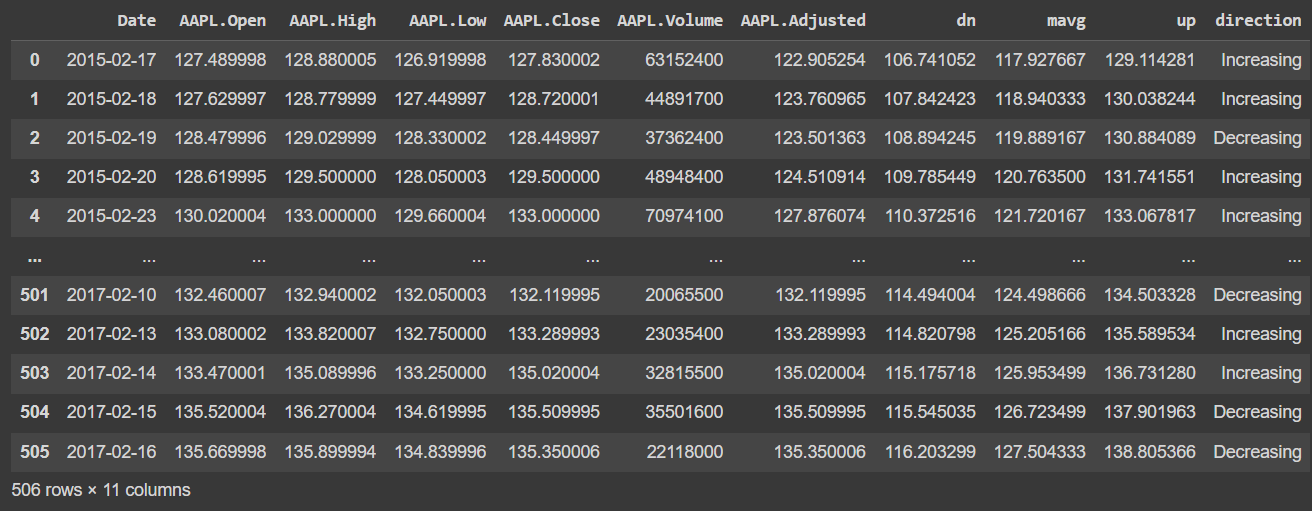
# 캔들스틱 차트에는 기본적으로 range_slider가 포함되어 있음
fig = go.Figure(data=[go.Candlestick(x=df['Date'],
open=df['AAPL.Open'],
high=df['AAPL.High'],
low=df['AAPL.Low'],
close=df['AAPL.Close'])])
fig.show()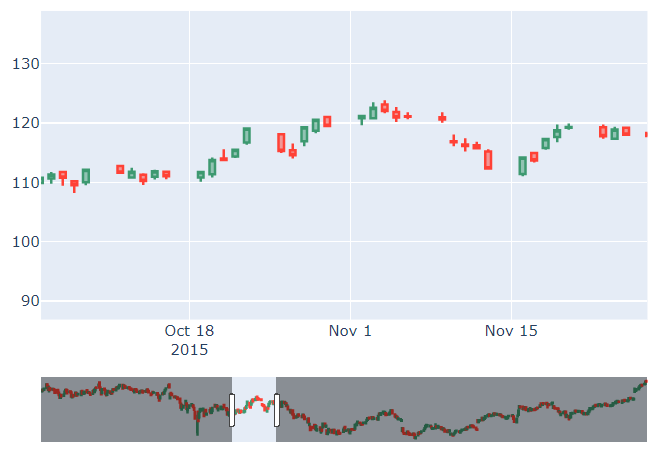
🔹 OHLC(Open-High-Low-Close)
: 주식 상장 종목의 시작가, 최고가, 최저가, 종가를 표현한 금융 차트
: 선의 위아래 끝점이 최고가와 최저가를, 선의 좌우로 튀어나온 막대가 시작가와 종가를 나타냄
: 시작가보다 종가가 높은 상승마감이면 초록색, 그 반대의 상황이면 빨간색
# OHLC 그래프에도 기본적으로 range slider가 내장되어 있음
fig = go.Figure(data=[go.Ohlc(x=df['Date'],
open=df['AAPL.Open'],
high=df['AAPL.High'],
low=df['AAPL.Low'],
close=df['AAPL.Close'])])
fig.show()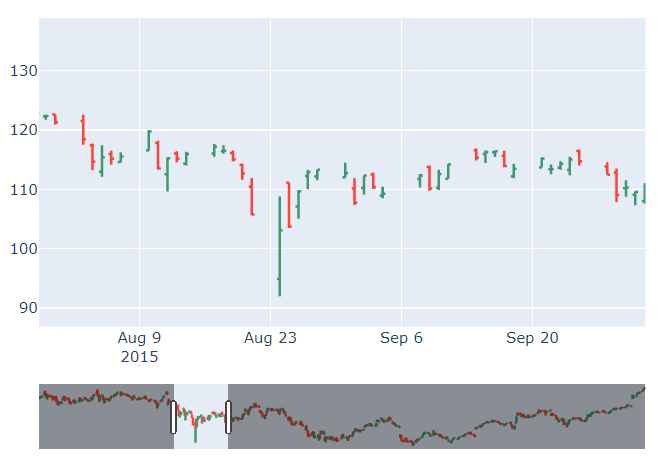
💡 range slider를 표현하고 싶지 않다면?
# fig.show() 전에 아래의 코드를 추가하면 range slider가 나타나지 않음
fig.update_xaxes(rangeslider_visible=False)4) 디즈니 데이터로 실습하기
🔹 데이터 불러오기
# FinanceDataReader 설치하기
!pip install -U finance-datareader# fdr 라이브러리 불러오기
import FinanceDataReader as fdr
# 원하는 종목(나는 디즈니!)의 2022년 이후 주가정보 불러오기
dis = fdr.DataReader("DIS", start="2022")
dis.tail()
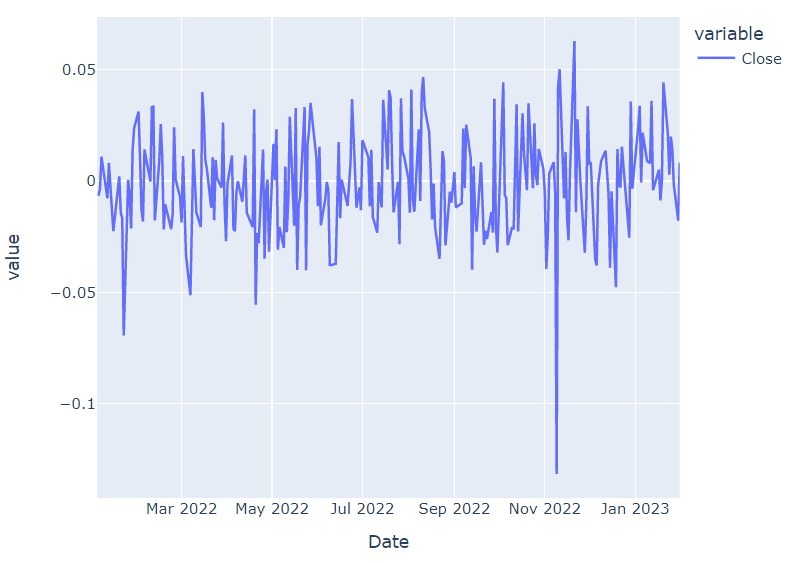
🔹 전일비 선그래프
💡 전일비 : 전일 종가를 기준으로 최종가격의 상승 및 하락 비율
# 전일비를 나타내는 매서드는 pct_change()
diff = dis["Close"].pct_change()
px.line(diff)22년 11월쯤... 디즈니는 추운 겨울을 보냈구나..
🔹 히스토그램(marginal box)
# 전일비에 대한 히스토그램
# marginal="box"를 추가하면 box plot을 여백에 그릴 수 있음
px.histogram(diff, marginal="box")
5) 여러 종목 데이터로 실습하기
🔹 데이터 준비하기
MYLIST = ["DIS", "AAPL", "SBUX"]
# fdr로 "DIS", "AAPL", "SBUX" 주가 데이터 리스트로 가져오기
my_list = [fdr.DataReader(ticker, "2022")["Close"] for ticker in MYLIST]
# pd.concat으로 "DIS", "AAPL", "SBUX" 주가 데이터 병합하기
df_ml = pd.concat(my_list, axis=1)
df_ml.columns = MYLIST
# 일별 수익률 구하기
df_ratio = (df_ml / df_ml.iloc[0]) -1
# 서브플롯을 그리기 위해 columns.name 설정하기
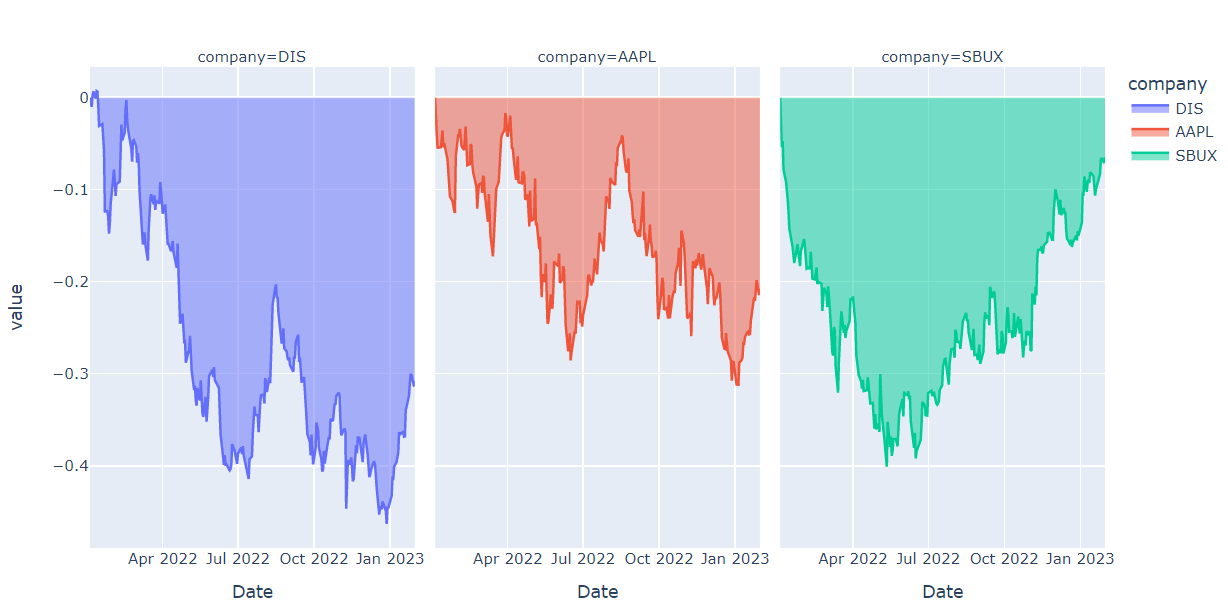
df_ratio.columns.name = "company"🔹 areaplot
# px.area
px.area(df_ratio, facet_col="company", facet_col_wrap=3, width=1000)그래프가 흘러내리는데.. 이게 맞나요 ㅠㅠ?
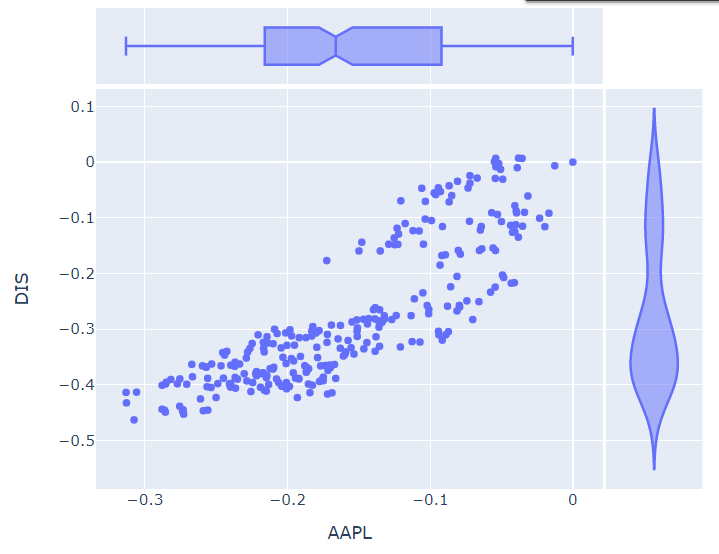
🔹 scatterplot
# px.scatter
# 애플과 디즈니의 일별 수익률 상관관계 파악하기
px.scatter(df_ratio, x="AAPL", y="DIS", marginal_x="box", marginal_y="violin")애플과 디즈니 사이 수익률이 양의 상관관계를 가지는 것처럼 보임!
🔹 scatterplot matrix
# px.scatter_matrix
px.scatter_matrix(df_ratio)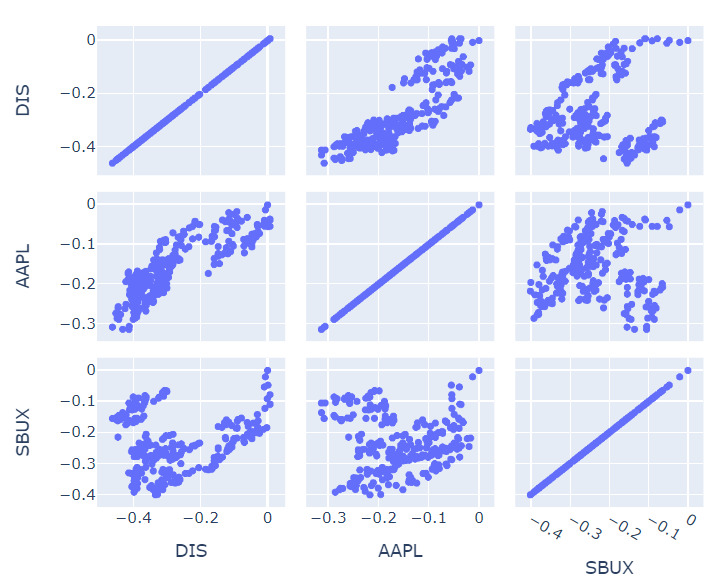
🔹 box
: 주로 4분위수(기술통계값)를 보기 위해 사용함
: 기술통계값만 보여줄 수 있다는 한계가 있음.
: 개별 데이터가 달라도 기술통계값이 달라지지 않는 경우 boxplot으로는 개별 데이터의 변화를 표현하지 못함.
# px.box
# 디즈니가 가장 낮은 수익률을 기록. 수익률의 분포가 다른 두 종목보다 넓게 퍼져있기도 함. (맘고생..)
px.box(df_ratio, height=300)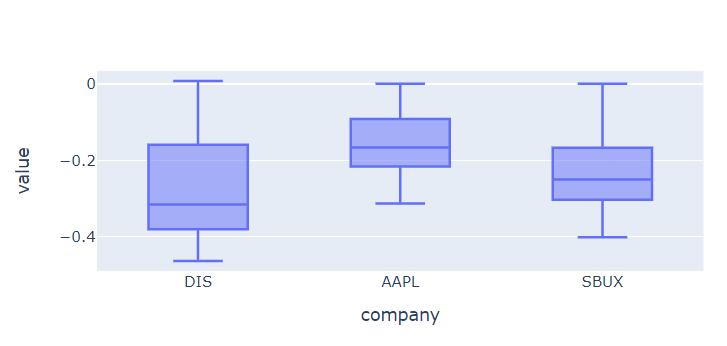
💡 그래프 위에 마우스를 갖다대면 hover에 4분위수를 포함한 기본적인 기술통계량이 나타남
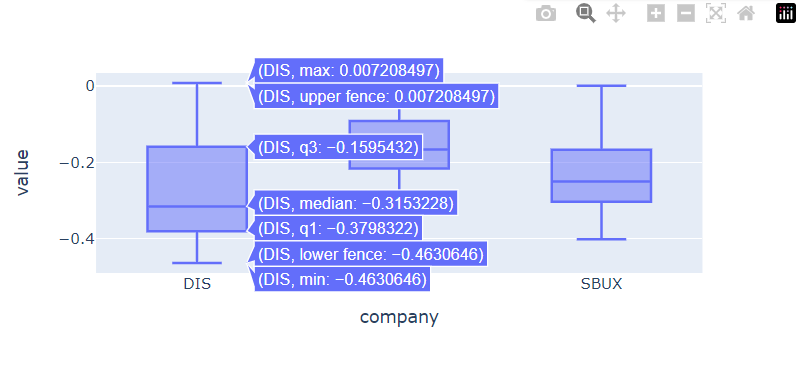
🔹 violin
: 히스토그램의 밀도 추정하여 부드러운 곡선으로 표현함.
: box plot의 한계를 극복하기 위해 만들어짐.
: 4분위수가 변하지 않더라도 데이터의 변화를 나타낼 수 있음.
# px.violin
# 애플과 스벅은 중간 수익률이었던 적이 대체로 많은데, 디즈니는 유독 낮은 수익률이었던 적이 많았나봄. (ㅠㅠ)
px.violin(df_ratio, height=300)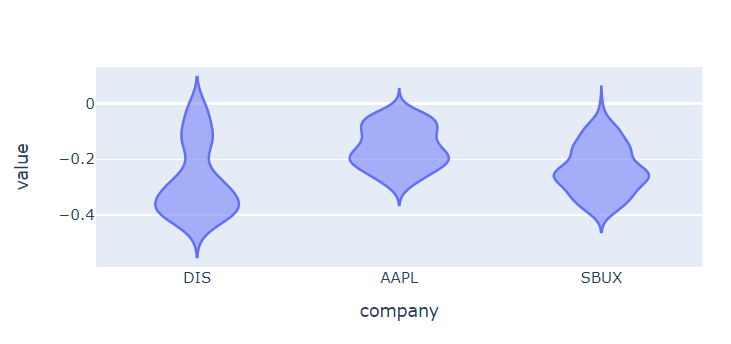
💡 violin과 box를 둘 다 나타내고 싶을 때
px.violin(df_ratio, height=300, box=True, points="all")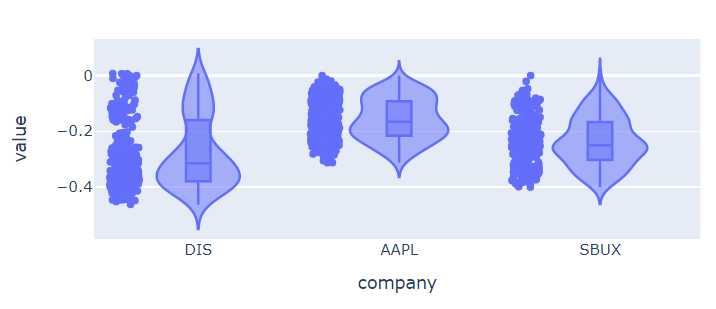
🔹 strip
# px.strip
# 애플은 확실히 안정적인 모습. 스벅은 수익률이 갑자기 높았던 적이 있었나봄.
px.strip(df_ratio, height=300)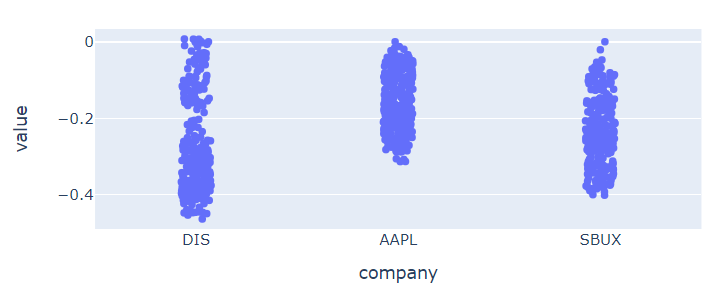
🔹 4분위수
# 판다스에서 4분위 수 보는 법
# df_ratio.quantile()
df_ratio.quantile(q=0.25)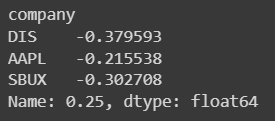
❗이것만은 외우고 자자 Top 3
📌 plotly에서 facet_col을 이용해 서브플롯을 그리려면 반드시 column의 name이 있어야 한다.
df.columns.name = "company"
px.area(df, facet_col="company", facet_col_wrap=2)📌 전일비를 나타내는 매서드는 pct_change()
📌 plotly는 figsize가 아니라 width, height로 사이즈 조절!
🌟데일리 피드백
1. 오늘의 칭찬&반성
수업시간에 흥미를 느낀 것. 힘들긴 하지만 즐기고 있다. 어려운 내용일수록 도전정신이 불타오른다. AI SCHOOL을 하면서 나는 '이런 사람이구나'를 자주 느끼는 것 같다.
매일 회고를 하고 정리를 하는 것에 비해 연습을 충분히 하지 않는 것. 인스타 볼 시간에 코드 한줄이라도 더 적자!
2. 내가 부족한 부분
시각화 라이브러리 별로 파라미터가 뒤죽박죽 헷갈린다. 많이 사용하면서 익혀야겠다. 정리만 하지말고 실제로 써보자!
3. 내일의 목표
미니플젝 코드 정리 및 결과물 노션에 옮기기
