[wanted] NoSQL의 Normalized Data Model
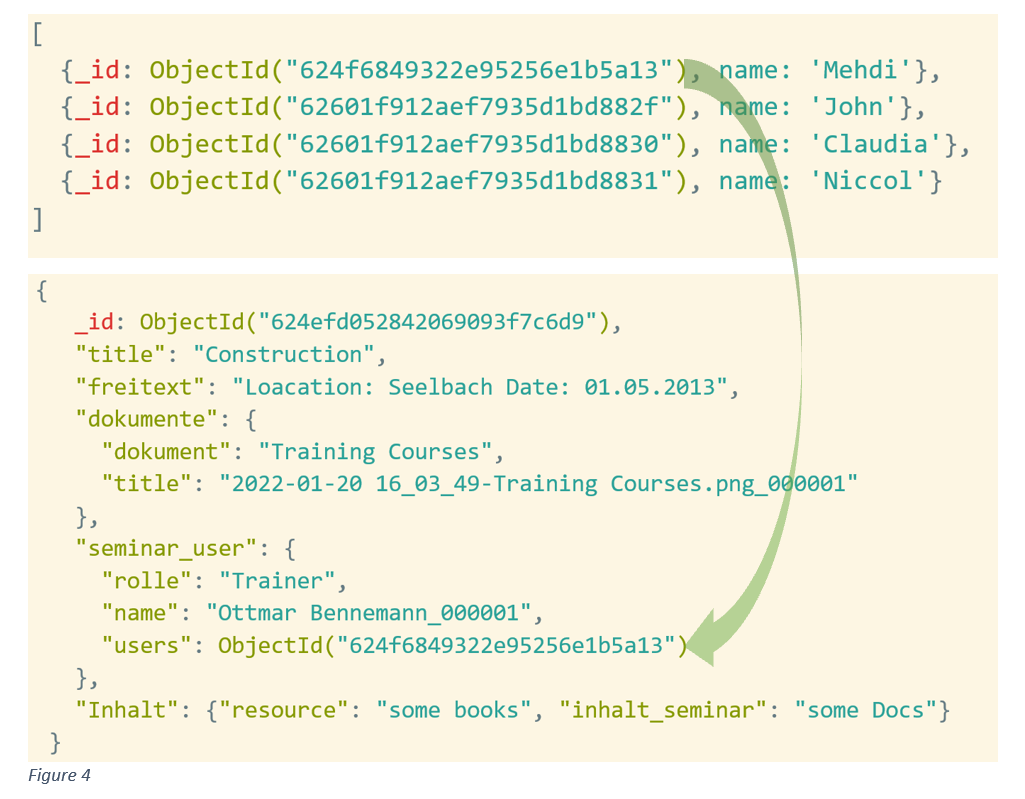
팀원과 회의 중 NoSQL과 RDBMS의 선택 과정에 있어서, 내가 사용했던 기술이 무엇인지 되짚어보았다. 이전 프로젝트에서는 유저의 팔로잉기능을 제작하면서, 이런 테이블을 구성해서 만든 적이 있다.
@Document(collection = "follows")
data class Follow(
@Id val id: String? = null,
@field:NotBlank(message = "비워둘 수 없습니다.")
val follower: String,
@field:NotBlank(message = "비워둘 수 없습니다.")
val following: String,
)이런 전략을 그냥 모르고 개발했는데, 이것을 NoSQL의 "Normalized Data Model"이라고 부른다고 한다. 한국말로 풀이하면, 정규화 데이터 모델이다.
RDBMS (NestJS with TypeORM):
RDBMS에서는 테이블을 분리하여 중복을 최소화하고 무결성을 유지한다. 아래는 Normalized 사례이다. 사실 관계형 데이터베이스에서는 이 모델링이 주를 이루는 것 같다.
- Normalized Data Model
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number;
@Column()
nickname: string;
// other fields...
}
@Entity()
export class Follow {
@PrimaryGeneratedColumn()
id: number;
@ManyToOne(() => User, user => user.following)
follower: User;
@ManyToOne(() => User, user => user.followers)
following: User;
}반면 Denormalized Data Model은 단일 테이블에 모든 데이터를 저장하여 쿼리의 복잡성을 줄인다.
- Denormalized Data Model
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number;
@Column()
nickname: string;
@Column("simple-array")
following: number[];
@Column("simple-array")
followers: number[];
// other fields...
}NoSQL (NestJS with Mongoose)
- Normalized Data Model
@Schema()
export class User extends Document {
@Prop()
nickname: string;
// other fields...
}
export const UserSchema = SchemaFactory.createForClass(User);
@Schema()
export class Follow extends Document {
@Prop({ type: Types.ObjectId, ref: 'User' })
follower: Types.ObjectId;
@Prop({ type: Types.ObjectId, ref: 'User' })
following: Types.ObjectId;
}
export const FollowSchema = SchemaFactory.createForClass(Follow);- Denormalized Data Model
import { Prop, Schema, SchemaFactory } from '@nestjs/mongoose';
import { Document, Types } from 'mongoose';
@Schema()
export class User extends Document {
@Prop()
nickname: string;
@Prop([{ type: Types.ObjectId, ref: 'User' }])
following: Types.ObjectId[];
@Prop([{ type: Types.ObjectId, ref: 'User' }])
followers: Types.ObjectId[];
// other fields...
}
export const UserSchema = SchemaFactory.createForClass(User);역으로 Nosql에서는 비정규화 데이터 모델이 주를 이루는 것 같다. 아마 이전프로젝트에서는 팔로우 취소와 팔로우 기능이 빠르게 동작해야했기 때문에, 정규화를 통해 속도향상을 기대하는게 맞았던 것 같다.
NoSQL 데이터베이스에서 정규화(Normalization)와 비정규화(Denormalization)
NoSQL 데이터베이스에서의 데이터 구조와 성능에 영향을 미치는 중요한 개념인 정규화와 비정규화에 대해 알아보겠습니다.
정규화 (Normalization)
정의:
정규화는 데이터를 여러 컬렉션에 나누어 저장하고, 이들 사이의 참조를 통해 데이터를 정의하는 방식입니다 (blog.usu.com).
장점:
- 데이터의 중복을 방지하며, 데이터 무결성과 일관성을 유지할 수 있습니다 (tutorialspoint).
- 데이터 업데이트가 쉽습니다 (blog.usu.com).
단점:
- 데이터를 읽으려면 여러 컬렉션에서 여러 쿼리를 수행해야 하므로 읽기 프로세스가 느려질 수 있습니다 (blog.usu.com).
비정규화 (Denormalization)
정의:
비정규화는 하나의 문서에 대량의 중첩 데이터를 저장하는 방식으로, 이 모델은 읽기 작업을 더 빠르게 수행하지만 삽입 및 업데이트 작업은 느리게 만듭니다 (blog.usu.com).
장점:
- 한 번의 쿼리로 모든 관련 정보를 검색할 수 있습니다.
- 응용 프로그램 코드에서 조인을 구현하거나 populate/lookup (Join)을 사용할 필요가 없습니다.
- 관련 정보를 단일 원자 작업으로 업데이트할 수 있습니다 (blog.usu.com).
단점:
- 문서 기반 데이터베이스에는 문서 크기 제한이 있으며, 예를 들어 MongoDB는 단일 문서 항목에 대한 16MB의 제한을 가집니다. 또한 서브 문서의 임베딩 수준도 고려해야 하는 이슈입니다 (blog.usu.com).
NoSQL에서는 비정규화 방식이 일반적으로 선호되며, 이는 읽기 작업의 성능을 향상시키고 단일 쿼리로 더 많은 데이터를 빠르게 가져오기 때문입니다 (TechTarget)(tutorialspoint). 그러나 정규화된 모델은 데이터의 무결성과 일관성을 유지하는 데 더 유리하며, 특히 데이터를 업데이트하거나 수정할 때 유용할 수 있습니다 (blog.usu.com).
출처
