
Ⅰ. AWS RDS
1. Database 생성 및 접근 가능한 사용자 계정 만들기
- Database Name : oneday
- User Name / Password : oneday / 1234
import mysql.connector
conn = mysql.connector.connect(
host = "__호스트 주소__",
port = 3306,
user = "admin",
password = "__비밀번호__",
)
cursor = conn.cursor(buffered = True)
sql = "create database oneday"
cursor.execute(sql)
cursor.execute("create user 'oneday'@'%' identified by '1234'")
cursor.execute("grant all on oneday.* to 'oneday'@'%'")- Database 생성문 조회 결과
sql_result1 = "show create database oneday"
cursor.execute(sql_result1)
result = cursor.fetchall()
for i in result:
print(i)
- 사용자 권한 확인 결과
sql_result2 = "show grants for 'oneday'@'%'"
cursor.execute(sql_result2)
result = cursor.fetchall()
for i in result:
print(i)
2. 스타벅스 이디야 데이터를 저장할 테이블 생성
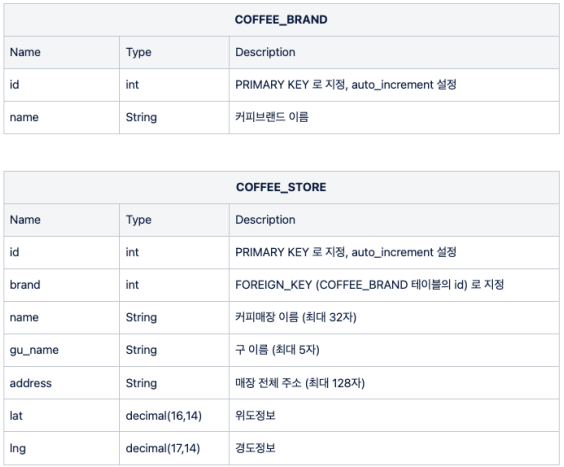
cursor.execute("use oneday")
# COFFEE_BRAND Table
sql1 = "create table COFFEE_BRAND(id int not null auto_increment primary key, name varchar(12))"
cursor.execute(sql1)
# COFFEE_STORE Table
sql2 = "create table COFFEE_STORE(id int not null auto_increment primary key, brand int, name varchar(32) not null, gu_name varchar(5) not null, address varchar(128) not null, lat decimal(16,14) not null, lng decimal(17,14) not null, foreign key (brand) references COFFEE_BRAND(id))"
cursor.execute(sql2)
conn.close()- Table 생성 결과 - COFFEE_BRAND
sql_result3 = "desc COFFEE_BRAND"
cursor.execute(sql_result3)
result = cursor.fetchall()
for i in result:
print(i)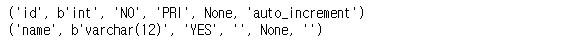
- Table 생성 결과 - COFFEE_STORE
sql_result4 = "desc COFFEE_STORE"
cursor.execute(sql_result4)
result = cursor.fetchall()
for i in result:
print(i)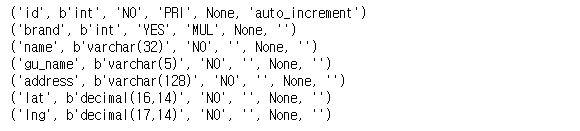
3. Python 코드로 COFFEE_BRAND 데이터 입력
conn = mysql.connector.connect(
host = "__호스트 주소__",
port = 3306,
user = "oneday",
password = "1234",
database = "oneday"
)
cursor = conn.cursor(buffered = True)
cursor.execute("insert into COFFEE_BRAND values (1, 'STARBUCKS'), (2, 'EDIYA')")
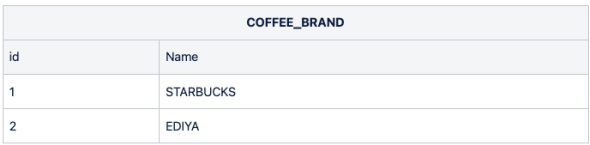
conn.commit()- COFFEE_BRAND 조회 결과
sql_result5 = "select * from COFFEE_BRAND"
cursor.execute(sql_result5)
result = cursor.fetchall()
for i in result:
print(i)
conn.close()
Ⅱ. 스타벅스 데이터 수집
1. 데이터 수집
- Requirements
import pandas as pd
import numpy as np
import time
import warnings
from selenium import webdriver
from urllib.request import urlopen, Request
from bs4 import BeautifulSoup
from tqdm import tqdm_notebook
warnings.simplefilter(action = 'ignore')- 페이지 접근
url = "https://www.starbucks.co.kr/store/store_map.do"
driver = webdriver.Chrome('../driver/chromedriver.exe')
driver.get(url)- 팝업창 닫기 (예외 처리)
from selenium.common.exceptions import NoSuchElementException
try:
driver.find_element_by_css_selector('.holiday_notice_close a').click()
except NoSuchElementException as e:
print(e)
- 데이터 수집
# 지역 검색 클릭
xpath_1 ='//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/header[2]/h3/a'
some_tag_1 = driver.find_element_by_xpath(xpath_1)
some_tag_1.click()
time.sleep(1)
# 지역 → 시도 → 서울 클릭
xpath_2 = '//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/article[2]/div[1]/div[2]/ul/li[1]/a'
some_tag_2 = driver.find_element_by_xpath(xpath_2)
some_tag_2.click()
time.sleep(1)
# 지역 → 시도 정보 → 서울 → 서울 전체 클릭
xpath_3 = '//*[@id="mCSB_2_container"]/ul/li[1]/a'
some_tag_3 = driver.find_element_by_xpath(xpath_3)
some_tag_3.click()
# BeautifulSoup
req_starbucks = driver.page_source
soup_starbucks = BeautifulSoup(req_starbucks, "html.parser")
2. 전체 데이터 수집
- 가져온 스타벅스 데이터를 AWS RDS(SQL) COFFEE_STORE에 바로 입력
conn = mysql.connector.connect(
host = "__호스트 주소__",
port = 3306,
user = "oneday",
password = "1234",
database = "oneday"
)
cursor = conn.cursor(buffered = True)
sql = "insert into COFFEE_STORE (brand, name, gu_name, address, lat, lng) values (1, %s, %s, %s, %s, %s)"
for content in tqdm_notebook(seoul_list):
name = content['data-name']
address = content.select_one('p').text[:-9]
lat = content['data-lat']
lng = content['data-long']
gu_name = address.split()[1]
cursor.execute(sql, (name, gu_name, address, lat, lng))
conn.commit()
driver.close()- 입력된 데이터 상위 10개 확인
sql_result7 = "select * from COFFEE_STORE limit 10"
cursor.execute(sql_result7)
result = cursor.fetchall()
for i in result:
print(i)
conn.close()Ⅲ. 이디야 데이터 수집
1. 데이터 수집
- 페이지 접근
url_ediya = 'https://www.ediya.com/contents/find_store.html'
driver = webdriver.Chrome('../driver/chromedriver.exe')
driver.get(url_ediya)- 주소 검색 탭 선택
xpath_4 ='//*[@id="contentWrap"]/div[3]/div/div[1]/ul/li[2]/a'
some_tag_4 = driver.find_element_by_xpath(xpath_4)
some_tag_4.click()- 구 이름: COFFEE_STORE에서 중복을 제거하는 쿼리를 사용하여 가져와서 {'서울 ' + 구이름} 형식으로 변환하여 사용
conn = mysql.connector.connect(
host = "database-1.cf6hkx6hb0r2.ap-northeast-1.rds.amazonaws.com",
port = 3306,
user = "oneday",
password = "1234",
database = "oneday"
)
cursor = conn.cursor(buffered = True)
# 중복을 제거 쿼리 사용(distinct)
gu_list = []
cursor.execute("select distinct(gu_name) from COFFEE_STORE")
result = cursor.fetchall()
for row in result:
gu_list.append(str('서울 ') + row[0])- 구별 검색어 입력
search_keyword = driver.find_element_by_xpath('//*[@id="keyword"]')
search_keyword.clear()
search_keyword.send_keys(gu_list[2])- 검색버튼 클릭
search_button = driver.find_element_by_xpath('//*[@id="keyword_div"]/form/button')
search_button.click()- 서울시 구별 매장 데이터 - BeautifulSoup
req_ediya = driver.page_source
soup_ediya = BeautifulSoup(req_ediya, "html.parser")
contents = soup_ediya.select('#placesList li')
len(contents), contents[0]
2. 전체 데이터 수집
- 가져온 스타벅스 데이터를 AWS RDS(SQL) COFFEE_STORE에 바로 입력
import googlemaps
gmaps_key = '____________'
gmaps = googlemaps.Client(key = gmaps_key)
sql = "insert into COFFEE_STORE (brand, name, gu_name, address, lat, lng) values (2, %s, %s, %s, %s, %s)"
for gu in tqdm_notebook(gu_list):
try:
driver.find_element_by_xpath('//*[@id="keyword"]')
# 검색 초기화
driver.find_element_by_xpath('//*[@id="keyword"]').clear()
time.sleep(1)
# 검색어 입력
driver.find_element_by_xpath('//*[@id="keyword"]').send_keys(gu)
time.sleep(1)
# 검색버튼 클릭
driver.find_element_by_xpath('//*[@id="keyword_div"]/form/button').click()
time.sleep(1)
# 서울시 구별 매장 데이터 스크래핑 - BeautifulSoup을 이용해서 html로 읽기
req_ediya = driver.page_source
soup_ediya = BeautifulSoup(req_ediya, "html.parser")
ul = soup_ediya.find('ul', id = 'placesList')
dl = ul.find_all('dl')
for i in dl:
name = i.find('dt').text.strip()
address = i.find('dd').text.strip()
adrs_list = address.split()[0:4]
adrs = ' '.join(adrs_list)
gu_name = adrs.split(' ')[1]
lat = gmaps.geocode(adrs)[0].get("geometry")["location"]["lat"]
lng = gmaps.geocode(adrs)[0].get("geometry")["location"]["lng"]
cursor.execute(sql, (name, gu_name, adrs, lat, lng))
conn.commit()
except Exception as e:
print(e)
continue
driver.close()Ⅳ. 수집한 데이터 SQL 쿼리로 조회
1. 스타벅스 매장 주요 분포 지역
- 매장수가 많은 상위 5개 구이름, 매장 개수 출력
sql_result8 = "select s.gu_name, count(s.brand) from COFFEE_BRAND as b, COFFEE_STORE as s where b.id = s.brand and b.name='STARBUCKS' group by s.gu_name order by count(s.brand) desc limit 5"
cursor.execute(sql_result8)
result = cursor.fetchall()
for row in result:
print(row)
2. 이디야 매장 주요 분포 지역
- 매장수가 많은 상위 5개 구이름, 매장 개수 출력
sql_result10 = "select s.gu_name, count(s.brand) from COFFEE_BRAND as b, COFFEE_STORE as s where b.id = s.brand and b.name='EDIYA' group by s.gu_name order by count(s.brand) desc limit 5"
cursor.execute(sql_result10)
result = cursor.fetchall()
for row in result:
print(row)
3. 구별 브랜드 각각의 매장 개수 조회
- 구이름, 브랜드이름, 매장 개수 출력
스타벅스
# ('구', '스타벅스', '개수')
sql_result12 = "select gu_name, brand as STARBUCKS, count(brand) as count from COFFEE_STORE where brand = 1 group by gu_name"
cursor.execute(sql_result12)
result = cursor.fetchall()
for row in result:
print(row)
이디야
# ('구', '이디야', '개수')
sql_result13 = "select gu_name, brand, count(brand) as count from COFFEE_STORE where brand = 2 group by gu_name"
cursor.execute(sql_result13)
result = cursor.fetchall()
for row in result:
print(row)
Ⅴ. CSV 파일로 저장
sql_result14 = "select * " + \
"from (select s.id as s_id, b.name as s_brand, s.name as s_name, s.gu_name as s_gu, s.address as s_address, s.lat as s_lat, s.lng as s_lng " + \
"from COFFEE_STORE as s, COFFEE_BRAND as b " + \
"where b.id = s.brand and b.name like 'STARBUCKS') as st, " + \
"(select s.id as e_id, b.name as e_brand, s.name as e_name, s.gu_name as e_gu, s.address as e_address, s.lat as e_lat, s.lng as e_lng " + \
"from COFFEE_STORE as s, COFFEE_BRAND as b " + \
"where b.id = s.brand and b.name like 'EDIYA') as ed " + \
"order by st.s_id, ed.e_id"
cursor.execute(sql_result14)
result = cursor.fetchall()
num_fields = len(cursor.description)
field_names = [i[0] for i in cursor.description]
df = pd.DataFrame(result)
df.columns = field_names
df.to_csv('../data/SQL1_starbucks_ediya_data.csv', index = False, encoding = "euc-kr")
conn.close()- 저장한 csv 파일 확인
cafe = pd.read_csv('../data/SQL1_starbucks_ediya_data.csv', encoding = "euc-kr")
cafe.head()
cafe.tail()

Date Scientist & Data Analyst