![]()
2014년에 발표된 SPPnet을 정리!
혹시나 틀린 부분이 있다면 댓글로 알려주시면 감사하겠습니다 :)
기존 R-CNN의 문제점
- 2000개의 region proposal된 이미지 모두에 대해서 순차적으로 CNN연산을 적용하기 때문에 학습이나 테스트시에 시간이 굉장히 많이 소요된다.

- AlexNet의 입력 size인 224X224 size로 변화시키기 위해 사용하는 crop, warp에서 이미지의 변형이 발생하고 이는 performance에 좋지 않은 영향을 미친다.
(CNN의 convolution연산은 sliding window 방식이기 때문에 어떤 크기의 input이 들어와도 가변적인 output을 산출할 수 있는 유연한 구조이지만, 뒤의 fc layer가 고정된 입력을 필요로하기 때문에 CNN또한 input image를 crop, warp를 통한 고정적 사이즈로 변환한다.)
개선 방안
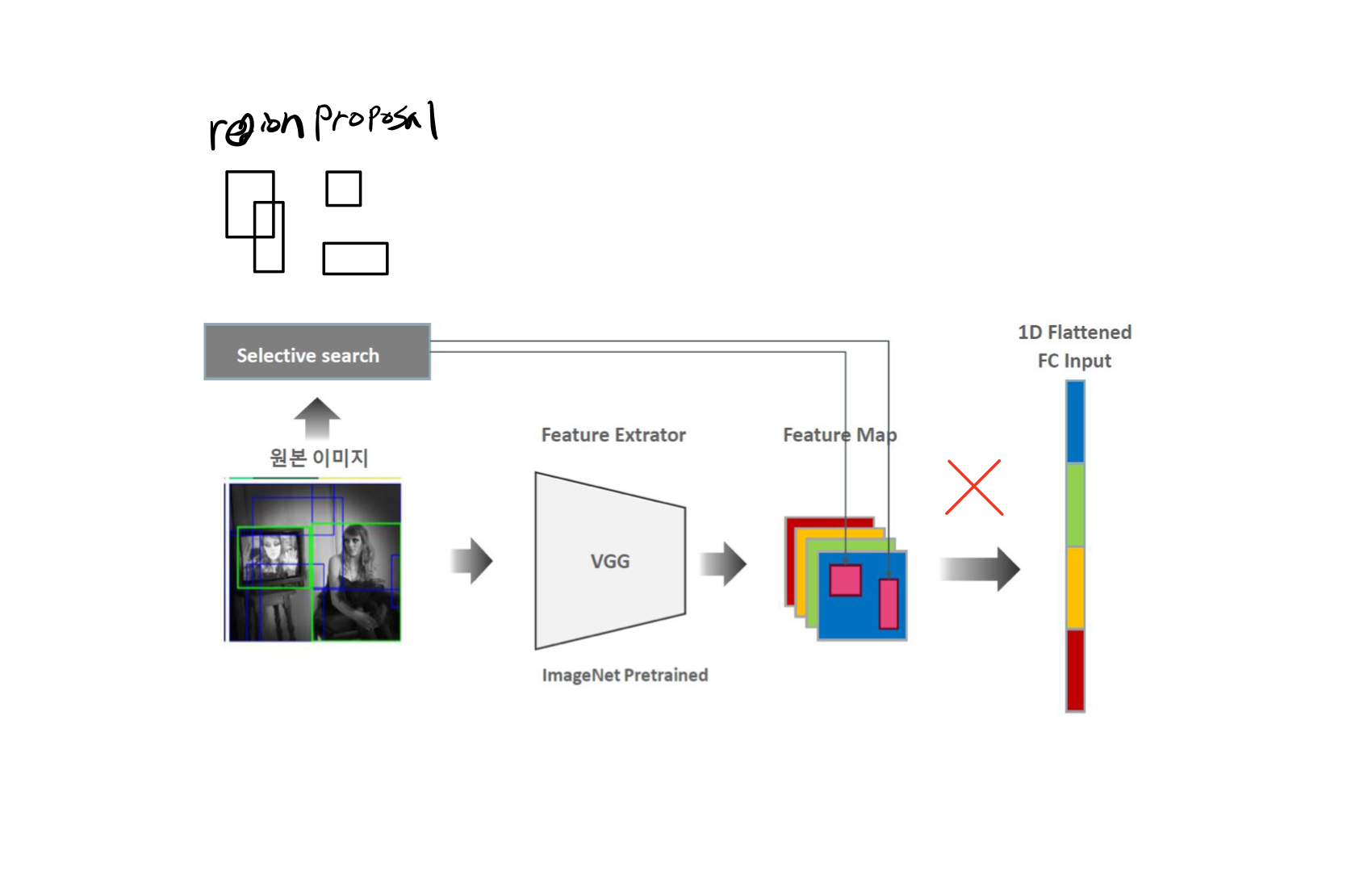
원본 이미지에서 selective search를 적용하고 얻은 region proposal을 원본 이미지에 feature Extractor를 거친 결과인 feature map에 대응시키고자 했다. 이러한 방법으로 R-cnn의 crop, warp에서 생기는 이미지 변형을 해결하고 훈련 등에 걸리는 시간을 단축할 수 있다.
하지만 feature map의 사이즈가 결부된 region proposal의 크기마다 모두 달라지는 문제가 발생하고, 결과적으로 고정된 이미지 크기를 받아야하는 FC layer의 input이 될 수 없다.
그래서 이 문제를 해결하기 위해 SPP(SPP(Spatial Pyramid Pooling) Net)가 나온다!
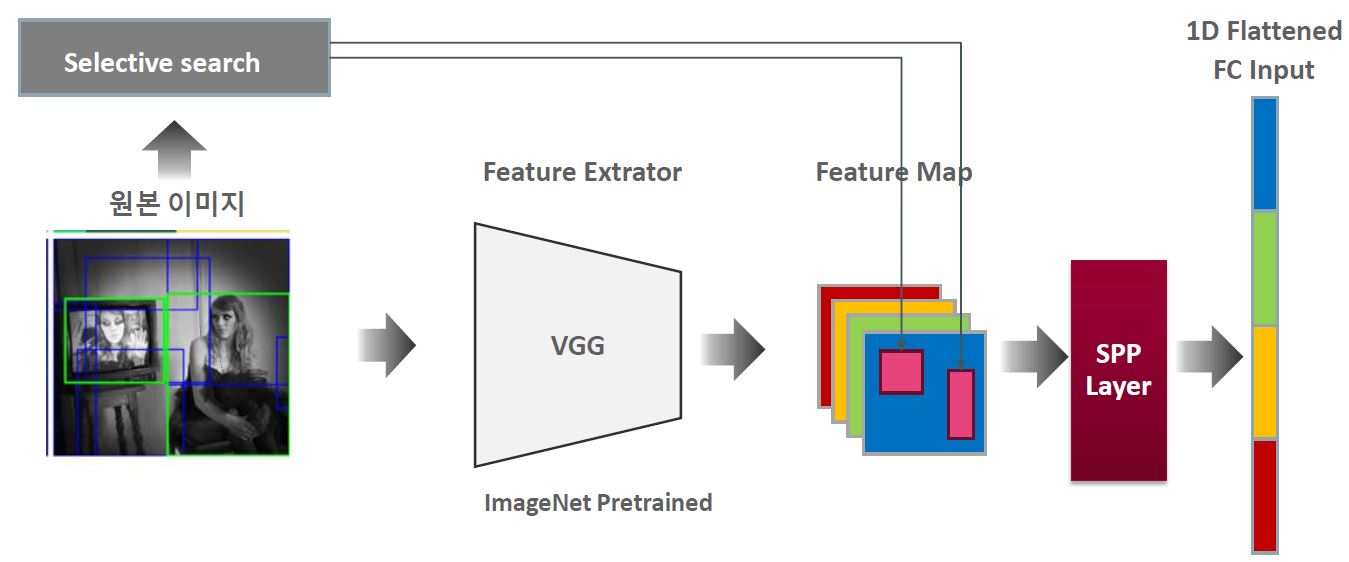

다른 size의 feature map들을 SPP라는 pooling layer에 통과 시켜서 고정된 size의 벡터로 변환하는 것이다.
이렇게 되면 어떤 size의 input image/feature map이 들어와도 FC-layer의 input이 될 수 있다.
SPP의 원리
SPP는 bovw가 공간정보를 잃는 것을 방지하기 위하여 생긴 SPM에서 착안되었다.
SPP layer를 통과하게 되면 고정된 사이즈의 output을 얻을 수 있고, 이는 FC-layer에 input으로 입력될 수 있는 고정된 vector를 얻을 수 있음을 의미한다.
bin이 2x2일 때 4x4, 6x2의 input에 SPP를 적용한 것을 그림으로 그려보았다.
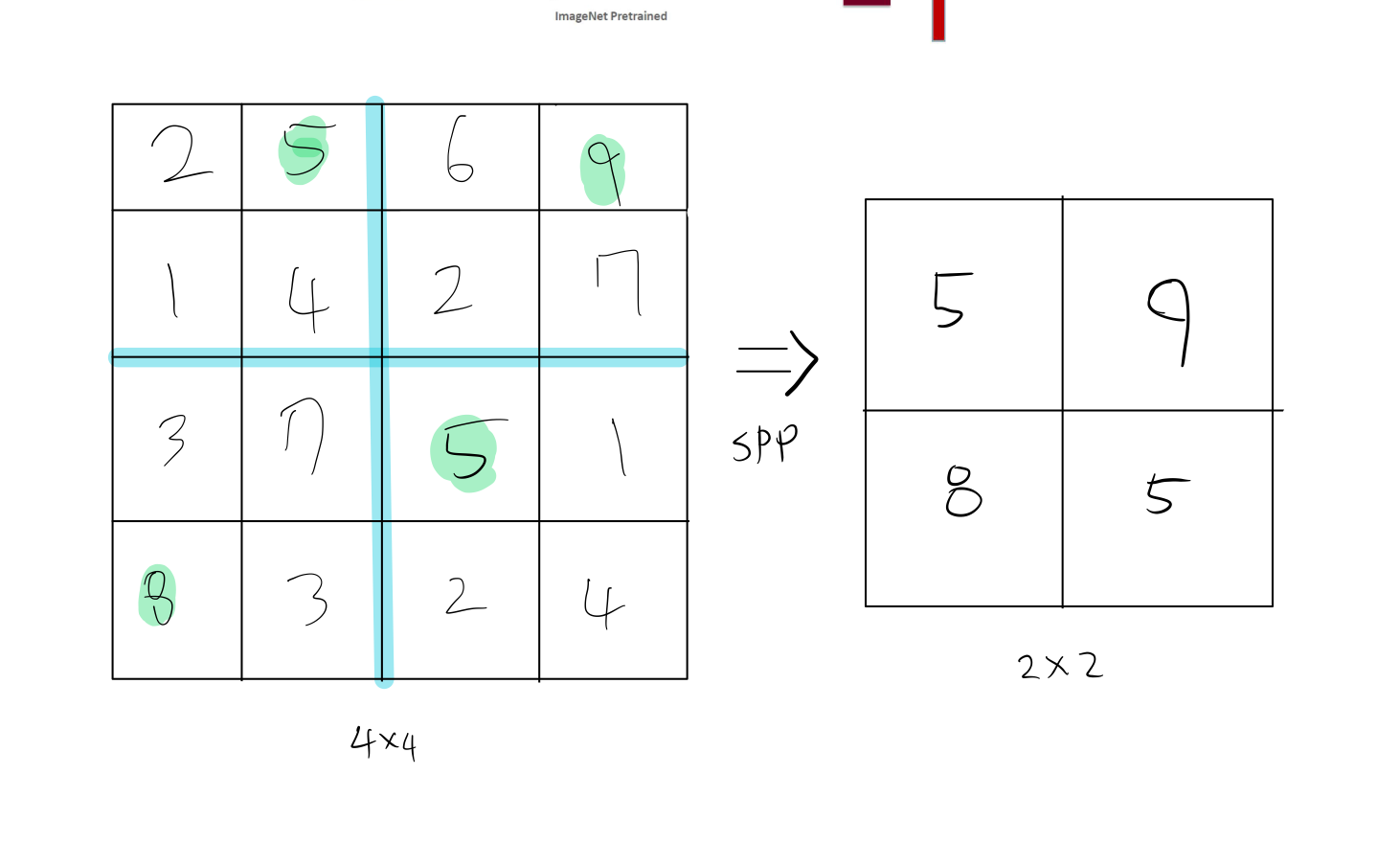
4x4 size의 input이 2x2 size의 output을 반환한다.
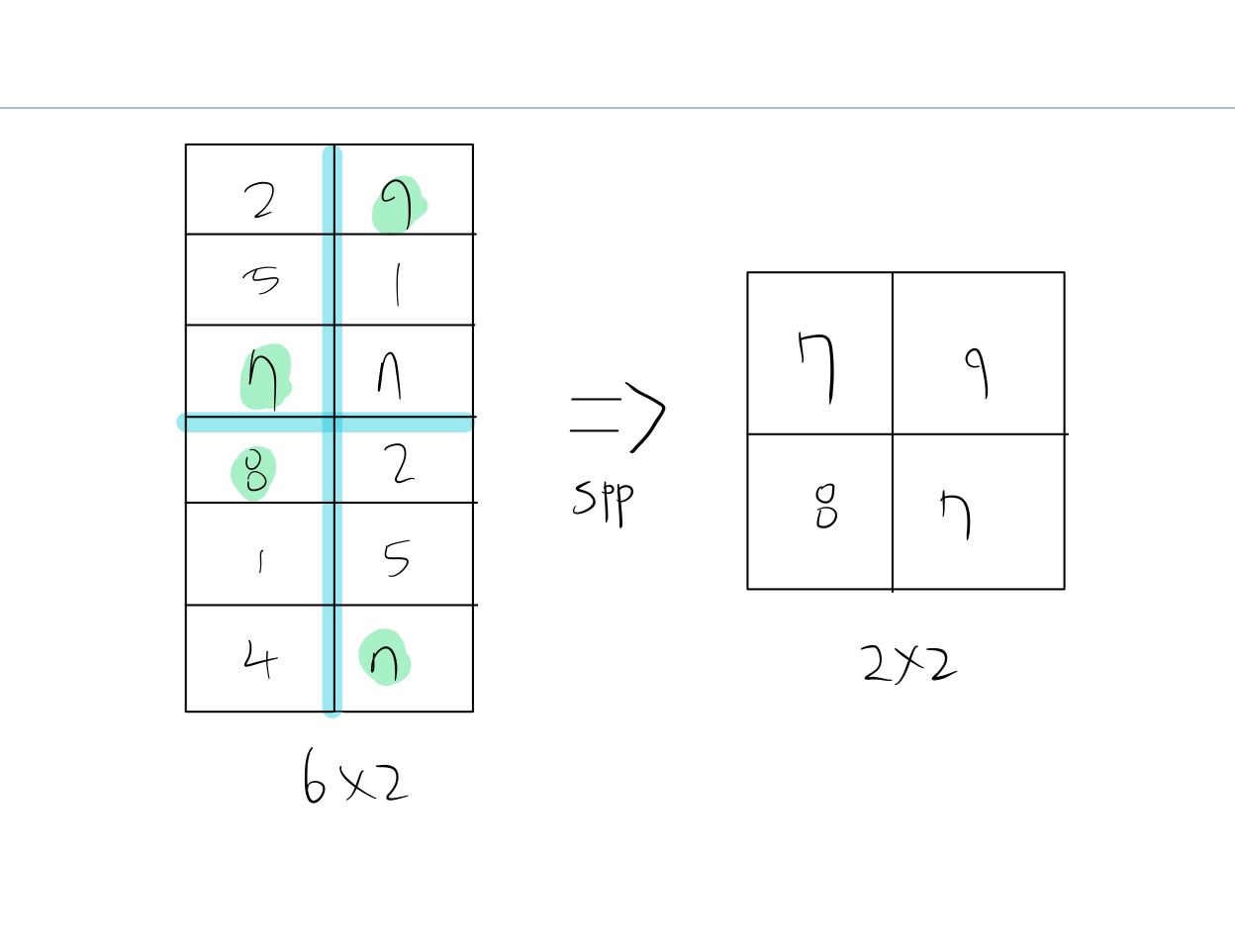
6x2 size의 input 또한 위와 같이 2x2 size의 output을 반환한다.
4X4, 6X2 서로 input의 size가 다르지만, 미리 설정한 2x2의 size로 output size가 같은 것을 확인할 수 있다.
그림으로는 간략하게 표시했지만, 실제로는 pooling의 window size, stride를 정하는 공식이 있기 때문에 그 공식에 맞추어 계산하면 같은 size의 output을 얻을 수 있다.
window size = ceil(feature map size / bin size)
stride = floor(feature map size / bin size)
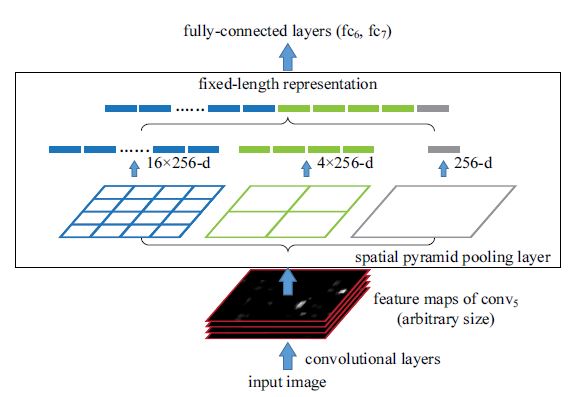
임의의 size를 가지는 conv5의 output가 SPPlayer를 거치게 되면 미리 정해놓은 binsize에 따라 고정된 vector값을 얻을 수 있고, Fc layer의 입력으로 들어갈 수 있게 된다!
위의 사진에서는 bin = 21이다.
SPPnet 작동 순서
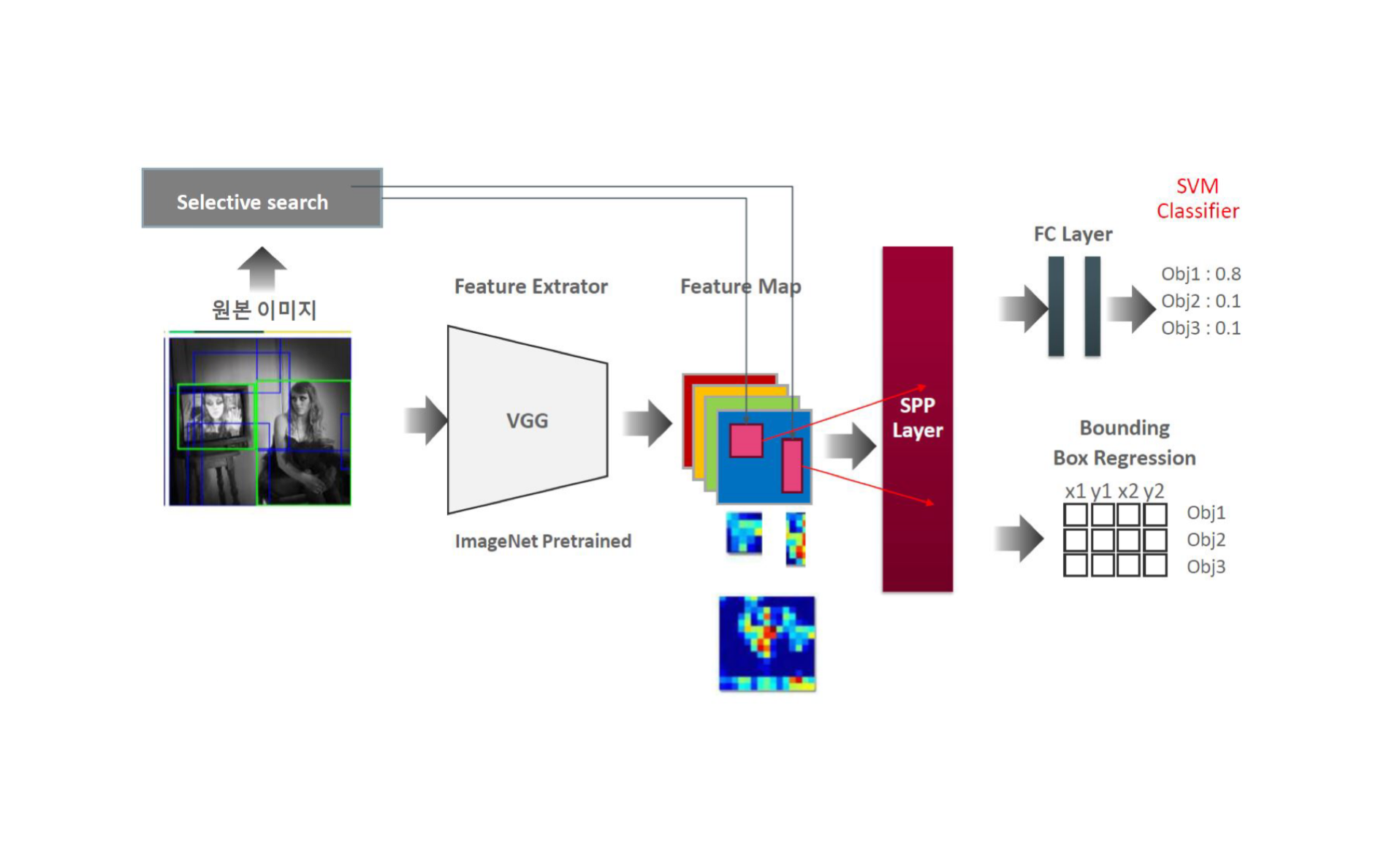
-
selective search를 사용하여 약 2000개의 region proposals를 생성한다
-
이미지를 CNN에 통과시켜 feature map을 얻는다.
-
feature map에 region proposal별로 결부시키고 SPP layer에 전달한다.
-
SPP layer를 적용하여 얻은 고정된 벡터 크기를 fc layer의 input으로 입력한다.
-
SVM으로 classification을 수행
-
bbox regression으로 bounding box 크기를 조정하고 non-maximum suppression을 사용하여 bounding box를 산출한다.
결론
-
SPP layer를 도입하면서 R-CNN에서 발생하는 문제점인 crop, warp에서 생기는 이미지 변형, CNN 연산 횟수를 2000회 에서 1회로 감소시키면서 train, test에 소요되는 시간을 대폭 감소 시켰다.
-
하지만 이 점을 제외하고는 R-CNN과 같은 구조여서 여전히 복잡한 과정이 남아있다는 문제점이 있다.
Reference
https://deep-learning-study.tistory.com/445
https://yeomko.tistory.com/14
딥러닝 컴퓨터 비전 완벽 가이드
