정리해보고 있는데 그냥 https://rebro.kr/167 이 글을 읽는게 훨씬 나아보인다.
(정리가 무진장 잘 되어있다.)
인덱스(Index)는 데이터베이스의 테이블에 대한 검색 속도를 향상시켜주는 자료구조이다.
테이블의 특정 컬럼(Column)에 인덱스를 생성하면, 해당 컬럼의 데이터를 정렬한 후 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장된다. 컬럼의 값과 물리적 주소를 (key, value)의 한 쌍으로 저장한다.
인덱스는 책에서의 목차 혹은 색인이라고 생각하면 된다.
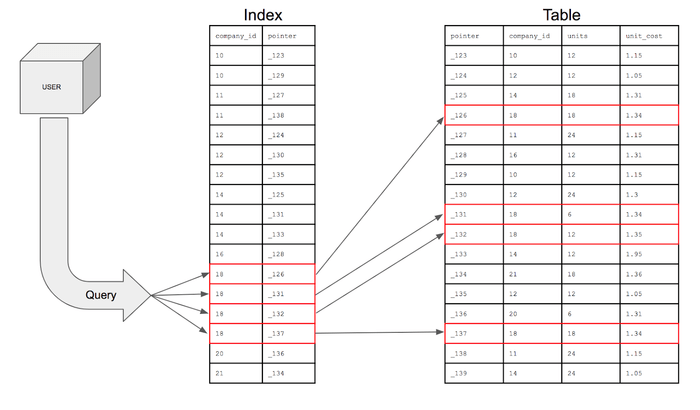
출처 : https://mangkyu.tistory.com/96
결합 인덱스 컬럼의 설정 시 고려해야 할 우선순위
- where절 조건에 많이 사용되는 컬럼이 우선시
- Equal('=')로 사용되는 컴럼을 우선
- 분포도가 좋은 컴럼을 우선
- 자주 이용되는 순서대로 결합 인덱스 컬럼의 순서 결정
인덱스(Index)의 장점
- 테이블 검색 속도와 성능 향상
- 인덱스에 의해 데이터들이 정렬된 형태를 갖음
- where문으로 특정 조건의 데이터를 찾을 때 테이블의 전체 조건과 비교(풀 테이블 스캔) -> 조건에 맞는 데이터만 빠르게 찾음
인덱스(Index)의 단점
- 인덱스를 관리하기 위한 추가 작업이 필요
- 추가 저장 공간 필요
- 잘못 사용하는 경우 오히려 검색 성능 저하
인덱스를 항상 정렬된 상태로 유지해야 하기 때문에 인덱스가 적용된 컬럼에 삽입(INSERT), 삭제(DELETE), 수정(UPDATE) 작업을 수행하면 다음과 같은 추가 작업이 필요하다.
- INSERT : 새로운 데이터에 대한 인덱스를 추가
- DELETE : 삭제하는 데이터의 인덱스를 사용하지 않는다는 작업 수행
- UPDATE : 기존의 인덱스를 사용하지 않음 처리, 갱신된 데이터에 대한 인덱스 추가
또한 인덱스는 전체 데이터의 10 ~ 15% 이상의 데이터를 처리하거나, 데이터의 형식에 따라 오히려 성능이 낮아질 수 있다. 예를 들어 나이나 성별과 같이 값의 range가 적은 컬럼인 경우, 인덱스를 읽고 나서 다시 많은 데이터를 조회해야 하기 때문에 비효율적이다
인덱스를 사용하면 좋은 경우
- 규모가 큰 테이블
- 삽입(INSERT), 수정(UPDATE), 삭제(DELETE) 작업이 자주 발생하지 않는 컬럼
- WHERE나 ORDER BT, JOIN 등이 자주 사용되는 컬럼
- 데이터의 중복도가 낮은 컬럼
단일 Index

복합 Index

- Jmeter로 돌렸을 때
local 상황
단일 index : 298 ~ 330
period, start_date, member : 337 ~ 372
period, member, start_date : 235 ~ 258
start_date, member, period : 245 ~ 263
start_date, period, member : 280 ~ 307
member, start_date, period : 265 ~ 277
member, period, start_date : 323 ~ 369
처음 3번의 제외 이 후, 5번 조회
프리티어 EC2 서버 상황
단일 index : 532 ~ 694
period, start_date, member : 367 ~ 409
period, member, start_date : 398 ~ 440
member, period, start_date : 326 ~ 360
처음 15번 제외 이 후, 5번 조회
Jmeter를 써서 확인을 여러 번 했는데 애초에 Workbench로 하는 거였다.
Jmeter로 느리다고 판단되는 것들을 확인하고 Workbench로 돌려봤다.
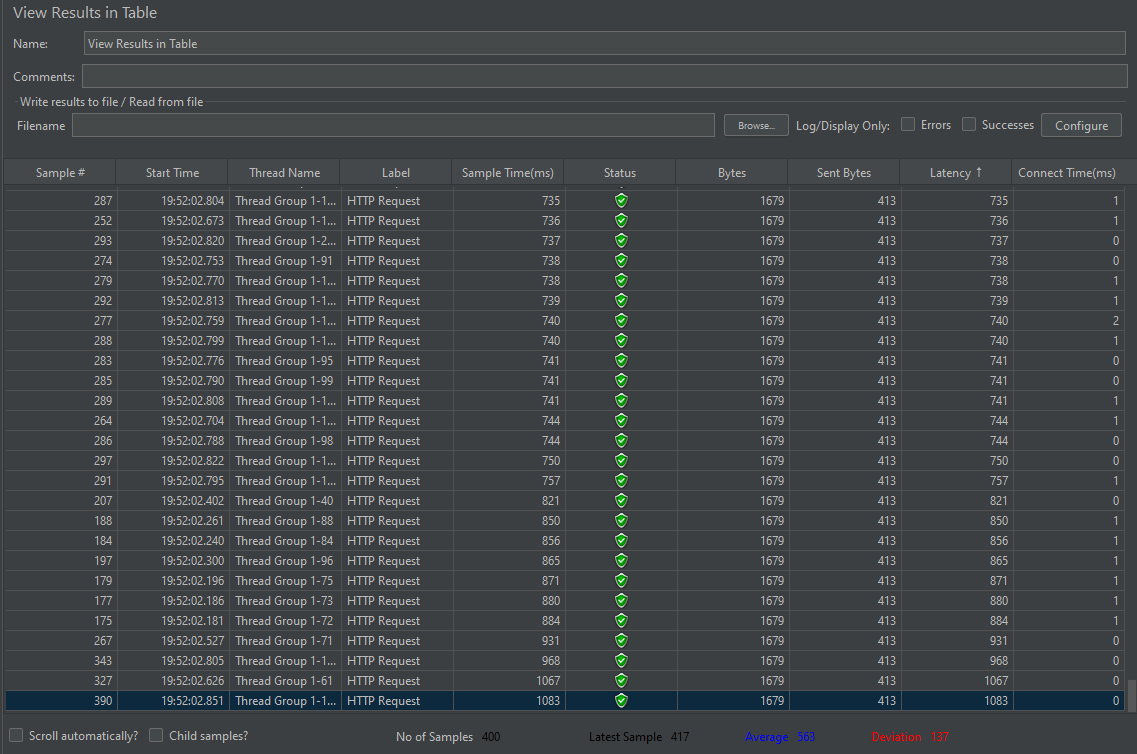
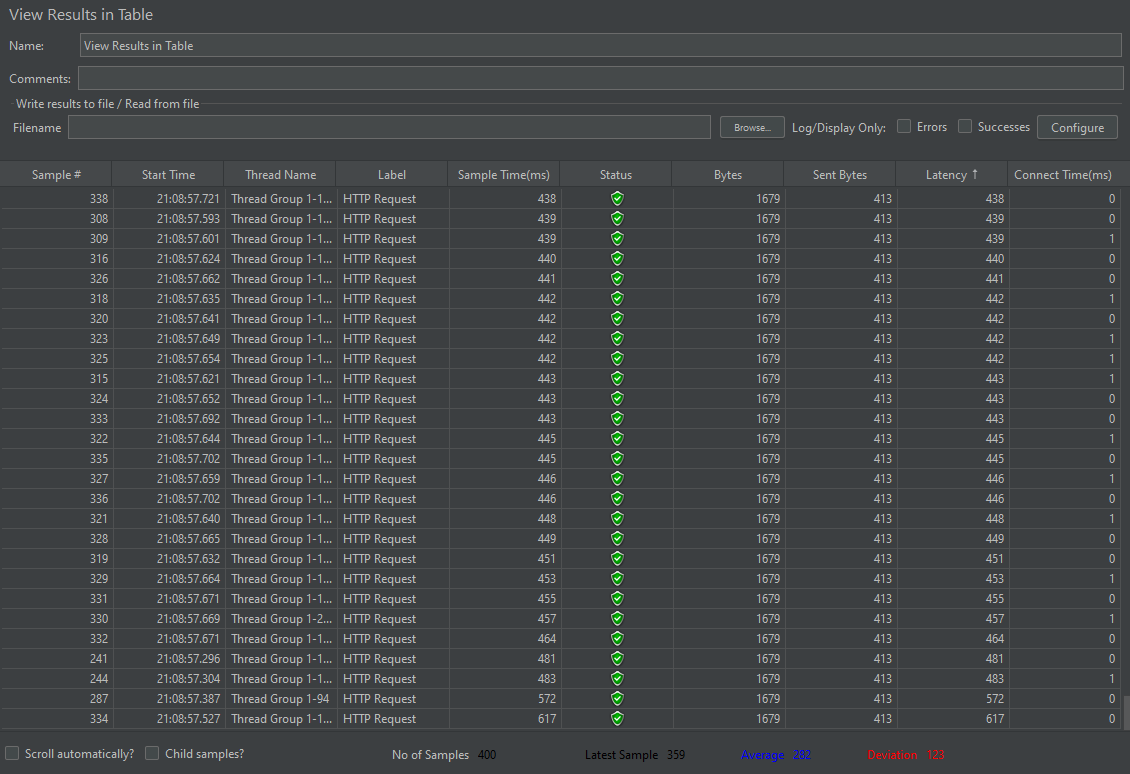
2번째 테스트 - 일일, 주간, 월간, 연간 통계 페이지 조회
개선 전
개선 후
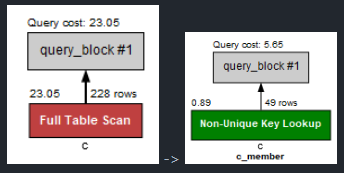
test 상황
- Query cost
1. index 제외 : 23.05
단일 index(1개)
2 - 1. member만 : 5.65
2 - 2. 단일 index(전체) : 5.65(member만 index한 것과 동일)
복합 index(2개)
3 - 1. start_date, period : 7.01
3 - 2. period, start_date : 7.01
복합 index(3개)
4 - 1. period, start_date, member : 7.01
4 - 2. period, member, start_date : 6.56
4 - 3. start_date, member, period : 7.01
4 - 4. start_date, period, member : 7.01
4 - 5. member, start_date, period : 6.56
4 - 6. member, period, start_date : 6.56
-> 확연한 개선 (Latency : 1083ms -> 617ms, Average : 563ms -> 282ms)
3번째 테스트 - 메인 페이지 조회(행성, 달성 개수, 좋아요 개수 조회)
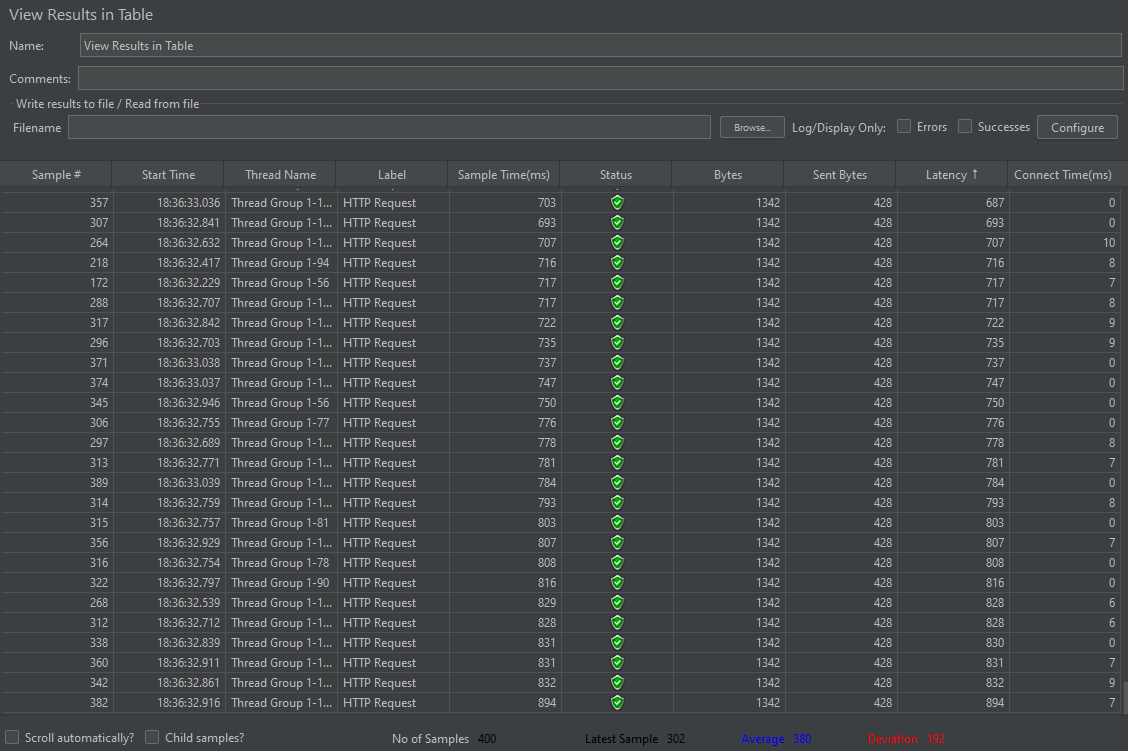
개선 전
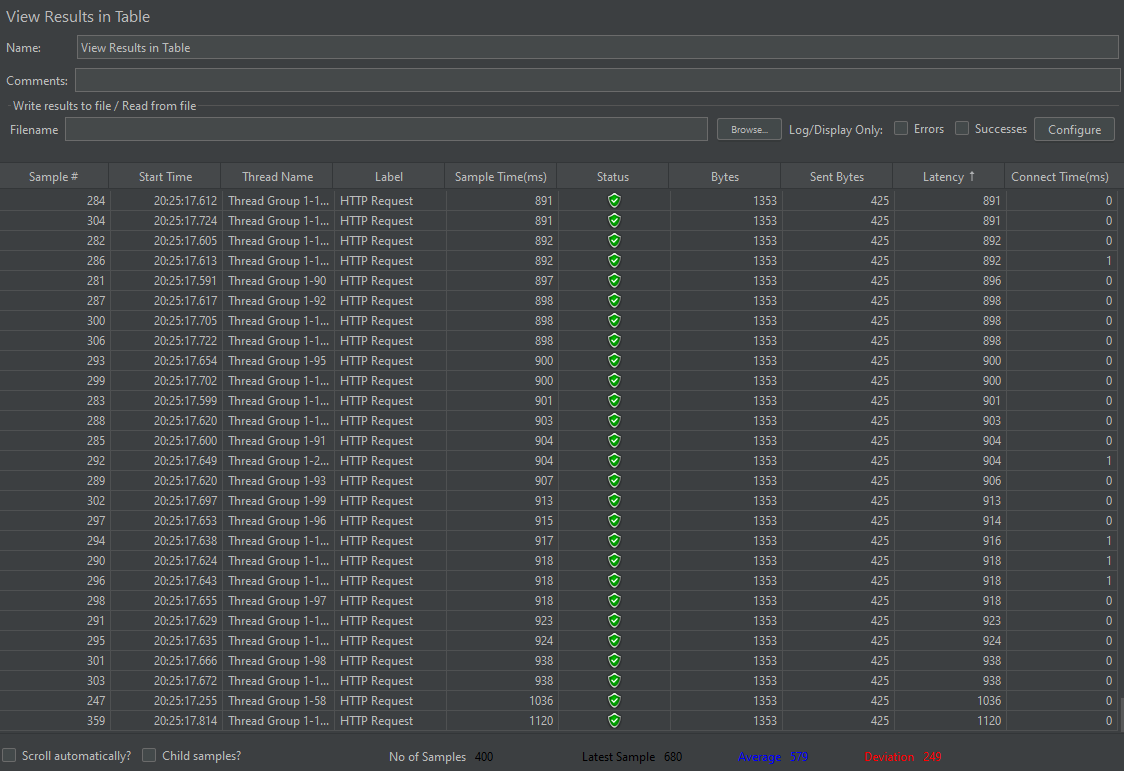
개선 후
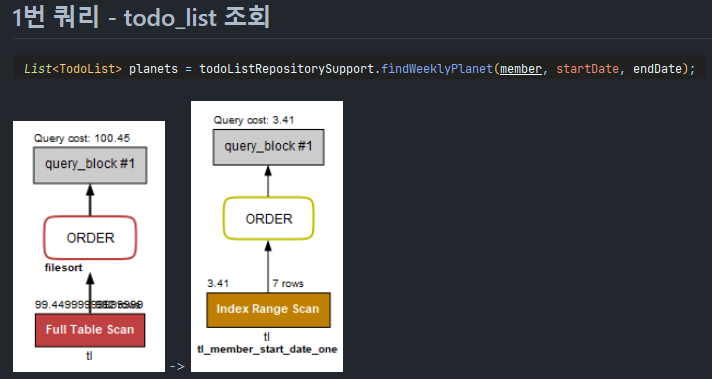
test 상황
- Query cost
1. index 제외 : 100.45
단일 index
2 - 1. member만 : 12.35
2 - 2. start_date만 : 109.61
복합 index(2개)
3 - 1. member, start_date : 3.41
3 - 2. start_date, member : 102.86
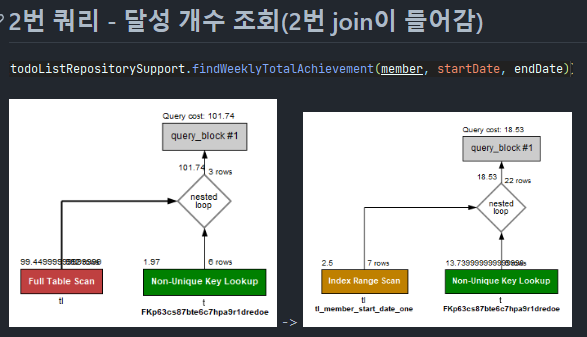
test 상황
- Query cost
todo_list에서
1. index 제외 : 101.74
단일 index
2 - 1. member만 : 34.23
2 - 2. start_date만 : 113.64
2 - 3. member, start_date : 61.08
복합 index(2개)
3 - 1. member, start_date : 18.53
3 - 2. start_date, member : 67.75
todo에서
단일 index(todo에서)
4 - 1. is_achieved : 19.44(전체 상황에서 동일)
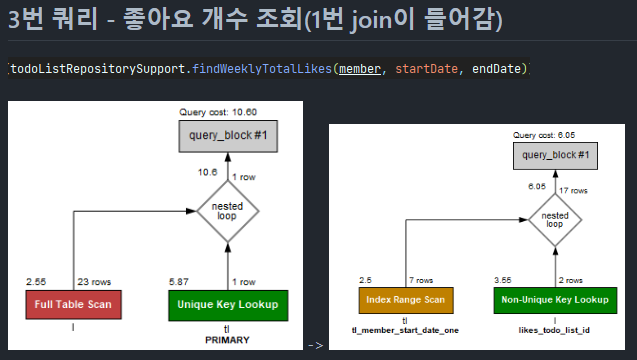
test 상황
- Query cost
todo_list에서는 위에 비용이 적은 복합 index(2개, member, start_date를 적용)
1. index 제외 : 10.60
단일 index
2. todo_list : 6.05
복합인덱스를 적용할 때 카디널리티(cardinality)가 높은 것을 앞에 적는 게 쿼리 비용 적다.
중복도가 ‘낮으면’ 카디널리티가 ‘높다’고 표현한다.
중복도가 ‘높으면’ 카디널리티가 ‘낮다’고 표현한다.
참고 자료 :
https://mangkyu.tistory.com/96
https://coding-factory.tistory.com/755
https://herojoon-dev.tistory.com/142
https://itholic.github.io/database-cardinality
https://engineering.linecorp.com/ko/blog/mysql-workbench-visual-explain-index/
