
Intro
- 사용자가 상품을 등록할 때마다 일일이 적절한 카테고리를 찾아야 한다면 서비스의 사용성이 떨어지기 때문에, 번개장터는 사용자에 상품 제목을 보고 등록 카테고리를 추천해주는 기능을 제공하고 있습니다. (번개장터에는 상품을 등록할 수 있는 카테고리가 700개 정도 있습니다. )
- 2021년 4분기에 번개장터 데이터 팀은 기존 기능을 개선할 새로운 상품 카테고리 추천 알고리즘에 대한 연구 및 개발을 진행하게 됩니다.
01 기존 알고리즘의 문제점과 개선 방향
- 기존 알고리즘은 상품 제목이 입력되는 순서에 맞춰 키워드를 인식하고, 해당 키워드를 포함한 상품이 가장 많이 등록된 순으로 카테고리를 추천하였습니다.
- 검색 엔진만 구축되어 있다면 개발이나 유지보수에 대한 비용을 추가할 필요 없이 추천을 제공할 수 있다는 장점이 있습니다.
- 그러나 이러한 방식은 부정확한 추천을 해주는 경우가 많았습니다. ex) 제목을 ‘방탄소년단 포토카드'로 입력하면 ‘보이그룹 포스터/화보' 카테고리를 추천해줬습니다. (사용자들이 ‘포토카드' 키워드가 포함된 상품들을 해당 카테고리에 가장 많이 등록했기 때문). 그러나 번개장터는 현재 보이그룹 스타굿즈 하위 카테고리로 ‘팬시/포카’ 카테고리를 별도로 만들어 놓았기 때문에, 적합한 추천이 아니게 됩니다.
- 위 사례처럼 일부 키워드들에 가중치를 과도하게 부여하는 추천이 제공되지 않도록, 상품 제목에 있는 모든 단어들을 활용해서 추천을 제공할 수 있는 알고리즘이 필요했습니다.
- 또한 상품 등록이 상대적으로 적은 카테고리들도 후보군에 적절히 들어갈 수 있도록 해야 했습니다.
02 데이터 수집
-
번개장터는 상품 제목이 A락 입력되면 B 카테고리를 추천하라는 규칙을 모델에 학습시키기 위해 일정 기간동안 사용자가 등록한 상품의 제목과 해당 상품이 등록된 카테고리의 쌍으로 이뤄진 데이터를 수집하였습니다.
-
데이터 수집 고려 사항
-
추천에서 제외할 카테고리 선정
- 상품 등록이 잘 일어나지 않아 카테고리 추천에 대한 수요 자체가 적은 카테고리들은 추천 대상에서 제외하였습니다. (모델의 파라미터 개수를 제한하고, 연산을 줄이기 위해 불필요한 카테고리는 제외함)
- 이질적인 상품이 등록될 수 있는 카테고리를 추천 대상에서 제외하였습니다. (예를 들어 ‘방탄소녀단 포토카드'라는 제목에 ‘기타(보이그룹)’ 카테고리가 추천되면, 이 카테고리가 딱히 틀린 추천은 아니기 때문에 ‘보이그룹 팬시/포카' 카테고리가 있어도 이 카테고리를 선택하는 역선택이 발생할 수 있습니다.)
- 상품 등록이 잘 일어나지 않아 카테고리 추천에 대한 수요 자체가 적은 카테고리들은 추천 대상에서 제외하였습니다. (모델의 파라미터 개수를 제한하고, 연산을 줄이기 위해 불필요한 카테고리는 제외함)
-
카테고리별 상품 개수 상한 설정
-
카테고리별 상품 개수가 특정 카테고리에 치우처져 있다면 편향된 학습이 일어날 수 있습니다(비인기인 카테고리에 대한 정확도를 희생하여 인기 카테고리에 대한 정확도를 개선시키게 됨). 번개장터는 아래 세 가지 전략들 중 하나를 정해 카테고리별 상품 개수를 제한한 데이터로 모델을 학습시켰습니다.
-
none: 카테고리별 상품 개수 상한을 정하지 않음(현상유지)
-
log: 상품 개수 상한을 카테고리별 상품 개수의 로그 값에 상수를 곱한 값으로 적용
-
uniform: 카테고리별 상품 개수 상한을 10,000개로 일괄 적용
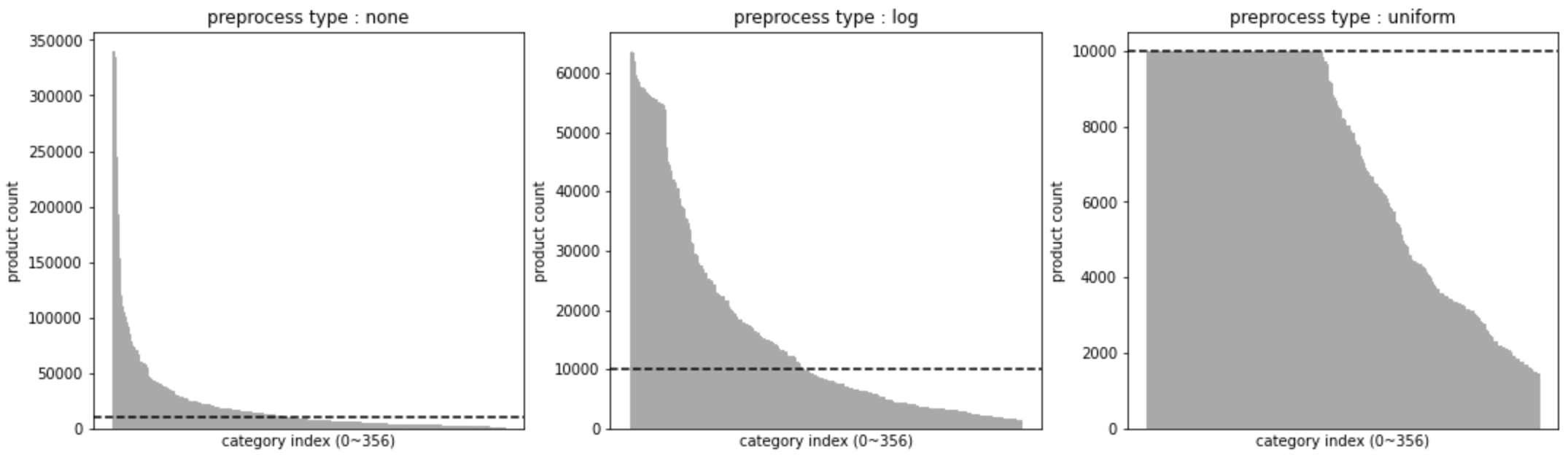
(그림에서 까만 점선은 10,000을 의미)
-
-
-
03 모델 학습
- 토크나이저
- 브랜드명과 같은 대명사들은 카테고리를 분류하는 데 중요한 정보를 제공하는 경우가 많습니다. 그리고 이 대명사들은 트렌드에 따라 상품 제목에 새로 포함되기도 하고 더 이상 쓰이지 않아 사라지기도 합니다. 따라서 번개장터 외부 텍스트로 미리 학습된 토크나이저보다는, 비교적 최근에 수집된 상품 제목들을 사용해 BPE, unigram 같은 알고리즘으로 새로 학습시킬 수 있는 sentencepiece 토크나이저를 사용했습니다.
- 아키텍처
- 상품 제목을 분할한 토큰들의 배열의 대응하는 임베딩 벡터들의 배열(행렬)이 입력되었을 때, 신경망 모델은 연산을 거쳐 특정 카테고리해 해당할 가능성(점수)를 계산합니다.
- 번개장터는 이번 프로젝트에서 아래의 세 아키텍처를 후보로 정하였습니다.
- FastText
- 장점
- 페이스북이 구현한 라이브러리를 사용해서 토크나이저, 임베딩 벡터, 다양한 파라미터들을 간편하고 빠르게 학습시킬 수 있음.
- output이 bin파일 하나밖에 없어서 관리가 용이
- 단점
- 정의된 대로만 라이브러리를 사용할 수 있기 때문에, 성능 개선 여지가 적음(연산 횟수를 조정할 수 없는 등)
- 장점
- DAN
- 토큰별 임베딩들의 평균을 상품 제목의 임베딩으로 사용한다는 점은 FastText와 같으면서, FastText의 단점(성능 개선 여지가 적음)을 타개할 수 있어 FastText에 비해 나은 성능을 내느 모델을 만들 수 있음
- 하지만 FastText 라이브러리가 주는 편리함은 포기해야 함(토크나이저, 임베딩, 분류기 학습이 전부 각각 이뤄지고, 이에 따라 실제 서빙을 위해 필요한 파일도 각각 따로 생성됨)
- GRU
- recurrent 연산을 통해 토큰의 순서 정보를 사용할 수 있음
- 그러나 recurrent 연산을 해야하기 때문에 상품 제목 내 토큰의 개수만큼 행렬 곱 연산이 이루어져야 한다는 단점이 있음
- FastText
04 평가 결과(offline test)
-
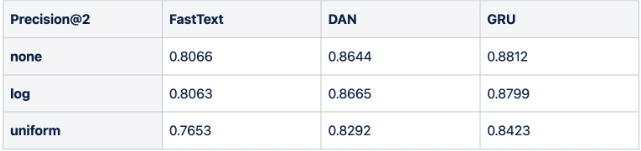
번개장터는 Precision@k를 사용하여 모델의 성능을 검증하였습니다.
** Precision@k: 추천을 k개 제공했을 때의 추천 성공률
-
카테고리별 상품 개수에 대한 전처리를 사용하지 않는 none 전략으로 학습시킨 모델의 성능이 가장 좋은 것처럼 보이지만, 이를 박스플롯으로 분포를 비교하면 다른 인사이트를 얻을 수 있습니다.
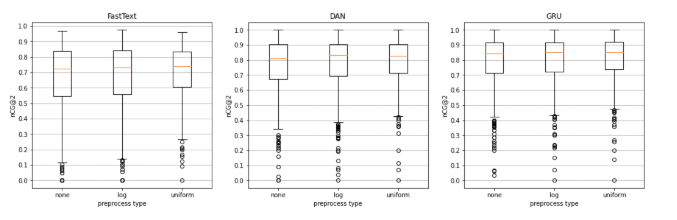
: Uniform 방식을 사용했을 때 박스의 세로 길이가 가장 작음 → 균등하게 좋은 추천을 제공함
-
-
번개장터는 검증 결과 전처리 방법 선택과 관계 없이 GRU가 항상 좋은 성능을 보였기 때문에 GRU 아키텍처를 선택하였습니다.
05 실제 사용자 피드백(online test)
-
카테고리 추천 성공 및 실패 정의
- 번개장터는 각 알고리즘을 평가할 척도로 ‘전체 상품 등록 이벤트 중에서 제목을 입력해 카테고리 추천을 받은 사용자가 추천된 카테고리를 선택해서 상품을 등록하는 이벤트가 차지하는 비중'으로 정했습니다.
- 상품을 등록한 사용자가 추천 카테고리를 선택해서 상품을 등록했다 → 성공
- 자신이 직접 카테고리 목록에서 등록할 카테고리를 탐색해서 상품을 등록했다 → 실패
- 번개장터는 각 알고리즘을 평가할 척도로 ‘전체 상품 등록 이벤트 중에서 제목을 입력해 카테고리 추천을 받은 사용자가 추천된 카테고리를 선택해서 상품을 등록하는 이벤트가 차지하는 비중'으로 정했습니다.
-
성능 평가 결과(a/b test)
- 성능 평가 결과, 신규 알고리즘이 실제로 사용되는 비율(92%)이 기존 알고리즘(73%)에 비해 더 많이 사용되는 것을 확인하였습니다
- 또한 추천 알고리즘 사용률을 주 단위로 집계하고, 이 비율들의 분포를 박스플롯으로 나타낸 결과, 기존 알고리즘에 비해 신규 알고리즘이 다양한 카테고리를 정확하게 추천해주고 있음을 확인할 수 있었습니다.
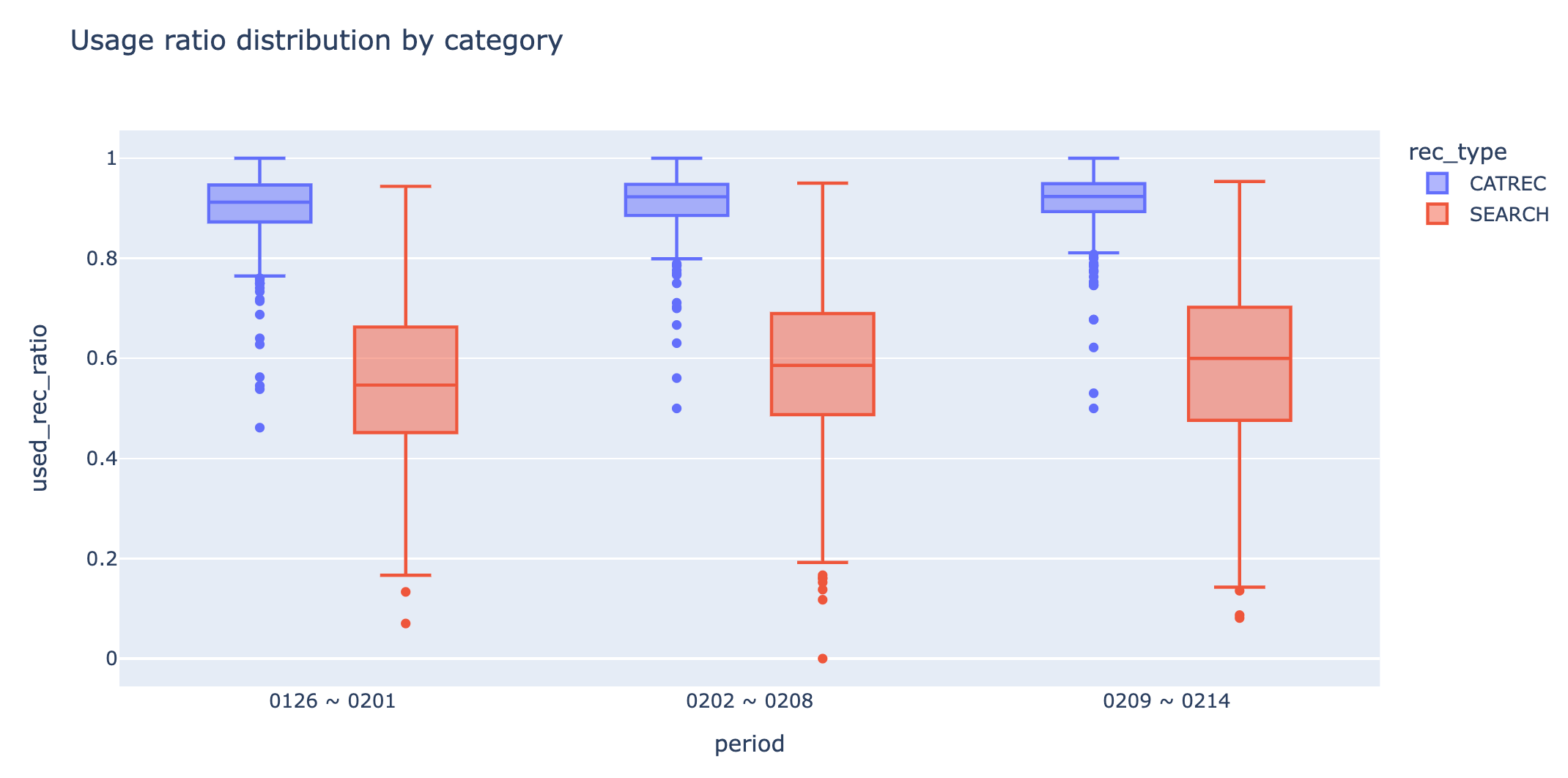
- 성능 평가 결과, 신규 알고리즘이 실제로 사용되는 비율(92%)이 기존 알고리즘(73%)에 비해 더 많이 사용되는 것을 확인하였습니다
마무리
- 상품 제목을 분류하는 등의 자연어 처리 테스크를 해결하기 위해 최근에는 BERT 계열의 아키텍처들이 가장 많이 활용되고 있습니다. 하지만 번개장터 카테고리 추천은 실시간으로 일어나기 때문에, 서빙되는 시간과 비용을 고려해야만 했고, 무거운 BERT는 후보군에서 제외되었다고 합니다.
Reference
