
Competition with AI Stages - tutorial
Why Competition?
- 경험한 이론을 실제 데이터와 코드 베이스에 적용하며 이해를 도울 수 있다.
- Competition 형태의 실습을 통해 점진적인 모델 성능 향상을 경험할 수 있다.
- 머신러닝 파이프라인의 일부분을 경험해볼 수 있다.
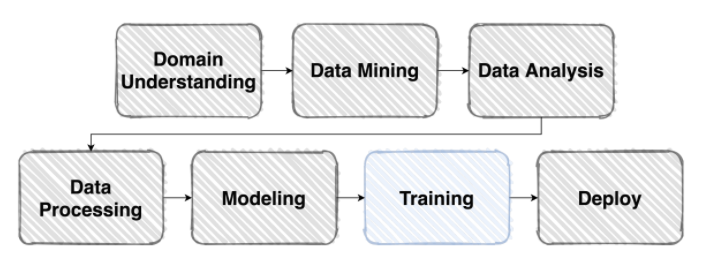
일반적인 머신러닝 Flow
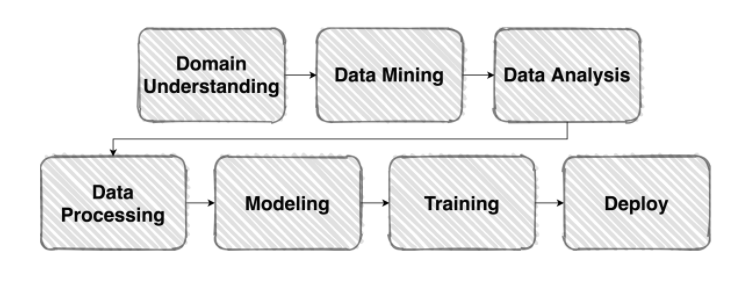
Competion에서의 머신러닝 Flow
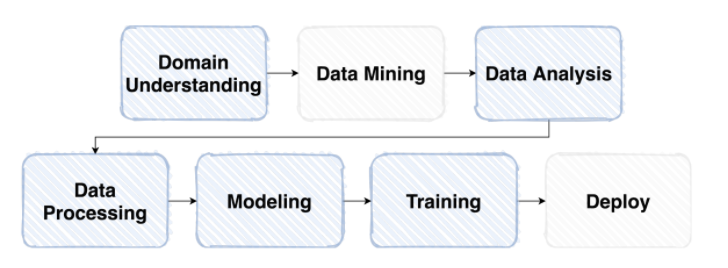
Competition Overview - Problem Definition
대회에 들어가기 앞서, 문제 정의를 정확히 할 필요가 있다. 다음과 같은 질문들을 통해 어떤 방식으로 문제를 풀어나갈 것인지 생각해봐야 한다.
- 내가 지금 풀어야 할 문제는 무엇인가?
- 배경, 이유, 문제점, ...
- 이 문제의 Input과 Output은 무엇인가?
- 이 솔루션은 어디서 어떻게 사용되어지는가?
- File의 형태와 Metadata Field는 어떤 식으로 구성되어 있는가?
- ...
조금은 다른 시각의 문제 정의
- 이 대회를 통해 우리 팀은 무엇을 얻어가야 할까?
- 팀 목표, 개인 목표, 문제를 해결해 나갈 과정 및 방법 정의 등
- 이론과 이론을 적용하는 문제 사이에는 어떤 괴리가 있으며, 이를 어떻게 해결할 수 있을까?
- ...
EDA(Exploratory Data Analysis)
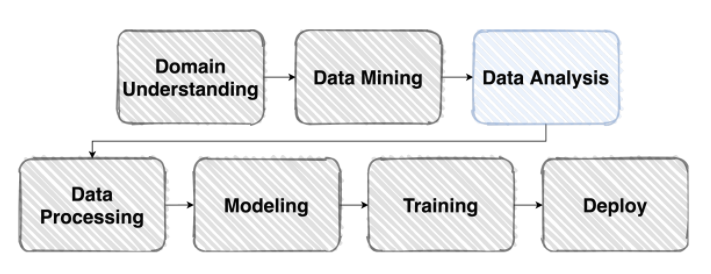
- Exploratory Data Anlaysis: 탐색적 데이터 분석
- 혹은 "데이터를 이해하기 위한 모든 노력"
- 데이터는 어떻게 생겼을까?
- 데이터는 어떤 타입일까?
- 이 데이터를 주제와 어떻게 연결지어 생각해볼 수 있을까?
- 이 데이터는 어떻게 모아졌을까?
"데이터" + "아무 생각" = EDA
Data Processing
- 주어진 Vanilla Data를 모델이 좋아하는 형태의 Dataset으로 바꿔볼자!
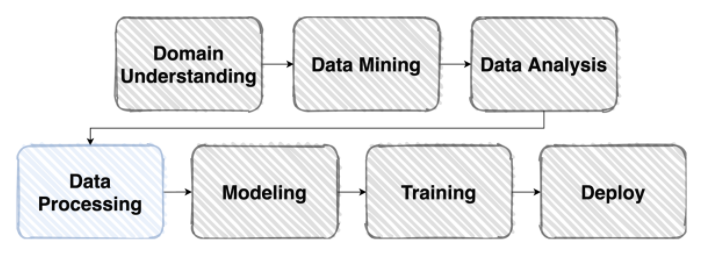
Dataset: Pre-Processing
- 다양한 전처리 과정들이 존재
- 도메인, 데이터 형식에 따라 정말 다양한 Case가 존재할 수 있음
- EDA 작업을 거치며 필요한 전처리를 탐색 및 설계
- ex) 이 사진에는 너무 많은 정보가 담겨 있어.. -> 필요한 정보만 추출 !

- ex) 이 사진은 너무 고화질이라 모델링을 하기엔 컴퓨팅 자원이 부족해... -> Resize !?
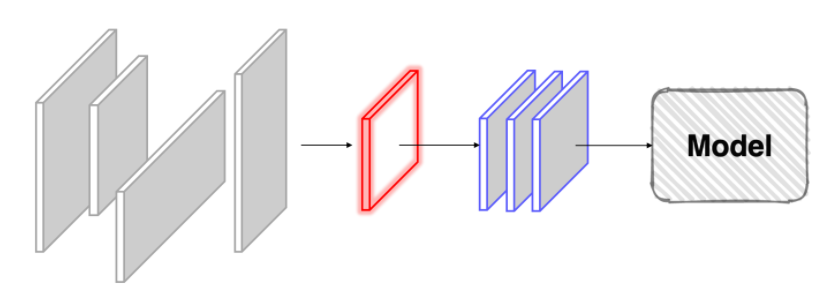
- 도메인, 데이터 형식에 따라 정말 다양한 Case가 존재할 수 있음
Dataset: Generalization
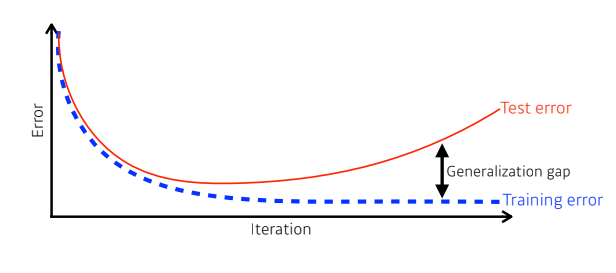
- 일반화 성능이란 Training error와 Test error간 차이에 대해 이야기한다.
- 차이가 작을수록 일반화 성능이 좋다고 말함.
- (Training error와 상관없이 Test error가 낮게 낮다고 해서 일반화 성능이 안 좋다고 할 수는 없음)
Under-fitting & Over-fitting
- 과소적합: 모형이 너무 단순한 것
- 과대적합: 모형이 데이터의 패턴을 너무 과도하게 반영한 것
- 훈련 데이터에 대한 성능은 좋지만, 새로운 데이터에서의 일반화 성능이 나빠질 수 있음
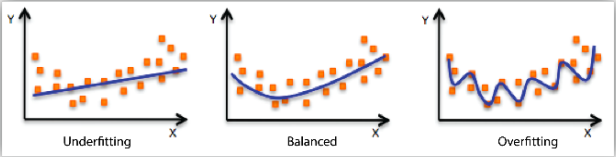
- 훈련 데이터에 대한 성능은 좋지만, 새로운 데이터에서의 일반화 성능이 나빠질 수 있음
Bias-variance trade off
- Bias: 평균적으로 봤을 때, 주요 타겟에 근접해있는가?
- Variance: 출력이 얼마나 일괄되게 나오는가?
- Variance가 크면 overfitting될 가능성이 큼
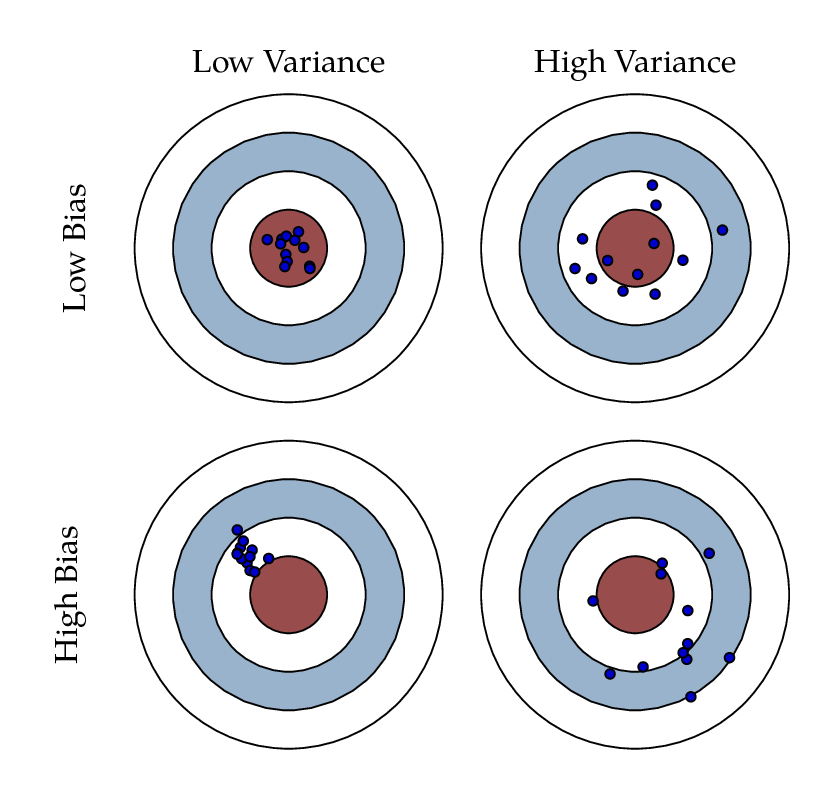
- bias와 variance는 동시에 줄일 수 없음(trade-off 관계)

- bias와 variance는 동시에 줄일 수 없음(trade-off 관계)
- Variance가 크면 overfitting될 가능성이 큼
Cross Validation
- 교차검증(CV: Cross Validation)
- 데이터가 충분치 않아 검증용 데이터를 따로 할당하기 어려운 경우 사용
- 훈련 데이터를 여러 번 반복해서 나누고 여러 모델을 학습하고 평가하는 방법
- 대표적인 방법: k-fold CV
- 전체 데이터를 k등분하여 K-1개 그룹은 훈련용으로, 나머지 한 그룹은 검증용으로 사용하는 과정을 반복하여 평균을 구함
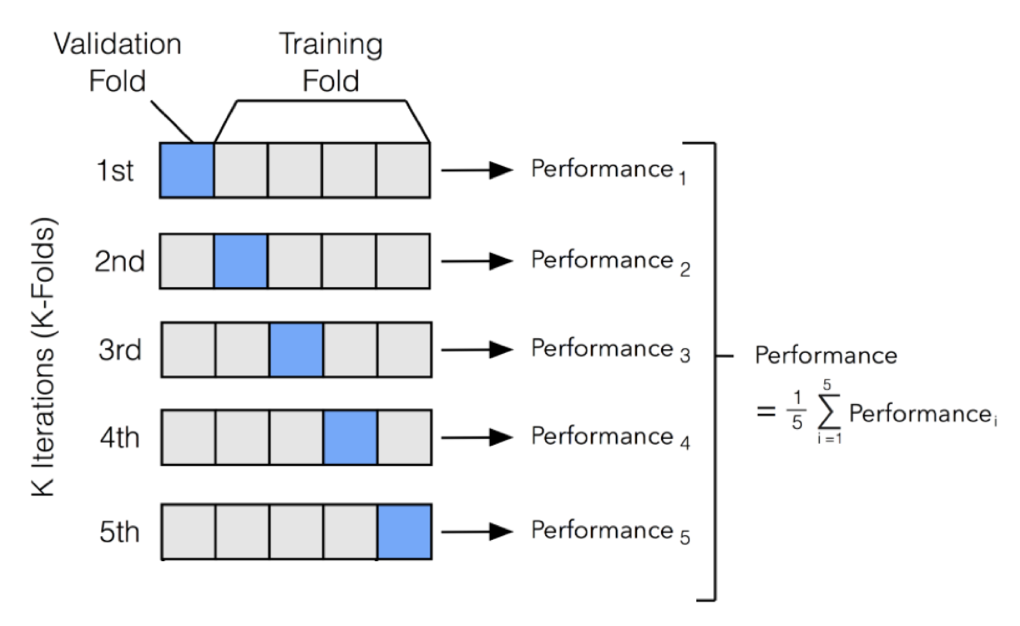
- 전체 데이터를 k등분하여 K-1개 그룹은 훈련용으로, 나머지 한 그룹은 검증용으로 사용하는 과정을 반복하여 평균을 구함
Data Augmentation
- 주어진 데이터가 가질 수 있는 Case(경우), State(상태)의 다양성
- 문제가 만들어진 배경과 모델의 쓰임새 등을 살펴보며 힌트를 얻을 수 있음

torchvision.transforms,Albumentations, ...
- 문제가 만들어진 배경과 모델의 쓰임새 등을 살펴보며 힌트를 얻을 수 있음
데이터에 적용하는 모든 것들은 항상 좋은 결과를 보장하지는 않는다.
- 앞서 정의한 Problem을 깊이 관찰하며, 어떤 기법을 적용하면 이러이러한 다양성을 가질 수 있음을 가정하고, 실험으로 증명해야 한다.
Data Generation
- 데이터 셋을 잘 구성하였으면, 모델에게 잘 전달해주어야 한다.
- 어떻게?
- 대상의 상태를 고려하여 적정한 양을 적절한 조합으로 준다!
- 어떻게?
torch.utils.data
-
Datasets
- Vanilla Data를 원하는 형태의 Dataset으로 변환
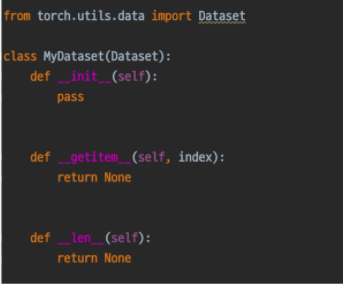
- Vanilla Data를 원하는 형태의 Dataset으로 변환
-
DataLoader
- 내가 만든 Dataset을 효율적으로 사용할 수 있도록 관련 기능 추가

- 내가 만든 Dataset을 효율적으로 사용할 수 있도록 관련 기능 추가
Model
- 모델이란?
- 데이터를 어떤식으로 변형시켜서 학습하고, 원하는 값을 도출해낼지에 대한 방법들
Design Model with Pytorch
- 딥러닝 관련된 오픈소스 머신러닝 프레임워크들은 많지만, 우린 Pytorch를 사용하고자 한다.
- Pytorch 장점: Low-level, Pytonic, Flexibility
- 👉PyTorch
Pretrained Model
- 모델 일반화를 위해 매번 수 많은 이미지를 학습시키는 것은 까다롭고 비효율적임
Pretrained Model: 좋은 품질, 대용량의 데이터로 미리 학습한 모델

- 미리 학습된 좋은 성능이 검증되어 있는 모델을 사용하면 비용적으로 매우 효율적임
- 이미 공개되어 있는 수 많은 Pretrained Model을 가져와서 사용할 수 있음
- torchvision.models, Gitbub
Transfer Learning: Pretrained Model을 가져와서 우리가 해결하고자 하는 과제에 맞게 재보정하여 사용하는 것
- Pretrained 모델이 가졌던 문제 정의와 나의 문제 정의를 비교하여 유사성을 고려해야 함.
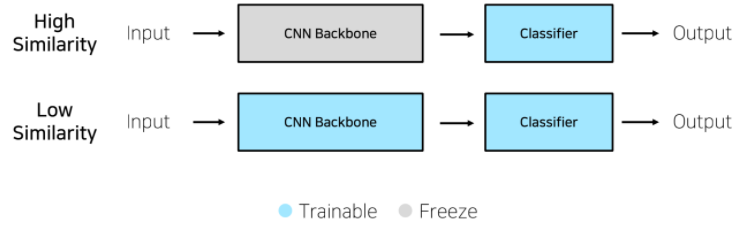
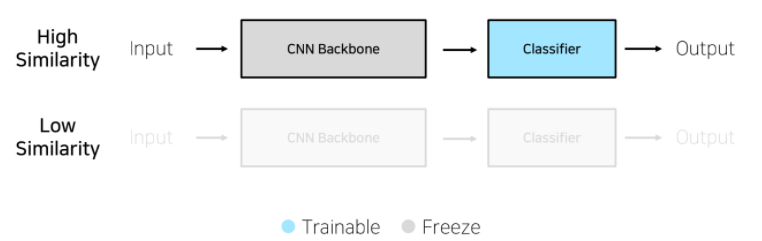
- Transfer Learning의 네 가지 경우
-
학습 데이터가 충분 & 높은 유사성: Feature Extraction
- Backbone 모델을 수정하지 않으며, Classifier만 수정하여 사용 -
학습 데이터가 충분 & 낮은 유사성: Fine Tuning
- Backbone 모델과 Classifier를 동시에 업데이트
-
학습 데이터가 불충분 & 높은 유사성
- Backbone 모델을 수정하지 않으며, Classifier만 수정하여 사용 -
학습 데이터가 불충분 & 낮은 유사성 -> 다른 방법을 찾아봐야..
Training & Inference
Loss, Optimizer, Metric
Loss
- Loss 함수 = Cost 함수 = Error 함수
- 분류에서의 Loss
- cross-entropy Loss
- Focal Loss: Class Imbalance 문제가 있는 경우, 맞춘 확률이 높은 Class는 조금의 loss를, 맞춘 확률이 낮은 Class는 Loss를 훨씬 높게 부여
- Label Smoothing Loss: Class target label을 Onehot 표현으로 사용하기 보다는([0, 1, 0, 0]), 조금 soft하게 표현하여 일반화 성능을 높이기 위한 loss([0.025, 0.9, 0.025, 0.025])
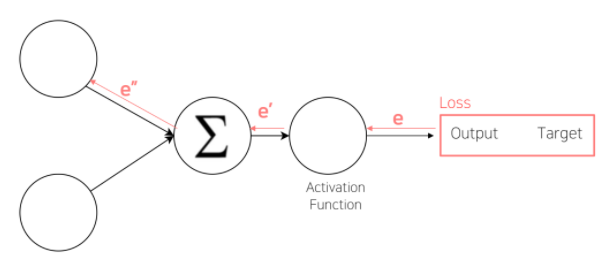
- loss.backward()
- Layer에 있는 Parameter들의 미분을 수행
- Forwad의 결과값(예측치)과 실제값 간의 차이(Loss)에 대해 미분을 수행함
- 해당 값으로 Parameter를 업데이트
Optimizer
-
어느 방향으로, 얼마나 움직일까?

-
LR scheduler: 학습 시에 Learning rate를 동적으로 조절하는 스케줄러
-
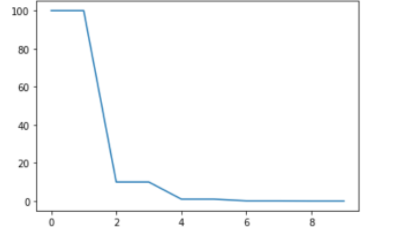
StepLR: 특정 step마다 LR을 감소시킴
- step_size = step의 수
- gamma = Step마다 LR에 곱해줄 값(0.1, ...)
-
CosineAnnealingLR: Cosine 함수 형태처럼 LR을 급격히 변경
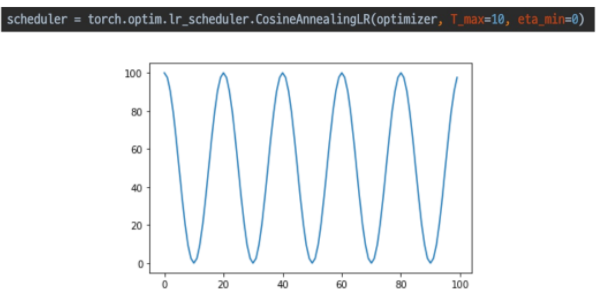
-
ReduceLROnPlateau: 더이상 성능 향상이 없을 때 LR 감소
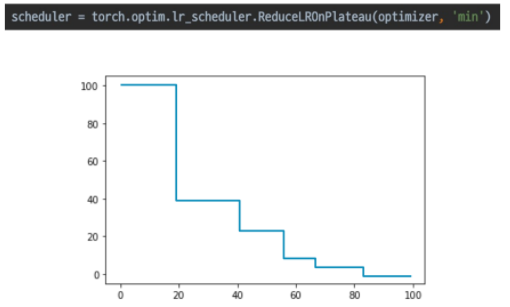
-
Metric
- 학습된 모델을 객관적으로 평가할 수 있는 지표가 필요
- Classification
- Accuracy, F1-score(class별 밸런스가 좋지 않을 때), precision, recall, ROC & AUC, ...
- Regression
- MAE, MSE, ...
- Ranking
- MRR, NDCG, MAP, ...
- Classification
- 상황에 맞는 Metric을 적절히 사용하여 모델을 평가해야 함
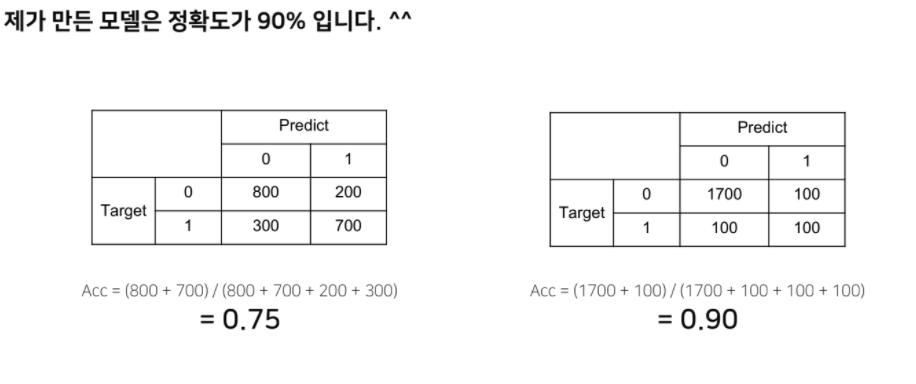
Training Process
Training Process의 핵심 Point
model.train(): 모델의 파라미터를 train가능한 모드로 바꾸어줌- 파라미터가 업데이트 가능해지며, Dropout과 BatchNorm을 사용 가능하게 만들어 줌
optimizer.zero_grad(): 배치마다 이전 gradient 정보를 없앰(없애지 않으면 이전 grad들이 더해짐)loss = criterion(outputs, labels): criterion을 바탕으로 chain 생성- Loss 함수 == criterion
criterion = torch.nn.CrossEntropyLoss()
- Loss 함수 == criterion
loss.backward(): loss에 대한 역전파 값 계산optimizer.step(): 업데이트 된 grad를 바탕으로 파라미터를 업데이트시킴
Inference Process의 핵심 Point
model.eval(): 모델의 파라미터를 test가능한 모드로 바꾸어줌- 파라미터가 업데이트 불가능하게 바뀌며, Dropout과 BatchNorm을 사용 불가능하게 만들어 줌
with torch.no_grad(): 모델의 Tensor 안에 모든 grad를 추적하지 않음.- grad를 '추적하지 않음'으로써 메모리 사용량을 줄이고 연산 속도를 높임
- model.eval()만으로도 파라미터 업데이트를 하지 않기 때문에 필수 사항은 아니지만, 사용하는 것을 권장
Ensemble
- 싱글 모델보다 더 나은 성능을 위해 서로 다른 여러 학습 모델을 사용하는 것
- 앙상블은 성능을 올릴 수 있는 방법 중 하나지만, 그만큼 비용도 많이 들어가기 때문에 현업에서는 잘 사용되진 않음(competition에선 많이 사용됨)
Bootstrapping
- 무작위 샘플링을 사용하는 여러 모델을 만들어서 무언가 하겠다는 것
- 학습 데이터가 고정되어 있을 때, 그 안에서 샘플링을 통해 학습 데이터를 여러 개 만들고, 이를 통해 모델, metrics를 만드는 것
- 모델의 전체적인 불확실성(uncertainty)를 예측함
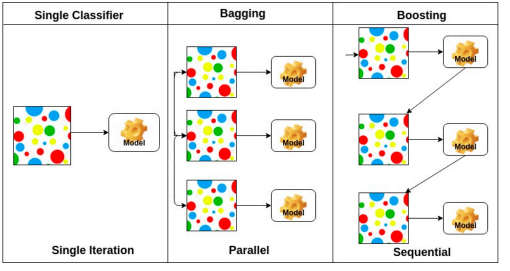
Bagging and boosting
- Bagging(Bootstrapping aggregating)( boostrapping)( 앙상블)
- 학습데이터를 여러 개 만들고, 독립적인 모델들을 여러 개 만들어 output을 내고, 그것들의 평균을 구하는 것
- Boosting
- 여러 개의 week learner를 합쳐, strong model을 만드는 것
- 앞선 week learner의 실수로부터 배움(sequence 형태)
Cross Validation
- 훈련 셋과 검증 셋을 분리는 하되, 검증 셋을 학습에 활용할 수 있는 방법은 없을까?라는 접근에서 나온 방법
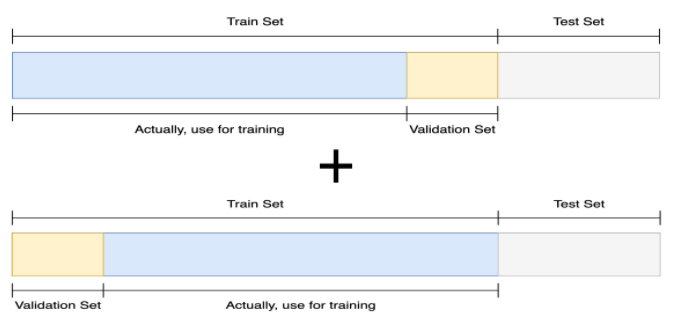
- Stratified K-Fold Cross Validation: K개로 Split시, Class의 분포를 고려하는 것
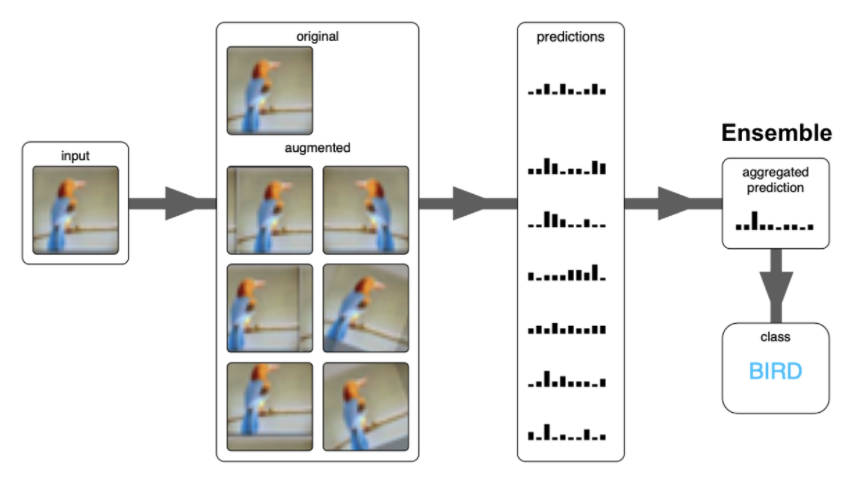
Test Time Augmentation(TTA)
- 학습할 때 데이터를 Augmentation하는 것이 아닌, 테스트 셋으로 모델을 테스트하거나 실제 운영을 할 때 들어오는 데이터를 augmentation하고, augmentation된 이미지들에 대해 개별 예측 한 후, 그 결과값들에 대하여 앙상블을 진행하여 최종 결과를 내보내는 것

AI Engineer : Lv 0