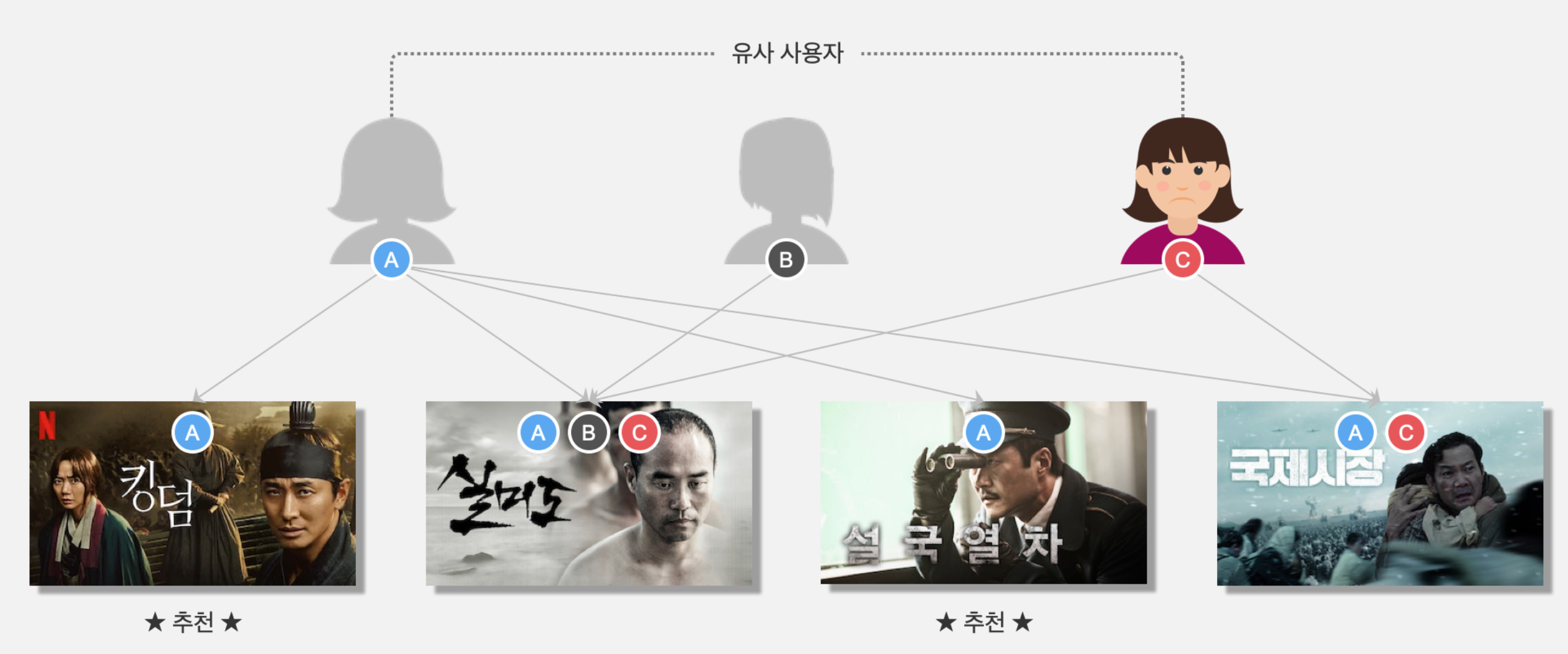
프로젝트 개요
“사용자의 영화 시청 이력 데이터를 바탕으로 사용자가 다음에 시청할 영화 및 좋아할 영화를 예측”
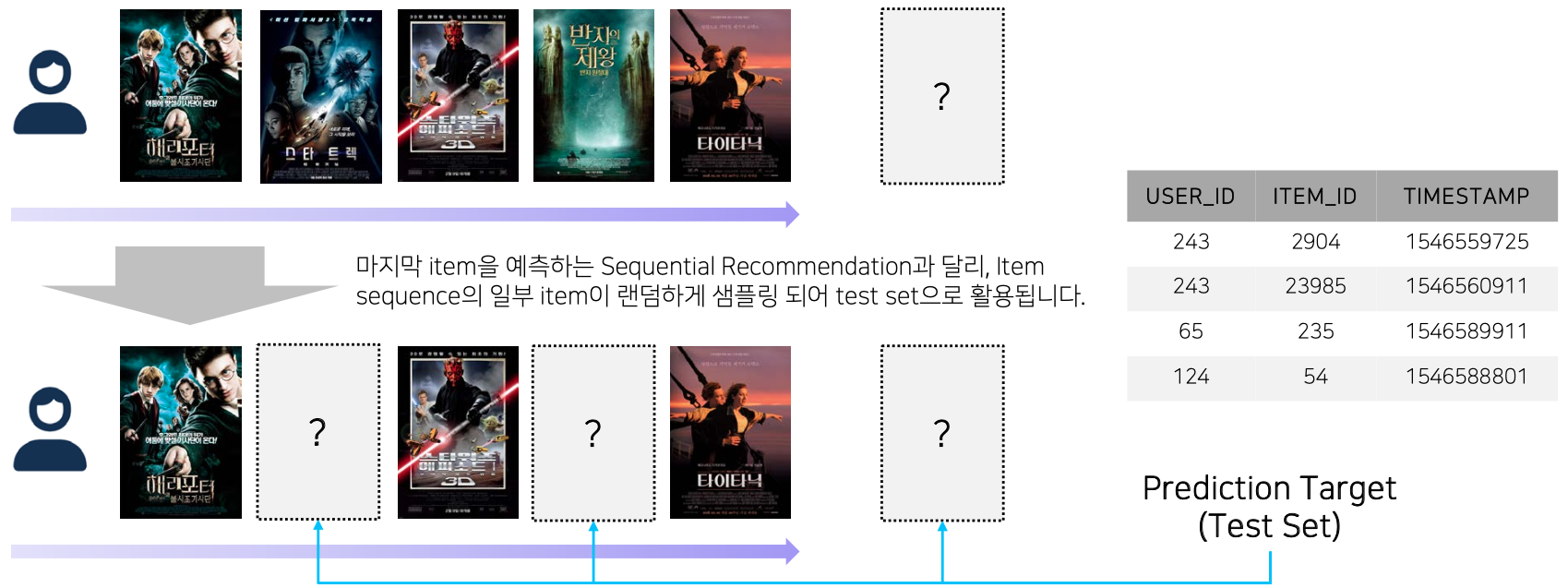
대회에서는 implicit feedback 기반의 sequential recommendation 시나리오를 바탕으로 사용자의 time-orderd sequence에서의 일부 item이 누락(dropout)된 상황을 상정합니다. 이는 sequence를 바탕으로 마지막 item만을 예측하는 sequential recommendation 시나리오와 비교하여, 보다 복잡하며 실제와 비슷한 상황을 가정하고 있습니다. 또한, 여러가지 아이템 (영화)과 관련된 side-information이 존재하기 때문에, 이것들을 어떤 식으로 효과적으로 활용할지도 중요한 포인트가 될 수 있습니다.
- input: user의 implicit 데이터, item(movie)의 meta데이터
- output: user별 10가지 아이템 추천
데이터 셋
- 입력 값: 31360명의 user와 6807가지 item의 상호작용 데이터
- Ml_item2attributes.json
- item과 genre의 mapping 데이터
- Dict{str:list}
- 5,154,471 행
- directors.tsv
- 영화 감독 데이터
- item : int, director : str
- 5,905 행
- genres.tsv
- 영화 장르 데이터
- item : int, genre : int
- 15,934 행
- titles.tsv
- 영화 제목 데이터
- item : int, movie : str
- 6,799 행
- train_ratings.csv
- 주 학습 데이터
- user_id : int, item_id : int, timestamp : int
- 5,154,471 행
- writers.tsv
- 영화 작가 데이터
- item : int, writer : str
- 11,307 행
- years.tsv
- 영화 개봉년도
- item : int, year : int
- 6,799 행
- Ml_item2attributes.json
- 출력 값: user별 10가지 아이템의 추천
개인 회고
목표
- (팀) 추천시스템에 대한 팀 전체의 기량을 향상시키기 위해, 다양한 심화 이론들에 대한 모델링을 각자 진행하고, 시도한 방법과 결과를 노션과 깃허브에 공유하는, 대회와 스터디의 장점을 융합한 형태의 협업을 진행한다.
- (개인) 추천시스템 관련 심화 논문을 읽고 이해하며, 이를 구현할 수 있는 능력을 함양하기 위해 나만의 모델링 코드를 구축하고, 다양한 실험 사이클(가설-검증)를 구성한다.
나는 내 목표를 달성하기 위해 무엇을 어떻게 했는가?
- 팁 단위 협업 방법 제시
- Git Flow, Notion, wandb, ...
- EDA 및 데이터 분석 적용(필터링)
- 영화를 본 유저들의 취향(장르) 흐름(year 및 week 기준)을 살펴 본 결과, 유저들의 취향은 크게 변하지 않음(변하더라도 다시 회귀하는 성향을 발견).
-> sequential한 모델이 의미가 있을까? -> 기본적인 CF 모델부터 살펴봄. - 활동시기가 유저마다 다름을 확인.
-> 유저별 활동시기 이후에 개봉한 영화들은 필터링시킴. - 영화추천 태스크의 흐름을 static/sequential로 나누어 예측.
-> static/seq 모델을 특정한 비율로 앙상블.
- 영화를 본 유저들의 취향(장르) 흐름(year 및 week 기준)을 살펴 본 결과, 유저들의 취향은 크게 변하지 않음(변하더라도 다시 회귀하는 성향을 발견).
- CF & 딥러닝 모델
- ALS 모델 구현 및 다양한 실험
- Neural Collaborative Filtering 모델 구현 및 다양한 실험
- Multi-VAE 모델 구현 및 다양한 실험
- Context 모델
- deepFM 모델 구현 및 다양한 실험
- Sequential 모델
- SASRec 모델 구현 및 다양한 실험
스스로 칭찬할 점은 무엇인가?
- 대회 초반, 대회 태스크를 먼저 고민하기 보다 팀 단위 협업을 어떻게 효율적으로 할 수 있는가를 먼저 고민하고, 좋은 팀 환경을 구축하려 노력했던 점을 칭찬하고 싶다.
- 필요한 태스크에 대해 정확한 문제 정의를 진행하기 위해 노력하였다.
- 추천시스템 모델들에 대한 이론을 추가로 공부한 뒤, 태스크별로 정리하는 작업을 가장 먼저 진행하여, 각 실험 태스크에 적절한 모델 설계를 진행하였다.
마주한 한계는 무엇이며, 아쉬웠던 점은 무엇인가?
- 실험에 대해서는 노션을 통해 효율적으로 협업하였지만, 팀원들의 실험 코드에 대한 인사이트는 많이 공유받지 못했다고 생각된다.
- 문제 정의와 모델 설계 등 너무 세세하게 실험을 설계하였던 점은 스스로 칭찬할 점이지만, 동시에 한 실험에 너무 많은 자원(시간 등)을 투자했다는 점은 아쉽게 느껴진다.
- 실험 설계 과정에서 EDA에 대한 비율이 조금 적었던 것 같다.
- 장기간 프로젝트에 대한 설계가 조금 미흡하여 팀 전체가 후반으로 갈수록 조금 느슨해졌던 것 같다.
한계/교훈을 바탕으로 다음 프로젝트에서 스스로 새롭게 시도해볼 것은 무엇인가?
- 다음 프로젝트에서는 깃 Issue와 PR을 적극적으로 사용하여 실험 코드에 대한 인사이트를 명확히 공유할 수 있도록 해야겠다.
- 팀 목표의 초점이 ‘점수 향상'에 맞춰진다면, 너무 세세한 실험 설계 보다는 빠른 가설-실험 사이클을 돌려보는 것도 좋은 대안일 수 있을 것 같다.
- 각 실험별로 충분한 데이터 분석이 필요할 것으로 보인다.
👉Github Link

AI Engineer : Lv 0