
다음, 한 끼
- 한 줄 소개: 개인화된 레시피 추천 서비스
- 관련 활동: Boostcamp AI Tedh
- 진행 기간: 2022/05/23 → 2022/06/12
- 기여: Modeling & Scheduling
- 개발 2022.05.23 → 2022.06.12
- 운영 2022.06.12 → 2022.06.15
- Skills:
Airflow,Docker,FastAPI,GCP,Linux,PostgreSQL,PyTorch,React.js,Wandb - Links
📜 서비스 내용
"당신의 다음, 한 끼는 무엇인가요?"
다음, 한 끼는 사용자의 레시피 사용 이력을 바탕으로 사용자 본인조차도 명시할 수 없는 다양한 요구사항들을 반영하고, 개인별로 필요한 추가적인 필터링을 통해 최적의 레시피를 추천해드립니다.
Project Objective
- 가지고 있는 식재료와 사용자의 이력을 바탕으로 레시피 추천
- 테마별 레시피 추천
- 사용자 계정 관리
🖥 개발 내용
EDA
- tf-idf를 이용하여 레시피의 (desc, step에서) 중요 특징을 추출
- Bert Sentence를 사용하여 조리 과정 전체를 Embedding하여 레시피 간 유사도를 측정
모델링
- Recbole 라이브러리를 통해 6개의 CF모델 적용
- BPR, MultiVAE, MultiDAE, CDAE, RecVAE, LightGCN
- Bert Sentence Embedding을 이용한 Bert2Vec 구현
- self-supervised Learning과 Item2Vec에 사용 가능
- 학습 및 inference 자동화
- 모델 학습, 학습 관리(Wandb), Google Cloud Storage에 학습 결과 전송, inference용 db관리, 학습완료 후 backend로 정보 전송 등을 구현
- 모델 학습부터 서빙을 위해 Google Cloud Storage에 저장하기까지의 과정을 자동화하는 api 구현(fast-api 사용)
스케쥴링 설계 및 적용
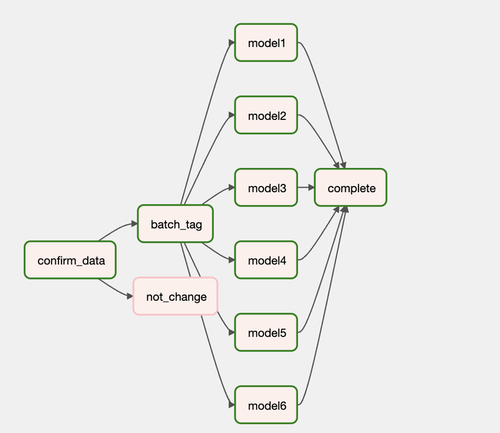
- 모델링 파트의 '학습 및 inference 자동화'를 airflow로 적용할 수 있도록 설계
- airflow를 통해 모델링쪽 자동화를 컨트롤할 수 있도록 구현
- 새로운 학습시 'batch tag 업데이트 및 학습을 위한 데이터 다운' 요청
- '모든 모델 학습' 요청
- 학습 후 '결과물 Storage로 전송 및 Top N모델(offline 평가 기준) 찾기' 요청
평가 전략 설계 및 적용
- 첫 번째 발의 (실패): Bert Sentence Embedding과 그래프 알고리즘을 이용하여 비슷한 아이템을 동시에 정답으로 처리하는 Offline-Evaluation 제안
- 상호작용 대비 아이템 수가 너무 많은 것을 고려하여, 위와 같은 평가 전략을 제시하였으나, 적용 전과 큰 차이가 없었음.
- 만약, 유의미한 차이가 있었다고 해도 Serving bias를 해결할 수는 없었음.
- 두 번째 발의 (적용): Test-Time Evaluation 제안 및 적용
- 요약
- [Naver Deview 2020: 추천시스템 3.0]에서 영감을 받아, offline-evaluation 이후 online-evaluation에서도 지속적으로 모델의 성능을 평가하여 서빙에 반영할 수 있도록 함(N개의 모델에 대하여 Multi-Armed Bandit 알고리즘 적용)
test 결과를 지속적으로 반영하여 모델들의 개별 inference traffic을 나눔으로써 전체 시스템의 성능을 향상시킬 수 있음.
- [Naver Deview 2020: 추천시스템 3.0]에서 영감을 받아, offline-evaluation 이후 online-evaluation에서도 지속적으로 모델의 성능을 평가하여 서빙에 반영할 수 있도록 함(N개의 모델에 대하여 Multi-Armed Bandit 알고리즘 적용)
- 설명(영상)
Test-Time Evaluation (영상) - 설명(글)
Test-Time Evaluation (글)
- 요약
💡 회고
스스로 칭찬할 점은 무엇인가?
- 정확한 Evaluation을 하기 위해, 새로운 방법들을 다양하게 연구/적용해보았다.
- Bert2Vec 구현에서 기존 라이브러리(sklearn)를 사용하여 대용량 데이터에 대한 pairwise 유사도 계산시 메모리가 감당하지 못하는 문제 & 계산 속도가 너무 느린 문제를 인지하고, Pytorch 기반 batch 방식으로 코드를 새롭게 구현하여 해결하였다.
- 많은 노력이 들어갔더라도 마땅한 방법이 아니라고 판단되면 과감히 포기하고, 새로운 방법을 찾기 위해 노력하였다.
- 설계했던 Task들을 원하는 수준만큼 구현할 수 있도록 노력하였고, 실제로 적용하였다.
- 팀원들이 내 작업들의 상황을 알기 쉽게 하기 위해 작업 중간 중간에도 꼼꼼히 README와 커밋 메시지를 남기려 노력하였다.
마주한 한계는 무엇이며, 아쉬웠던 점은 무엇인가?
- 시간이 부족하여 cf 외 다른 모델들을 적용하지 못했던 것이 너무 아쉽다.
- 코드 리뷰를 통해 내가 코드를 너무 복잡하게 짜고 있다는 것을 느꼈다. 코드 짜는 역량에 대한 개선이 필요할 것 같다.
- 모르는 것이 있을 때 빠르게 팀원에게 도움을 요청하지 못한 점이 아쉽다.
- 작업 중 다른 task의 세부 사항을 놓쳤던 적이 많았던 것 같다.
한계/교훈을 바탕으로 다음 프로젝트에서 스스로 새롭게 시도해볼 것은 무엇인가?
- 이번 프로젝트에서 마주했던 한계들은 대부분 ‘코드를 짜는 역량'이 다소 부족해서 벌어진 것 같다고 느껴진다. 파이썬과 코딩 관련 지식을 더 깊이 공부하며 부족한 역량을 채울 수 있도록 노력해야겠다.
- 팀 단위 프로젝트에서 팀원들과 더 많이 커뮤니케이션 하여 서로의 의도를 정확히 인지하고 작업해나가야겠다.
- 작업에 들어가기 전, 맡은 테스크를 스케줄링하여 더 효율적인 작업을 할 수 있도록 해야겠다.
👀 서비스 화면
1. 상호작용 이력이 없는 유저(테마 기반 추천)
demo1.mp4
2. 상호작용 이력이 있는 유저(모델 기반 추천)
demo2.mp4

AI Engineer : Lv 0