
fork()의 오버헤드 문제
이전 글에서 자식 프로세스를 Create하는 것에 대한 과정을 살펴봤음. 여기서 중요한 것은 프로세스를 생성할 때(fork 할 때) 2가지의 오버헤드가 생길 수 있다는 것임.
- 부모 프로세스의 이미지를 복사하는 데 드는 오버헤드
- 부모 프로세스의 PCB를 복사하는 데 드는 오버헤드
이러한 오버헤드를 줄이기 위해 다음과 같은 방법을 이용할 수 있다.
PCB 복사 시 오버헤드 줄이기 - Thread와 clone()
PCB에는 프로세스 관리를 위한 다양한 리소스가 들어있다. 이를 크게 6가지 구조로 구분지으면 다음과 같다.
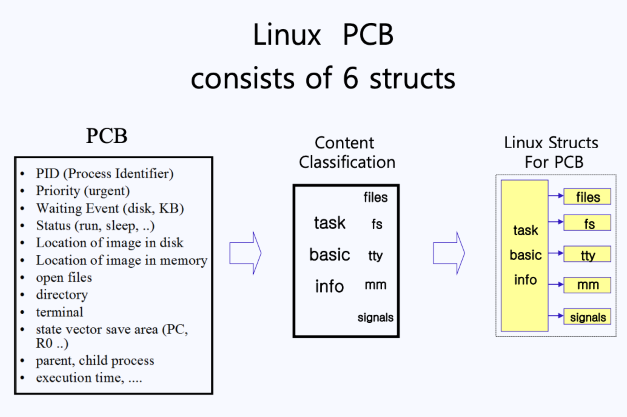
- task basic info
- files : 프로세스가 오픈한 파일에 대한 정보
- fs : 프로세스가 접근 중인 file system에 대한 정보
- tty : 프로세스가 사용 중인 터미널 정보
- mm : 사용 중인 메인 메모리에 대한 정보
- signals : 여러 신호 정보
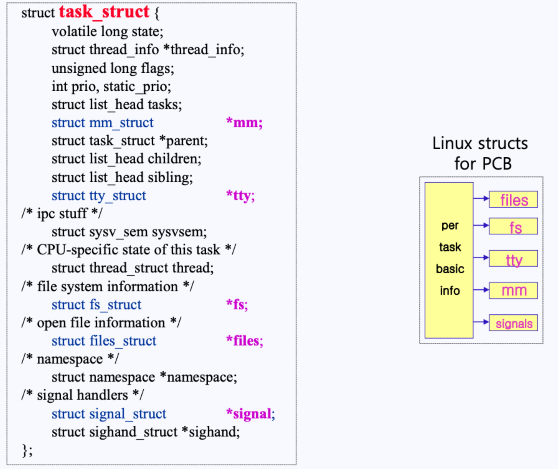
- 위와 같이 task_struct라는 구조(리눅스가 가지고 있는 PCB) 안에 이러한 PCB 데이터를 포함한 여러 데이터들이 들어있다.
그렇다면, 왜 리눅스는 PCB 정보를 왜 하나가 아닌 6개의 구조로 관리하는 것일까?
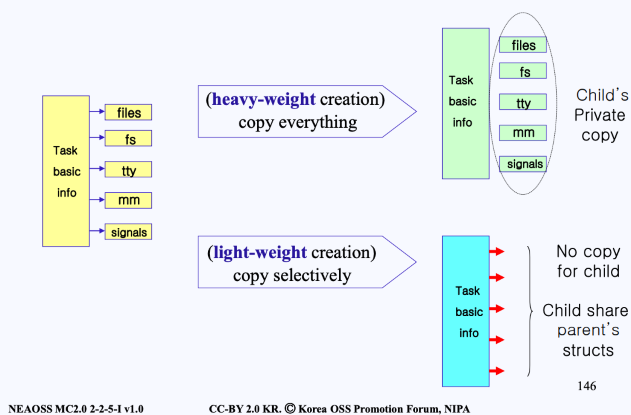
- 그림의 위쪽 heavy-weight creation과 같이 모든 구조들을 복사한다면, read & write가 되어 상당한 부하가 걸리게 된다.
- 초기 리눅스는 이런 방식있다고 함
- 막상 시스템을 만들다 보니 부모 프로세스가 가지고 있는 tty(터미널)이나 fs(파일 시스템)는 자식이 가지고 있는 것과 동일한 경우가 많다는 것을 알게 되었고,
- 따라서 아래쪽 light-weight creation 방식이 제안됨
- 부모 프로세스가 가지고 있는 tty(터미널)이나 fs(파일 시스템)등의 주소를 자식과 공유하는 방식으로 생성하는 것
- 즉, 부모와 자식 프로세스가 다르게 사용할 것들만 선택적으로 copy하자는 것
→ 리눅스는 PCB를 6개의 구조로 나눔으로써 부모 PCB 중 일부를 공유할 수 있게 하였고, 이를 통해 오베헤드를 줄이게 됨
예를 들면 다음과 같이 현재 메인 메모리, 4개의 CPU, 그리고 이들의 통로인 버스가 있다고 가정하자.
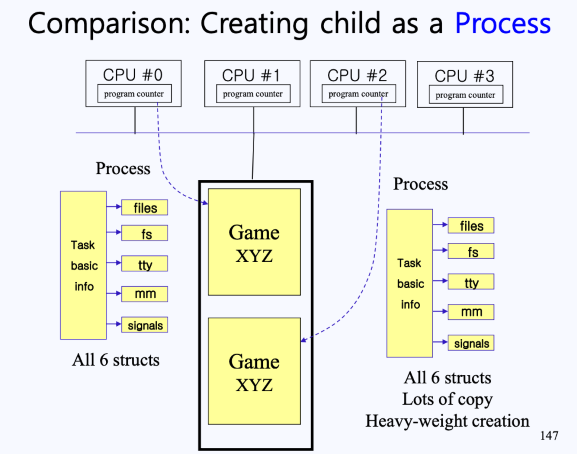
- 이 상황에서 Game XYZ라는 프로그램이 하나 돌아가고 있는 상태이다. 이 게임은 현재
CPU #0에서 실행되고 있으며, Game XYZ 프로세스를CPU #0의 PC가 가르키고 있다. - 이러한 상황에서 전통적인 방법으로 Game XYZ의 자식 프로세스를 생성하려면, 위 그림과 같이 PCB를 통쨰로 복사해야 했고, 이는 오버헤드로 직결된다.
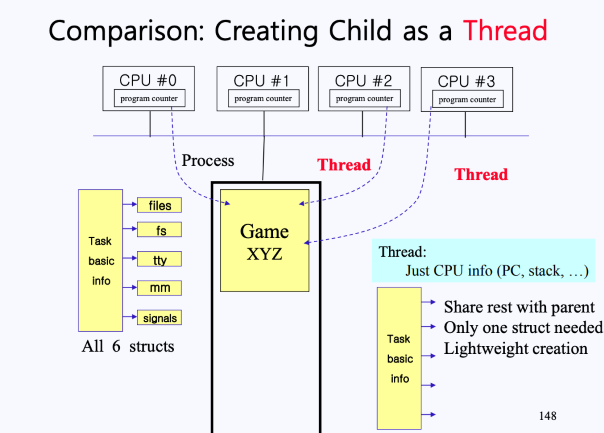
- 따라서 위 그림과 같이 PCB의 모든 정보가 아닌
Task basic info만 복사하고, 나머지 구조체(files, fs, tty, mm, signals)들은 부모의 것과 공유하게 된다. - 즉, 새로운 프로세스로 생성하는 것이 아니라 Thread를 만드는 것이다.
- ** 프로세스는 운영체제로부터 자원을 할당받는 작업의 단위이며, 스레드는 프로세스가 할당받은 자원을 이용하여 실행하는 단위이다.
- 스레드는 Task bask info 파트만 복사를 하고, 나머지는 부모 프로세스와 공유한다. 이떄, Task bask info 안에는 state vector save area가 있기 때문에 각 스레드마다 별도의 PC와 Stack Pointer를 갖고 있을 수 있는 것이다. 또한 각 스레드가 각자의 Stack을 갖고 있기 떄문에 개별적으로 다른 함수들을 호출하면서 실행될 수 있다.
이러한 방식은 단순히 복사를 하는 fork()가 아니라 clone()이라는 시스템 콜을 사용한다.
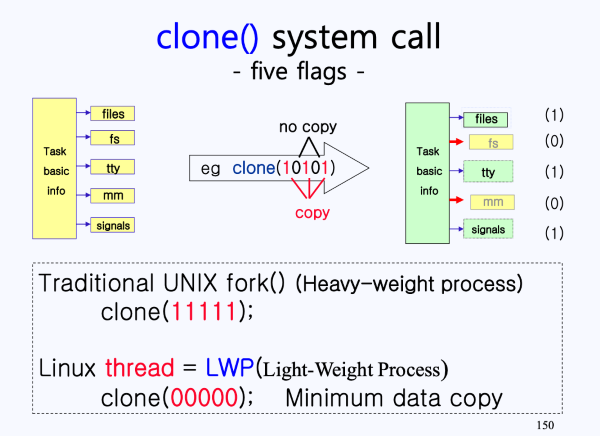
sys_clone()이 호출되면, 내부적으로 binary bit 5개를 함께 보내게 된다.- binary bit 5개는
ask basic info외 나머지 구조체(files, fs, tty, mm, signals)를 의미함 - binary bit은 1이면 복사, 0이면 공유한다는 의미를 내포하고 있음
- binary bit 5개는
이미지를 복사 시 오버헤드 줄이기 - CoW
- 이때, 이미지는 PCB를 실행하기 위해 필요한 Code, Stack, Data 등을 포함하는 것이다.
리눅스 엔지니어들은 child 생성 시 부모의 이미지를 그대로 복사해오는 것이 아니라 page mapping table만 복사해오도록 구현하여 오버헤드를 줄였다.
- 자식 프로세스는 이미지를 부모 프로세스로부터 복사하여 가져오는 것이 아니라 부모 프로세스의 이미지를 가르키는 page mapping table만 복사해서 가져오게 된다.
- 자식 프로세스는 이러한 page mapping table을 가지고 실행을 하며, 명령어들을 수행시킬 동안 page mapping table을 부모와 같이 사용할 수 있게 된다.
페이지 테이블 : 페이징 기법에 사용되는 자료도구로, 프로세스의 페이지 정보를 저장하고 있는 테이블임.
- 테이블의 내용은 해당 페이지에 할당된 물리 메모리의 시작 주소를 담고있음
이러한 방식은 read()만 사용할 떈 문제가 없지만, write()를 해서 무언가를 쓰게 된다면 문제가 발생할 수 있다.
- 이를 해결하기 위해 만약
write()를 하게 되는 경우, 해당하는 페이지만 부모와 자식에게 하나씩 복사본을 따로 만들어주는 방식으로 해결하였다. - 이러한 방식을 Copy on Write라고 부른다
CoW를 fork() 과정에서 살펴보자.

- 먼저 부모 프로세스에서 fork()를 하면 정보를 전부 복사하는 것이 아니라 CoW 방식으로 page mapping table만 가져오게 된다.
- 이후
wait()과정이 일어나며, CPU는 자식 프로세스가 넘겨받게 된다. - 이후 자식 프로세스는
fork()가 일어난 곳으로 가서 자신의 일을 하게 된다.
그러나 만약, 부모가 fork()를 하고 돌아와서 바로 wait()를 하지 않고, write()를 하게 된다면 문제가 발생한다.
- 이렇게 된다면 자식 프로세스가 CPU를 점유하기 전에 페이지 테이블에 변화가 생기는 것이다.
- 이는 계속해서 CoW를 만들어 낼 것이지만, 어차피 자식 프로세스가 exec()를 하게 되면 덮어씌어지기 때문에 결국 의미 없는 복사를 한 것이 된다.
- 즉, 비효율 문제(오버헤드)가 또 발생한다는 것이다.
이를 해결하기 위해 다음과 같은 새로운 방법을 사용한다.
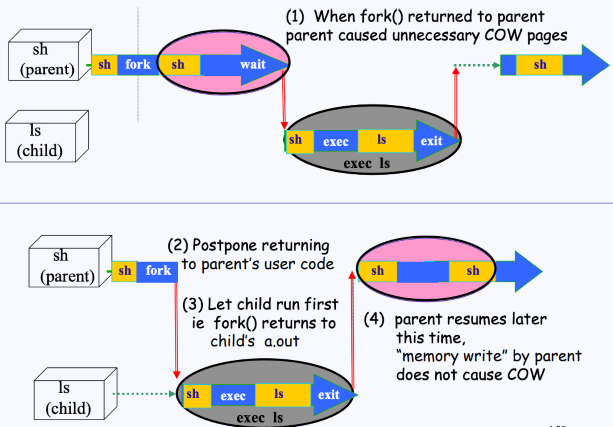
- 부모 프로세스가
fork()를 호출해서 자식 생성을 끝내고,fork()를 했던 곳으로 돌아가려하고 있다. - 이때
fork()안에서 자식 프로세스의 CPU 우선순위를 확 높여버린다.- 이렇게 우선순위를 높이는 이유는, Kernel-mode에서 User-mode로 돌아갈 때에는 우선순위가 제일 높은 프로세스에게 CPU를 넘겨주기 떄문임
- 이렇게 되면 CPU가 부모한테 돌아가는 것이 아니라 바로 자식 프로세스에게 가게 된다.
- 자식 프로세스는 CPU를 받아 바로
exec()를 하게 된다.
- 자식 프로세스는 CPU를 받아 바로
- 이후에 부모 프로세스가 CPU를 받게 되며,
fork()에서 돌아오고 본인이 할 일을 하게 된다.
Kernel Thread
위에서 말했던 light-weight creation 내용을 복기하면 다음과 같다.
- 부모 프로세스가 가지고 있는 tty(터미널)이나 fs(파일 시스템)등의 주소를 자식과 공유하는 방식으로 생성하는 것
- 즉, 부모와 자식 프로세스가 다르게 사용할 것들만 선택적으로 copy하자는 것 → 즉, 자식 프로세스를 생성하는 것이 아니라 자식 스레드를 생성하는 것
그렇다면 커널은 무엇인가?
-
커널은 Memory resident한 독립된 C 프로그램
** Memory resident: 부팅되고나서부터 꺼질 때까지 항상 메모리에 상주하고 있는 것
스레드와 커널에 대해 알아보았으니 이제 Kernel Thread에 대해 알아보자.
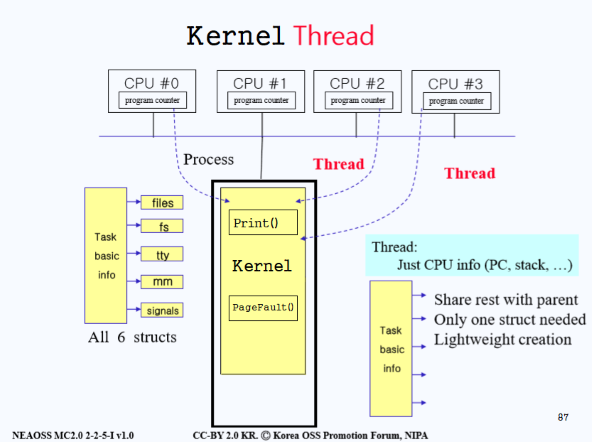
- 컴퓨터가 부팅되고, 커널이
main()이 실행 된 이후, 커널 프로세스가 동작하다가 시스템 콜clone()을 호출하게 되면 자식 프로세스가 생기는데, 이렇게 만들어진 자식 프로세스를 커널 스레드라고 한다.- 커널 프로세스는 커널 공간에서만 실행되는 프로세스이다. 대부분 커널 스레드 형태로 동작한다.
- 커널 스레드는 리눅스 시스템 프로그래밍에서 데몬과 거의 비슷한 일을 하는데, 데몬과 커널 스레드는 백그라운드 작업으로 실행되면서 시스템 메모리나 전원을 제어하는 동작을 수행한다.
- 커널 스레드는 유저 영역과 시스템 콜을 받지 않고 동작한다. 이 점이 데몬과 커널 스레드의 차이점이다.
Process State
프로세스 상태는 기본적으로 running, waiting, ready로 이루어져 있다.
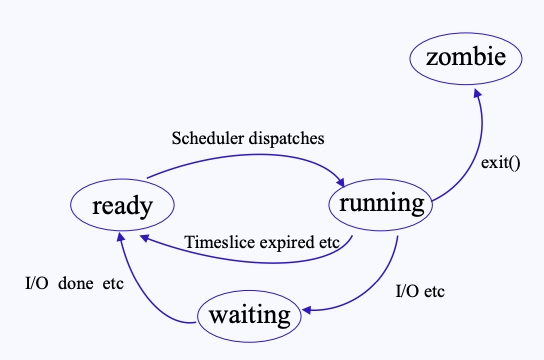
- running : CPU에 의해 프로세스가 실행되고 있는 상태
- running 상태에서 나가지는 경우는 다음과 같다.
- Preemption : Ready State로 돌아가는 경우임. 프로세서 스케줄링 등으로, 프로세서를 잃고 다시 프로세서 할당을 대기하는 상태.
- wait / sleep : 입/출력 등의 특정한 Event 를 기다리게 된다. 할당받았던 프로세서를 반납하고, asleep(blocked, waiting) 상태가 되어I/O 자원 등 필요한 자원을 할당 받기를 기다린다.
- running 상태가 되었다고 해도 무한정으로 CPU를 점유하는 것은 아님. 프로세스는 특정 시간동안만 CPU를 할당받게 되고, 시간이 끝나면 ready queue의 맨 뒤로 돌아가게 됨.
- running 중
exit()시스템 콜이 호출되면 좀비 상태가 됨- 좀비 상태가 되면 PCB를 제외한 모든게 없어지게 됨
- child로 생성된 프로세스가
exit()되면, 해당 프로세스의 부모 프로세스가 자식의 PCB 정보를 보고, 자기 자식 말소를 시작함. 말소 작업이 다 끝내기 전까지는 좀비 상태를 유지함
- running 상태에서 나가지는 경우는 다음과 같다.
- waiting : 프로세서 외 다른 자원을 기다리는 상태 (e.g. I/O 자원).
- 다른 자원을 받는 것이 끝나면 ready 상태로 들어간다.
- ready : (현재는 CPU가 할당되어 있지 않지만) CPU 할당을 받으면 바로 Running State로 들어가 실행을 할 수 있는 상태
Kernel Scheduling
리눅스에서는 CPU가 어떤 방식으로 할당되는지(Scheduling)를 알아보자.
Scheduling Algorithm
먼저 스케줄링 알고리즘들을 살펴보자

- 위와 같은 형태의 Ready Queue가 있다고 하자. Ready Queue에는 실행할 수 있는 작업들이 위 그림처럼 순차적으로 연결되어 있게 된다.
- 하지만, 이런 형태는 멀티 프로세서 환경에서 CPU의 개수가 증가하게 되면 레디큐에 연결되어 있는 PCB도 엄청나게 많아 질 것이고,
context_switch()를 실행할 때마다 모든 내용을 뒤져서 우선순위가 높은 프로세스를 골라내야하는 작업은 굉장히 비효율성을 야기할 것이다.
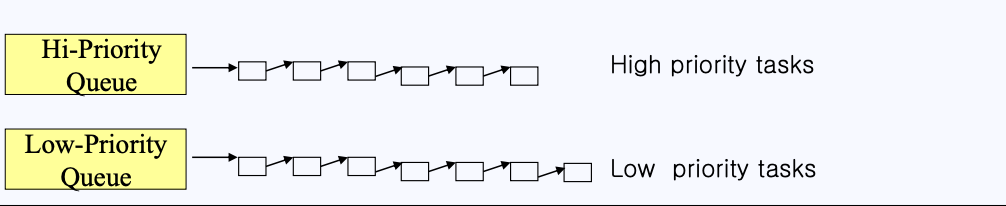
- 위와 같은 비효율성을 없애기 위해 단순한 레디큐가 아니라 높은-우선순위 큐 / 낮은-우선순위 큐로 나누게 되었다.

- 더 나아가 여러 개의 우선순위 큐를 만들어 더욱 더 효율적이게 동작하게도 만들게 되었다.
- 하지만 위 주황색 큐를 들여다보면 중간에 비어있는 큐가 보이게 된다. 이런 큐까지 탐색한다면 이 역시도 비효율성을 야기할 수 있다.
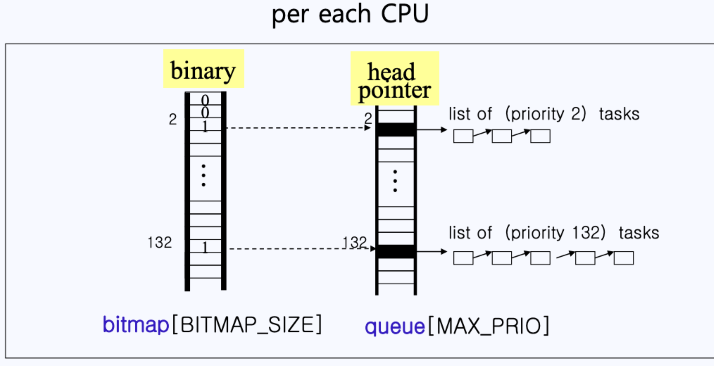
- 따라서 위와 같이 바이너리 배열을 하나 만들게 된다.
- 바이너리 배열에서 0은 해당 인덱스의 큐가 비어있다는 뜻이고, 1은 해당 인덱스에 내용물이 있다는 뜻이다.
- 유닉스에서는 이 바이너리 배열을 비트맵이라고 부르며, 이를 통해 탐색 속도를 향상시킨다.
- ex)
- 예를 들어 위 그림과 같이 binary[2]가 1이라면,
- 2의 우선순위를 갖는 task가 존재한다는 것을 바로 알 수 있게 됨
- 이렇게 비트맵과 큐 배열을 동시에 포함하고 있는 구조체가 바로 priority array(우선순위 배열)이다.
- 이러한 우선순위 배열은 각 cpu마다 두 개씩 존재한다.
우선순위 배열과 스케줄링
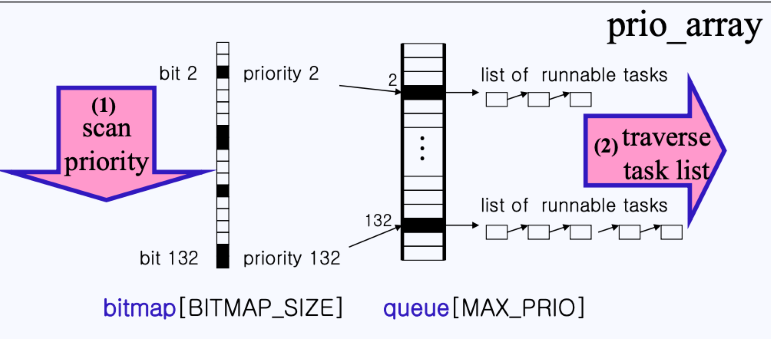
- bitmap을 차례로 스캔한다.
- 만약, bitmap이 1로 세팅(내용물이 있음)된 인덱스가 있다면, 해당 인덱스에 해당하는 queue의 task list를 순회하며 cpu를 할당해준다.

-
빨간색 task는 cpu가 할당되어서 실행중이다. 이는 현재 빨간색 task가 Active array에 있으며 해당 task는 timeslice가 남아있는 상태임을 의미한다.
a. 만약, timeslice가 0이 된다면, Expired array로 빠지게 되고
b. Expired array에서 자기 우선순위에 맞는 리스트에 다시 삽입되며
c. 다시 자신의 차례를 기다리게 된다.
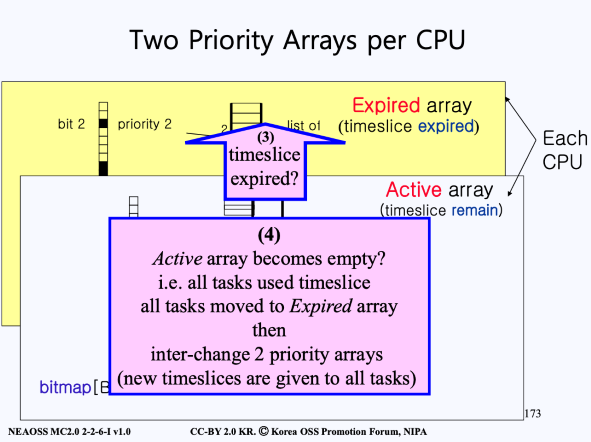
- 모든 task에 (3)을 반복하다보면, 수행을 끝내지 못한 task들이 전부 Expired array로 모이게 된다. 이때 Expired array에 모인 모든 프로세스들은 한 번에 time slice를 재배정 받게 되며, Expired array영역은 Active 영역이 되고, Active 영역은 Expired 영역으로 바뀌게 된다.
→ 각 CPU는 두 개의 우선순위 배열을 가지고 있으며, 해당 스케줄링은 의 시간복잡도를 가진다.
Kernel Preemption
컴퓨터의 일반적인 구조를 살펴보자.
- CPU에는 저장 공간이 많이 없고, 비싸기 때문에 CPU에 많음 데이터를 저장할 수는 없음
- 이 떄문에 일반적인 컴퓨터 시스템에서 연산은 CPU에서 이루어지지만, 데이터는 저장소에 저장되게 됨
이러한 컴퓨터의 구조는 다음 예시와 같은 문제를 야기할 수 있다.
- 두 개의 프로세스(A, B)가 존재하고, 이 두 프로세스는 한 개의 변수(x)를 공유하고 있다.
- A프로세스는 변수에 1을 더하는 작업을 한다.
- B프로세스는 변수에 1을 더하는 작업을 한다.
- 변수 x의 초기 값은 1이다.
- 이때, A프로세스와 B프로세스는 동시에 CPU를 할당받아, 공유되고 있는 변수 x에 각자의 작업을 하고 둘 다 저장한다고 해보자
- A프로세스에서 +1을 하였고, B프로세스에서 +1을 하였지만, 결국 저장되는 값은 2가 될 것이다.
- A, B 프로세스 모두 1이라는 x값을 불러와서, 1을 더한 후, 이를 기록했기 때문
- 즉, 두 번의 덧셈연산이 제대로 동작하지 않은 것이다.
이처럼 프로세스 간 공유되는 메모리에 접근하는 영역을 critical section이라고 부르며, critical section을 동시에 접근하는 일은 수행되어선 안 된다.
- 즉 한 순간에, 하나의 프로세스만이 critical section에 접근해야 한다는 의미이다.
- 이러한 것을 Mutual Exlusiom(상호 배제) 원칙이라고 부른다.
Mutual Exlusion(상호 배제)
유닉스는 이러한 상호 배제의 원칙을 위해 지난 40여년 간 아주 단순하게 다음과 같은 방법을 사용해왔다.
- Kernel-mode인 경우에는 CPU를 빼았지 않고, User-mode인 경우에만 CPU를 빼았는다,
- 즉, 커널에 있을 떈 CPU Preemption을 고려하지 않아도 된다.
하지만 위와 같은 방법을 사용하게 된다면, 정말 중요한 작업이 도중에 발생하더라도 모드 비트가 Kernel-mode에 있다면 CPU를 뻇을 수 없기 떄문에 중요한 작업을 빠르게 처리할 수 없게 된다는 문제가 발생한다.
- 이와 같은 문제는 실시간 컴퓨팅(real-time system)과 같은 빠른 처리와 빠른 전환을 요구하는 시스템에서는 매우 부적합함.
- ** 실시간 컴퓨팅 : 사용할 수 있는 자원이 한정되어 있는 상황에서 작업 수행이 요청되었을 때, 이를 제한된 시간안에 처리해 결과를 내주는 것을 말함
이에 리눅스 엔지니어들은 다음과 같은 방법으로 이러한 문제를 해결하게 된다.
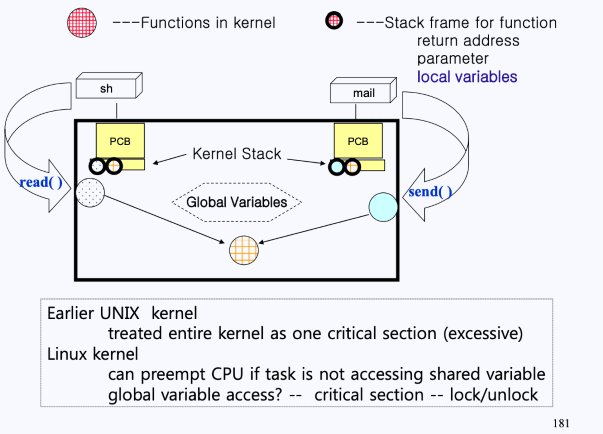
- 리눅스에서는 공유된 변수에 접근할 때 Lock을 거는 시스템이 있음
- lock이 걸려있다면, Kernel-mode건 아니건 CPU를 빼았는 일은 발생하지 않음
- 그러나 unlock이라면, Kernel-mode임에도 CPU를 다른 프로세스에 할당하는 것이 가능
리눅스의 lock 시스템은 다음과 같은 로직으로 구현된다.

- preempt_count - 모든 thread 마다 존재
- global 변수에 접근할 때마다 preempt_count 개수를 증가시킨다.
- 즉, 해당 스레드가 접근 중인 global 변수의 개수(lock의 개수)라고 볼 수 있다.
- 접근이 끝나면 count를 감소시킨다.
- need_resched
- 만약 CPU를 빼았으러 왔는데 preempt_count가 0이 아니라 못 뻈었다면, “지금 나 급한 일이 있어서 왔는데, 못 뻈고 기다리고 있어”라는 표시를 해주는 용도로 사용된다.
Reference
