FastSpeech
FastSpeech는 attention model같은 autoregression TTS method가 아닌, non-autoregression TTS이다. end-to-end TTS method에 큰 영향을 주었다.
end to end 는 통합 신경망을 거쳐 문자열 혹은 단어열을 인식하는 음성인식 방법이다.
이러한 점은 추론시간을 좀 더 빠르게 만들어 주어 TTS 모델의 변화에 큰 영향을 미쳤다. 즉 RNN으로 구성되지 않기 때문에, AT(autoregression transformer)의 한계점을 무시할 수 있는 것이다. 아래는 AT의 구조이다.
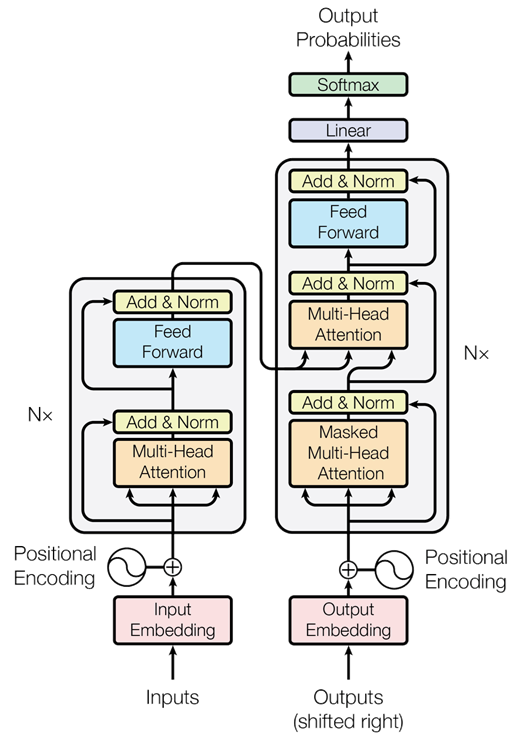
AT는 Nx 만큼 순환하면서 학습하게 된다. 순환 신경망(RNN)과 같은 구조를 띄며, 이는 각각의 단어를 학습시킬 때 병렬적으로 학습시킬 수 없게 된다. 이전의 단어를 학습시켜야만 이전의 것을 참고해서 학습시킬 수 있기 때문이다.
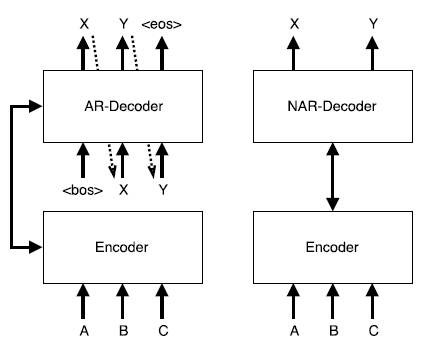
아래의 그림에서 왼쪽은 AR의 구조이고, 오른쪽은 Non AR의 구조이다. 이런 구조를 띄면서 NAR-Decoder가 속도가 더 빠른 것이다.
그러면 어떻게 NAR-Decoder는 이를 병렬적으로 처리 할 수 있을까?
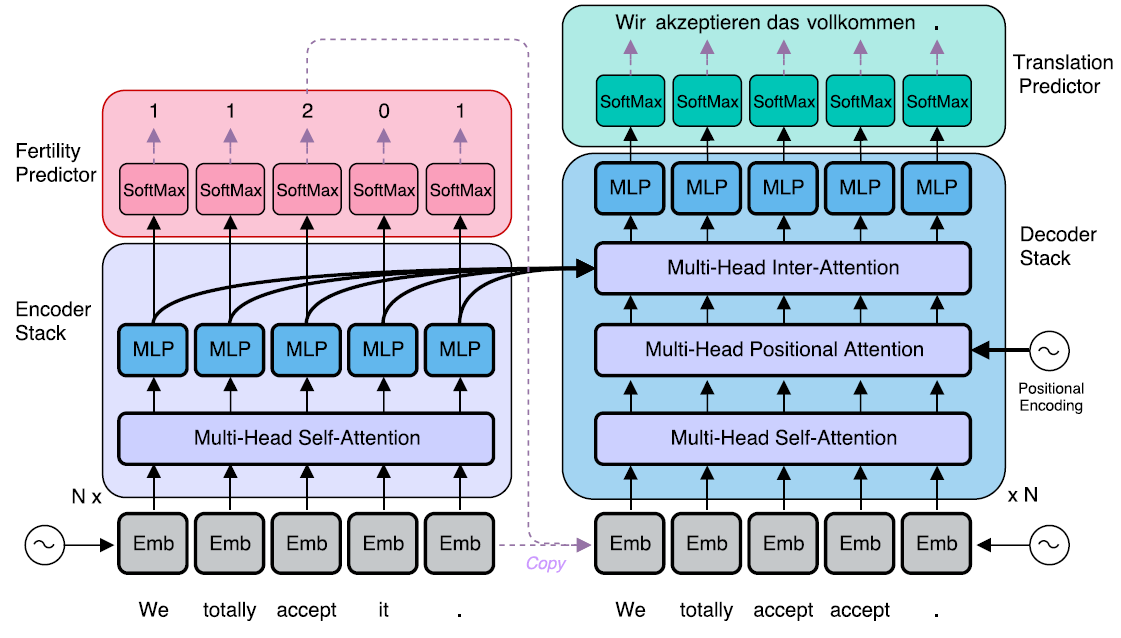
여기에서는 decoder에 들어갈 Embedding된 내용과 인코더에 들어갈 내용이 같다. 원래는 encoding 후에 decoding이 일어나야 해서 decoder의 target sequence 즉, 입력되는 문자열의 길이가 달라야 한다. 근데, 문자열을 그대로 복사해서 넣으면 길이가 같아서 문제가 된다. 그래서 여기에서는 delay를 이용해서 문자열이 넣어지는 시간을 늦춰서 target sequence를 T로 일정하게 바꾼다고 한다. (어렵다..)
우리는 fastspeech에서 fast가 non-autoregression에서 왔다는 것만 알면 된다. 병렬적으로 문자열을 훈련시키니 훨씬 빠른 것이다. 이를 확장시킨 방법이 바로 fastspeech2이다.
Fastspeech2
fastspeech는 좋아보이지만 문제점이 있다. 두 가지를 대표적으로 들 수 있는데, 첫번째로 two stage teacher-student training pipeline 이 굉장히 복잡하다.
teacher-student training pipeline은 Knowledge distillation에서 나온 것인데, 정의는 다음과 같다.
미리 잘 학습된 큰 네트워크(Teacher network)의 지식을 실제로 사용하고자 하는 작은 네트워크(Student network)에게 전달하는 것
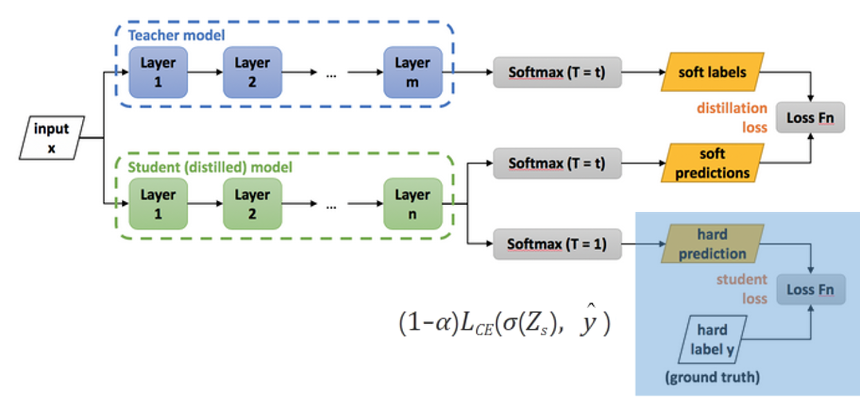
이런 구조를 의미한다. 즉, 큰 네트워크 (Layer가 많고 데이터가 많은) 네트워크에서 이미 훈련을 해서 나온 결과값과 Student에서 나온 예측한 데이터의 차를 loss function으로 이용했다.
또한 student model의 데이터를 ground truth(실제값)와 한번 더 비교하여 loss function을 구한다.
여기서 loss function은 cross entropy를 이용하는데, 파란색 영역이 왼쪽 항을 의미한다.

장점 중 하나는 큰 네트워크로 작은 네트워크를 훈련시키기에 정확하지만 시간이 오래걸리지 않는 모델을 만들 수 있다는 것이고,
단점은 큰 네트워크를 훈련시킬 때의 시간이 많이 들어가면 처음의 훈련시간이 길다는 의미이다. 또한, 과정이 굉장히 복잡하다..
그리고 여기서 두번째 문제점이 나오는데, teacher student model때문에 teacher과 student의 정보가 비교될 때 information loss가 극심하다는 것이다.
그래서 fastspeech2는 이 방법을 없애 버렸다. teacher-student model을 쓰는게 아니라, 바로 ground-truth mel-spectrogram과 바로 비교해서 loss function을 구하는 것이다. 즉 위 그림에서 파란색 영역만 해서 cross entropy를 구한다는 것이다.
갑자기
mel-spectrogram은 어디서 나왔을까.
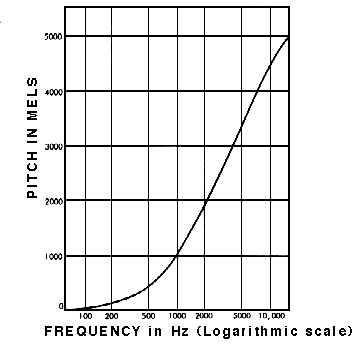
우리가 speech를 훈련할 때fastspeech에서도decoder로mel-spectrogram을 이용하였다. 이는 목소리의signal, wave에서 차원을 늘려,spectrum으로 확장 시킨 것을 아래의mel-scale그래프에 넣어서 만든 것이다.
이 덕분에 목소리가 각자 다른 소리 크기,Hz를 가지고 있어도mel-spectrogram decoder을 통해서 데이터를 정규화 시킬 수 있는 것이다.
참고자료
이렇게 ground-truth를 이용하면, teacher와 비교해서 얻은 information loss를 없앨 수 있다. 그리고 처음 나오는 대문자의 억양에 대한 품질을 높일 수 있다고 한다.
이는 어떻게 대문자 억양을 표현할 수 있다는 지 모르겠지만, 뇌피셜로는 information loss가 없기 때문에 문장 그대로 훈련을 해버려서 소문자 대문자 구분이 없었던 TS model과는 달리 억양이 살아난 것으로 해석했다.
세번째 문제점은 위에서 말했던 teacher model의 attention map이 말하는 시간(duration)에 대해서 충분히 정확도를 가지지 못했다는 것이다. 중간에 말하다가 끊기고, 단어가 생략되고, 옹알이(babble) 가 계속 되는 one-to-many mapping problem이 일어난 것이다.
그래서 fastspeech2는 정확도를 높이기 위해 Variance Adaptor을 이용하기로 했다.
Variance Adaptor
Variance가 높을 수록 데이터는 model과 너무 가까워지는overfitting이 일어날 수 있다. 여기에서의variance adaptor는underfitting도 아니고overfitting도 아닌 적당한 구간을 의미한다.
또한 분산을 이용해서 데이터 처리를 하는 것의 의미를 담고 잇을 것이다.
TTS에서 fastspeech2가 fastspeech와 가장 큰 다른 점은 바로 Variance Adaptor을 가지고 있다는 것이다.
Variance Adaptor는 말 그대로 여러 분산 데이터를 통해서 정확한 Speech를 예측한다는 의미이다. 원래는 Text만으로 예측을 하자는 것인데, feature을 여러 개를 추가하면 좀 더 정확한 Speech를 얻을 수 있다. feature은 pitch, energy, duration 정도가 있다. 그래서 이 Variance Adaptor의 구조는 다음과 같은 이미지를 가지고 있다.
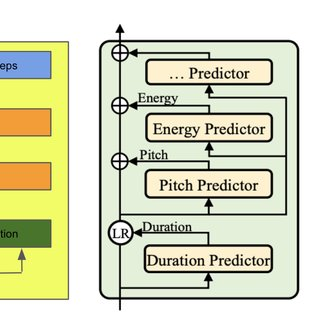
1. Duration Predictor
참고자료
각각의 음절이 얼마나 Speech를 길게하는지 알아보는 것이다. 즉 phoneme duration 음절 길이를 정확도를 예측하는 요소로 만드는 것이다. 얼마나 많은 mel frames 들이 각각의 음절과 일치하는지 보고, ease prediction을 위해 이를 log로 변환시키는 역할을 한다.
Loss function으로는 mean square error을 이용하며, training에 이용할 duration은 fastspeech에서 이용한 미리 학습된 (Teacher model) autoregressive TTS방식을 이용하는 것이 아닌, Montreal forced alignment (MFA) 방식을 이용한다.
Montreal forced alignment는 audio file의 vector들을 따와서 음절 속의 단어를 찾는 기술이다. 과정은 다음과 같다.
Monophone model->Triphone model->LDA+MLLT->Triphone model
처음 모노폰 모델은 각 음절을 맥락에 관계없이 동일하게 모델링하고, 두번째 트라이폰 모델은 음절 양쪽의 단어 맥락을 고려해서 모델을 만든다. 세번째는 각 음절의 특징을 변형시켜서 각자의 음절을 전혀 다른 특성을 가지도록 만들고, 마지막의 트라이 폰 모델은 각자의 스피커마다의 특징을 잡아서 변형된 MFCC 특징을 계산한다. 이를 Kaldi 특징이라고도 한다. 또한 MFA는 DNN을 이용한다.
마지막에 하는 변형된 MFCC 특징을 이용하는 것이 MFA만의 큰 장점이라고 한다.
이는 정렬 정확도를 높이고, input과 output 사이의 information loss를 줄인다.
2. Pitch Predictor
pitch는 Sound pitch 즉 음높이를 의미한다. 음높이는 speech program을 만들때 speech에서 감정을 공급해주는 요소중 하나다.
이전의 pitch predictor는 pitch의 윤곽선을 잘 만들어 내는 것 들중 하나였는데, 이러한 자연스러운 윤곽선은 실제 윤곽선인 ground truth와 매우 큰 차이를 보였었다.
그래서 fastspeech2 pitch predictor는 CWT(continuous wavelet transform)와 inverse CWT를 이용해서 pitch contour을 좀 더 정확하게 ground truth랑 비슷하게 예측할 수 있게 됐다.
CWT는pitch를spectrogram으로 바꿔서 평균과 분산을 계산하고 이를 iCWT에 넣어 좀 더 나은contour을 만들어 내는 것이 목표이다.
이 또한loss function은 MSE를 이용하였으며, forwarding을 CWT, backpropagation을 iCWT 혹은 그 반대로 이해하면 될 것이다.
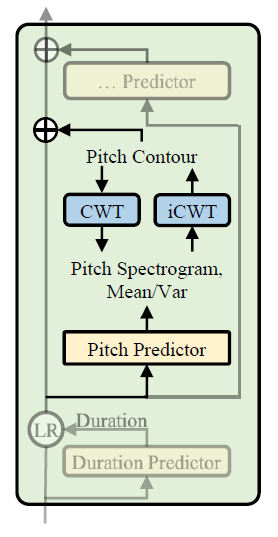
이렇게 구해진 pitch contour를 정량화하고, 256개의 log-scale의 가능한 값으로 변환 시켜서 pitch vector p 256개를 embedding 시키고, feed forwarding을 시킨다. (DNN)
그래서 fastspeech2가 억양을 잘살리고, pitch contours 가 더 좋다는 결과가 아래의 그림에 나타난다.
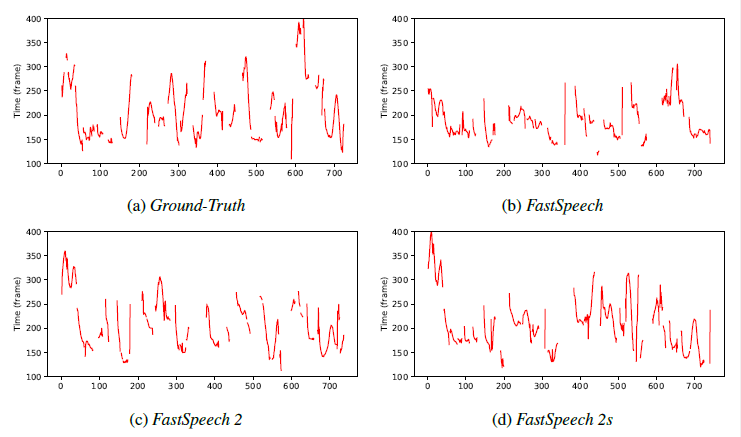
3. Energy Predictor
참고자료
Energy 는 mel-spectrogram의 크기와 speech volumn의 크기를 의미하며, 이는 speech의 분석 요소중 하나가 된다.
Energy는 예측할 값의 진폭과 ground truth의 진폭 사이의 L2 norm을 구하는데, L2 norm을 구하기 위해서 단시간 푸리에 변환을 이용한다. (STFT)
short time fourier transform (STFT)를 이해하기 전에, 푸리에 변환이란signal을 우리가 아는 주기함수들로 나누는 것을 의미한다. 예를 들어sin,cos이 있을 것이다. 다음 그림을 보자.
빨간색이 실제 주파수 이고 파란색이 푸리에 변환을 한 주기함수이다. 여러 개가 나오게 되고 마치 원 핫 인코딩 느낌으로 어떤 주파수가 도드라지는 지 알 수 있게 된다.
이런 식으로 각 주파수 마다 주기함수를 가질 수 있도록 파악하고, 이를 가능한 256개의 값으로 정량화 시킨후 pitch와 비슷하게 encoding을 한다.
loss function은 MSE를 이용하였다.
코드 분석
# Variance Predictor, 즉 pitch, energy, duration모두를 훈련할 때 이용한다.
self.conv_layer = nn.Sequential(OrderedDict([
("conv1d_1", Conv(self.input_size,
self.filter_size,
kernel_size=self.kernel,
padding=(self.kernel-1)//2)),
("relu_1", nn.ReLU()),
("layer_norm_1", nn.LayerNorm(self.filter_size)),
("dropout_1", nn.Dropout(self.dropout)),
("conv1d_2", Conv(self.filter_size,
self.filter_size,
kernel_size=self.kernel,
padding=1)),
("relu_2", nn.ReLU()),
("layer_norm_2", nn.LayerNorm(self.filter_size)),
("dropout_2", nn.Dropout(self.dropout))
]))
