csv 파일을 읽고 저장
전용 검색 앱 생성
출처 : https://cafe.naver.com/splunker?iframe_url_utf8=%2FArticleRead.nhn%253Fclubid%3D26625693%2526articleid%3D438
Stock app

폴더이름 : 리눅스에 생성될 디렉토리의 이름
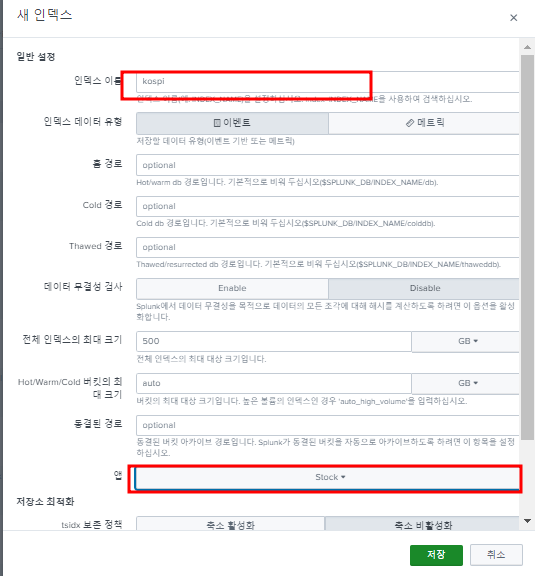
stock_monitor.py 파일을 생성
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 19 12:00:44 2019
@author: cchoi
"""
from pandas_datareader import data
import pandas as pd
import argparse
from datetime import datetime, timedelta
import json
import os
import sys
CONF_PATH=os.path.dirname(os.path.abspath(__file__))
# 수집한 데이터를 실행한 디렉토리 및 /stock 에 텍스트 파일로 모을 것이다.
LOG_PATH=CONF_PATH + '/stock'
def write_log(f, df):
"""
수집한 데이터를 파일에 쓴다.
"""
json_string = df.to_json(orient='records') # Pandas에 있는 데이터 프레임을 json 형태로 변환한다.
json_obj = json.loads(json_string)
# Json array를 개별 이벤트로 만들기 위해 줄바꿈해서 입력한다.
# 스플렁크에서 JSON 타입은 작은 따옴표(') 가 아닌 큰 따옴표(") 로 되어 있어야 한다.
# 파이썬은 기본적으로 작은 따옴표로 만들어지기 때문에 replace 구문을 작성한다.
[f.write(str(val).replace("'", '"') + "\n") for val in json_obj]
def getStockHistory(companyCode, fromDate, toDate):
"""
Yahoo Financial 에서 주식데이터를 불러온다.
compandCode: 종목 코드 (kospi_200.csv 참조)
fromDate: 수집할 시작 날짜 (%Y-%m-%d 형태)
toDate: 수집할 마지막 날짜 (%Y-%m-%d 형태)
"""
dataSource = 'yahoo'
ticker = companyCode
print('===========>Call ' + ticker)
try:
start = pd.to_datetime(fromDate).date()
end = pd.to_datetime(toDate).date()
panel_data = data.DataReader(ticker, dataSource, start, end) # 이 한줄이면 해당 날짜에 대한 주식 데이터를 가져올 수 있다.
# 가져온 데이터를 우리의 입맛에 맞게 조금 고쳐준다.
df_reset =panel_data.reset_index()
df_reset['code'] = companyCode # 수집 된 데이터에는 종목 코드가 없기 때문에 새로 추가
df_reset['Date'] = df_reset['Date'].dt.strftime('%Y-%m-%d') # 날짜 형태 고정
return df_reset
except:
print(sys.exc_info()[0])
return None
def getCodeList():
"""
종목 코드 파일을 읽어서 가져온다.
"""
df = pd.read_csv(CONF_PATH + "/kospi_200.csv", dtype=str) # 파일을 읽는 것도 pandas를 이용하면 한줄로 가능하다.
return df.code.values
if __name__ == "__main__":
"""
메인 함수
--start_date : (Option)검색 시작 날짜로 %Y-%m-%d 형식을 취한다. (생략 시 어제 날짜)
--end_date : (Option)검색 종료 날짜로 %Y-%m-%d 형식을 취한다. (생략 시 어제 날짜)
--code : (Option) 검색할 종목 코드 (생략 시 kospi_200.csv 에 있는 전 종목)
"""
parser = argparse.ArgumentParser()
parser.add_argument('--start_date', help='start_date help')
parser.add_argument('--end_date', help='end_date help')
parser.add_argument('--code', help='code help')
args = parser.parse_args()
if args.start_date:
start_time = args.start_date
else:
start_time = (datetime.now() - timedelta(days=1)).strftime('%Y-%m-%d')
if args.end_date:
end_time = args.end_date
else:
end_time = (datetime.now() - timedelta(days=1)).strftime('%Y-%m-%d')
codes = []
if args.code:
codes.append(args.code)
else:
codes = getCodeList()
print("%s-%s",(start_time, end_time))
# 주식 종목을 조회하고 파일에 해당 내용을 쓴다.
with open(LOG_PATH + '/stocks_' + end_time.replace("-", "") + ".log" , "a") as f:
for code in codes:
result = getStockHistory(code + ".KS" , start_time, end_time)
if result is not None:
write_log(f, result)
f.close()$ python3 stock_monitor.py --start_date 2020-12-01 --end_date 2020-12-31
stock 디렉토리와 stocks_20201231.log 파일을 생성하면 로그 기록이 해당 파일로 저장된다
리눅스에서 위의 명령을 실행하면 로그 기록들이 디렉토리에 저장된다
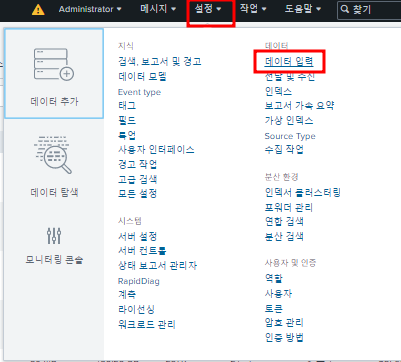
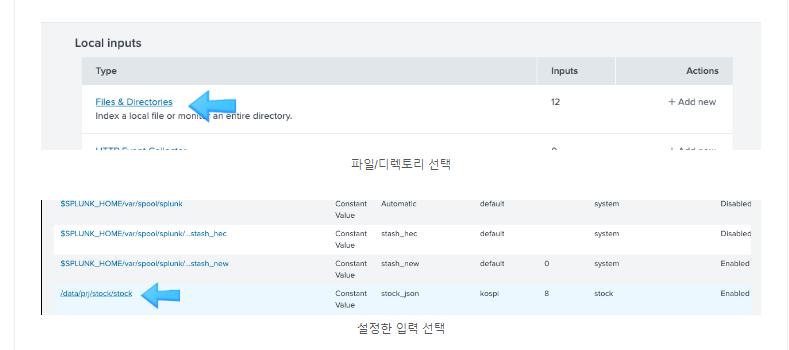
저장된 로그기록을 스플렁크 데이터로 입력
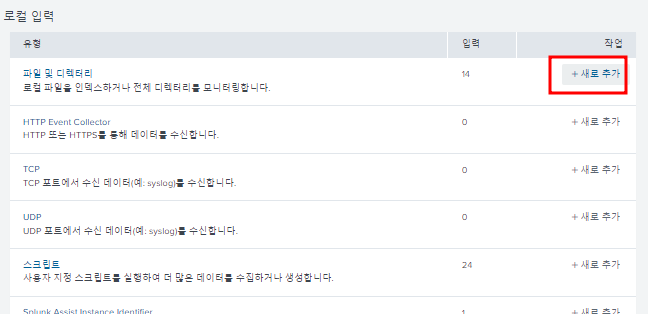
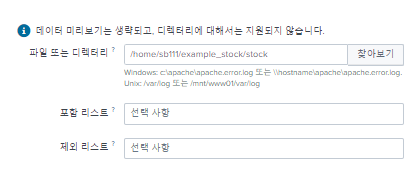
저장된 로그의 디렉토리 주소를 입력해두면 로그기록을 읽음
다음을 누른다
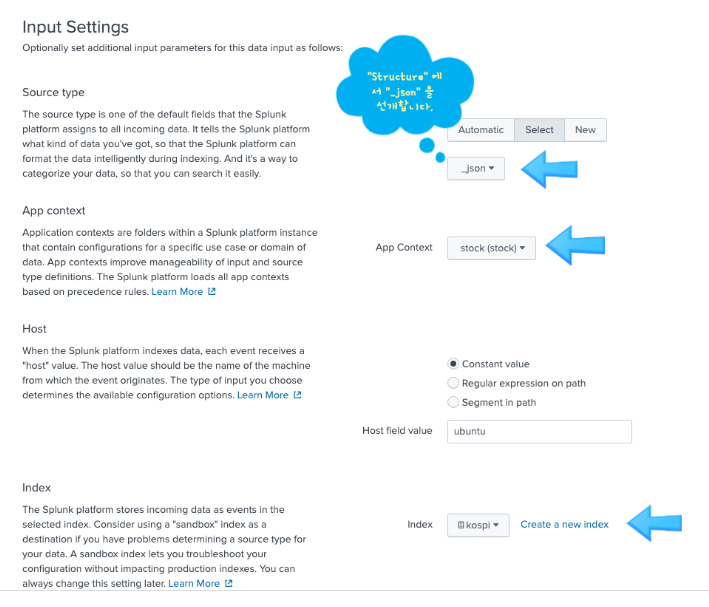
데이터 형식을 미리 지정하기
출처 : https://cafe.naver.com/splunker?iframe_url_utf8=%2FArticleRead.nhn%253Fclubid%3D26625693%2526articleid%3D438

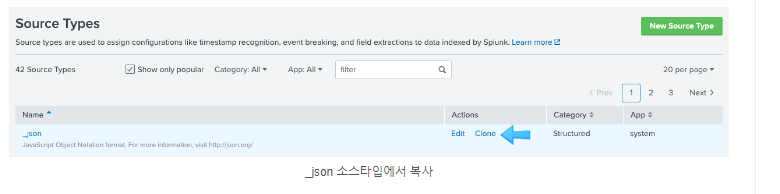
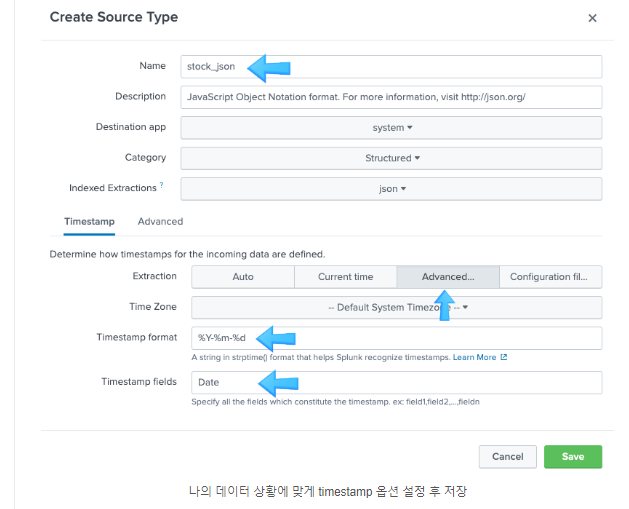
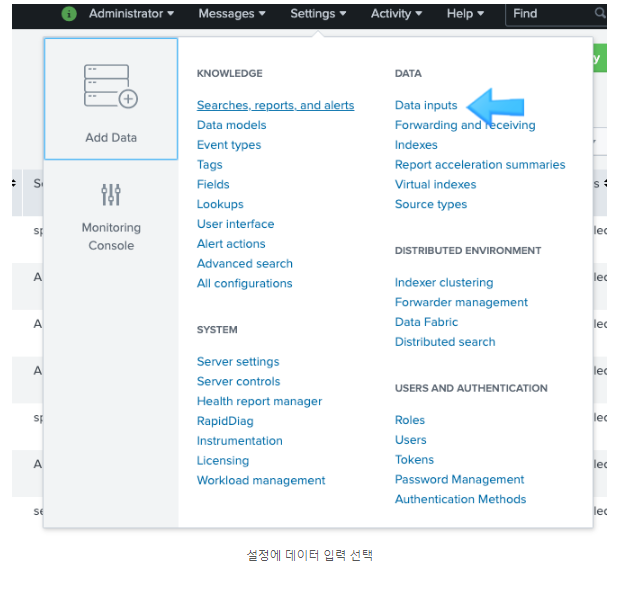
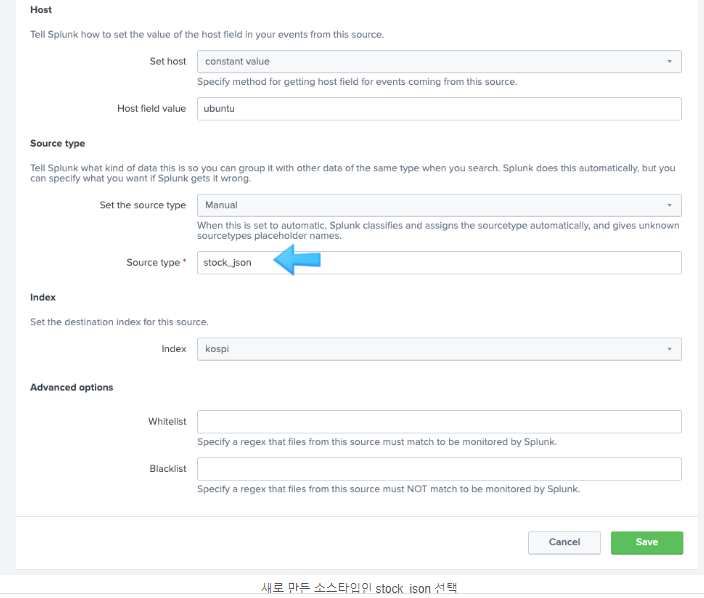
위의 순서대로 하면 처음 입력된 데이터가 남아서 sourcetype=_json 인 파일만 검색된다. 따라서 기존의 인덱스를 삭제하고 새로운 인덱스를 생성하여 해결한다. 2022-01-01 ~ 2022-03-3, 2022-04-01 ~ 2022-07-20의 데이터 두 개의 파일로 불러오려고 했으나 되지 않았다. 그래서 2022-01-01 ~ 2022-07-20 파일 하나로 불러오니 그건 또 됨. 아마도 디렉토리라고 하지만 인덱싱하고 불러오는 건 하나의 파일만 가능한 듯 하다

배운 건 써 먹자