Swift Concurrency: Behind the scenes Part. 01
Concurrent Programming

앞에서는 새롭게 나온 개념들을 어떻게 사용하는지에 대해서 알아보았다. 그렇다면 왜 이렇게 설계했는지, 실제로는 어떻게 동작하는지 알아보자.
Threading Model
New feed reader 앱을 만든다고 생각해보자. 고수준에서 어떠한 것들이 필요할지 생각해보자.
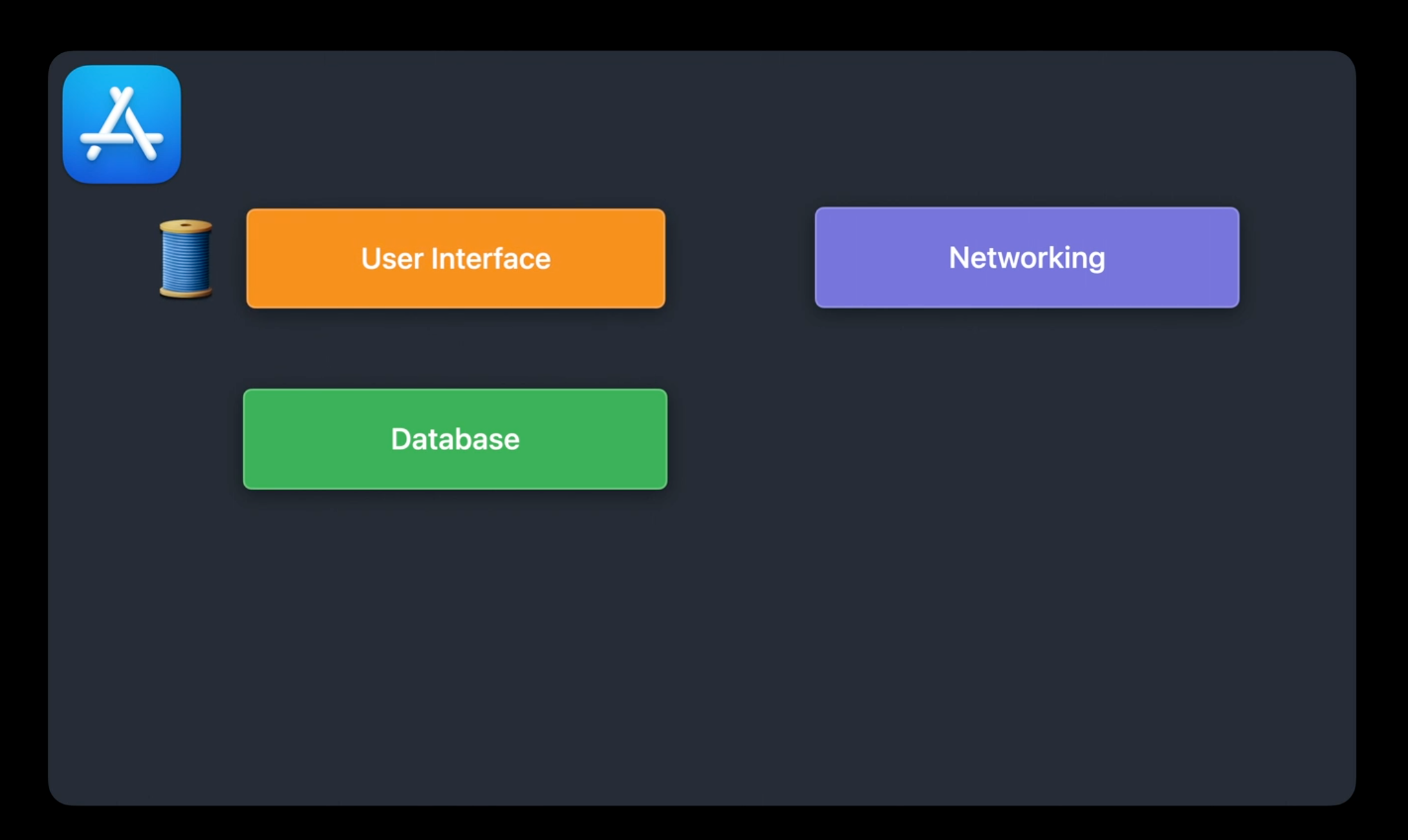
- User Interface를 처리할 main thread가 있다.
- User가 구독한 news feed를 추적할 Database도 있다.
- 마지막으로 feed로 부터 최신 content를 받아올 네트워크 처리단이 있다.
Grand Central Dispatch
User가 새로운 news feed를 가져오라는 gesture를 했다고 생각해보자. GCD를 사용했을 때는 다음과 같이 처리했었다.
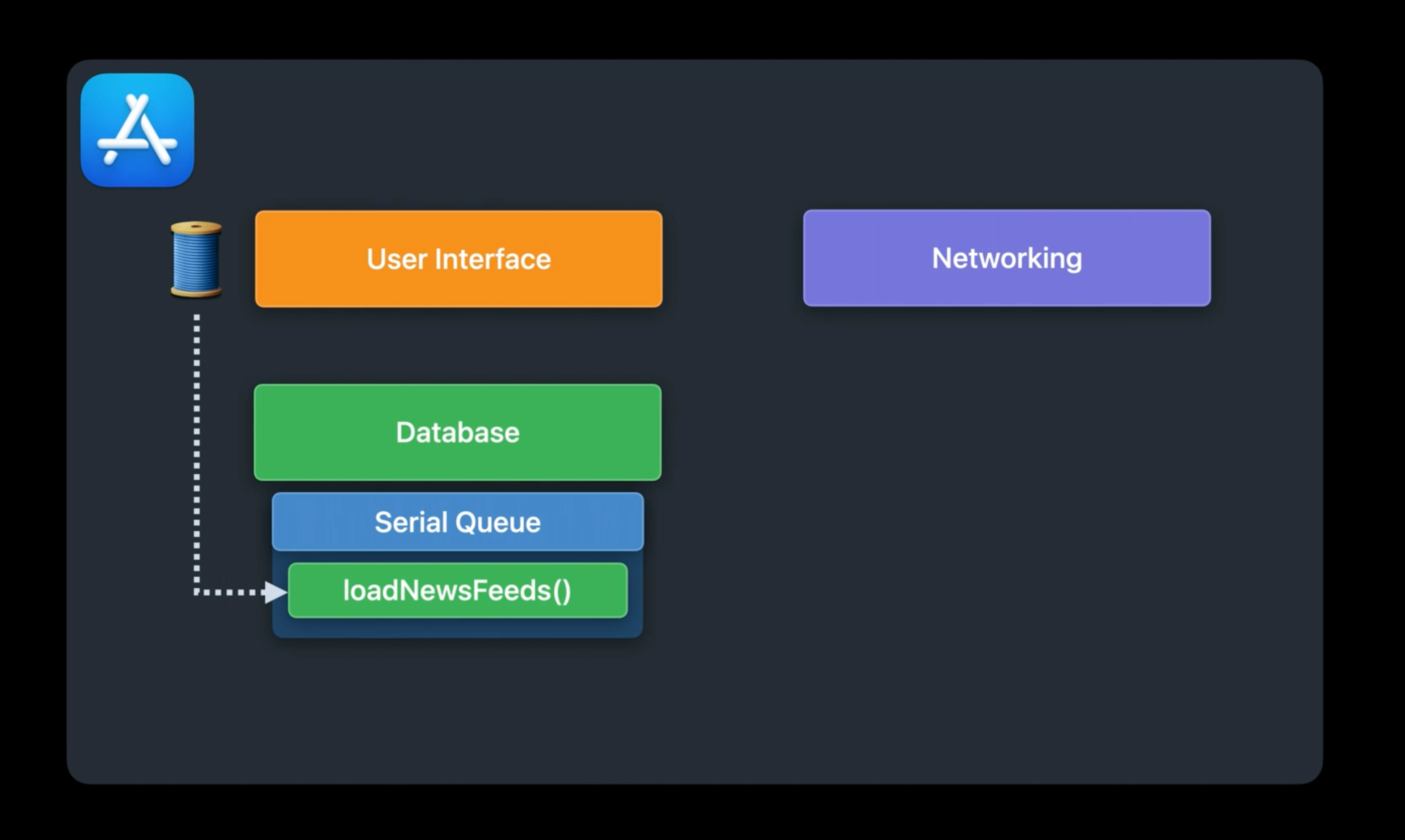
User의 gesture를 받아 Serial Dispatch Queue에 async 하게 동작을 넘긴다.
- 다른 Dispatch Queue에서 작업을 뽑아옴으로써 많은 양의 작업일지라도 main thread가 user의 동작을 계속 받을 수 있도록 하기 위해서
- serial queue를 사용함으로써 database의 접근에 있어 상호 배제를 보장
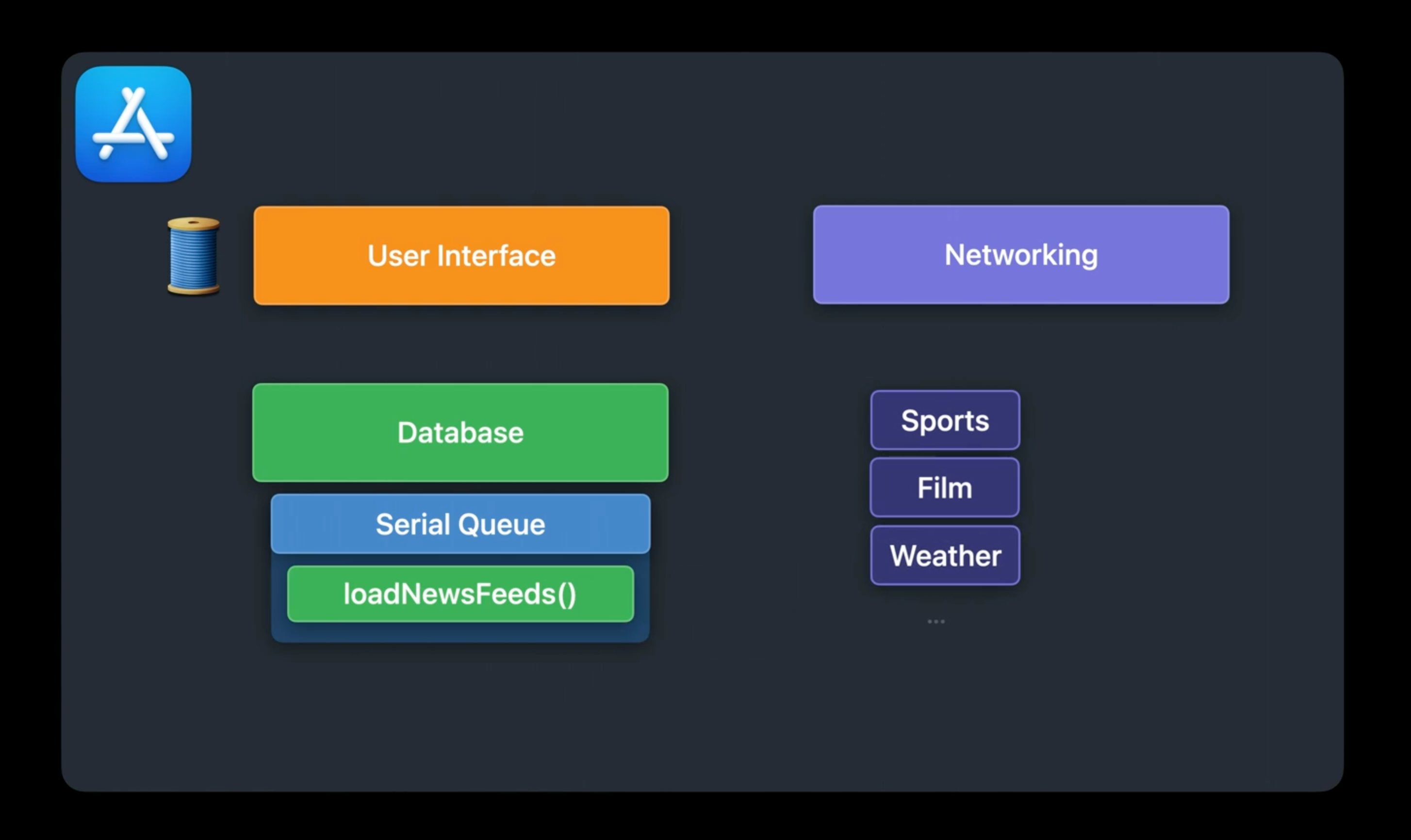
Database Queue안에서 user가 구독한 feed들을 iterate하며, network 요청을 하도록 URL Session에 넘긴다.
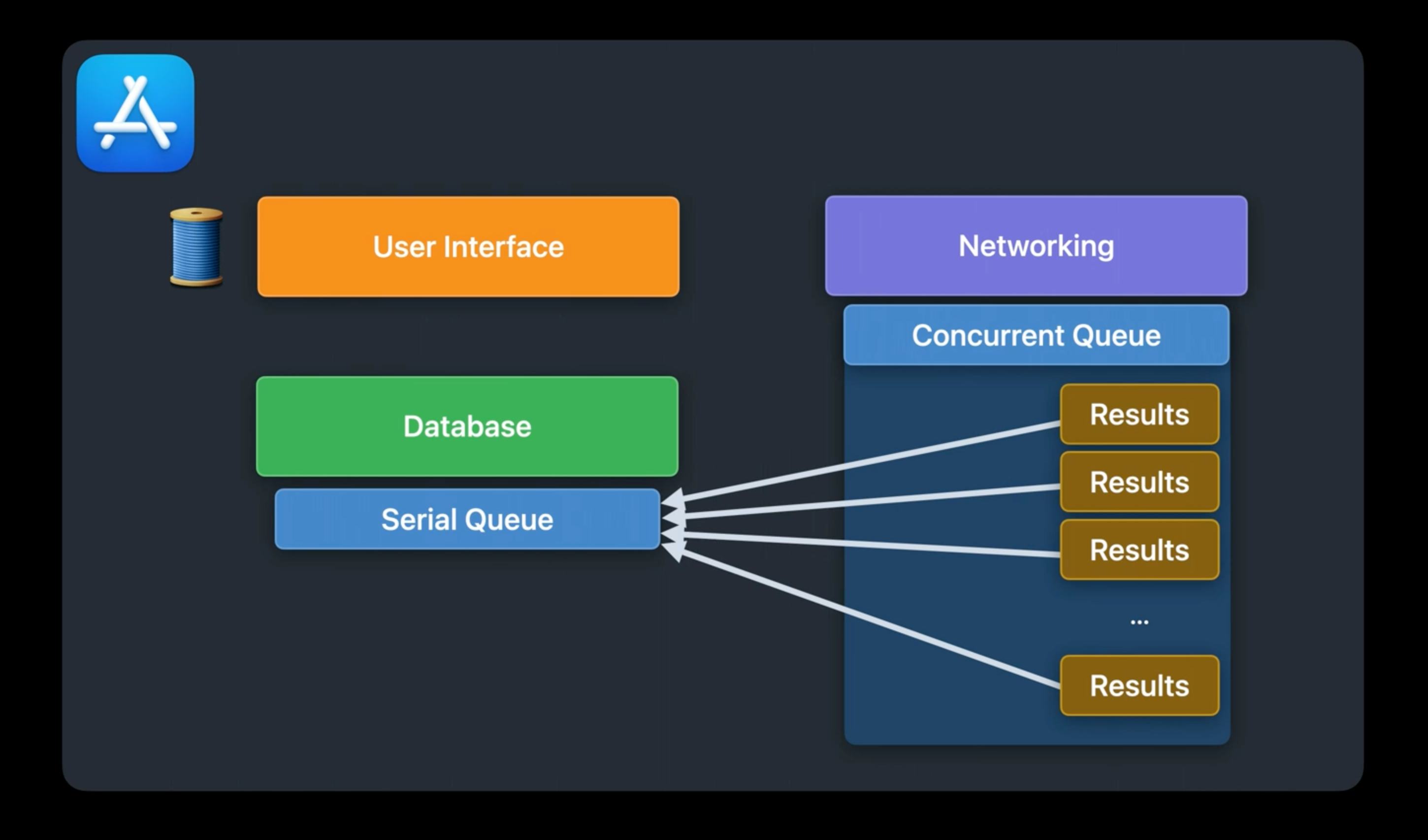
Network 결과가 들어오면, URL Session callback이 delegate queue에서 실행된다.
- 이 때 Queue는 conccurent queue로 지정하여 parallelism을 적용시켜 효율적으로 동작시키도록 해보자.
callback에서는 받은 결과를 Database Queue(Serial)에 작업을 넘긴다.
- 순차적으로 반영되기 때문에 data race 상황은 발생하지 않는다.
- 가장 최신의 결과가 반영되기 때문에, 이 과정에서 cache를 적용할 수도 있을 것이다.
마지막으로 main thread에 해당 결과를 반영하여 UI를 업데이트한다.
이 과정은 매우 합리적인 것처럼 보인다. main thread를 막지 않아 UI 업데이트도 일어나게 하였으며, network 요청도 concurrent하게 수행하며, data base에서는 serial queue를 사용하여 data race 상황이 발생하지 않도록 했다. 이번에는 코드를 봐보자.
func deserializeArticles(from data: Data) throws -> [Article] { /* ... */ }
func updateDatabase(with articles: [Article], for feed: Feed) { /* ... */ }
// 1. 네트워크 요청을 위한 URLSession(Concurrent Queue)
let urlSession = URLSession(configuration: .default, delegate: self, delegateQueue: concurrentQueue)
// 2. Database에서 가져온 feed 목록에 대해 모두 network 요청한다.
for feed in feedsToUpdate {
// 3. completion handler에 적힌 task는 system에서 요청을 받은 후에 처리된다.
// 결과는 delegate queue, 여기서는 concurrent queue에서 받게 된다.
let dataTask = urlSession.dataTask(with: feed.url) { data, response, error in
// ...
guard let data = data else { return }
do {
// 4. 받은 결과에 대해 deserialization 한다.
let articles = try deserializeArticles(from: data)
// 5. 화면에 업데이트 되기전에 결과에 대해 database queue에 task를 sync로 넘겨 반영한다.
databaseQueue.sync {
updateDatabase(with: articles, for: feed)
}
} catch { /* ... */ }
}
dataTask.resume()
}아까 생각한 흐름에 대해 코드로 스무스하게 적혔다. 하지만 이 코드는 성능 측면에서 숨겨진 함정이 있다.
GCD and thread bring up
이 문제를 이해하기 위해서는 GCD Queue가 어떻게 work item을 처리하는지 알아야 한다.

- concurrent queue는 여러개의 work item을 한번에 처리할 수 있기 때문에 시스템은 CPU Core수가 포화되는 수준까지 여러개의 thread를 가져온다.
- 그런데 만약, Thread가 Block되면, (그리고 더 많은 수행될 work들이 있다면) System은 해당 CPU Core를 채울 수 있는 thread를 더 가져온다.
- 다른 Thread에게 처리 권한을 넘겨줌으로써 다른 Thread가 일을 할 수 있도록 하기 위해서
- Blocked된 Thread는 다음 처리를 위해 semaphore처럼 다음 resource를 기다리고 있을 수 있다. 그렇기에 다음 작업이 처리되어야 block이 해제될 수 있기 때문에 위와 같은 방식을 채택했다.
- 이렇게 새롭게 만들어진 thread는 resource를 unlock하여 작업을 계속 이어나갈 수 있게 해준다.
이제 동작을 좀 이해했으니 다시 news feed앱으로 돌아가보자.
CPU Execution
URLSession의 결과를 가져오는 동작에서 Apple watch 처럼 2개의 코어가 있다고 생각해보자.
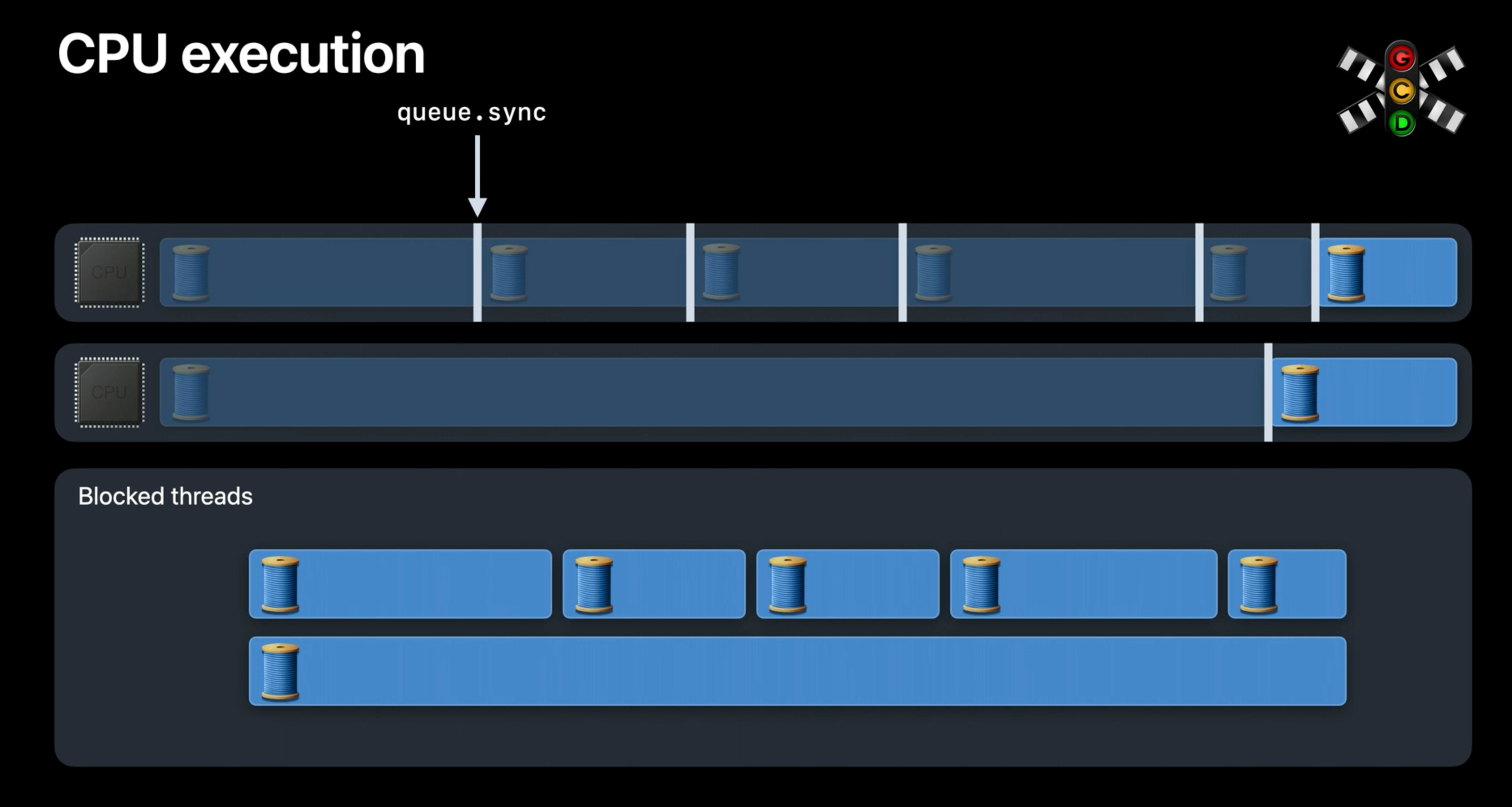
- Core가 2개이므로 GCD는 feed update result를 처리하기 위해 2개의 thread를 가져온다.
- 그 안에서
databaseQueue.sync를 호출하고 있기 대문에, 해당 task는 block된다. - GCD는 다음 thread를 가져와 동작을 수행한다.
- 그 안에도
databaseQueue.sync가 있기 때문에 block된다. - 2~3이 loop를 다 돌때까지 반복된다.
이 과정에서 CPU는 다른 Thread간의 Context Switching을 수행한다. 즉, 우리가 작성한 코드에서 쉽게 많은 수의 thread가 발생하고, 그렇기 때문에 성능저하가 생길 수 있다.
Excessive concurrency
Thread 수가 많아지는 것은 Application에 좋지 않은 영향을 끼친다.
- CPU Core보다 많은 수의 thread는 시스템의 동작을 낭비하는 것이다.
- Thread Explosion
- 6개의 core가 있는 iphone을 생각해봤을 때 100번의 feed update를 수행한다면, 우리는 core수보다 16배나 많은 thread를 생성한 것이다.
- Memory overhead
- Scheduling overhead
결국, core 수보다 많은 양의 thread를 통해 관리하는 것은 memory, scheduling에 있어 문제를 일으킨다.
Memory overhead
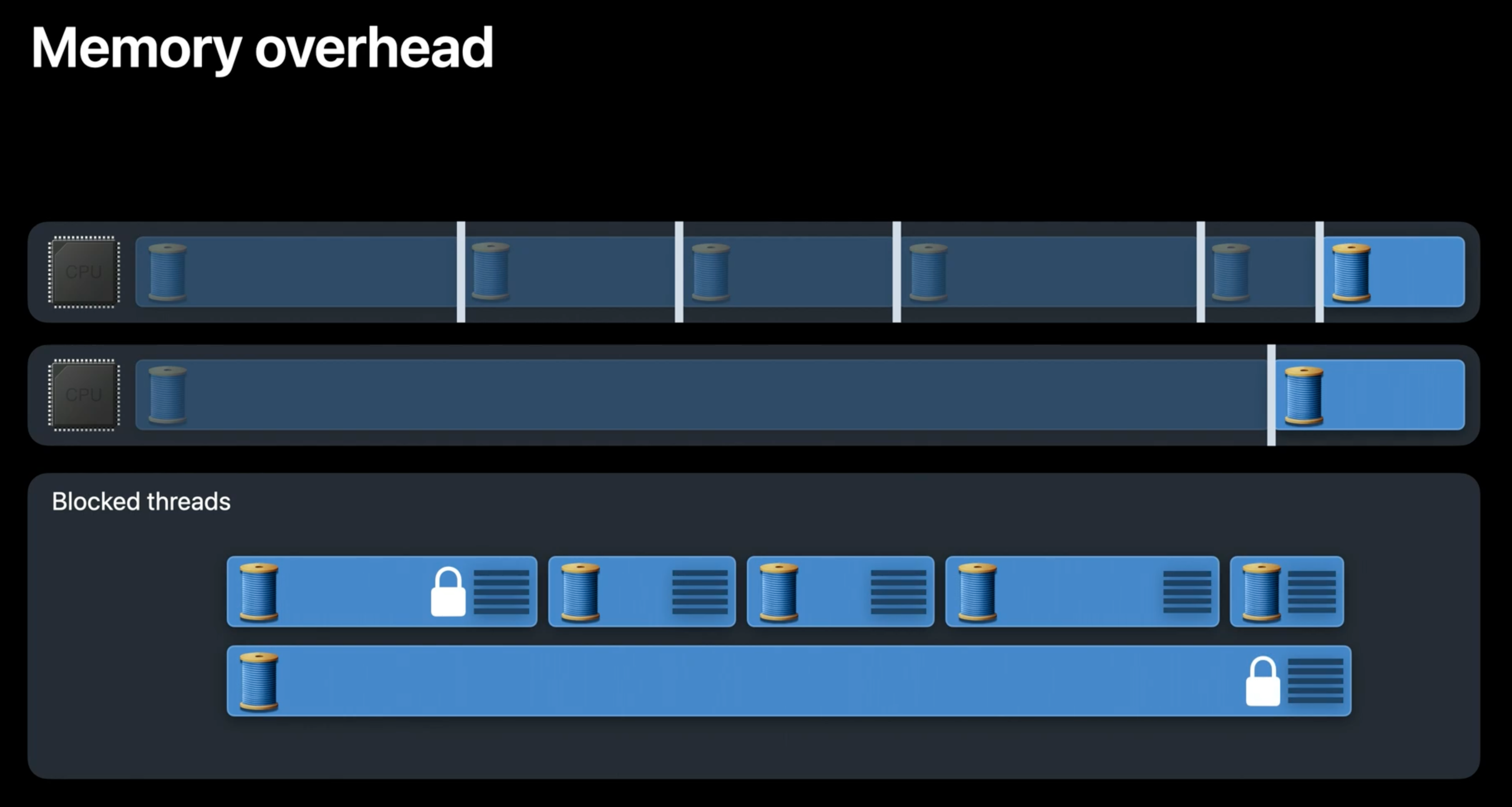
쉽게 알 수 있겠지만, block된 thread는 결국 나중에 돌아와서 본인의 작업을 수행해야 한다. 이점에서 작업이 중단된 상태를 기억하고 있어야 하고, 이는 곧 memory에 저장되게 된다.
각각의 thread에서는 실행 흐름을 저장하는 stack이 있고, 그와 관련된 kernal 자료구조가 thread를 추적하고 있다. 몇몇 스레드는 lock으로 붙잡혀있어, 다른 thread의 동작이 필요할 수도 있다. 즉, 이런 당장 동작하지 않는 thread들이 많은 양의 memory와 자원을 붙잡는 상태가 벌어진다.
내용이 헷갈린다면 07: 쓰레드(Thread)을 참고하자.
Scheduling overhead
Thread가 많아지는 것은 메모리 측면에서만 문제가 있는 것은 아니다. 결국 이런 Thread들이 언제 처리될 것인지를 관장하는 스케쥴링도 해야 하는데, 많아질 수록 이런 과정은 더욱 복잡해지기 마련이다.

제한된 Core수를 가진 상태에서 Thread explosion이 발생하면, 과도한 Context Switching을 발생시킬 수 있다. 이렇게 늦어진 처리는 결국 중요한 처리를 늦게하게 만들 수 있다. 결과적으로 CPU가 효과적으로 동작하는 것을 방해한다.
Swift Concurrency
위에서 살펴본 것과 같이 Thread explosion은 GCD에서 발생할 수 있는 문제이다. 그럼에도 이 부분을 섬세하게 캐치하여 코드를 작성하는 것은 놓치기 쉬운 부분이다. 이런 부분에서 Swift의 언어설계는 concurrency를 설계하는데 있어 다른 접근을 도입했다.
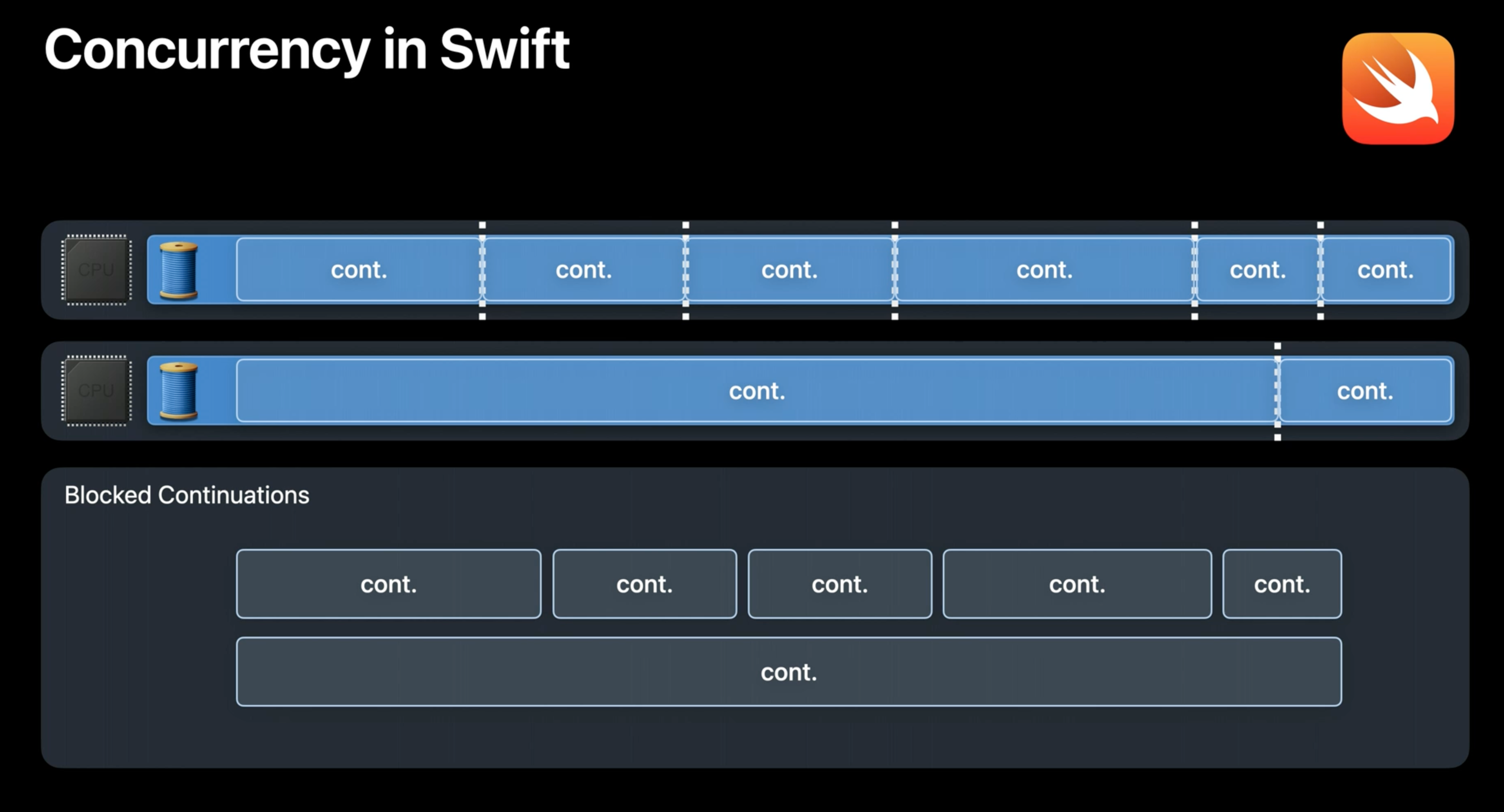
- Core 수에 맞는 Thread만 사용한다.
- Blocking Thread가 없어진다.
- Full Thread Context Switching이 없어진다.
- 대신 가벼운 Object인
Continuation을 사용한다.- 작업의 재개 여부를 추적한다.
- Continuation간의 switching이 발생한다.
- Full Thread Context Switching대신 function call로 대체할 수 있다.
즉, Swift concurrency에서는 runtime에 CPU Core 수만큼의 Thread만 생성하여 저렴하고 효율적으로 work item이 block되었을 때 Switching을 수행한다. 이런 동작을 수행하기 위해서는 runtime에 Thread를 차단하지 않는 Contract이 필요하다. 그리고 언어 역시 이를 지원할 수 있어야 했다.
Language features
이에 Swift의 Concurrency에서는 이 Runtime Contract를 유지할 수 있는 기능을 마련했다. 언어 차원에서 제공하는 두가지 기능을 설명하겠다.
await의 사용과 thread를 non-block으로 사용한다.- Swift runtime에 task의 의존성을 추적한다.
이전의 news feed 코드를 Swift concurrency를 적용해 다시 적어보자.
func deserializeArticles(from data: Data) throws -> [Article] { /* ... */ }
func updateDatabase(with articles: [Article], for feed: Feed) async { /* ... */ }
// 1. Concurrent Queue에서 network 결과를 처리하지 않고, concurrency를 처리하기 위해 `TaskGroup`을 사용한다.
await withThrowingTaskGroup(of: [Article].self) { group in
for feed in feedsToUpdate {
// 2. `TaskGroup`에서 Child task를 사용하여 각각의 feed가 update되어야 함을 명시한다.
group.async {
// 3. feed의 url을 기반으로 네트워크 요청한다.
let (data, response) = try await URLSession.shared.data(from: feed.url)
// 4. 결과를 deserialize한다.
let articles = try deserializeArticles(from: data)
// 5. async function인 updateDatabase를 호출하여 데이터베이스를 업데이트한다.
await updateDatabase(with: articles, for: feed)
return articles
}
}
}여기서 주목할 부분은 다음과 같다.
asyncfunction을 사용하는 경우await키워드를 추가해야 한다.await키워드는 현재 작업하고 있는 Thread를 Block하는 것이 아니다. non-blocking이다.- block이 아니고 해당 작업을
suspend시키고, 다른 작업을 하러 간다.
그런데 가만 있어보자. 어떻게 작업이 thread를 포기하고 나갈 수 있을까?
await and non-blocking of threads
async function이 어떻게 구현되어 있는지 알아보기 전에, 어떻게 non-async function이 동작하는지 알아보자.
Non-async functions
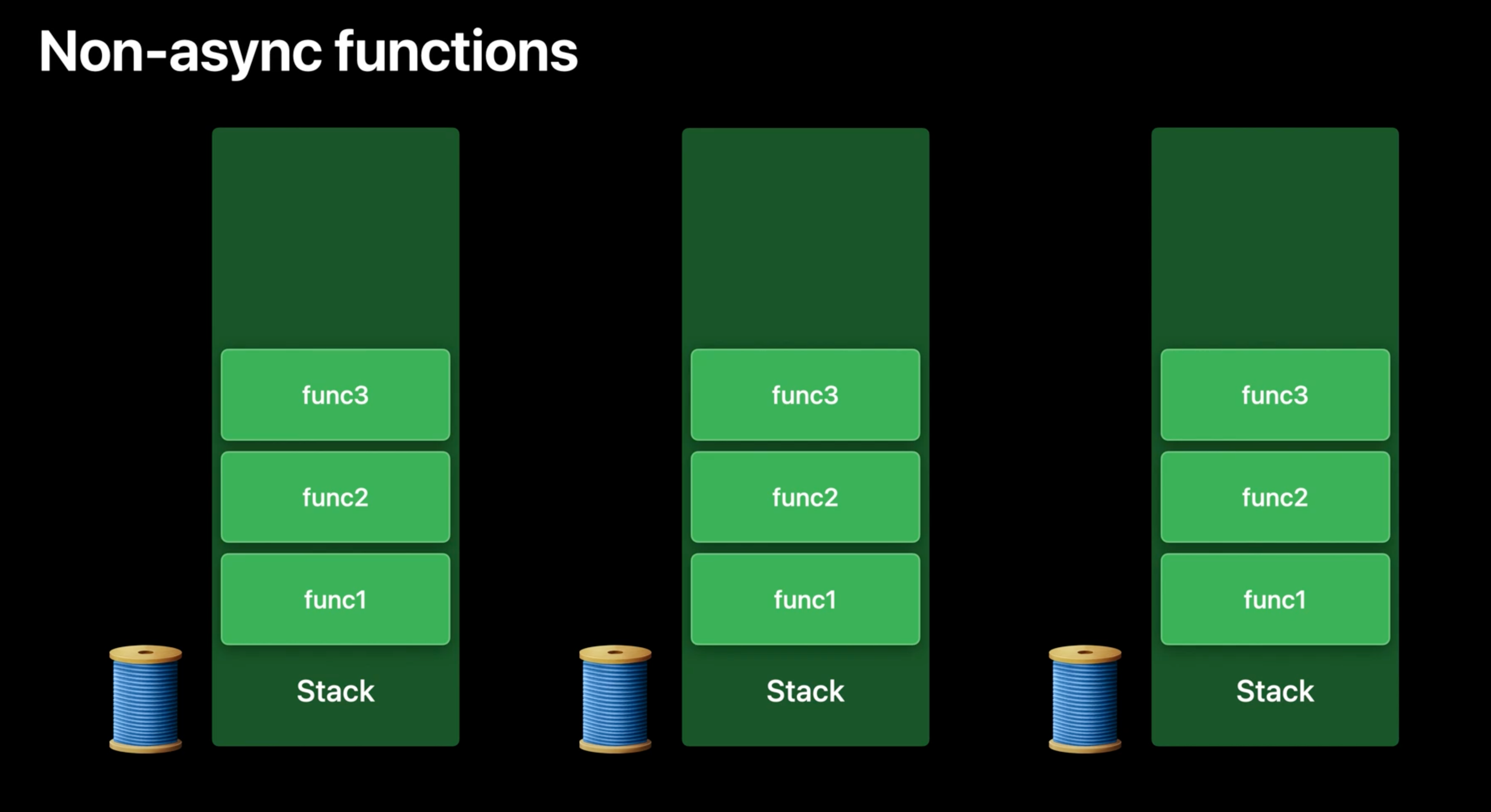
Program에서 동작하는 모든 Thread는 함수 call상태를 저장하기 위한 stack을 가지고 있다.
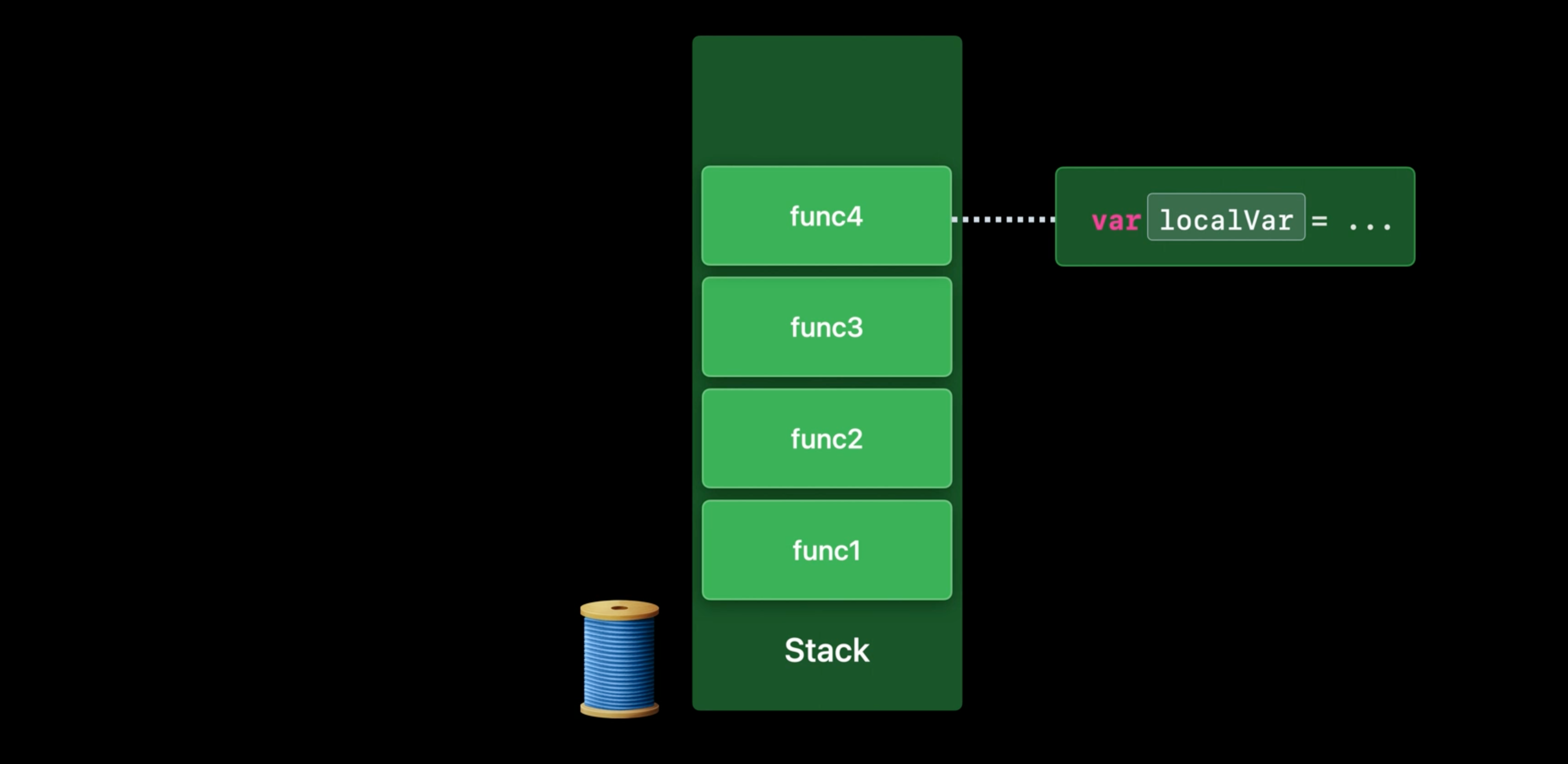
하나의 stack을 살펴보자. 하나의 함수가 call되면 새로운 frame이 stack에 push된다. 새롭게 만들어진 frame은 지역 변수 저장, 반환 주소 전달, 다른 기타 용도를 위해 사용된다. 일단 함수가 동작을 바치고 반환하면, stack frame은 pop된다.
Async functions
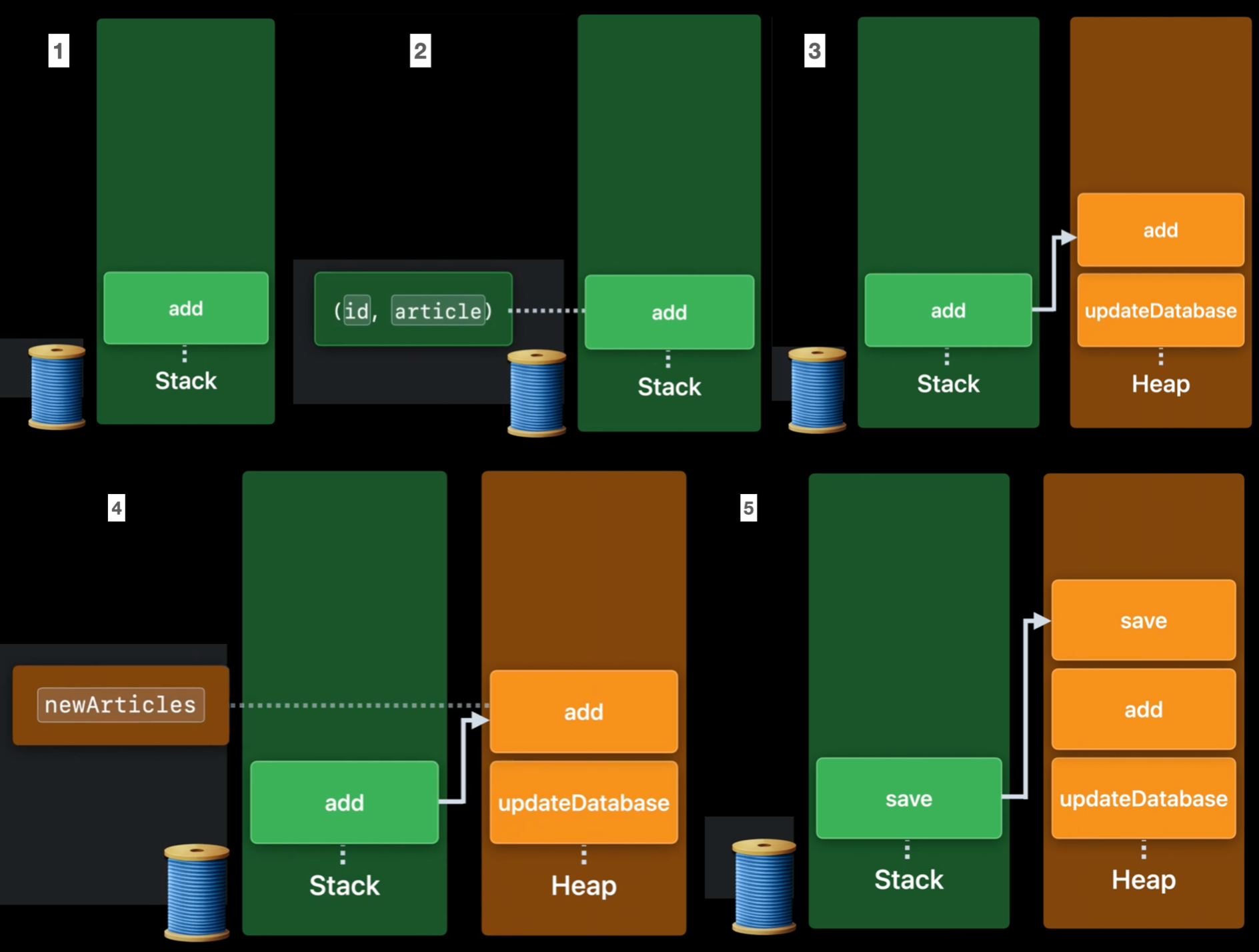
func updateDatabase(with articles: [Article], for feed: Feed) async throws {
// skip old articles ...
try await feed.add(articles) // 1. `updateDatabase` 함수 내부에서 `feed.add` 함수가 호출된다.
}
// on Feed
func add(_ newArticles: [Article]) async throws {
let ids = try await database.save(newArticles, for: self) // await 이후에 필요한 변수들은 stack frame에 저장된다.
// 2. 이런 이유로, `id`, `article`은 stack frame에 저장된다.
for (id, article) in zip(ids, newArticles) { // 3, 4. newArticle은 heap frame에서 추적된다.
articles[id] = article
}
}
// on Database
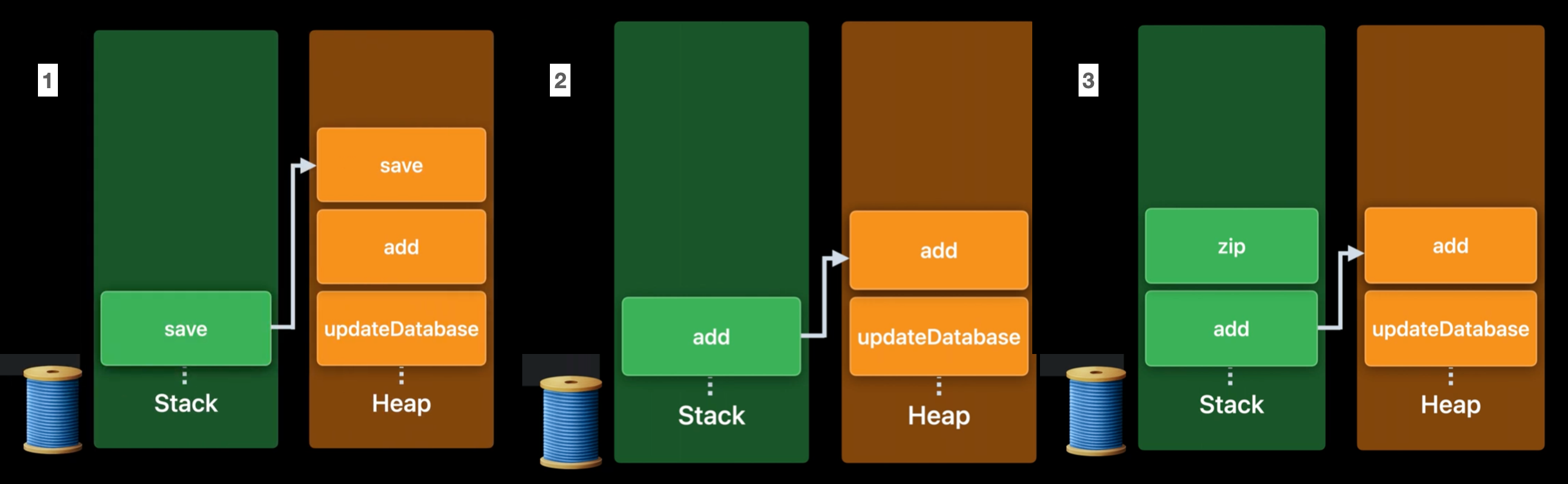
func save(_ newArticles: [Article], for feed: Feed) async throws -> [ID] { /* ... */ }Database 구현체에 save method가 있고, Feed구현체에 add method가 있다고 생각해보자.
updateDatabase함수 내부에서feed.add함수가 호출된다.- stack frame은 이 suspension point에서 사용할 필요가 없는 지역 변수를 저장한다.
add함수의 안에는await로 표시된 하나의 suspension point가 있다.id,article은 suspension point 정의된 후 loop body안에서 즉각 사용된다. 그리고 그 사이에 suspension point도 없다.
- 이런 이유로,
id,article은 stack frame에 저장된다. - 추가적으로 heap에는 두개의 async frame이 있다.
updateDatabase,add- 이의 존재 이유는, suspendsion point를 넘나들어 저장해야 하는 정보를 담기 위함이다.
newArticlesargument는await전에 정의되었으나await이후에 사용되어 진다.
- 이런 경우를 대비하여 add async frame에
newArticles이 저장되며, 이는newArticles을 추적할 것이다. - 이제
save함수가 실행되면,add는save를 위한 새로운 stack frame으로 대체된다.- 새로운 stack frame을 push하는 것 대신, top에 있는 stack frame은 대체된다.
- 이는 후에 필요한 변수(
newArticles)가 이미 async frame list에 저장됐기 때문이다.
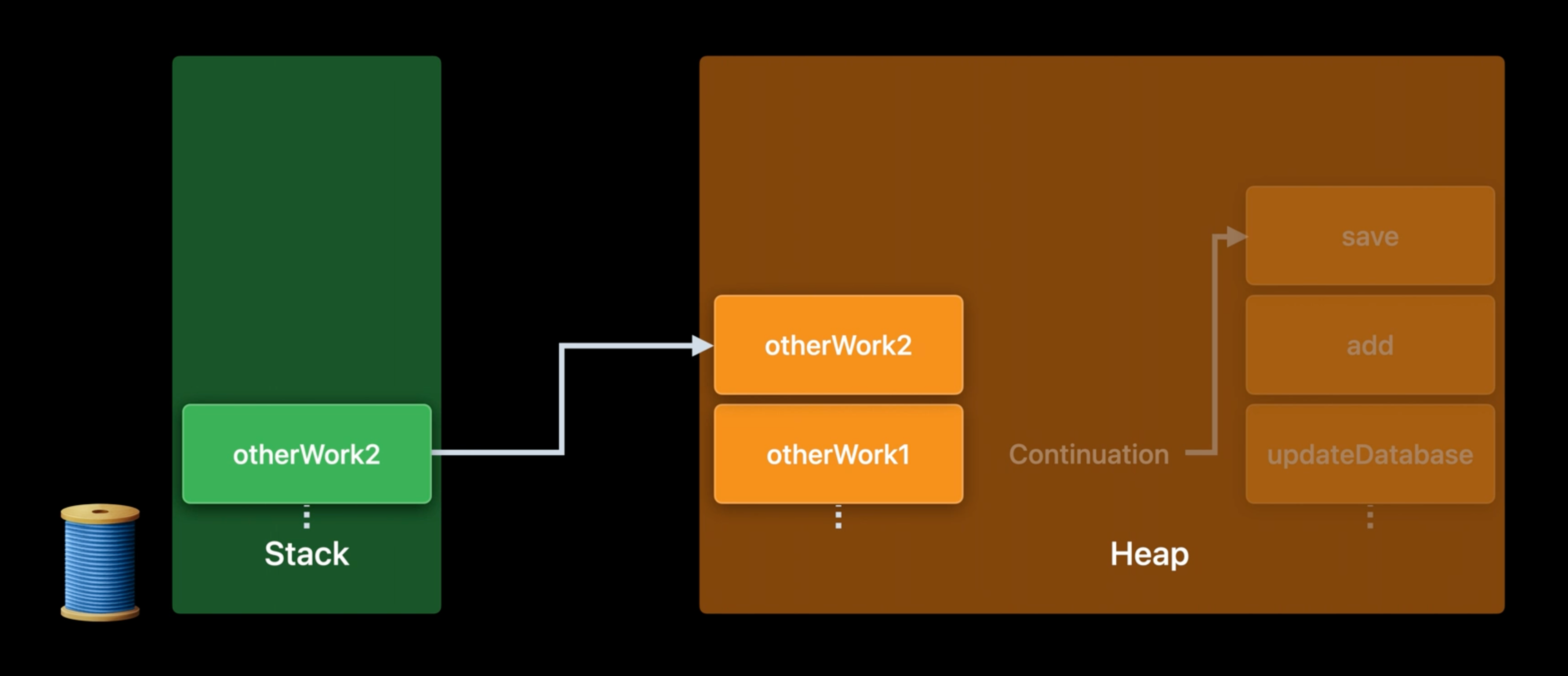
5번까지 진행한 후에, save function의 실행이 suspend되었다고 생각해보자. 상황이 이렇다면, thread가 block되어 있는 것보다 다른 작업을 하기 위해 재사용 되는 것이 보다 좋다. 위의 사진은 stack에 다른 작업이 들어와있고, 같은 방식으로 async frame에 작업 사항을 저장하는 것을 나타냈다.
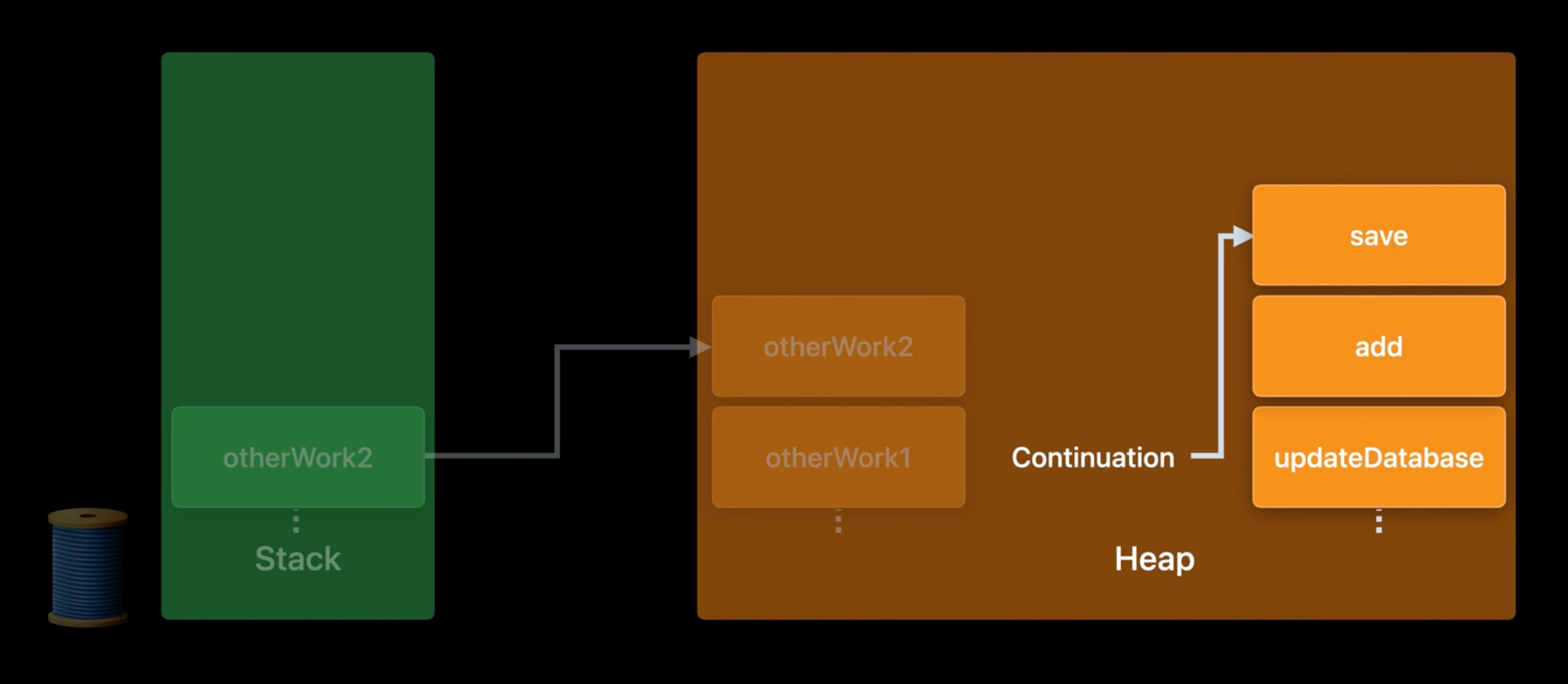
suspension point를 걸쳐 필요한 모든 정보가 heap에 저장되어있기 때문에, conitinue 실행을 통해 나중에 사용될 수 있다. 이 async frame list가 conituation의 runtime 표현이다.

어느정도 시간이 지난 후에, database 요청이 끝났고, 몇몇 thread가 비었다. 이 thread는 이전에 작업을 요청한 thread일 수도 있고 다른 thread일 수도 있다. (core개수에 맞게 생성된 thread를 말한다.) 이렇게 빈 thread에서 작업이 계속된다.
func updateDatabase(with articles: [Article], for feed: Feed) async throws {
// skip old articles ...
try await feed.add(articles)
}
// on Feed
func add(_ newArticles: [Article]) async throws {
let ids = try await database.save(newArticles, for: self) // 1.
for (id, article) in zip(ids, newArticles) {
articles[id] = article
}
}
// on Database
func save(_ newArticles: [Article], for feed: Feed) async throws -> [ID] { /* ... */ }- async frame에서 가장 최근 작업을 stack으로 부른다. 실행결과로, IDs를 반환 받는다.
save를 위한 stack frame은add를 위한 stack frame으로 대체된다.- 이제 thread는
zip연산을 수행할 수 있다. zip 연산은 nonasync 작업이기 때문에, 새로운 stack frame을 만든다.- Swift는 여전히 OS의 stack를 사용하기 대문에, async, nonasync한 Swift code모두 효율적으로 C 와 Objective-C를 호출할 수 있다.
- 그 반대도 가능하다.
- zip function이 끝나면, stack frame은 pop되고 계속된다.
Tracking of dependencies in Swift task model
지금까지의 내용을 보면, 함수가 await를 기준으로 continuations로 깨질 수 있다는 것을 배웠다. 물론 작동했던 thread로 돌아갈 수도 있다. 이런 점에서 해당 지점은 potential suspenstion point라 불린다.
func deserializeArticles(from data: Data) throws -> [Article] { /* ... */ }
func updateDatabase(with articles: [Article], for feed: Feed) async { /* ... */ }
await withThrowingTaskGroup(of: [Article].self) { group in
for feed in feedsToUpdate {
group.async {
let (data, response) = try await URLSession.shared.data(from: feed.url) // ✅
// ‼️
let articles = try deserializeArticles(from: data)
await updateDatabase(with: articles, for: feed)
return articles
}
}
}이 경우, ✅ 부분은 async function이고, ‼️ 부분은 ✅ 작업에서 continuation이 발생한 후 계속되는 작업이다. continuation은 async function이 완료된 후에만 실행될 수 있다. 이것이 Swift concurrency runtime에서 추적하는 의존성이다.
비슷하게, 최상단에 보이는 TaskGroup에서도 parent task는 하위에 child task를 만들 수 있는데, 각각의 child task가 완료되어야 parent task가 계속될 수 있다. 이렇게 scope를 기준으로 코드에 의존성이 표현될 수 있다. 그리고 그렇기 때문에 이런 것들은 Swift compiler와 runtime에 명시적으로 알려진다. 그리고 이런 Task는 Swift runtime에 알려진 task(Continuation, child task)만 await 할 수 있다. 이렇게 제약이 걸려있기 때문에, Swift concurrency 원시 타입으로 만들어진 Swift concurrency는 runtime에 task간에 dependency chain을 명확하게 제공한다.
Cooperative thread pool
결국 이런 과정을 통해, thread는 task dependency에 대해 추론할 수 있고, 다른 task를 선택할 수 있다. 즉, 위의 과정들을 통해서 thread가 항상 무언가를 처리할 수 있는 runtime contract를 달성했다.
- 이는 Default executor로 Swift concurrency를 지원하는 새로운 형태의 thread pool이다.
- 새로운 thread pool은 CPU 코어 수만큼만 thread를 가지고 있다.(spawn)
- 낱알처럼 흩어진 concurrency를 제어한다.
- Worker thread는 block되지 않는다.
- thread explosion을 피하고, 과도한 context switching을 방지한다.
- workitem이 block되면 더 많은 thread를 spawn했던 GCD의 concurrenct queue와 다르게 Swift의 thread는 앞으로 나아갈 수 있다.
Reference
