
포스팅 이유
Kubernetes Cluster를 운영하며 발생하는 문제 상황들(ex. Pod Down, Node Down, Resource 과다 등..)을 보다 빠르게 확인하기 위해 Alertmanager 사용
Kubernetes Cluster 운영에 필수적인 모니터링 방안 중 하나이기 때문에 포스팅을 통해 정리
시작하며
Kubernetes Cluster를 안정적으로 운영하기 위해 가장 중요한 것을 두 가지 뽑자면 백업과 모니터링이라 생각합니다. 이 두 분야를 실무에서 담당한 경험이 있고 이런 경험에서 사용하고 공부한 내용을 포스팅을 통해 정리하고자 합니다.
1. Prometheus Rule 설정
환경정보
Prometheus와 Alertmanager를 Operator를 통해 설치한 환경
일단 Alert을 위한 Rule을 생성해야합니다.
실제 환경에 구성되어 있는 Rule을 예시로 먼저 보면
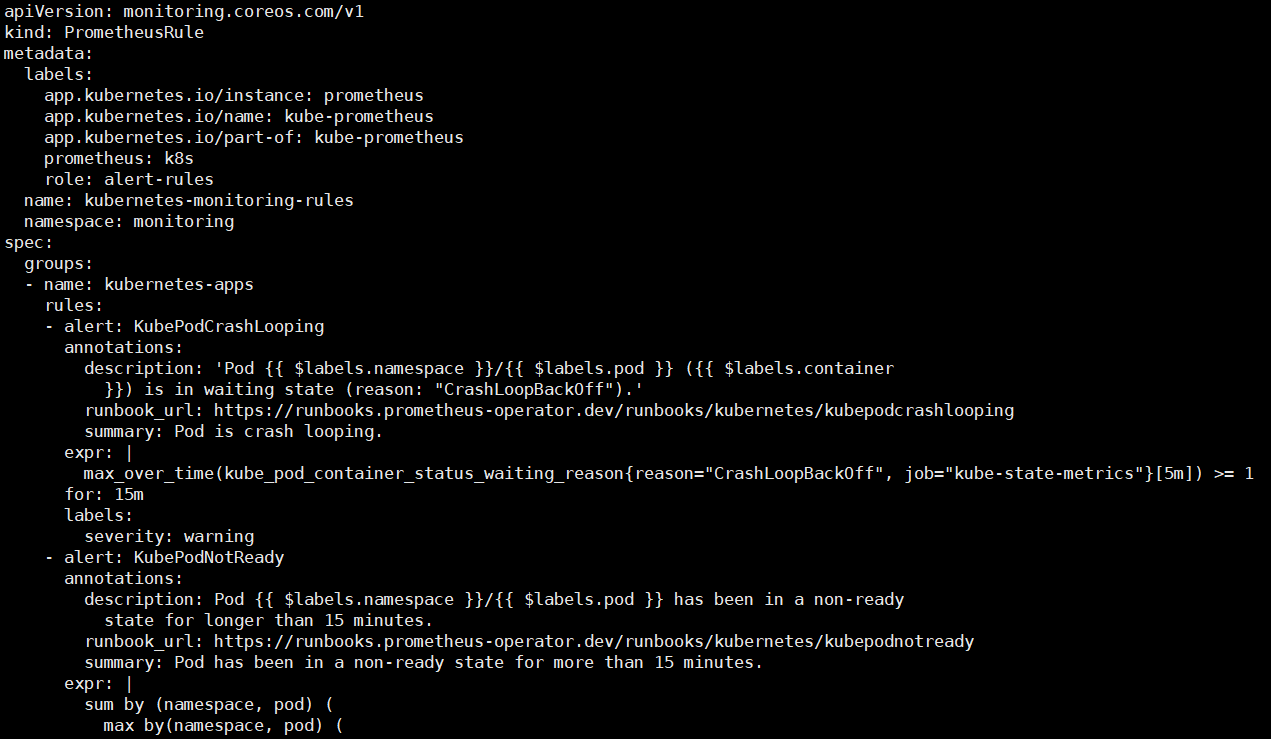
다음과 같습니다.
1.1 Rule 작성법
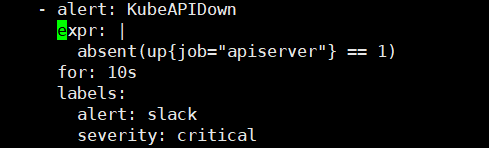
그럼 Kube-apiserver가 Down된 상황을 감지하는 Rule을 작성해보며 어떻게 Rule을 작성해야하는지 알아보겠습니다.
groups:
- name: Kubernetes-apps # 원하는 그룹명
# ...
- alert: KubeAPIDown # Alert명 *필수작성*
expr: |
absent(up{job="apiserver"} == 1) # Alert 조건 *필수작성*
for: 10s # 시간만큼 상황 지속 시 Alert 발생
labels:
alert: slack
severity: critical
annotations:
description: KubeAPI has disappeared from Prometheus target discovery.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeapidown
summary: Target disappeared from Prometheus target discovery.
# ...다음과 같이 KubeAPIDown alert을 만들었습니다.
label을 설정하여 Slack으로 특정 alert들만 묶어서 알람을 보낼 수 있습니다.
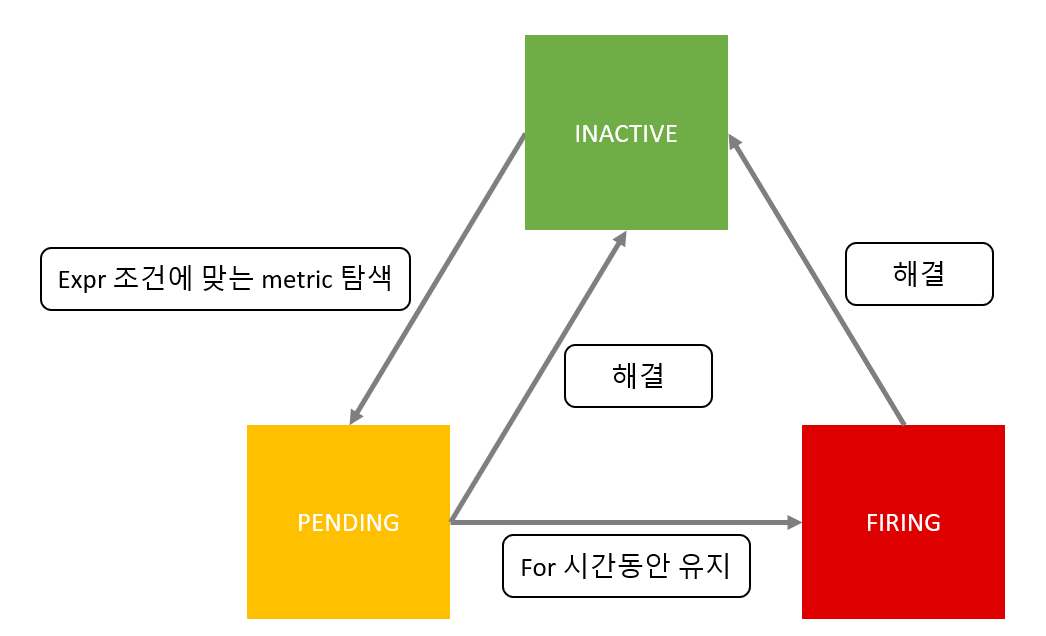
expr을 통해 alert 상황을 감지하고(PENDING) for에 명시한 시간이 지나도 상태가 지속될 경우(FIRING) 알람을 전송합니다.
그림을 통해 이 과정을 이해하면 쉽습니다.
이제 해당 Rule을 적용해줍니다.
적용이 끝나면 Prometheus Pod를 재기동하여 변경한 Rule이 적용될 수 있게 합니다.
2. alertmanager 설정
alertmanager쪽 설정을 할 때 일반적으로는 alertmanager.yml 파일의 수정을 통해 가능합니다. 하지만 해당 환경의 경우 operator를 통해 alertmanager를 설치하여 alertmanager.yaml파일을 secret을 통해 mount 시켜주는 구조를 가집니다.
2.1 alertmanager-config.yaml 작성
alertmanager-config.yaml 파일을 작성하고 yaml파일을 가지고 secret을 만들겠습니다.
alertmanager-config.yaml 예시 파일을 보면
global:
slack_api_url: ${ Slack Webhook URL }
receivers:
- name: default-slack-alert
- name: $ { alert 받을 slack 계정명 }
slack_configs:
- channel: '${ alert 받을 slack 채널명 }'
send_resolved: true
title: '[{{.Status | toUpper}}] {{ .CommonLabels.alertname }}'
text: >-
*Description:* {{ .CommonAnnotations.description }}
route:
group_wait: 0s
group_interval: 30s
repeat_interval: 12h
receiver: default-slack-alert
routes:
- match:
${ prometheusRule에 추가한 label }# 예시 alert: slack
receiver: $ { alert 받을 slack 계정명 }다음과 같습니다.
slack_api_url의 경우 slack에서 수신 웹훅 앱을 추가하면 URL을 받을 수 있는데 그때 발급 받은 URL을 입력하면 됩니다.
routes의 match항목에 label을 입력할 수 있습니다. 일치하는 label이 설정된 alert들만 routes의 receiver에게 알람을 보낼 수 있습니다.
실제로 작성해보면
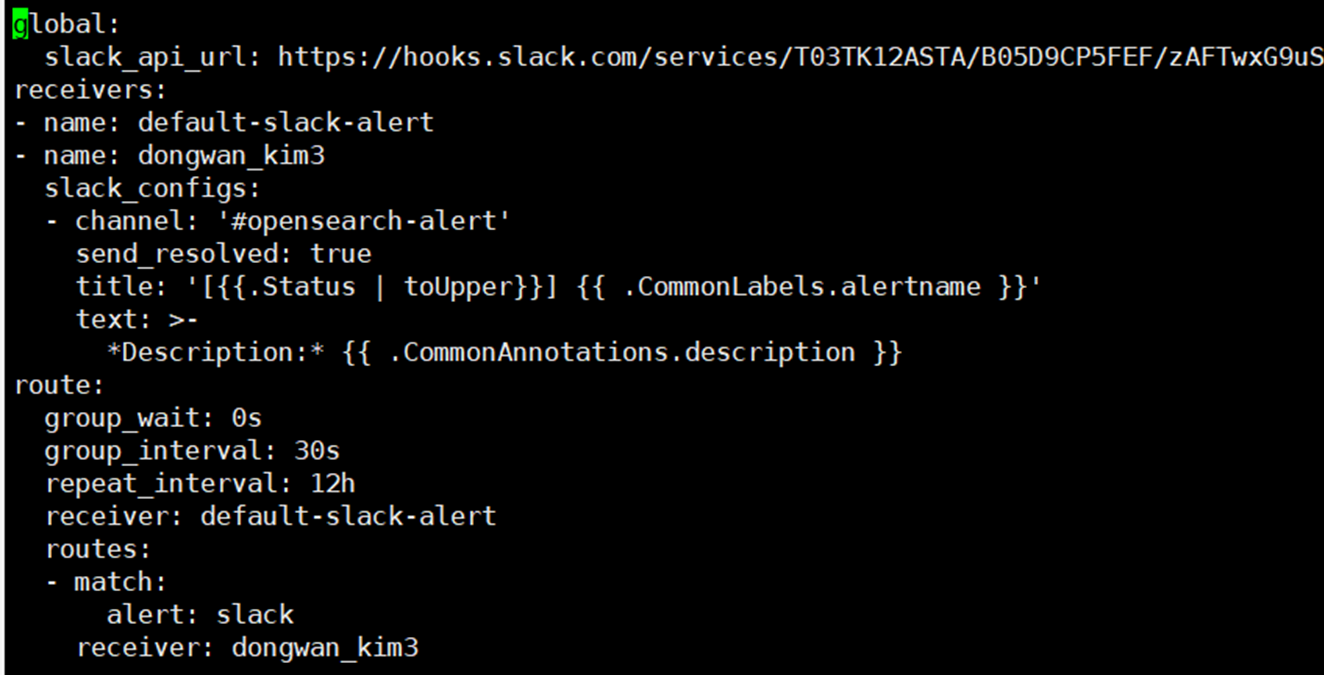
다음과 같습니다.
alert: slack label을 설정하여 이전 스텝에서 생성한 KubeAPIDown alert이 발생했을 때 알람을 받을 수 있게 구성하였습니다.
2.2 alertmanager-main sercert 재생성
이제 생성되어 있는 alertmanager-main secret을 삭제하고 방금 만든 alertmanager-config.yaml파일로 secret 을 재생성합니다.
# secret 삭제
$ kubectl delete secret -n { alertmanager 설치 ns } alertmanager-main
# secret 생성
$ kubectl create secret –n { alertmanager 설치 ns } generic alertmanager-main –from-file=alertmanager.yaml=alertmanager-config.yaml
# Alertmanager 재기동
$ kubectl rollout restart sts -n { alertmanager 설치 ns } { alertmanager sts명 }
3. 알람 확인
실제로 알람이 제대로 오는지 확인해보겠습니다.
일단 /etc/kubernetes/manifests/kube-apiserver.yaml 파일을 수정하여 apiserver가 뜨지 못하게 합니다.
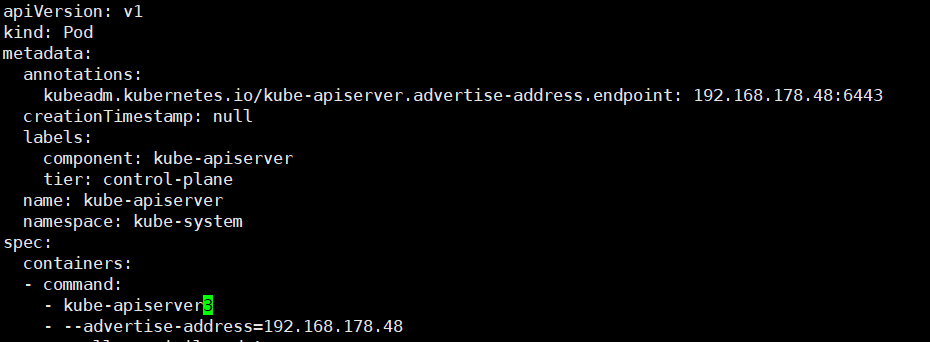
spec.containers.command 에서 kube-apiserver를 kube-apiserver3 이런식으로 다른 값으로 변경해주면 apiserver가 동작하지 못합니다.
이후 prometheus web console에 접속하여 Alerts 탭에 들어가 KubeAPIDown Rule의 상태를 확인합니다.
apiserver down이 감지되면 노란색으로 pending상태가 되고 for에서 설정한 10초가 지나면 빨간색으로 변하며 FIRING 상태가 됩니다.


그리고 다시 apiserver yaml을 원상복구시켜 apiserver를 정상화하면 INACTIVE 상태로 돌아감을 확인할 수 있습니다.

마지막으로 Slack에 정상적으로 알람이 왔는지 확인해보면

다음과 같이 알람이 도착한것을 확인할 수 있습니다. 장애가 발생한 상황과 정상화가 된 상황 모두 알람이 왔습니다.
마무리
-
Alertmanager를 통해 kubernetes cluster에서 이상 상황(Rule에서 설정한)이 감지됐을 때 알람이 오는것을 확인했습니다.
-
이를 활용하여 cluster 모니터링을 조금 더 편하게 할 수 있는 장점이 있습니다.
