
RDB를 처음 생각해냈던 Codd라는 사람은 이러한 말을 했다고 한다.
관계 조작(SQL)은 관계 전체를 모두 조작의 대상으로 삼는다.
이러한 것의 목적은 반복을 제외하는 것이다.
이처럼 초기 설계단계에서부터 SQL은 반복문을 지양하며 만들어진 언어라 한다.
그리고 그렇게 한 이유는 '최종 사용자와 응용 프로그래머의 생산성을 위해서'라고
Codd는 설명한다.
CREATE OR REPLACE PROCEDURE PROC_INSERT_VAR
IS
/* 커서 선언 */
CURSOR c_sales IS
SELECT company, year, sale
FROM Sales
ORDER BY company, year;
/* 레코드 타입 선언 */
rec_sales c_sales %ROWTYPE;
/* 카운터 */
i_pre_sale INTEGER :=0;
c_company CHAR(1) :='*';
c_var CHAR(1) :='*';
BEGIN
OPEN c_sales;
LOOP
/* 레코드를 패치해서 변수에 대입 */
fetch c_sales into rec_sales;
/* 레코드가 없다면 반복을 종료 */
exit when c_sales%notfound;
IF (c_company = rec_sales.company) THEN
/* 직전 레코드가 같은 회사의 레코드 일 때 */
/* 직전 레코드와 매상을 비교 */
IF (i_pre_sale < rec_sales.sale) THEN
c_var :='+';
ELSEIF(i_pre_sale > rec_sales.sale) THEN
c_var :='-';
ELSE
c_var :='=';
END IF;
ELSE
c_var :=NULL;
END IF;
/* 등록 대상이 테이블에 테이블을 등록 */
INSERT INTO Sales2 (company, year, sale, var)
VALUES (rec_sales.company, rec_sales.year, rec_sales.sale, c_var);
c_company := rec_sales.company;
i_pre_sale := rec_sales.sale;
END LOOP;
CLOSE c_sales;
commit;
END;책에서 말하는 '한번에 한 레코드' 사고방식의 PLSQL이다.
간단하게 이 SQL을 설명하자면 작년의 매출과 비교하여
올랐으면 '+', 내렸으면 '-', 같으면 '='을 표현하고
그 결과를 Sales2라는 Table에 새롭게 저장하는 SQL이다.
IF (c_company = rec_sales.company) THEN
/* 직전 레코드가 같은 회사의 레코드 일 때 */
/* 직전 레코드와 매상을 비교 */
IF (i_pre_sale < rec_sales.sale) THEN
c_var :='+';
ELSEIF(i_pre_sale > rec_sales.sale) THEN
c_var :='-';
ELSE
c_var :='=';
END IF;
ELSE
c_var :=NULL;
END IF;이 부분을 계속해서 반복하면서
직전 row와 해당 row를 비교하여, 해당 row의 '+-=' 여부를 결정한다.
좀 길긴하지만 반복문에 익숙한 나에게는 '그러면 어떻게 하라는거지?'라는 생각이 들었다.
먼저 저자는 이렇게 한줄한줄 처리하는 반복문을 주로 사용하는 방식을 '반복계'
여러 행을 한번에 처리하는 방식을 '포장계'라고 지칭하며 비교를 시작한다.
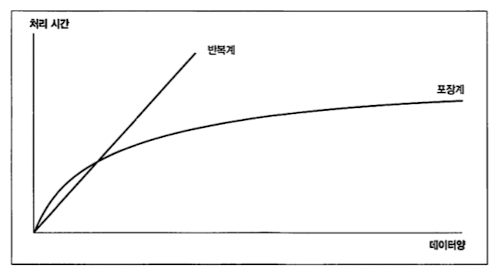
먼저 가장 문제가 되는 것은 일단 '성능'이다.
처리 횟수 x 한 회 처리에 걸리는 시간 = 총 시간
반복계의 경우 위와 같은 계산 방법을 가지기 때문에 총 처리 시간이 선형적으로 증가한다.
레코드 수가 많지 않다면 큰 차이가 없거나 오히려 반복계가 빠를 수도 있으나
대용량 레코드로 넘어갈 수록 이러한 차이는 점점 벌어진다고 저자는 주장한다.
<반복계의 단점들>
1. 같은 SQL 문을 반복 실행하므로 SQL 구문 분석이 반복되어 불필요한 낭비가 있다.
2. 반복계의 1회 처리는 굉장히 단순하여 병렬 처리와 같은 최적화가 어렵다.
3. DBMS는 벤더들은 복잡한 SQL을 처리하는 것을 목표로 연구중인데
단순하고 가벼운 SQL 구문을 처리하는 반복계는 추후 이러한 혜택을 받기 어렵다.
4. 반복계의 SQL은 튜닝이 가능한 영역이 거의없기 때문에 추후 개선도 어렵다.
저자가 주장하는 반복계가 포장계에 비해 성능이 떨어지는 큰 이유들이다.
처음 읽었을 때는 그런가보다 했는데 다시 읽어보니 내 이해가 부족해서인지
좀 추상적으로 느껴졌다.
<반복계의 장점들>
1. SQL 구문이 단순하여 실행 계획의 변동이 적고, 성능이 안정적이다.
2. 각 구문이 개별적으로 실행되기 때문에 트랜젝션 제어가 편리하다.
(중간에 실패하면 그 지점부터 다시 처리를 시작하면 된다.)
반복계라고 단점만 있는 것은 아니고 위와 같은 장점들도 존재한다.
하지만 저자는 '성능'이라는 측면에서 비교가 안될 정도이므로
둘의 장단에 대한 신중한 고려를 추천한다.
도대체 그러면 어떻게 어떻게 작성하는 것이 성능 좋은 포장계 SQL인가?
라는 의문이 들었는데 핵심은
'CASE 식과 윈도우 함수를 잘 활용하여 반복을 대신하는 것'이다.
INSERT INTO Sales2
SELECT company,
year,
sale,
CASE SIGN(sale - MAX(sale)
OVER(PARTITION BY company
ORDER BY year
ROWS BETWEEN 1 PRECEDING
AND 1 PRECEDING))
WHEN 0 THEN '='
WHEN 1 THEN '+'
WHEN -1 THEN '-'
ELSE NULL END AS var
FROM Sales위의 반복계 SQL을 포장계 SQL로 바꾼 Code이다.
같은 결과이지만 좀 더 간결하게 표현이 가능하다.
표현도 간결하지만 같은 구문을 반복하는 것이 아니므로
위에서 말한 불필요한 구문 분석이 사라진다.
(SIGN(), ROWS BETWEEN 을 추가로 공부할 필요는 생긴다.)
SIGN : https://uniksy1106.tistory.com/168
ROWS BETWEEN : https://tiboy.tistory.com/570

장의 마지막에는 심리학의 내용으로 '망치라는 도구만을 가지고 있는 사람에게는 모든 문제가 못으로 보인다' 말을 인용하며 반복을 너무나도 강력한 망치라고 표현한다.
저자는 반복계와 포장계 사이에는 TradeOff가 있지만 RDB의 고성능을 추구한다면
기존 절차지향적 세계관의 방법인 반복계를 넘어
집합지향적 세계관의 포장계 방식을 고려할 것을 강력하게 강조한다.

나도 책을 보면서 포장계가 성능은 좋을 수도 있겠지만
포스팅하지 않은 다른 예제 SQL들을 보며 오히려 가독성이 떨어질 수도 있고
같이 유지보수를 진행해야할 동료들이 이해하기 어려운 Code일 수 있겠다는 생각이 들었다.
물론 성능은 굉장히 중요한 포인트이지만 어떤 상황이나 시점에서는
더 중요한 것들(생산성, 협업, 안정성 등)이 있을 수 있다고 생각한다.
하지만 이렇게 다양한 도구를 다루는 능력이 있다면 상황과 필요에 따라
방법을 선택할 자유도가 생기는 것이라 생각하며 무조건적인 지향은 경계해야겠다.
참고도서 : SQL 레벨업(한빛미디어)
