
[왜 SQL 튜닝인가?(Why)]
Application 성능을 향상 시키는 방법에는
Caching, DB Replication, Shading, Scale up/out... 등이 있겠지만
가장 가성비가 좋고(추가적인 요소나 비용이 들지 않고)
근본적인 해결책은 SQL 튜닝이므로 가장 먼저 적용할 방법이다.
(Server 연산이 병목이 되는 경우는 드물고, Data가 쌓일 수록 DB 연산의 부담은 커진다.)
[어디에 집중해야 할까?]
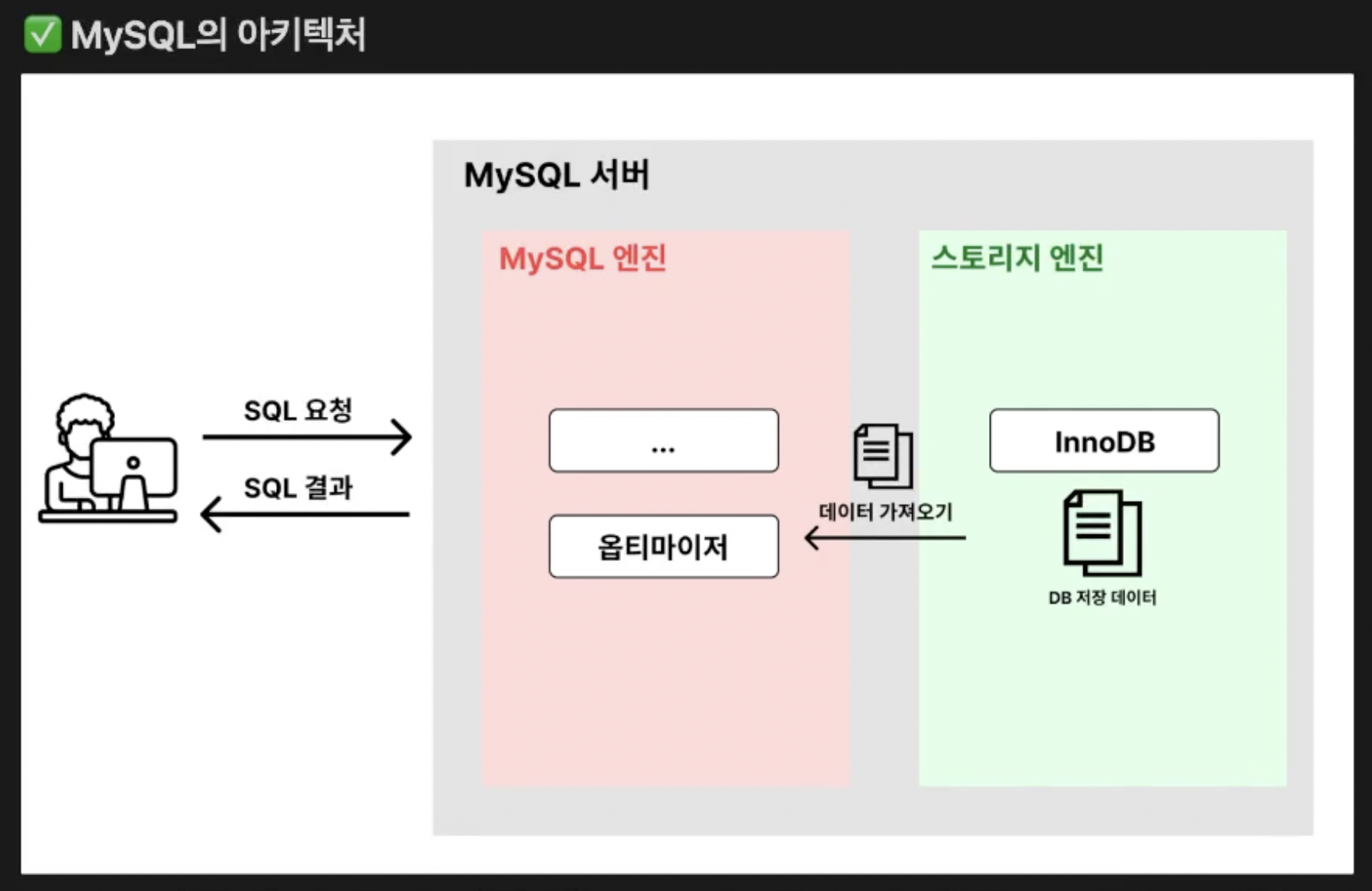
SQL 요청 -> 옵티마이저의 SQL 실행 계획 분석 후 요청 ->
“스토리지 엔진에서 Data 가져오기” -> MySQL 엔진에서 정렬, 필터링 등의 후처리
DB 연산에서 보통 가장 병목이 되는 것은 "조회"이고 조회는 위와 같은 과정을 거친다.
그 과정에서 가장 신경써야 하는 부분은 스토리지 엔진에서 Data를 가지고 올때 어떻게
- 적은 양의 Data를
- 찾기 쉬운 형태로 바꿔서 가져오는가
두가지이고 이것을 빠르게 처리하기 위한 방법이 Index이다.
[Index 한번 더 정리]

특정 컬럼을 index로 지정하면 지정한 컬럼을 기준으로 정렬된 별도의 Index Table을 생성하게 된다.
(pk와 함께 저장되므로 row에 빠르게 접근 가능 -> 모든 row에 접근할 필요가 없다!)
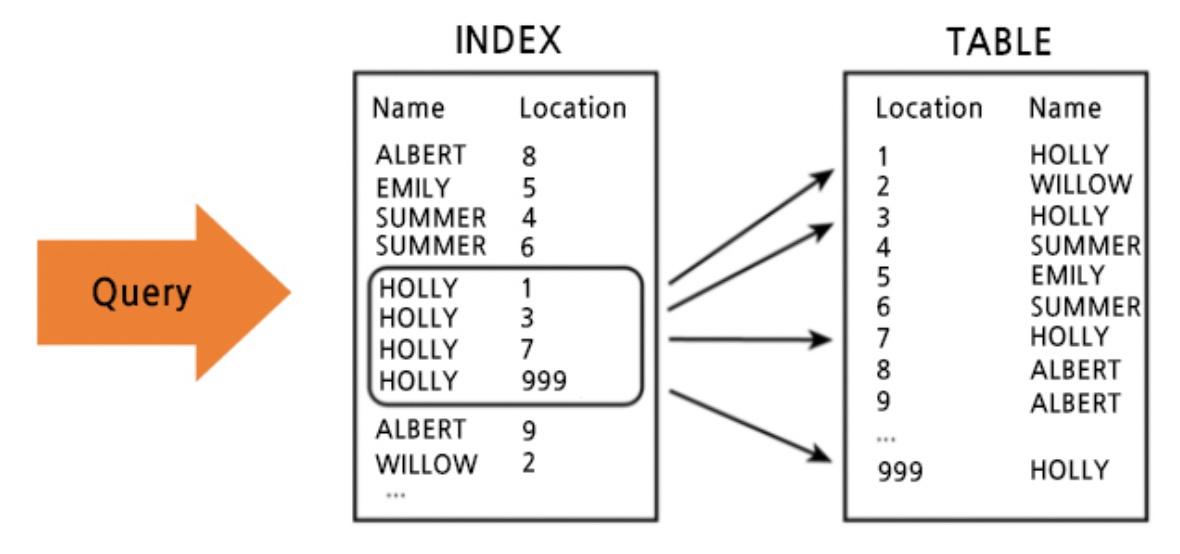
Query 요청
-> Index 테이블에서 key(특정 조건)의 value(PK) 확인 (B+Tree 구조) : O(log N)
-> PK로 Data 테이블에서 정보 선택 - Clustered Index + B+Tree 구조 : O(1)에 가까움
위와 같은 과정으로 Index 가 동작하기 때문에 인덱스를 사용하지 않는 경우의 복잡도인
Full Table Scan(O(N)) 대신 O(log N) + O(1)의 복잡도로 Data를 빠르게 가져올 수 있다.
(Clustered Index는 PK를 찾으면 그 자체로 데이터 레코드의 위치를 찾은 것과 같음 : O(1))
[복합 Index & 커버링 Index]
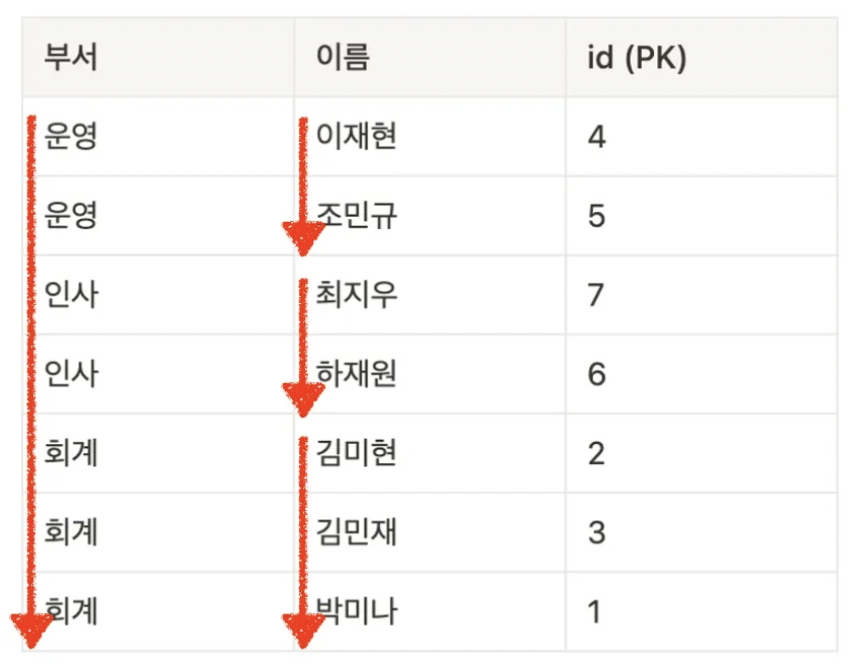
<복합 Index>
Index(부서, 이름) -> "부서"로 먼저 정렬하고, 이후 "같은 부서" 안에서 "이름"을 기준으로 정렬
주의사항
-
부서 column만 있는 별도의 index를 만들 필요는 없음
(복합 Index의 첫 column는 일반 index와 같음) -
두번째 column의 경우는 따로 만들어줘야 별도 Index 사용 가능
-
위의 사례처럼 중복도가 높은(카디널리티가 낮은) 부서를 먼저 Index로 잡는 것이 아니라
중복도가 낮은(카디널리티가 높은) 이름을 앞쪽 Index로 하는 것이 더 효율적일 수 있다.
ex) Index(이름, 부서) - 상황에 맞게 설정
<커버링 Index>
select 요소(Projection) / 조건절을 모두 포함하고 있는 index가 존재하는 경우 -> 커버링 Index
옵티마이저는 실제 Data 테이블에 아예 접근하지 않고 Index 테이블만 접근해서 처리함(2번-> 1번)
