1. 파일 시스템 일관성
1. Consistency 란?
1. 정의
- 유효한(일관된) 상태로 남아 있는것
2. 대표적인 방법
1. fsck(File System checker)
- A reactive approach
- 파일 시스템이 일관성을 유지하고 있는지 확인할 수 있는 도구
- 일관성에 문제가 있다면 그것을 해결해줌
체크 순서
- 슈퍼블록
- 비트맵을 통해 free block 확인
- 아이노드
- 디렉토리
문제점
- 너무 느리다
2. Journaling(기록)
- An proactive approach § Ext3, Ext4, Reiserfs, IBM’s JFS, ...
- 쓰기전에 로그를 남겨둠
-> 디스크를 업데이트 하기전에 어떤 내용을 업데이트 할 지 로그를 남겨두는 것저널링 순서
- write 가 발생하면 해당 내역을 Commiting
-> 최종위치에 쓰기 전에 로그에 먼저 기록
-> TxB(trasaction begin) 과 TxE(trasaction end) 사이에 기록- Checkpointing
-> 트랜젝션을 디스크에 안전하게 만들고 나면, 원본데이터를 업데이트 할 준비 완료됨Crash 발생시 Recovery
- 로그를 보고 redo(저널링이 유효할때) 또는 undo(저널링이 유효하지 않을때)
문제점
- 저널의 유효성을 어떻게 체크?
-> 트랜젝션의 개념을 도입
-> 트랜젝션이란 모두 발생하거나 아무 일도 일어나지 않는 일련의 작업
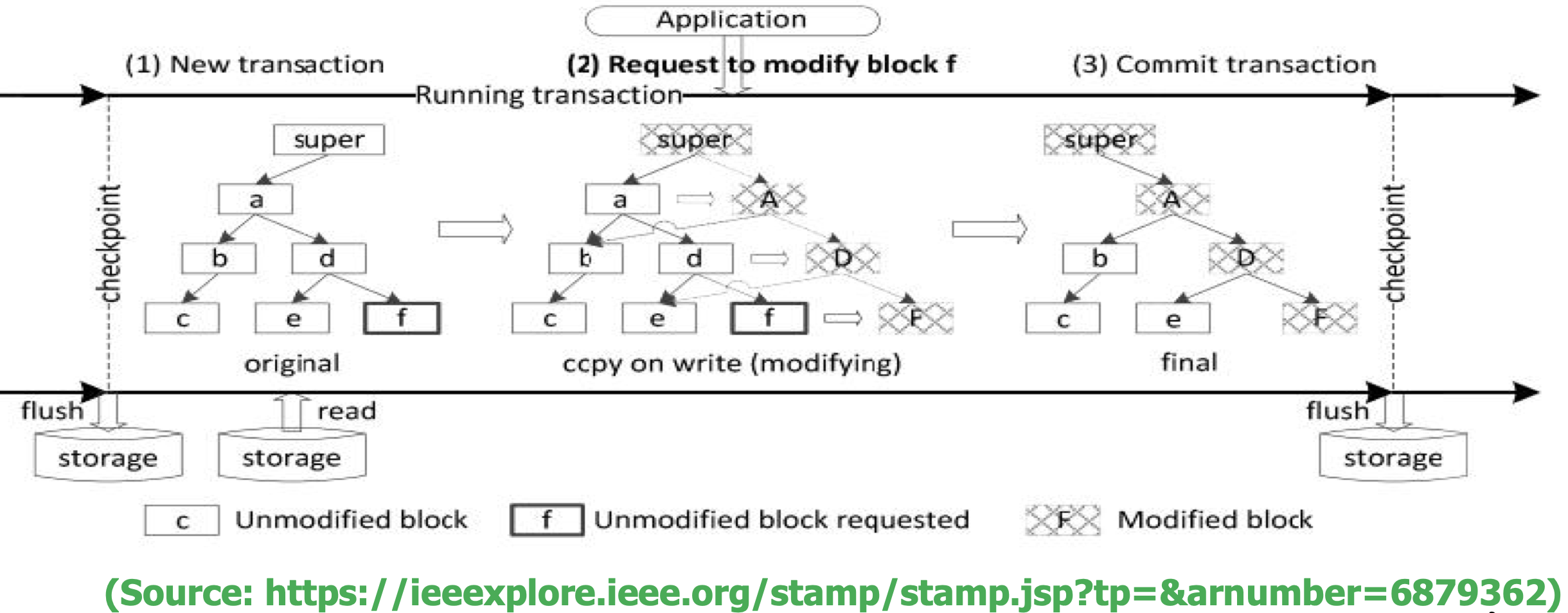
3. COW (Copy on Write)
- Used in Btrfs and Sun’s ZFS
- 데이터의 수정이 일어나면 해당위치(inplace update)가 아닌 다른 위치(out of place update)에 저장
4. Optimistic crash consistency
- Enhance performance by issuing as many writes to disk as possible
- Exploit checksum (or others) to validate integrity
5. Soft update
- Carefully order all writes so that on-disk structures are never left in an inconsistent state (e.g. data block is always written before its inode)
- Soft update is not easy to implement since it requires intricate knowledge about file system (on contrary, journaling can be implemented with relatively little knowledge about FS)
2. 여러 파일 시스템들
1. EXT4
- block(4kb) 기반에서 extent(segment와 비슷한 개념) 기반으로 변경해 더 큰 파일 크기 파일 지원
- 디렉토리는 64000개의 subdir 가질 수 있음
- 무제한 디렉토리
2. FAT(File Allocate Table)
- 작은 크기의 스토리지를 위한 파일 시스템
- 메타데이터를 위한 공간을 줄여야 작은 크기의 스토리지를 효율적으로 사용 가능
- 부트 섹터 , FAT1/2, Root, Data Area로 구성
- FAT는 bitmap + location information for all files 역할
3. NFS(Network File System)
- NFS 클라이언트와 NFS 서버
- inode는 "서버 + file" 을 지칭함(기존 파일 시스템에서 데이터 블록을 지칭하던것과 다르게)
4. GFS(Google File System)
- GFS client, GFS master, GFS chunk servers 로 구성됨
- File은 chunk들로 구성되는데 chunkr 1개의 크기는 64MB
- 클라이언트는 마스터로 부터 chunk가 저장되어 있는 서버의 위치를 받아오고, 서버에서 chunk들을 받아옴
- write 시, 3대의 chunk서버에 데이터를 저장, 데이터 오류 발생시 다른 chunk 서버로 부터 복구
- read 시, 3대의 chunk 서버에서 데이터를 병렬적으로 받아와서 속도 향상
- 이외에 스냅샷 기능이 있음
- HDFS(하둡 파일 시스템)은 GFS의 오픈소스 버전
5. LFS(Log-structured FS)
- 로그 구조: 모든 수정 사항을 로그와 같은 구조로 작성(추가 전용, 일종의 외부 업데이트)
3. 플래시 메모리
1. SSD(Solid state Drives)
1. 저장 장치
- 플래시 메모리 기반(NAND)
- 내부적인 컴퓨팅 자원이 있음
- 호스트 인터페이스 제공(PCIe, SATA, SCSI)
- Parallel unit(여러 칩과 여러 채널) -> 성능 높여준다
SSD 내부에 컴퓨팅 자원이 있는 이유
- 플래시 메모리의 특성을 다루기 위해
- FTL(Flash Translation Layer)가 플래시 메모리를 디스크처럼 추상화 해주기 위함
2. 디스크 VS 플래시 메모리
1. 공통점
- 비휘발성 저장장치
2. 차이점
- 플래시 메모리는 기계적인 부품이 없어 충격에 강하고 전력소모가 적고 크기가 작음
- 디스크보다 빠르다
- Overwrite에 제한이 있음, Write를 위해서는 erase()가 먼저 진행되어야 함
- read/write는 4kb(page unit) 씩 가능, 하지만 erase()는 2MB(block unit, 여기서 block는 page들의 집합, 한개의 칩셋?) 단위
- 내구성: 제한된 횟수의 erase()만 가능
3. FTL - Out of place Update and Mapping
- erase() 작업은 또한 시간이 오래 걸림
- 이러한 문제로 FTL을 이용해 write 발생시 다른 위치에 write하고, FTL(맵핑 테이블 기능을 제공)을 업데이트 해줌
- Free space가 부족하면 garbage collection을 통해 erase() 작업 수행
4. FTL - Garbage Collection
- FTL이 제공하는 기능
- 향후 할당을 위해 무효화된 페이지를 회수하는 작업
- 무효화된 페이지가 있는 블록을 erase()
erase() 할 블록을 결정하는 정책
- 무효화된 페이지가 가장 많은 블록
- 가장 오래된 블록
erase() 할 블록이 선정되면?
- 유효한 블록들은 복사해서 뒤에 쓰고,
- FTL(맵핑 테이블) 에 복사된 위치 업데이트
- 해당 블록 erase()해주고 해당 공간 free
5. FTL - Wear leveling
- 블록들이 erase() 된 횟수를 카운트해서,
- 만약 한계치의 erase()에 도달한 블록이 있으면
- 그 블록을 제외하고 다른 블록에서 erase() 작업을 수행할 수 있도록 해줌
- 또한 이러한 상황까지 가지 않도록 블록당 erase() 횟수를 비슷하게 맞춰줌
- SSD의 수명을 늘려준다

Dev Ops, "Git, Linux, Docker, Kubernetes, ansible, " .