데이터베이스 접근 로직 테스트 정의
도메인 클래스를 기반으로 어떻게 데이터베이스를 연결지어 사용 할 것인지에 대해 고민해본다. 또한 어떤 데이터베이스를 사용할 것인지, 실제 db와 테스트 db를 따로 둘 것인지 등을 정리하고 테스트를 정의를 한다.
github 프로젝트 카드 작성
DB기술 선택(DB 종류 결정)
어떤 데이터베이스를 사용 할 것인지 결정 할 때에는,
요즘에 어떤게 많이 쓰이는지도 보면 좋다.
이 때, DB ENGINES 사이트를 활용해보자.
해당 사이트는 계속해서 DB기술 동향 등을 분석(얼마나 트윗되었는지, 구글트랜드 분석 등)해서 순위를 측정하고 있다.
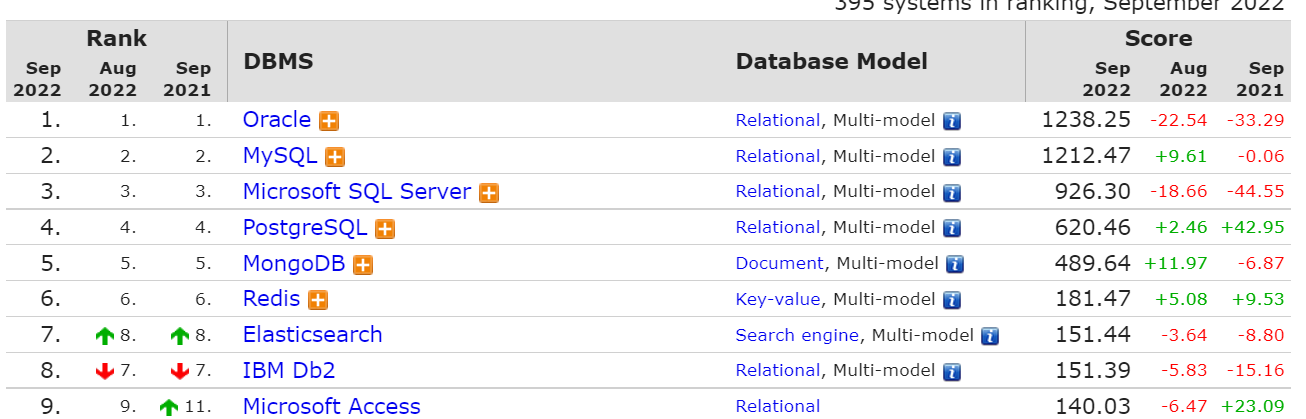
위와 같이 어떤 db가 가장 많이 사용되는지 확인이 가능하다.
MySQL 선택 이유 : 실무, 공부 두 분야에 두루두루 널리 사용
DB에 접근할 수 있는 상태로 환경 세팅
MySQL 설치
MySQL 홈페이지에 들어가 다운로드한다.

요즘 mysql에서 밀고있는 오라클 클라우드에서만 사용가능한 HeatWave.
5400배 빠르고 등등 엄청 자랑중이다.
하지만 나는 무료 community 버전을 사용 할 예정이다.
편하게 GUI로 사용하고싶을 때는 MySQL Workbench를 사용하면 된다.
하지만 나는 MySQL Community Server 를 사용 할 예정이다.
참고한 사이트 에서 나는 server 하나만 설치했다.
MySQL 연결 확인
그리고나서 jetbrains 에서 제공하는 datagrip을 사용하여 MySQL 연결을 해본다.
datagrip이란?
db통합관리도구. 다양한 DB들을 연동해서 사용 가능하다.
intellij 에서 오른쪽 메뉴 툴 바에서 DataBase -> datasource ->MySQL을 눌러 연결을 확인해보도록 하자.
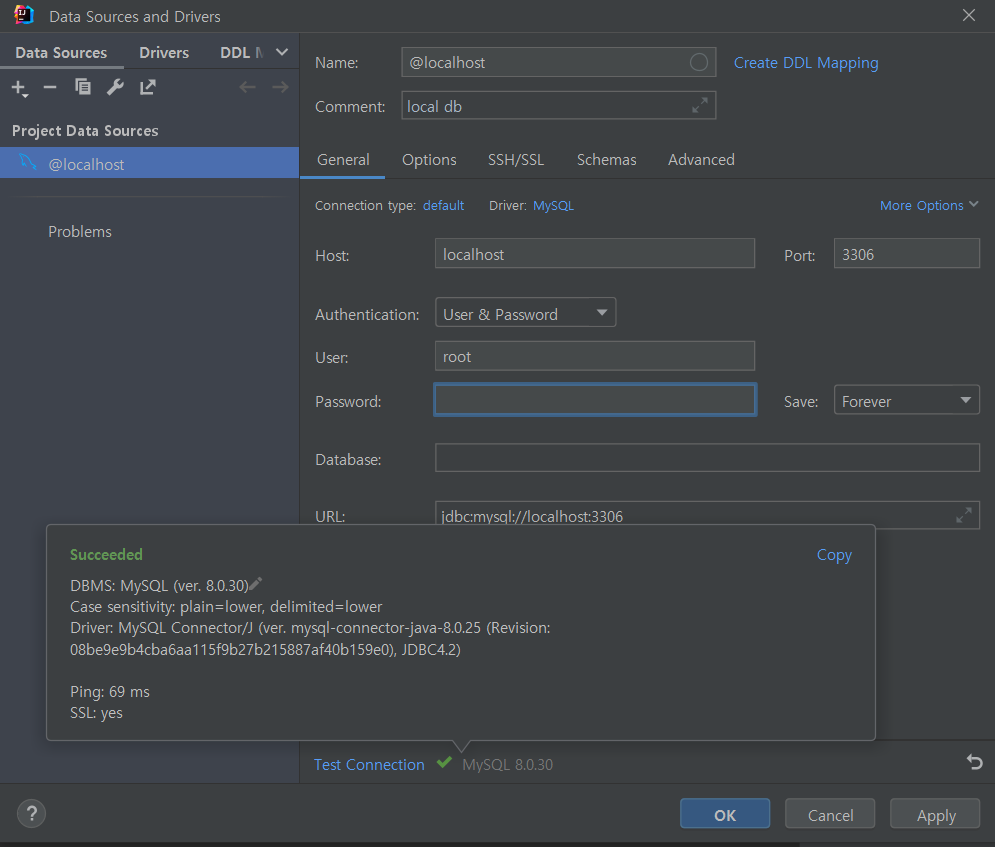
위와같이 비밀번호 등을 입력하고 Test Connection을 눌러서 succeeded 가 뜨면 연결이 된다는 뜻이다.
success를 확인 후, Apply 누르고 OK를 누른다.
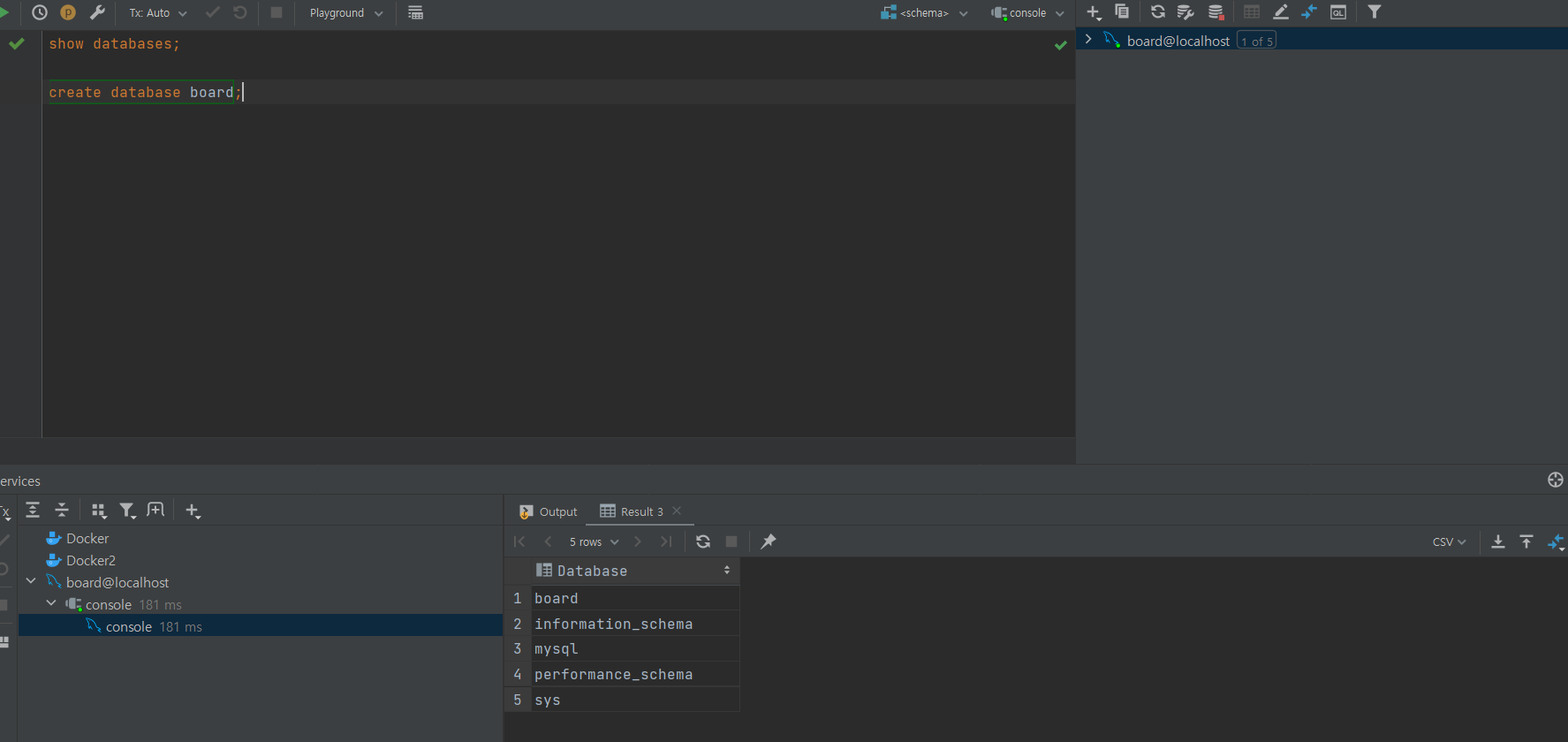
그러면 명령어 창에 이렇게 db 쿼리문을 쓸 수 있다.
테이블 및 유저생성
먼저 board database를 create 하였다.
ctrl + enter : 쿼리를 한줄만 실행할 지, 전체 실행할 지 선택 가능한 단축키.
위의 사진과 같이 선택이 가능하다.
그리고나서 접근하는 방식도 다르게 하기 위해서 data source properties 를 눌러 수정한다.

database에 아까 만든 board 를 입력한 후에, test connection 확인 하고 apply, ok 를 누른다.
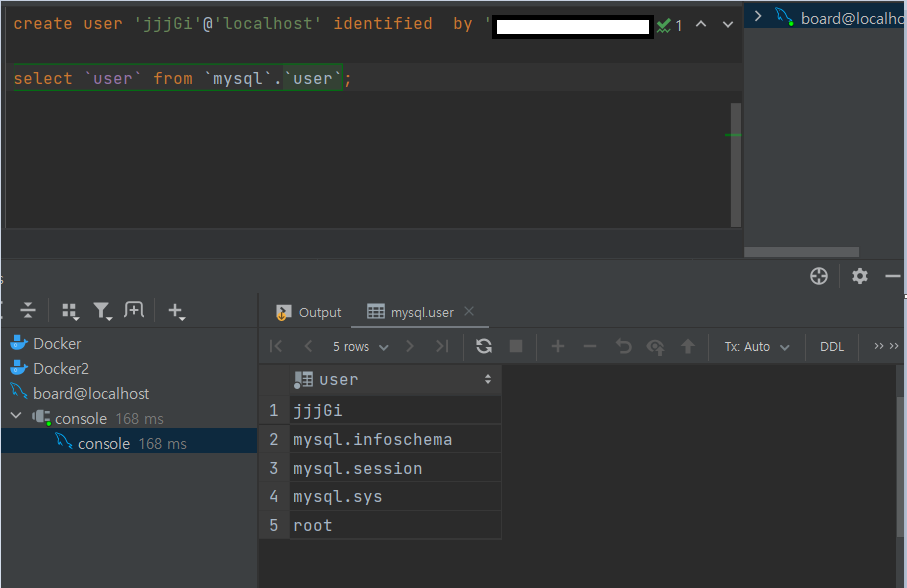
그리고 계속해서 root 계정으로 사용하면 문제가 발생했을 때 곤란하므로, 전용 사용자계정을 만들자.
create user '유저명'@'localhost' identified by '비밀번호'; //local에서 접속가능한 유저 생성
select `user` from `mysql`.`user`; // user 정보 조회. 벡틱임 주의!! 유저를 생성한 후, mysql db의 user 테이블에서 유저 정보를 확인 가능하므로 위와 같이 쿼리를 날렸다. 내가 만든 유저가 잘 저장되어 있는것을 확인 할 수 있다.
위와 같이 마우스 호버를 하면 해당 테이블의 필드와 필드들의 타입 등을 보여준다.
이를통해mysql.user테이블에 user정보가 있다는 것도 확인이 가능하다.
또, 여기서 끝나지 않는다!! 사용자 권한을 확인해보자.
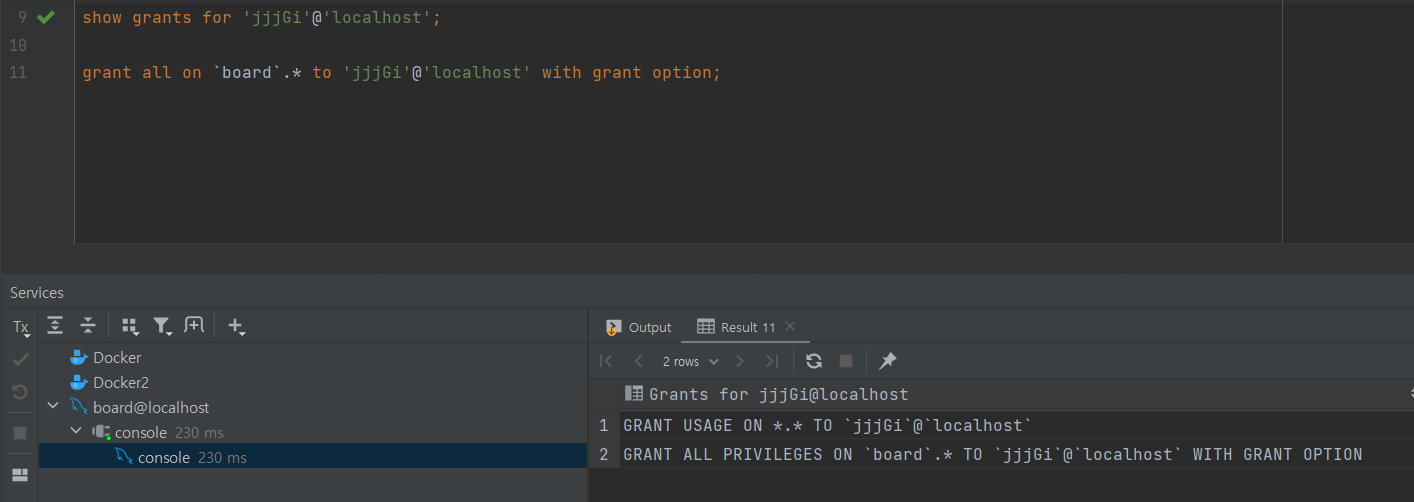
show grants for '유저명'@'localhost';위의 명령어를 통해 유저의 권한을 확인 해 보았을 때, 위의 사진과 같이 USAGE 만 있다면 별 권한이 없는것이다.
grant all on 'db명'.* to '유저명'@localhost with grant option;위의 명령어를 통해 특정 db의 모든 테이블에 권한을 유저에게 주며, with grant option을 통해 자신과 동일한 권한을 다른이에게도 부여가능한 권한을 가지게 한다.
권한 부여 후, 다시 권한을 확인하면 위와 같이 board의 모든 권한이 부여된 것을 확인 할 수 있다.
권한 넣어줬는데 안뜬다면?
flush privileges;위를 실행해보자.
JPA, MySQL driver, h2
spring boot에다가 db접근기술로 어떤걸 사용할지도 정해야 한다.
- 연결 : JPA
- 커넥터 : MySQL 드라이버
- 테스트용 인메모리 db : h2
테스트 할 시 실제 db에 영향이 가지 않게끔 테스트용 인메모리 db를 따로 둘 것이다.
설치

spring initializr 사이트에서 gradle선택하고, dependencies를 위와 같이 설정해준다.

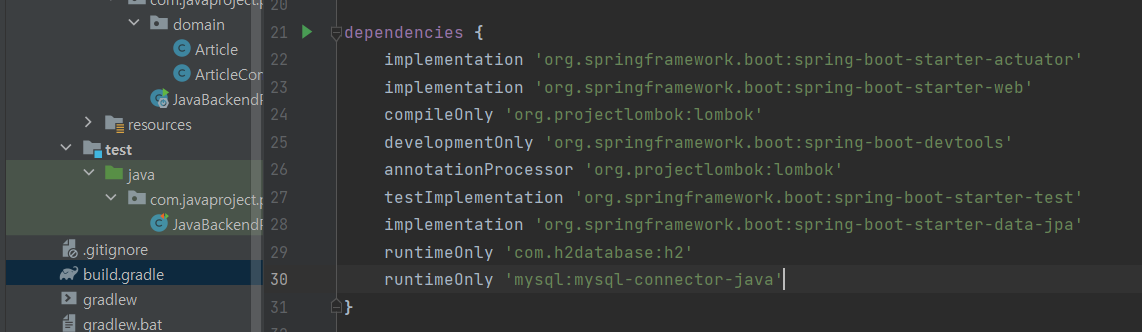
그리고 필요한 부분만 복사 하여 build.gradle의 dependencies에 붙여넣는다.
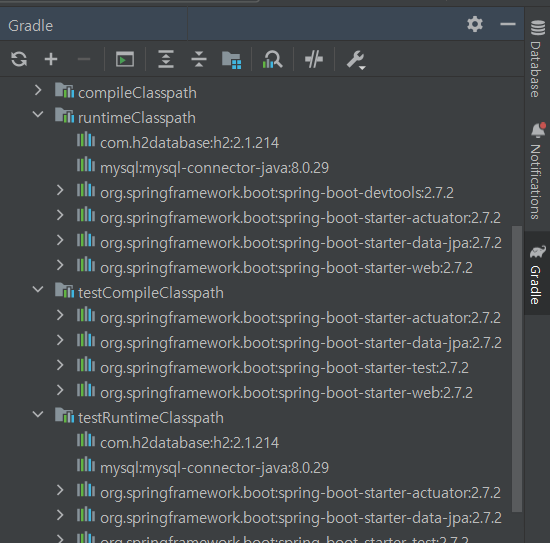
그리고 gradle을 새로고침하고나서 설치가 완료되면, 위와 같이 dependecies 폴더에서 확인 가능하다.
그리고 위와같이 JPA buddy에서 제공해주는 JPA structure도 보인다.
properties 세팅
jpa를 추가시켰으니까 리소스에서 application.properties 에서 jpa접근 property를 세팅 해줘야한다.
이때,propertiy 파일을 사용하기 편하게 yaml파일로 rename 하여 바꿔보자.
# spring boot의 각종 디버그 볼거냐
debug: false
#엑츄에이터: 스프링 부트 애플리케이션에서 제공하는 여러가지 정보를 모니터링하기 쉽게 해주는 기능,
#엑츄에이터의 감춰진 기능을 모두 활성화 시키는 것.
management.endpoints.web.exposure.include: "*"
#debug false로 하는 대신 보고싶은 로그들
logging:
level:
com.fastcampus.projectboard: debug
# request response 로그
org.springframework.web.servlet: debug
# 쿼리 ? 로 나오는거 실제 값 관찰
org.hibernate.type.descriptor.sql.BasicBinder: trace
spring:
datasource:
url: jdbc:mysql://localhost:3306/board
username: jjjGi
password: 내비밀번호!!!
driver-class-name: com.mysql.cj.jdbc.Driver
jpa:
defer-datasource-initialization: true
hibernate.ddl-auto: create
show-sql: true
# 추가 프로퍼티로 jpa 구현체에 종속된 프로퍼티 따로 설정가능. spring 에서지원해주지 않는 구현체 전용 프로퍼티는 이렇게 사용 가능.
properties:
# 디버그 쿼리문 정리
hibernate.format_sql: true
hibernate.default_batch_fetch_size: 100
# h2 웹에서보는거
h2.console.enabled: true
# data.sql을 언제 작동시킬 것인지.
sql.init.mode: always
#yaml은 ---로 문서를 여러개 만들 수 ㅇ
---
#doc 2. 특정 프로파일에 작동하는 spring
#testdb가 activate 되었을 때 이 문서를 읽는다.
spring:
config.activate.on-profile: testdb
# datasource:
# url: jdbc:h2:mem:board;mode=mysql
# driver-class-name: com.mysql.cj.jdbc.Driver
# jpa.hibernate.ddl-auto: create
# sql.init.mode: always테스트
현재 테스트를 돌려보면 돌아가긴 한다.
하지만, 지금은 repository나 Domain, Entity 이런게 하나도 잡히지 않아서 실제로 어떻게 연결되는지 관측하기 어렵다.
Entity를 만들어보자.
그 전에, 인덱싱을 위해 ERD를 조금 수정해본다. (사이즈 조정)
draw.io를 사용하기위해 feature 브랜치를 원격에 push한다.
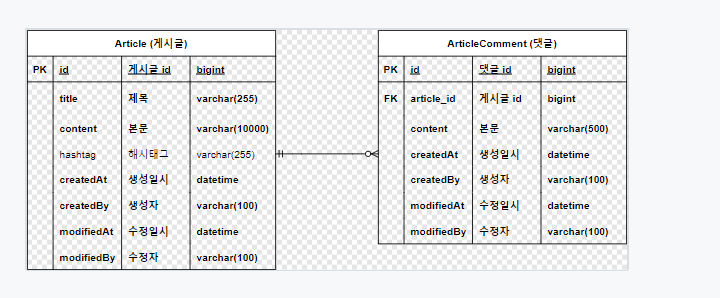
그리고 위와같이 사이즈를 조정하고 feature branch에 저장한다.
그리고 feature branch에서 fetch 이후 pull을 진행한다.
Entity정의
JPA 활용하여 Entity를 정의해보자.(Article.java, ArticleComment.java)
Article.java
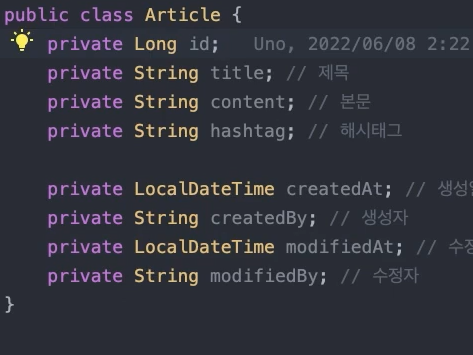
현재 이처럼 data만 간단하게 domain만 간단하게 설명되어있다.
여기에 JPA Annotation을 이용해서 Entity로 바꿔볼 것이다.
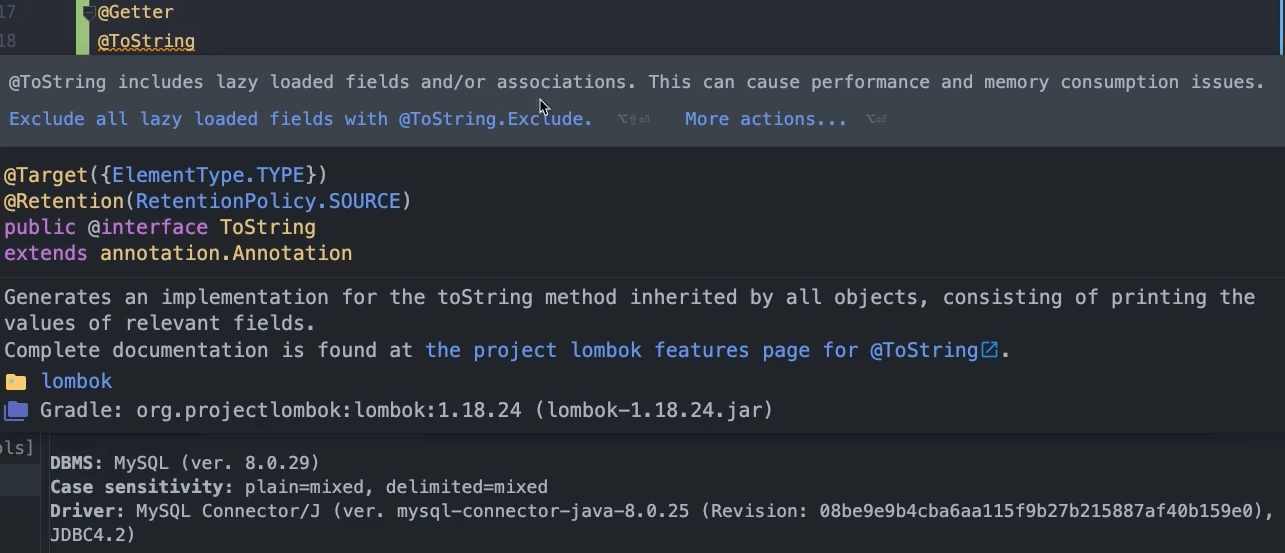
@Getter
@ToString
//빠른 검색 가능하게끔 인덱싱. 너무 긴 내용은 인덱싱 최대범위에 못도달.
@Table(indexes={
@Index(columnList = "title"),
@Index(columnList = "hashtag"),
@Index(columnList = "createdAt"),
@Index(columnList = "createdBy")
})- @Getter : 모든 필드는 접근 가능하게
- @ToString : 쉽게 출력이 가능하게, 관찰가능하게
- @Table(Indexes = ) : Indexes 안에 @Index 로 검색 가능하도록 인덱스를 걸 수 있다.
인덱스 사이즈 제한 있음 주의! 그래서 본문검색은 MySQL 엔진의 Full text search 이용하거나 따로 elastic search같은 검색엔진의 도움을 받는다.
@Entity
public class Article {
@Id //PK
@GeneratedValue(strategy = GenerationType.IDENTITY) //autoincrement 위해
private Long id;
@Setter @Column(nullable = false) private String title; //제목. length 디폴트가 255라서 생략
@Setter @Column(nullable = false, length = 10000) private String content; //본문
@Setter private String hashtag; //해시태그. null 가능
// 한번만 쓸거라서 final.
@ToString.Exclude
@OrderBy("id")
@OneToMany(mappedBy = "article", cascade = CascadeType.ALL)
private final Set<ArticleComment> articleComments = new LinkedHashSet<>();
// 메타데이터
@CreatedDate @Column(nullable = false) private LocalDateTime createdAt; //생성일시
@CreatedBy @Column(nullable = false,length =100) private String createdBy; //생성자
@LastModifiedDate @Column(nullable = false) private LocalDateTime modifiedAt; //수정일시
@LastModifiedBy @Column(nullable = false,length =100) private String modifiedBy; //수정자
- @Entity : 엔티티 명시. 엔티티는 당연하지만 엔티티 라는 것을 명시해줘야 한다.
- @Id : PK
- @GeneratedValue(strategy = GenerationType.IDENTITY) : autoincrement 걸어준다.
MySQL 은 IDENTITY 방식으로 autoincrement가 만들어지기 때문에 GenerationType.IDENTITY로 설정한다. 잘못된 방식으로 셋팅해주면 에러가 날 것이므로 주의하자. - @Setter : 해줘야 나중에 도메인에서 수정이 가능하다.
각각 필드에 넣고 전체 클래스레벨(Article)에 걸지 않은 이유는 일부러 자동으로 jpa에서 부여되는 id, 메타데이터와 같이 특정 필드는 접근하지 못하도록 막고싶어서이다. - @Column(nullable = true, length = 255, ...) : NOT NULL 여부(디폴트가 true), 길이(디폴트가 255)등을 설정 가능하다.
- @CreatedDate, @CreatedBy : JPA Auditing 기능이다. 최초 INSERT할 때 생성날짜, 생성자를 자동으로 넣어준다.
- @LastModifiedDate, @LastModeifiedBy : JPA Auditing 기능이다. 업데이트 할 때마다 자동으로 수정날짜, 수정자를 실시간으로 넣어준다.
Jpa Auditing 이란?
Spring Data JPA에서 누가, 언제?에 대해서 자동으로 값을 넣어주는 기능
JpaConfig
지금 우린 Spring Security 나 인증기능을 달아놓지 않았는데, @CreatedBy는 누구인지 모르는데 어떻게 식별하냐?
이것을 셋팅하기 위해 jpaconfig에 작성이 필요하다.
먼저 각종 spring boot 에 config 를 모아둘 config 패키지를 생성한다.
config 안에 jpa설정을 모아둘 jpaconfig 클래스를 만든다.
package com.javaproject.project_board.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.domain.AuditorAware;
import org.springframework.data.jpa.repository.config.EnableJpaAuditing;
import java.util.Optional;
@EnableJpaAuditing
@Configuration
public class JpaConfig {
@Bean
public AuditorAware<String> auditorAware(){
return ()-> Optional.of("jjjGi"); // TODO: 스프링 시큐리티로 인증 기능을 붙이게 될 때, 수정하자.
}
}- @Configuration : configuration 기능이 되도록 명시한다.
- @EnableJpaAuditing : jpa auditing 기능을 활성화한다.
- @Bean : 리턴되는 객체가 IoC 컨테이너 안에 빈으로 등록한다.
auditing할 때 사람 이름정보를 넣어주기 위한 config를 넣을 수 있다.
위와 같이 AuditorAware<>를 반환하는 함수로 만들 수 있다.
<>에는 사람이름을 넣어줄 것 이니까 String을 넣었다. return값은 람다함수로 만들었으며, Null값을 고려하는 Optional을 사용 할 것이다.
지금은 그냥 임의의 값을 넣어서 테스트 해보고 TODO로 수정계획을 작성하자.
TODO 주석
// TODO :이렇게 작성하면 intellij에서
위와 같이 TODO용 색상으로 바뀌게 된다.

생성자
전까지는 Entity를 구성하는 필드를 다루는 방법이었다면,이제 Entity자체의 기본기를 만족시키기 위한 작업을 시작하자.
hibernate 구현체 사용한다고 가정할 때, 모든 Entity들은 기본생성자를 가지고 있어야 한다. (public, protected 만 가능)
Alt + Insert : 생성자 자동생성 단축키
constructor를 누른 후 ,
생성자 매개변수를 정하고 OK를 누르거나 , 기본생성자(매개변수가없음)를 만들고자 한다면 Select None을 누르면 된다.
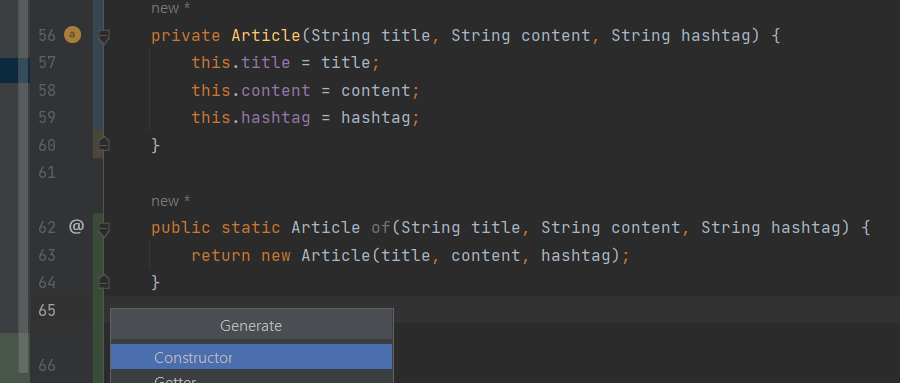
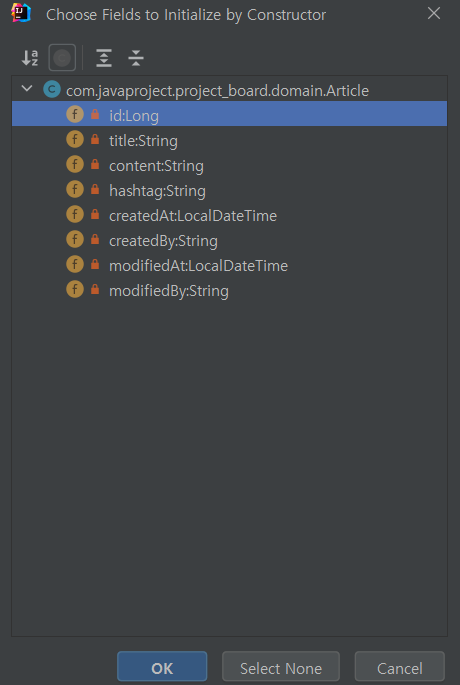
public class Article {
//...중략...
protected Article() {
}
}기본 생성자는 사용하지 않을 것이기 때문에 public이 아닌 protected로 한다.
public class Article {
//...중략...
protected Article() {
}
private Article(String title, String content, String hashtag) {
this.title = title;
this.content = content;
this.hashtag = hashtag;
}
}그리고 도메인과 관련이 있는 정보만 open하는 방식으로, 즉 관련없는 메타데이터나 id는 제외하고 관련이 있는 정보들로만 생성자를 통해 만들 수 있게끔 유도를 한다.
private Article(String title, String content, String hashtag) {
this.title = title;
this.content = content;
this.hashtag = hashtag;
}
public static Article of(String title, String content, String hashtag) {
return new Article(title, content, hashtag);
}그리고 private으로 막아버린 후, factory method로 제공할 수 있게끔 할 것이다. (new 키워드를 쓰지 않고 편하게 사용할 수 있게끔)
즉, 이런식으로 의도를 전하는 것이다. 도메인 Article을 생성하고자 할 때에는 이런 값들이 필요하다는것을 가이드 하는 것이다.
factory method 구현에서 함수 이름을 of로 하는 이유?
간단하게 말하자면, 다들 그렇게 쓰기 때문이다. 약간의 규약,약속 같은 것.
LocalTime.of(), Color.Valueof() 이런것들도 정적 팩토리 메서드의 일종이다.
동일성 동등성 검사
앞으로 Article이 담긴 list로 데이터를 받아오고 보내주고 하는 일이 많을 것 같은데(게시글 보여줄 때 등), 리스트를 넣거나, 중복요소 제거하거나 정렬을 해야할 때 비교를 할 수 있어야 한다. 이때, 동일성 동등성 검사를 할 수 있는 equals() 와 hashCode() 를 구현해야 한다.
롬복을 이용하여 간단하게 가능하다 .
예를들어
@EqualsAndHashCode
@Getter
@ToString
@Table(indexes={
@Index(columnList = "title"),
@Index(columnList = "hashtag"),
@Index(columnList = "createdAt"),
@Index(columnList = "createdBy")
})
@Entity
public class Article {
...
}
위와 같이 롬복을 이용하면 모든 필드를 비교해서 표준적인 방법으로 equals() 와 hashCode()를 구성한다.
하지만!!!! 우리는 기본적인 방법으로 하지 않고
가장 추천하는 방법은 objects를 이용하는 방법이다.
이렇게 한 후, Next
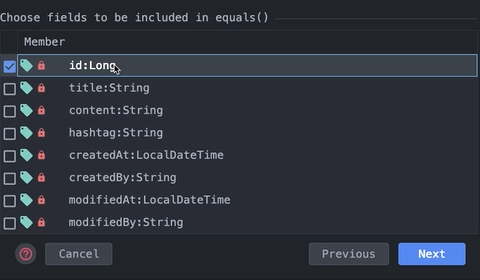
db entity를 동등성 검사할 때 굳이 모든 필드를 봐야할까? 아니다.
유일성이 있는 PK인 id만 비교하면 된다.
즉, 이렇게 하면 일반 롬복을 사용하는 것 보다 퍼포먼스가 증가하게 된다.
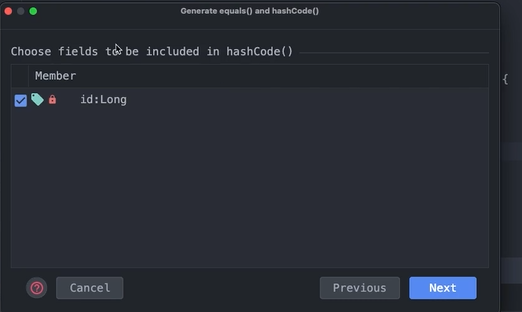
hashCode에 어떤 녀석을 추가할 것인지 고를 수 있게 해준다.
id를 넣어줘야한다.
@Override
public int hashCode() {
return Objects.hash(id);
}동일성 검사의 해시코드는 id만가지고 해싱 가능하므로 id하나면 된다.
id는 당연히 Not Null 이므로 체크누르고 넘어간다.
Not Null 체크, 미체크 차이
- Not Null 일 때 (체크)
값이 무조건 있으므로 그냥 equeals로 비교- Null 가능일 때 (미체크)
Null 값이 있을 수 도 있으므로 Object를 이용해서 equals사용 한다.
Ojbect의 equals는 위와같이 두개가 같거나(null도 두개가 null이거나) null이 아니면 equals를 실행하여 같은지 판단한다.


JAVA 14 Pattern Matching
java 14 이전에는

위와같이 동등성 검사위해 받아들인 Object o 가 Article인지 검사,
Article로의 type casting을 하여 equals검사를 진행한다.
하지만, 쓸데없는 코드가 있다고 생각된 java 14 이후에는
o instanceof Article article이렇게 바로 쓸 수 있게 바뀌었다.
즉, Pattern Matching을 사용하여 단일 표현식으로 결합하여 반복을 제거하고 제어 흐름을 단순화 한다.
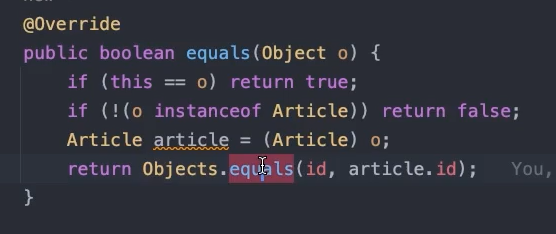
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Article article)) return false;
// 영속화 되지 않은 entity는 동등성 검사 탈락시키는 것 추가.
return id.equals(article.id);
}추가로, 현재 영속화 아직 하지 않았을 때, DB데이터를 연결시키지 않았을 때 아직 insert하기 전의 Entity는 id 가 Null이다. 해당 부분을 체크하기 위해
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Article article)) return false;
// 영속화 되지 않은 entity는 동등성 검사 탈락시키는 것 추가.
return id != null && id.equals(article.id);
}return 부분을 이와같이 수정한다. 즉, 영속화되지 않은 Entity는 같아도 동등성 검사를 탈락하게 만든 것이다.
완성된 전체코드
package com.javaproject.project_board.domain;
import com.fasterxml.jackson.databind.ser.std.ToStringSerializer;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
import org.springframework.data.annotation.CreatedBy;
import org.springframework.data.annotation.CreatedDate;
import org.springframework.data.annotation.LastModifiedBy;
import org.springframework.data.annotation.LastModifiedDate;
import javax.persistence.*;
import java.time.LocalDateTime;
import java.util.LinkedHashSet;
import java.util.Objects;
import java.util.Set;
//모든 필드는 접근이 가능해야 한다.
@Getter
@ToString
//빠른 검색 가능하게끔 인덱싱. 너무 긴 내용은 인덱싱 최대범위에 못도달.
@Table(indexes={
@Index(columnList = "title"),
@Index(columnList = "hashtag"),
@Index(columnList = "createdAt"),
@Index(columnList = "createdBy")
})
@Entity
public class Article {
@Id //PK
@GeneratedValue(strategy = GenerationType.IDENTITY) //autoincrement 위해
private Long id;
@Setter @Column(nullable = false) private String title; //제목. length 디폴트가 255라서 생략
@Setter @Column(nullable = false, length = 10000) private String content; //본문
@Setter private String hashtag; //해시태그. null 가능
// 한번만 쓸거라서 final. -> 그럼 article comment 는 왜 final안함? ㅈㅁ@@@@@@@@@@2
@ToString.Exclude
@OrderBy("id")
@OneToMany(mappedBy = "article", cascade = CascadeType.ALL)
private final Set<ArticleComment> articleComments = new LinkedHashSet<>();
// 메타데이터
@CreatedDate @Column(nullable = false) private LocalDateTime createdAt; //생성일시
@CreatedBy @Column(nullable = false,length =100) private String createdBy; //생성자
@LastModifiedDate @Column(nullable = false) private LocalDateTime modifiedAt; //수정일시
@LastModifiedBy @Column(nullable = false,length =100) private String modifiedBy; //수정자
protected Article() {
}
private Article(String title, String content, String hashtag) {
this.title = title;
this.content = content;
this.hashtag = hashtag;
}
public static Article of(String title, String content, String hashtag) {
return new Article(title, content, hashtag);
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Article article)) return false;
// 영속화 되지 않은 entity는 동등성 검사 탈락시키는 것 추가.
return id != null && id.equals(article.id);
}
@Override
public int hashCode() {
return Objects.hash(id);
}
}
ArticleComment.java
이제 Article을 참고하며 ArticleComment 를 작성할 차례이다.
내용은 비슷하므로 차이점만 언급하겠다.
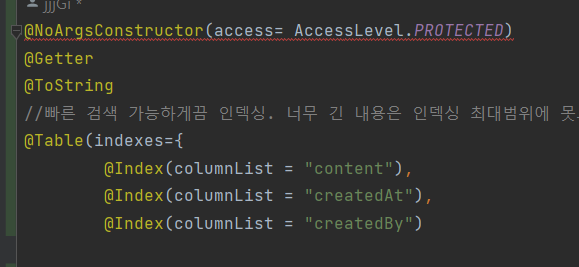
@Getter
@ToString
//빠른 검색 가능하게끔 인덱싱. 너무 긴 내용은 인덱싱 최대범위에 못도달.
@Table(indexes={
@Index(columnList = "content"),
@Index(columnList = "createdAt"),
@Index(columnList = "createdBy")
})
@Entity
public class ArticleComment {
@Id //PK
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// @Column(nullable = false) article에 이거 안하는 이유? ㅈㅁ @@@@@@
@Setter @ManyToOne(optional = false) private Article article; //게시글 (ID). 객체지향적으로 연관관계 줌.
@Setter @Column(nullable = false, length = 500) private String content; //본문
// 메타데이터
@CreatedDate @Column(nullable = false) private LocalDateTime createdAt; //생성일시
@CreatedBy @Column(nullable = false,length =100) private String createdBy; //생성자
@LastModifiedDate @Column(nullable = false) private LocalDateTime modifiedAt; //수정일시
@LastModifiedBy @Column(nullable = false,length =100) private String modifiedBy; //수정자
- @ManyToOne(optional = false , cascade = ) : 객체지향적으로 연관관계를 맺기 위해 필요. optional 을 false로 하면 optional하지않고 필수값임을 나타낸다.
그리고 추가로 cascading 옵션을 줄 수 있다.
우리는 댓글을 지웠을 때 관련된 게시글이 삭제되거나 하면 안되므로 cascading 옵션을 주지 않는다.(디폴트 : None. 옵션X)
생성자
protected ArticleComment() {}
private ArticleComment(Article article, String content) {
this.article = article;
this.content = content;
}
public static ArticleComment of(Article article, String content){
return new ArticleComment(article, content);
}
롬복을 이용하여 빈 생성자 만들기
위와 같이 @NoArgsConstructor 로 접근레벨가지 정할 수 있다.
근데protected ArticleComment() {}이 한줄 쓰는건 아무렇지도 않기때문에.. 또 더 쉽기때문에 나는 굳이 안쓰고있다.
동일성 동등성 검사
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof ArticleComment that)) return false;
return id!=null && id.equals(that.id);
}
@Override
public int hashCode() {
return Objects.hash(id);
}완성 전체코드
package com.javaproject.project_board.domain;
import lombok.*;
import org.springframework.data.annotation.CreatedBy;
import org.springframework.data.annotation.CreatedDate;
import org.springframework.data.annotation.LastModifiedBy;
import org.springframework.data.annotation.LastModifiedDate;
import javax.persistence.*;
import java.time.LocalDateTime;
import java.util.Objects;
@Getter
@ToString
//빠른 검색 가능하게끔 인덱싱. 너무 긴 내용은 인덱싱 최대범위에 못도달.
@Table(indexes={
@Index(columnList = "content"),
@Index(columnList = "createdAt"),
@Index(columnList = "createdBy")
})
@Entity
public class ArticleComment {
@Id //PK
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Setter @ManyToOne(optional = false) private Article article; //게시글 (ID). 객체지향적으로 연관관계 줌.
@Setter @Column(nullable = false, length = 500) private String content; //본문
// 메타데이터
@CreatedDate @Column(nullable = false) private LocalDateTime createdAt; //생성일시
@CreatedBy @Column(nullable = false,length =100) private String createdBy; //생성자
@LastModifiedDate @Column(nullable = false) private LocalDateTime modifiedAt; //수정일시
@LastModifiedBy @Column(nullable = false,length =100) private String modifiedBy; //수정자
protected ArticleComment() {}
private ArticleComment(Article article, String content) {
this.article = article;
this.content = content;
}
public static ArticleComment of(Article article, String content){
return new ArticleComment(article, content);
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof ArticleComment that)) return false;
return id!=null && id.equals(that.id);
}
@Override
public int hashCode() {
return Objects.hash(id);
}
}
구동해보기
여기서 세모를 눌러 실행 가능하지만, 하단 메뉴의 Services에서 실행이 되도록 해보자.
Run configuration type 누르고
Spring Boot를 찾아 누르면
현재 세팅되어있는 JavaBackendProjectBoardApplication이 잘 잡힌다.
여기서 삼각형을 눌러 실행이 가능하다.
- 이렇게 하는 이유?
이렇게 하면 Spring 로그가 Run쪽의 로그와 분리되어 보일 수 있게된다.
Run에서 빌드작업이나 테스트를 할 때 서비스 실행 로그와 분리하여 볼 수 있다는 이득이 있다.
또한 intellij안에서 여러개의 부트프로젝트를 관리할 때 실행코드를 Services 하나로 관리할 수 있다는 장점이 있다.
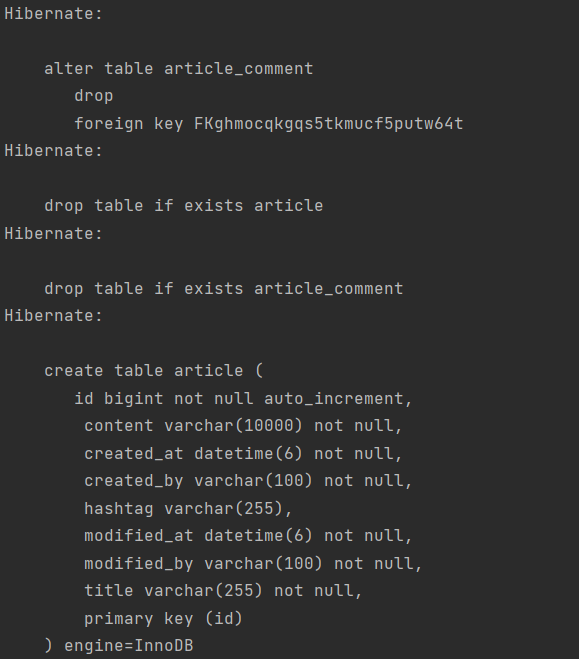
우리가 의도했던 대로 hibernate에서 테이블을 생성해주는 것을 볼 수 있다. (뒤에 인덱스가 붙는것도 볼 수 있다.)

dialect를 검색해봄으로써 MySQL도 잘 붙었는지 확인 가능하다.
그리고나서 DB를 refresh(순환버튼 클릭)하면 위와같이 테이블이 생성 된 것을 볼 수 있다.
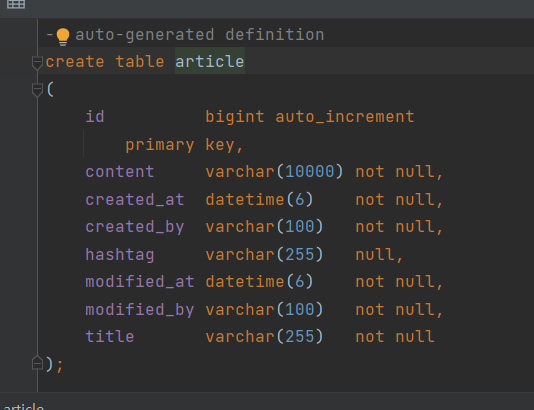
더블클릭하면 정보를 볼 수 있고, Navigation -> Go to DDL로 DDL까지 볼 수 있다.
그래서 우리는 create table을 직접 만들 필요가 없는거다! 문서화 작업할 때 여기서 복붙해도 된다.
만약 DB 먼저 만들고 ENTITY를 만드는 거라면?
DB로부터 Entity를 생성할 수 있다!!
이 JPA Buddy를 이용해서 DB로부터 Entity를 생성해보면
매핑하고자 하는 컬럼을 체크하고 OK를 누르면 우리가 만들었던 Article.java, ArticleComment.java와 거의 비슷하게 코드를 만들어준다.
그러나 현재는 유료기능...
DTO
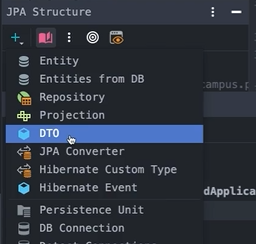
JPA Buddy 에서 DTO를 누르고

보통 id는 DTO에 안넣으니 제외하고 java record 체크!
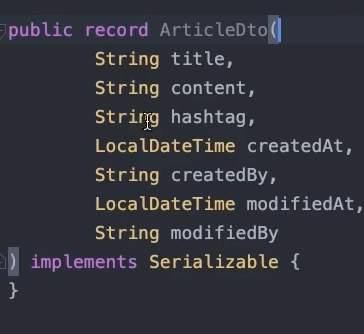
그러면 이렇게 DTO가 만들어진다.
DTO, DAO, VO ?
(좀 더 알아보자)
jpa buddy는 이따가 사용할 때 쓰도록 하고 지금은 서브메뉴들이 너무 많아 귀찮으므로 눈모양을 클릭하여 보이지 않도록 한다.

꺼도 이렇게 domain객체 우클릭하고 New-> others 에 JPA Buddy관련 기능들을 사용 가능하다.

전체 ctrl + shift+ A 하여 검색에서 이렇게 jpa buddy 를 OFF 해주면 다시 메뉴들이 뜬다.
ctrl + shift+ A : 전체 검색(기능, 액션, 파일 등등)
위와같이 전체적 검색을 할 수 있다.
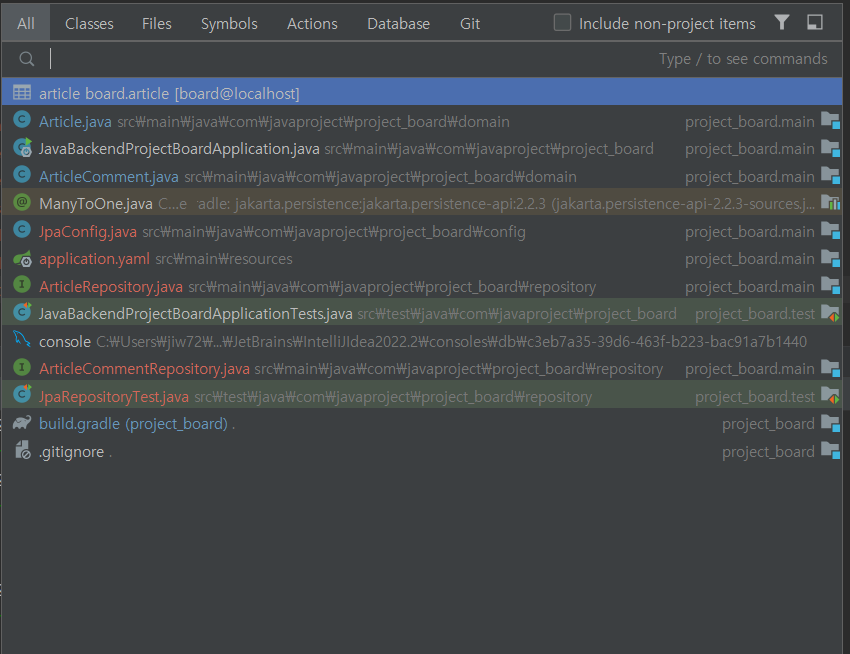
양방향 바인딩
댓글에서 게시글로는 객체지향적으로 매핑 했다.
이제 one to many를 해줘야한다.(게시글 -> 댓글)
메타데이터 위에 하는걸 선호하므로 중간에
@ToString.Exclude
@OrderBy("id")
@OneToMany(mappedBy = "article", cascade = CascadeType.ALL)
private final Set<ArticleComment> articleComments = new LinkedHashSet<>();를 추가한다.
세팅을 한번만 할 것이기때문에 final로 하고 Set을 사용하여 collection한다.
article에 연동되어있는 articleComment는 중복을 허용하지않고 리스트로 모아서 보겠다.라는 뜻이다.
- @OneToMany(mappedBy = "article", cascade = CascadeType.ALL) : one to many annotation이다.
mappedBy = "article"를 하지 않으면, 기본 이름인 두 테이블명을 합친게 된다.(article_article_Comment 이런식으로...) mappedBy = "article" 로 지정하여
article 테이블로부터 온 것이라고 명시해줄 수 있도록 article로 지정한다.
양방향 바인딩을 쓰기 위해 이번에는 cascade를 써보자.
실무에서는 양방향 바인딩 쓸까?
실무에서는 일부러 양방향 바인딩을 풀고 디자인 하는 경우가 많다.
왜냐하면, cascade로 인해 서로 결합되어있으면 데이터 편집 할 때 불편함이 좀 있고 원치않는 데이터 소실이 일어날 수 도 있기 때문이다.
예를들어, 게시글은 삭제해도 댓글은 따로 백업해서 남겨두고 싶을 때 가 있다. 그래서 일부러 FK를 안걸고 운영할 때가 많다.
우리는 공부목적이기 때문에 양방향 바인딩 cascade 쓸 것이다. (게시글 삭제시 댓글도 삭제)
cascade = CascadeType.ALL 로 모든 경우에 대해서 cascade 적용을 하겠다고 하자.
- @OrderBy("id") : 정렬기준을 id로 한다. 나중에 예쁘게 보려고ㅎㅎ
- @ToString.Exclude :
이렇게 둘중 한곳의 연결고리를 끊어주어 퍼포먼스 이슈를 해결해주고,
순환참조 (Circular reference) 가 일어나서(Article 에서 @toString 찍기 위해 쭉 찍다가 ArticleComment 있길래 ArticleComment.java로 갔는데 @toString이 있어서 쭉 찍다가 필드에 또 Article이 있어서 Article로 간다. 그러면 Article.java에서 또 @toString을 만나 다시 찍고...다시 ArticleComment.java->Article->ArticleComment.java->Article....)
메모리가 뻗어버리고 시스템 중단되는 상황을 막을 수 있다.
연결고리 끊는 기준?
예를들어
@ToString을 끊을 때 보통
댓글로 부터 글을 참조하여 뽑아보는거는 많이 있는 일,
글로부터 댓글들을 전체 리스트로 뽑아보는일은 흔지 않은 일.
-> Article.java쪽의 ToString을 끊어준다.
이렇게 좀 더 조리있는 방식으로 끊어준다.
다시 service에서 돌려보면 잘 돌아가는 것을 확인할 수 있다.
Repository
Entity를 다 정의했으면 이제 이걸 토대로 repository를 생성해줘야 한다.
생성하는 방법은 2가지정도 있다.
sol 1) Spring data repository 사용
sol 2) 일반 java 인터페이스 클래스 생성
- sol 1) Spring data repository 사용

com.~~ -> new -> spring data repository 를 누르고
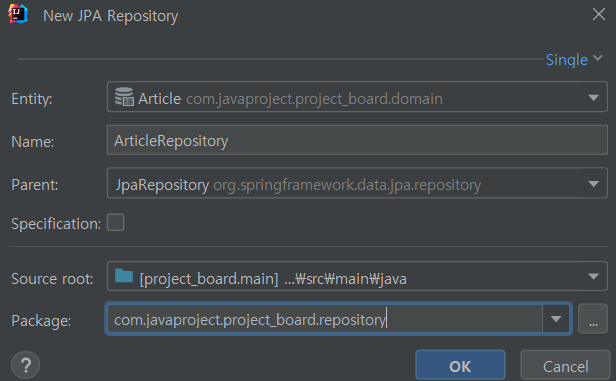
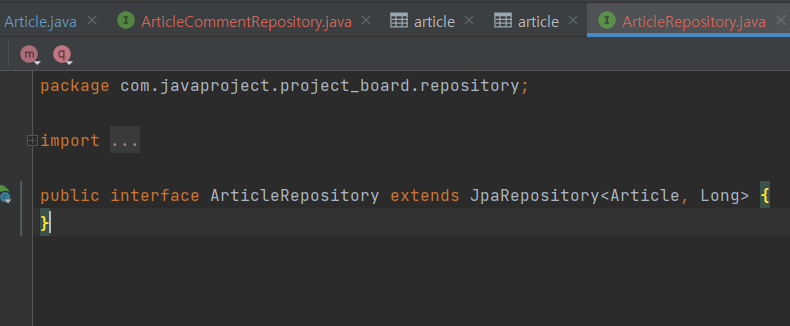
이렇게 JPA Repository를 만들 수 있다.
- sol 2) 일반 java 인터페이스 클래스 생성

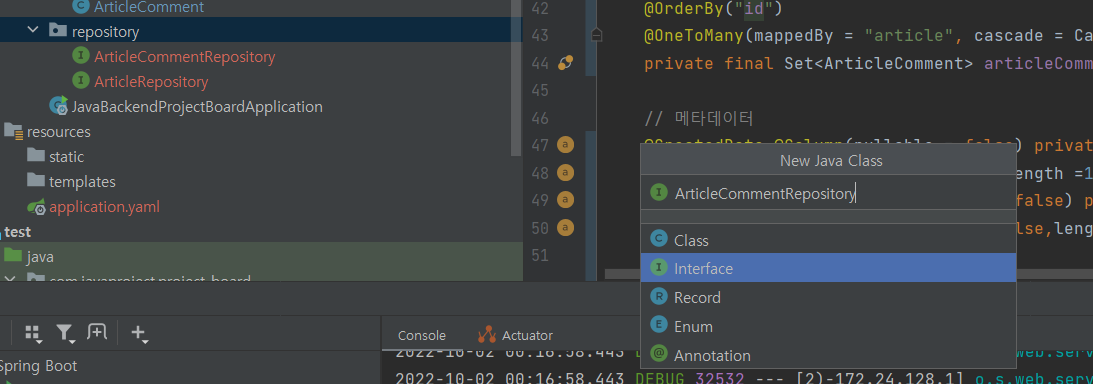

위와 같이 JPArepository를 상속받게 하면 끝이다. <>안에는 ArticleComment를 넣고,
id type은 Long이므로 Long을 넣는다.
이걸 토대로 JPA Test를 만들어보자.

클래스 명 클릭하고 ctrl+shift+T -> create new test 를 누른다.
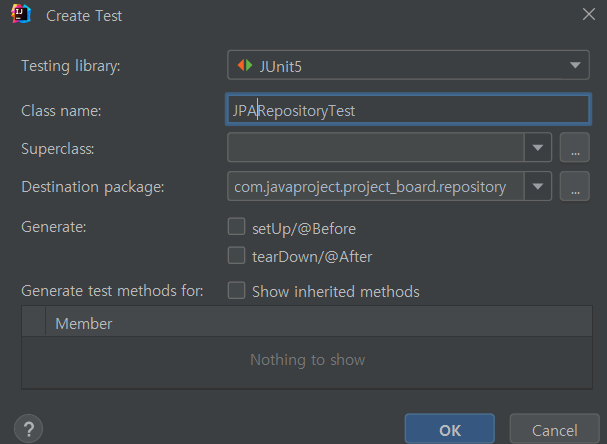
특정 repository test를 만드는게 아니라 JPA Repository test 를 만들거기 때문에 이름을 이렇게 수정하고 OK.
그럼 위와같이 TEST폴더의 repository 폴더에 JpaRespositoryTest.java가 생성되었다.
JpaRepositoryTest
import static org.junit.jupiter.api.Assertions.*;
@DataJpaTest
class JpaRepositoryTest {}@DataJpaTest의 도움을 받아 slice test 를 할 것이다.
import static org.junit.jupiter.api.Assertions.*;
@Import(JpaConfig.class)
@DataJpaTest
class JpaRepositoryTest {}근데 이대로는 test가 제대로 읽지 못하는 config가 있다. 그것은 내가 만든 JpaConfig.
JpaConfig 존재를 DataJpaTest는 모른다. 내가 만든거니까.
이렇게 되면 JpaConfig에 생성일자, 수정일자 등을 자동으로 채워주던 @EnableJpaAuditing을 사용하지 못하게 된다.
import static org.junit.jupiter.api.Assertions.*;
@DisplayName("JPA 연결 테스트")
@Import(JpaConfig.class)
@DataJpaTest
class JpaRepositoryTest {}그래서 @Import(JpaConfig.class)로 추가해준다.
그리고 jUnit5 기능을 이용해서 @DisplayName("JPA 연결 테스트") 로 이름을 하나 넣어준다.
jUnit5보다는 assertj를 쓰고싶으면
import static org.assertj.core.api.Assertions.*;위와같이 변경한다.
테스트는 ArticleRepository, ArticleCommentRepository 두개를 테스트 할 것이며,
필드 주입을 하기 위해 원래는
@Autowired private final ArticleRepository articleRepository;이런식으로 한다. 하지만!
jUnit5와 최신버전의 Spring Boot를 이용하면 이제는 test에서도 생성자 주입이 가능하다.

즉, @DatajpaTest 안에 들어가면, 모든 슬라이스 테스트가 가지고 있는 @ExtendWith(SpringExtension.class)가 있다.
@ExtendWith(SpringExtension.class)
jUnit5를 위해서 만들어진 것이며, SpringExtension에서 autowired를 검색해보면
주입을 위한 기능들이 있다. 즉, AutoWring을 위한 로직들이 구현되어 있다.
이 덕분에, 우리는 생성자 주입 패턴으로 필드를 만들 수 있다.
import static org.assertj.core.api.Assertions.*;
@DisplayName("JPA 연결 테스트")
@Import(JpaConfig.class)
@DataJpaTest
class JpaRepositoryTest {
private final ArticleRepository articleRepository;
private final ArticleCommentRepository articleCommentRepository;
public JpaRepositoryTest(
@Autowired ArticleRepository articleRepository,
@Autowired ArticleCommentRepository articleCommentRepository
) {
this.articleRepository = articleRepository;
this.articleCommentRepository = articleCommentRepository;
}
}저번처럼 Alt+insert 로 constructor를 만들어주자.
그리고나서 각 생성자 인자에 @Autowired를 걸어준다.
이렇게 생성자 주입 패턴이 완성되었다.
@DisplayName("select 테스트")
@Test
void givenTestData_whenSelecting_thenWorksFine(){
//Given
//When
//Then
}테스트 함수명은 '테스트 데이터가 들어왔을 때 SELECT 할 때 잘 동작한다'라고 하고
- @DisplayName("select 테스트") : 이 함수의 테스트 이름은 "select 테스트"로 지정한다.
given, when, then 패턴으로 테스트코드 작성을 할 것이다.
//Given
//When
//Then이 커멘드를 꼭!! 습관으로 작성하도록 하자~~!!!
Select 테스트
@DisplayName("select 테스트")
@Test
void givenTestData_whenSelecting_thenWorksFine(){
//Given
//When
// select를 위해 article로 하고 findall해서 article list로 받아온다.
List<Article> articles = articleRepository.findAll();
//Then
// articles가 notnull이면 좋겠고 size는 현재 0개(jpa기능을 잘 만들었다면 select가 잘 될거고
assertThat(articles).isNotNull().hasSize(0);
}
그리고나서 실행하면
jpa기능을 잘 만들었다면 select가 잘 될거고
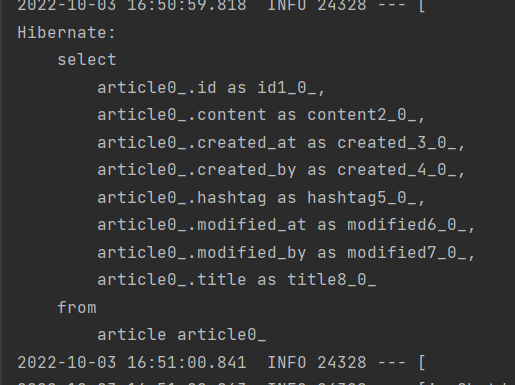
hibernate 쿼리도 의도된대로 잘 나온다.
테스트 데이터 생성
이제 여기에 테스트데이터를 만들것이다.
데스트데이터 대량 생산 사이트(mockaroo)를 이용 할 것이다.
mockaroo ?
대량의 임의데이터를 생산 할 때 유용하다.
임의 ip 주소, title, 등등 .. 여러 카테고리로 데이터들을 랜덤, 다수생성해준다.
아쉬운점은, 아직 한글데이터는 못만든다.

data.sql 이라는 이름은 이미 Spring Boot에서 약속된이름이다.
그래서 무조건 data.sql로 해야한다.

그리고 MySQL로 바꾼다.

그렇게 mockaroo에서 만든 데이터를 sql파일 안에 넣는다.
계정 도메인 추가 작업 따로 보고 완료 후! 진행하기
그리고나서 test를 다시 실행할 때


안녕하세요! 혹시 createAt, createdBy, modifiedAt, modifiedBy 만들어주는 제대로 무엇인지 궁금합니다!