
사실 이 주제에 대해서는 과거에 공부한적이 있다.
그치만 너무 오래전에 공부하여 다 잊어버려 다시 공부해보려 한다.
한명은 하나의 일을 할 수 있다.
하지만, 병렬로 처리한다면 한명은 여러개의 일을 할 수 있다.
우리는 일상생활 속에서 비동기적으로 일을 하는 경우가 있다.
예를 들자면 세탁기를 돌리며 식기세척기에 그릇을넣고 바닥을 닦는.. 이런 것들이다.
프로세스와 스레드
"청소" 라는 큰 단위가 있고,
그 안에는 바닥, 유리, 물품정리 등 여러 카테고리로 나뉜다.
집안일 이라는 키워드로만 비교를 해보자. 청소 = 프로세스 이다. 왜 프로세스일까?
집안일를 할 때 우리는 여러 일을 한다. 세탁, 설거지, 청소등 여러 일을 한다. 만약, 세탁을 안한다고 설거지를 못하나? 설거지를 한다고 청소를 못하나? 아니다. 불편함은 있을지 몰라도 불가능하지는 않다.
이처럼 프로세스는 서로 간섭하지 않고 독립적으로 실행된다는 것이 특징 중 하나이다.
그렇다면 스레드는 어떨까?
세탁을 하기 위해서는 세탁기가 있어야하고, 세탁기를 동작시키기 위한 전기가 필요하다. 또, 안에서 돌아가야할 세탁물이 있을것이고 그 세탁물에 휴지와같은것이 없어야하며 세제와 섬유유연제등 다양한것들이 필요하다.
하지만, 전기가 없다면? 세탁물에 휴지가 함께 들어가있다면? 세탁물이 없다면?
이런 예외들이 있다. 하나씩 생각해보자
1. 전기가 없다 -> 작동이 안된다
2. 휴지가 있다 -> 정상적인 세탁이 되지 않는다.
3. 세탁물이 없다 -> 세탁기를 청소하는 수준이다
4. 세제가 없다 -> 물에 적시는거다
5. 섬유유연제가 없다 -> 큰 문제는 없으나, 정전기 발생이나 향이 없는 등의 문제가 있다.이런 예외들이 있는데, 완벽한 세탁이라고 할 수 있을까? 아니다. 이 동작들은 내부적으로 모두 엮여있는 상황이다. 그렇기에 하나라도 예외가 난다면 "세탁"이라는 작업에는 치명적인 예외를 발생시킨다.
이처럼 세탁이라는 프로세스에서 내부적으로 동작하는것은 프로세스 내에서 자원을 공유하며 실행되는 스레드의 특징과 닮아있는다.
간단히 설명하자면
프로세스 -> 서로 간섭받지 않고 독립적으로 실행된다
스레드 -> 프로레스의 자원을 공유하여 서로 상호작용하며 작동한다.
프로세스
운영체제에서 실행중인 하나의 독립적인 프로그램 단위.
각 프로세스는 독립적인 메모리 공간을 할당받아 다른 프로세스와 공유하지 않는다.
- 우리는 일을 하기위해 출근해서 컴퓨터를 킨다
- 컴퓨터 위에는 운영체제가 구동된다
- 운영체제 위에서 IDE, 노션, 브라우저 등 각각의 프로그램(프로세스)를 작동시킨다.
여기까지는 프로세스의 간단한 구동 과정이다.
IDE, 노션, 브라우저. 이 3개가 서로 상호의존적인가? 아니다.
우리는 브라우저에서 얻은 정보를 노션에 정리하고, 정리된 내용을 학습하여 IDE 위에서 개발한다.
그렇다면 상호의존적인거 아니냐고 하는데, 이는 "사람" 이라는 매개체가 있기에 상호작용하는것 처럼 보이는것이다.
프로세스는 실행이 되면 고유한 메모리 공간을 할당받는다.
이 메모리 공간에는 TEXT, DATA, HEAP, STACK 같은 영역으로 나뉜다.
- TEXT - 실행할 프로그램의 코드(명령어)가 저장된다
- DATA - 초기화된 전역 변수와 static 변수가 선언된다.
- HEAP - 동적으로 할당되는 영역으, 객체가 생성되면 늘어나고 삭제되면 줄어든다.
- STACK - 함수 호출 시 사용되는 지역변수 및 매개변수, 반환 주소등을 저장한다.
이 영역들은 프로세스를 구성함에 있어 아주 중요한 구조이다.
만약 이 공간을 잘못 제어하거나 NullPointer, StackOverflow같은 것들이 발생하면 프로세스가 종료될 수 있다.
스레드
프로세스 내부에서 실행되는 작업 단위.
같은 프로세스의 자원(스택, 힙, 코드 등)을 공유하며 실행된다.
프로세스 하나라도 잘못된 접근이 있다면 충돌이나 동기화 문제가 생긴다.
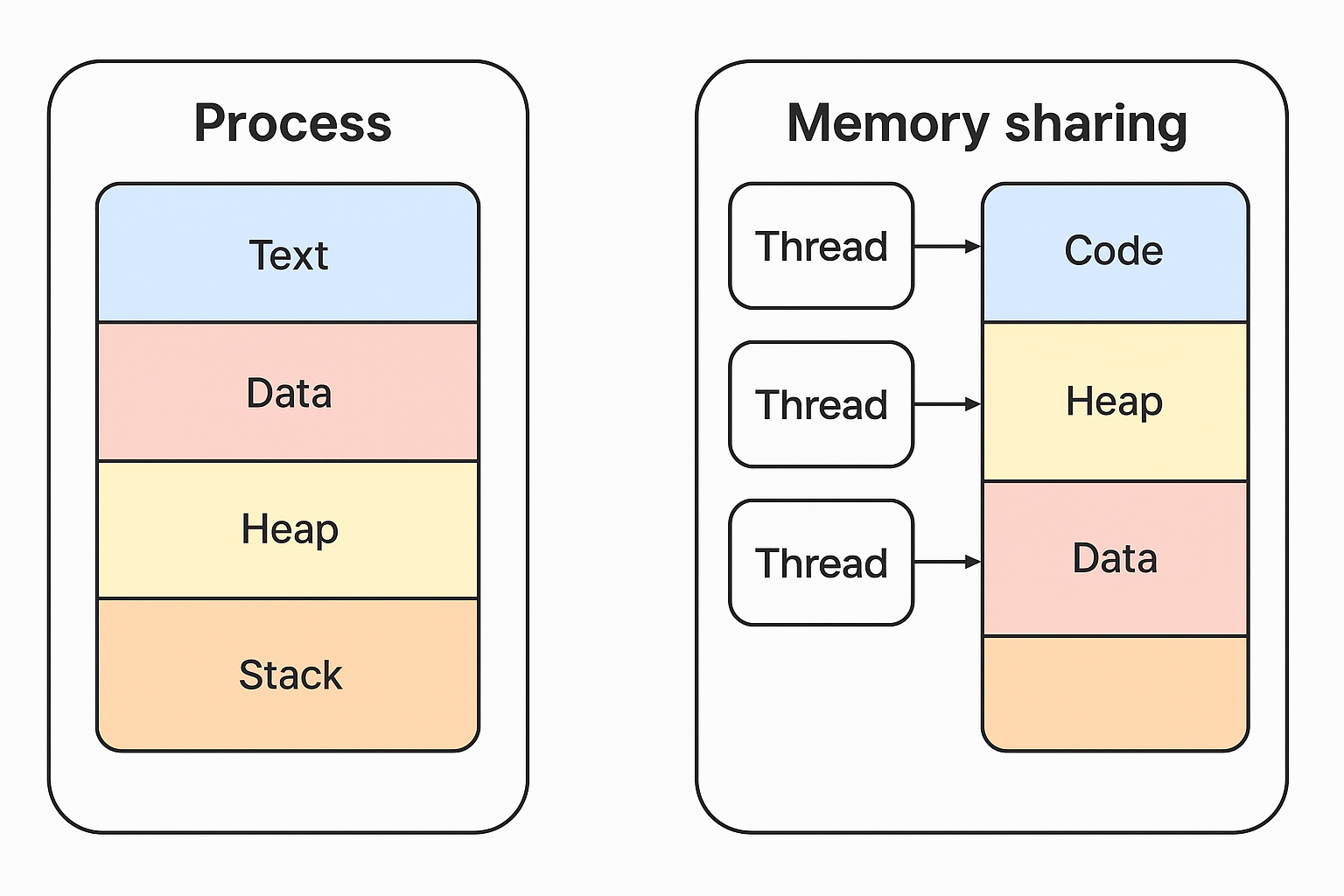
"프로세스의 자원 공유" 이 단어가 굉장히 중요하다.
각 스레드가 이 자원을 잘못 참조하여 NullPointer같은 예외가 발생할 경우 1차적으로 운영체제나 런타임이 이를 동작시키는 프로세스를 종료시켜 버린다.
JAVA같은 경우 이 메모리를 JVM 이라는 런타임 프로그램이 관리해주기에, JVM이 프로세스를 종료시킨다 생각하면 편하다.
왜 종료시키는걸까?
사실 이 부분이 가장 궁금했다. 그냥 동작시키면 될걸 왜 종료시키는지 굉장히 궁금하여 가설을 먼저 세워보았다.
1. 예외 발생 시 프로그램의 안정성을 보장하기 힘들어서
2. JVM은 예외를 처리할 수 있는 방법을 모르기에 그냥 종료
3. 프로세스도 운영체제 입장에서는 스레드인데, 이게 운영체제의 자원을 건드릴까봐
이런 가설을 세우고 여러 사이트와 LLM(ChatGPT, Grok)을 이용해 검색해보았다.
ChatGPT
스레드에서 발생한 예외가 잡히지 않고 런타임까지 전달되면, 런타임은 프로세스 전체를 정료시키는게 더 안전하다고 판단하기 때문
- 스레드가 공유 자원을 망가뜨릴 수 있기 때문
- OutOfMemory, StackOverFlow 같은 시스템 수준의 에러는 회복불가능으로 판단
- 각 런타임의 정책
Grok
시스템의 안정성과 일관성을 유지하기 위한 설계적 선택과 관련이 있다.
- 프로세스 단위 자원 관리
- 스레드에서 발생한 예외가 적절히 처리되지 않으면, 프로세스 전체의 상태가 손상될 수 있기 때문.
- 예외의 전파와 처리 방식
- 예외는 기본적으로 스래드 내에서만 전파된다. 하지만 try-catch와 같이 예외처리를 하지 않으면 처리되지 않은 예외로 간주하며, 이는 예측불가능한 예외이므로 프로세스를 종료한다.
- 시스템 안정성과 데이터 무결성
- 예외가 발생한 스레드가 계속 실행되면 손상된 상태로 인해 다른 스레드나 프로세스 전체레 영향을 줄 수 있기 때문
- 예를들어 한 스레드가 데이터베이스 트랜잭션 중 예외를 발생시키고, 이를 무시하면 데이터베이스의 무결성이 깨질 수 있기 때문
- 각 언어나 런타임별 예외처리 방식이 다르다. (JAVA, .NET, Python)
- 운영체제는 일반적으로 프로세스를 종료시키지 않지만, 런타임이나 애플리케이션이 예외처리에 실패하면 SIGSEGV, SIGABRT같은 신호를 보내 종료를 요청한다.
- 메모리 위반같은 프로세스의 비정상적인 활동을 감지해도 위 신호를 요청한다.
결론
스레드는 프로세스 입장에서 여러 일을 동시에(멀티스레드) 처리할 수 있기에 효율성을 높힐 수 있다.
하지만, 적절한 예외처리를 하지 않으면 시스템 전체를 위협할 수 있다.
결국, 내 가설 중 예외 발생 시 프로그램의 안정성을 보장하기 힘들어서 라는 가설이 맞았고, 추가적으로 회복불능의 예외, 처리방식등의 이유로 프로세스를 종료시키는것이엇다!
멀티 스레드
자, 이제 프로세스와 스레드에 대해 알아보았으니, 멀티스레드에 대해 간략하게나마 정리를 해보자.
멀티스레드는 하나의 프로세스 안에서 여러개의 스레드로 작업을 동시에 작업을 진행하는것이다.
사용 예시
대표적인 예시 몇가지만 뽑고 해당 글의 결론을 내보고자 한다.
- 파일 업/다운로드
- 대용량 파일 처리를 위해 I/O 병목을 방지하고, 응답률을 높히기 위하여
- 채팅
- 수/송신을 별도 스레드로 처리해 한쪽이 막혀도 전체 동작에 영향을 줄이기 위해
- 백그라운드 이미지 처리
- 보정등의 처리를 메인 스레드와 분리하여 처리
- 로그 수집
- 서비스 동작과 분리하여 로그를 별도 스레드에서 비동기로 수집하고 저장
- 알림 발송
- 수 천개의 알림을 여러 사용자에게 동시에 보내야할 때, 스레드로 나누어 병렬 처리
- 레이턴시가 높은 요청을 동시에 처리해야할 때
위 내용들을 보면 알겠지만 동시에 여러작업을 하기 위하여, 응답 속도 개선을 위하여 사용한다는것을 알 수 있을것이다.
즉, 이러한 멀티스레드는 병렬 호출과 비동기 작업에 유리하다.
단점
정말 많은 단점이 있지만, 대표적으로 멀티스레드를 다루다보면 꼭 나오는 말이 있다.
바로 RaceCondition, 동기화 문제이다.
여러 문제 중 RaceCondition만이라도 이해를 제대로 해보자.
동기화 문제(RaceCondition)
여러 스레드가 하나의 자원에 접근할 때 발생하는 문제로, 동기화 없이 비동기로 처리를 할 경우 많이 발생한다.
스레드는 프로세스의 자원을 공유한다. 그 만큼 스레드가 여럿이 될 수록 자원을 공유하는 사람이 많아진다.
n > 10일때, n명의 사람들이 바구니에 물을 넣기 위해 10km 거리에서부터 물을 떠온다. 하지만, 이 바구니는 n-5명이 물을 넣으면 더 이상 들어가지 않고 넘치게 된다. 그렇다면 n-5명만 물을 떠오면 되는데, 모두가 물을 떠온다면 5명은 헛걸음을 한거다.
이는 가벼운 예시인데, 이처럼 한명한명 물을 채우면 다른 사람들이 물이 얼마나 차는지 알게되고, 몇명만 채우면 되는지 알 수 있다. 하지만, 모두가 비동기적으로 처리를 한다면 헛수고를 하거나 물이 넘치는 일이 발생한다.
그렇기에 각 스레드들이 하나의 자원을 공유하기 위해서는 서로 제약 조건(동기화, Synchronization)이 있어야한다.
이 외의 단점
이 외의 단점으로 꽤 많이 들어본 단점도 많을것이다.
- DeadLock
- 각 스레드가 자원의 활성 상태를 기다리며 무한한 대기 상태에 빠지는 상태이다.
- 대부분 RaceCondition 을 해결하기 위해 Lock 방식을 채택하는데, 이 Lock이 해제되지 않아 해제될때까지 기다리는 현상
- 디버깅 난이도 상승
- 병렬로 처리되기 때문에 동일한 문제를 재현하기 어려워 디버깅 난이도가 올라간다.
- 컨텍스트 스위칭 비용
- 스레드가 많아질수록 CPU가 컨텍스트 스위칭에 많은 시간을 소모한다.
- 멀티스레드가 효율적일지라도 성능이 떨어질 수 있다.
- 규모에 맞게 사용해야한다..
- 자원 소비
- 스레드가 많아질수록 Stack은 계속 증가하고, 이 Stack 이 너무 많이 증가하면 프로세스 자체의 메모리 사용량도 높아진다.
- 복잡한 설계 구조
- RaceCondition의 해결을 위해 동기화, Lock, TTL, 알림, 상태관리 등 이러한 설계들이 들어가고 그만큼 프로그램의 복잡도가 올라간다.
- 유지보수 난이도도 함께 올라간다.
결론
멀티스레드가 시스템의 성능을 극대화할 수 있는 강력한 도구인것은 맞다.
하지만, 잘못된 사용으로 동기화, 디버깅, 자원 관리 측면에서 많은 위험과 복잡성을 가지고있어 필요성과 설계의 명확성을 따지며 도입해야한다.
공부하며 계속 느끼지만, 프로젝트 규모에 따라서 기술 스택을 선택해야지 옆에서 좋다고 무작정 도입한다고 좋은게 아니다 !
