1. main idea:
Deeper networks는 특별한 초기화(initialization methods)를 통해서 학습이 되는데, 이 논문에서는 activation function이 어떻게 training에 영향을 끼치는지에 대해 설명함
2. Dataset
- MNIST, CIFAR10, Small-ImageNet
3. activation
- soft-sign activation function
activation function은 excessive saturation과 overly linerar units을 고려해야 할 필요가 있음
sigmoid 같은 경우는 지그재그로 움직이는 none-zeron mean 문제로 learning이 느려지게 하는 것을 이미 알려져 있음.
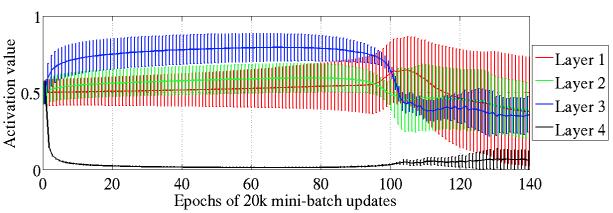
Sigmoid를 activation function으로 사용하면 Top hidden layers(layer 1, 2, 3)의 경우 epochs 100이 지나야 desatureates되는 것을 확인 할 수 있음 -> training이 어렵다는 증거
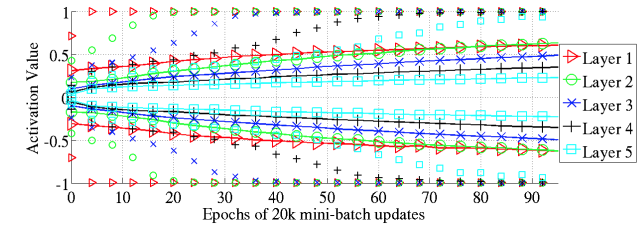
0에서 대칭이 되기 때문에 tanh() activation fuction의 경우 sigmoid와 같은 현상은 없지만, 순차적으로 포화 현상(sequentially occuring saturation phenomenon starting with layer 1 and propagating up in the network)이 발생함
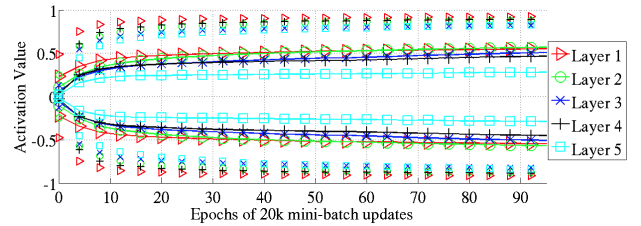
softsign의 경우 점진선(asymptotes) 때문에 tanh()와는 다른 양상을 보임.
4. 결론
- sigmoid or tahn units and standard initialization은 궁극적으로 나쁜 local minima로 수렴하기 때문에 다소 좋지 않음
- softsign network는 gentler non-linearity 때문에 initialization procedure에 좀 더 robust함
- tanh network의 경우, layer-to-layer transformation이 activation(flowing upward)과 gradient(flowing backward)의 크기를 유지하기 때문에 normalized initialization이 꽤 도움이 될 수 있음

매일 성장하고 있습니다