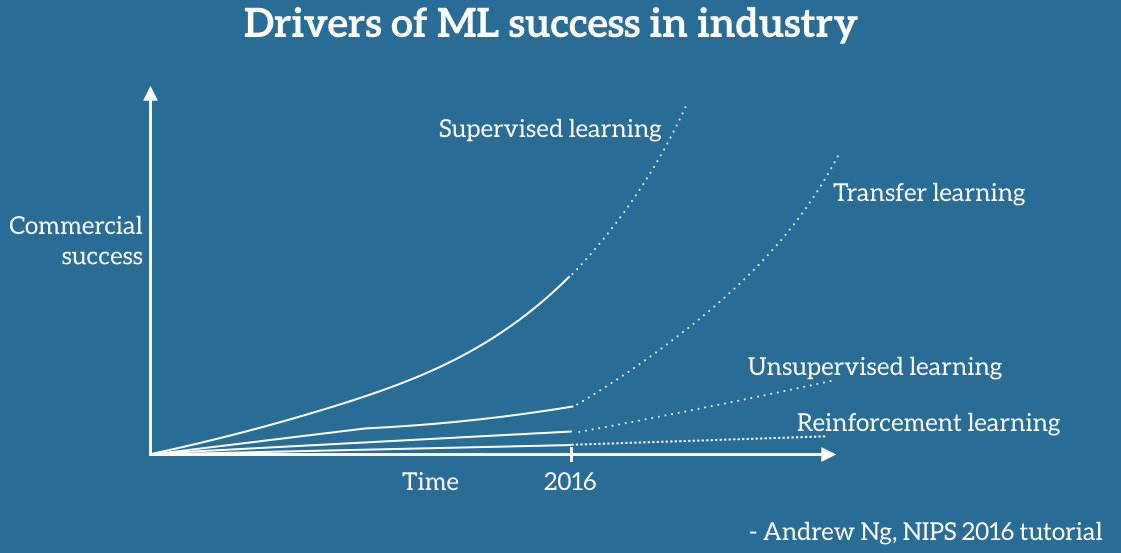
2016년 NIPS에서 Andrew Ng이 미래에는 Transfer learning이 훨씬 더 중요해질 것이라고 예언을 하였다. Transfer learning이 중요해진 이유는 더 짧은 시간에 적은 데이터의 양으로 학습을 진행할 수 있기 때문에 실무에서는 많이 쓰고 있는 상황이다.
1. Transfer learing의 정의
Transfer learning의 개념은 대규모 데이터를 대상으로 학습이 진행된 모델을, 상대적으로 유사한, 새로운 데이터셋으로 학습을 시키는 것이다. 학습의 가중치를 재사용함으로써 데이터의 수집에 대한 비용을 감소하고, 바로 활용을 할 수 있도록 하는 것이다.
2. Transfer learning의 원리
앞단의 layer의 경우, 범용적인 특성을 가지고 있고, layer가 깊어질 수록 복잡한 feature를 찾아낼 수 있게 된다. 보통 이미지가 비슷하면 비슷할수록 transfer learning이 잘 되긴 하지만, 앞단의 layer의 경우에는 일반적인 특성을 가졌기 때문에 대부분의 이미지는 비슷한 경향이 있다. 중요한 것은 누적된 weight들을 전파(propagation)하는 것이 중요한 것이기 때문에 이미지가 달라도 크게 문제는 없다. 다만, target data의 유사도, 양에 따라 접근을 다르게 해야 할 필요가 있다.
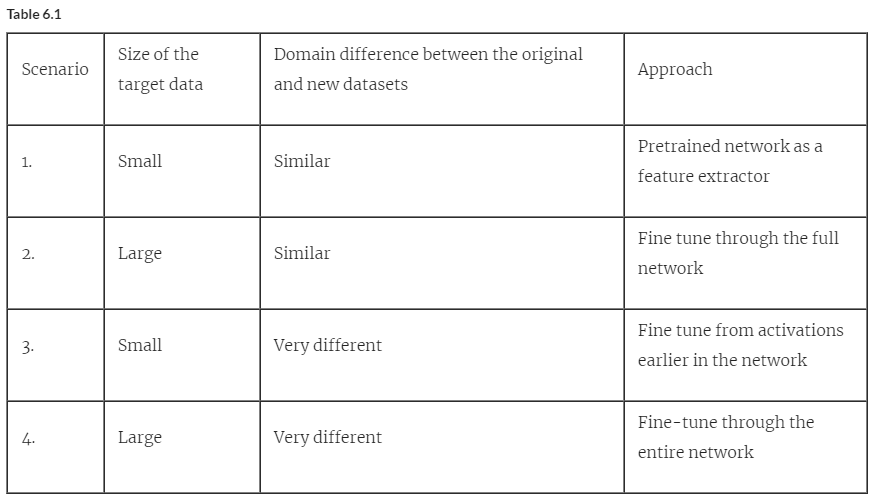
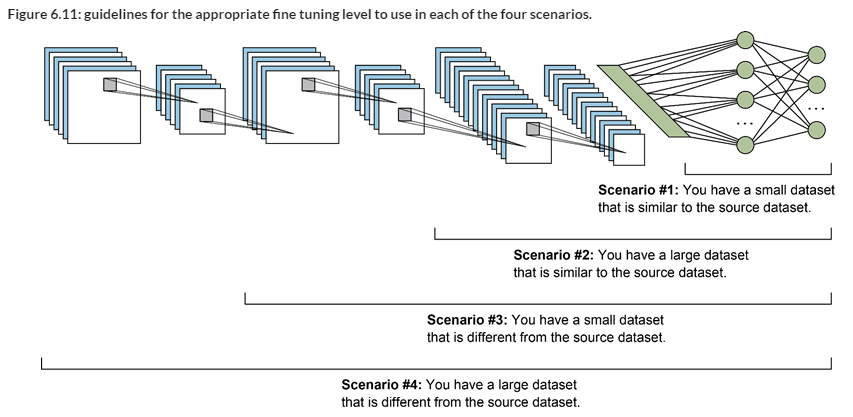
Transfer learning의 전제 조건은 비슷한 이미지를 분류하는 모델을 통하여 Transfer learning을 해야 한다는 것이지만, MS-COCO, ImageNet 같이 대규모의 class를 분류하는 모델이 있다면 학습된 weight들이 새로 학습을 시킬 데이터에 대해 새롭게 분류를 할 수 있게 된다.

예를 들어 3을 숫자로 입력하게 되면 위와 같은 형태로 '3'이란 숫자를 파악하게 된다. 즉, 범용적인 능력을 가진 classifier를 통하여 feature map을 뽑고, 이를 통하여 transfer learning을 하면 된다. 만약, 비슷한 이미지를 분류하는 model(개vs고양이)이라면 Feature extraction을 하면 된다.
2.1. 데이터셋의 크기가 작고, 두 모델이 유사한 경우
데이터셋의 크기가 작기 때문에 feature-extractor에 해당하는 layer를 fine-tuning 범위에 포함시키면 과적합이 발생하기 쉬워진다. 따라서, 데이터셋의 크기가 작으면 feature를 담지 못할 가능성이 높기 때문에 일반화 성능이 떨어지고, 과적합을 일으킬 가능성이 있다.
따라서 데이터셋의 크기가 작다면 사전 학습된 신경망의 미세 조정 범위를 넓히는데 주의해야 한다
2.2. 데이터셋의 크기가 작고, 두 모델이 크게 다른 경우
사전 학습된 모델의 앞 부분 60~80% 정도를 고정하고 나머지 부분을 데이터셋으로 재학습 시키는 것이 적절하다
2.3. 데이터셋의 크기가 크고, 두 모델이 크게 다른 경우
앞단 layer의 일부 저수준 특징을 고정하여, 전체 신경망을 fine tuning 범위로 삼는 것이 좋다. 그러나 데이터셋의 크기가 작은 만큼 전체 신경망의 재학습이 어려울 수 있다. 사전 학습된 모델의 1/3이나 절반 정도의 feature를 고정하는 수준으로 시작하는 것이 적절하다.
2.4. 데이터셋의 크기가 크고, 두 모델이 크게 다른 경우
데이터셋의 크기가 큰 경우, 사전 학습된 weight를 재학습 시키는 경우가 이로운 경우가 많다. 학습 시간이 빠르고, 과적합에 대한 걱정 없이 재학습을 시킬 수 있다
3. Tensorflow에서의 용어 정리
Feature Extraction: Use the representations learned by a previous network to extract meaningful features from new samples. You simply add a new classifier, which will be trained from scratch, on top of the pretrained model so that you can repurpose the feature maps learned previously for the dataset.
You do not need to (re)train the entire model. The base convolutional network already contains features that are generically useful for classifying pictures. However, the final, classification part of the pretrained model is specific to the original classification task, and subsequently specific to the set of classes on which the model was trained.
Fine-Tuning: Unfreeze a few of the top layers of a frozen model base and jointly train both the newly-added classifier layers and the last layers of the base model. This allows us to "fine-tune" the higher-order feature representations in the base model in order to make them more relevant for the specific task.
