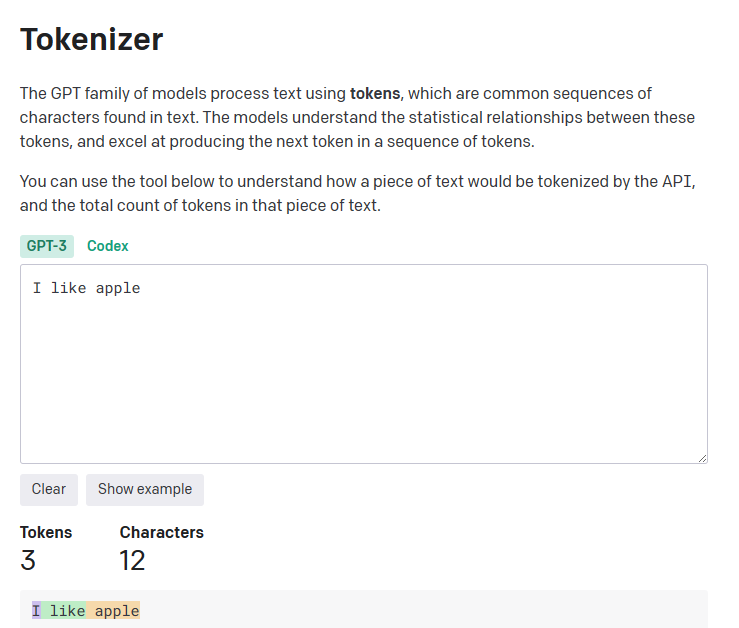
gpt api 과금은 토큰 수에 따라 결정 되는데, 프롬프트의 토큰 수는 openai의 tokenizer에서 확인 할 수 있다.
예시로 "I like apple"은 3토큰임을 알 수 있다.
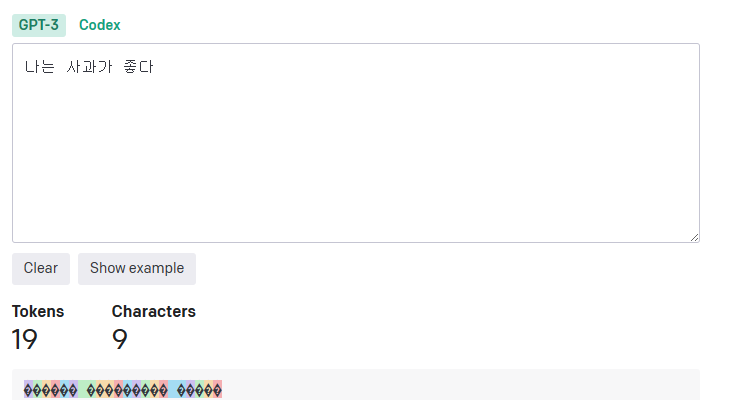
그리고 "나는 사과가 좋다"는 같은 의미지만, 한국어로 작성되어 19토큰을 차지하는 것을 알 수 있다.
즉, gpt api를 사용할 때 프롬프트를 한국어로 적으면 영어로 적을 때에 비해 상대적으로 금전적인 손해를 보는 것이다.
그래서 한국어는 그대로 사용하지만 보이지 않는 어떤 신비로운 알고리즘의 힘으로 잘 압축하여 "토큰-이득"을 볼 수 있는 방법을 생각해보았다.
-
토큰 고려없이 풀어 쓴 프롬프트
-
1과 같은 의미를 가지지만 잘 정제하여 줄인 프롬프트
-
2의 문장을 형태소 분류하여 최소 의미만 가지도록 자르기
-
gpt가 파편화된 문장을 잘 해석하기를 빌기
대충 이런느낌으로... 어떻게 잘 하면 잘 되지않을까?
20230630 추가
서문
현재 gpt api는 모델별로 토큰당 각각 xx달러인데, 토큰 집계방식의 차이때문에 같은 의미를 가진 프롬프트라도
영어와 한국어로 작성되었을때 토큰 수가 큰 차이가 난다.
따라서 프롬프트와 결과물의 토큰 갯수에 따라 사용료를 지불하는 api 호출은
프롬프트를 영어로 작성하여 결과 또한 영어문장으로 받는 방식이 경제적이다.
하지만 해당 방식은 이용자가 영어 작문과 해석에 무리가 없거나,
프롬프트 작성과 결과 해석에 번역기를 사용하는 과정이 추가되는 단점이 있다.
그래서 이번 문서에서는 한국어로 작성된 프롬프트를 상대적으로 저렴하게 사용하기 위한 방법인
"토큰-이득" 기법을 제안하고 실제로 효과가 있는지 실험했다.
"토큰-이득"을 간단히 설명하면 한국어로 작성된 프롬프트를 형태소 단위로 자르고 꼭 필요하다고 생각되는 품사만 골라
사용하여 gpt 모델이 스스로 형태소 단위의 프롬프트를 완성된 형태의 프롬프트로 해석하게 하는 것이다.
즉 상대적으로 적은 토큰의 프롬프트로 비슷한 결과를 내는 것이 목적으로, 아래 두가지 효과를 기대할 수 있다.
첫째, 비슷한 결과를 상대적으로 짧은 프롬프트를 통해 얻음으로써 토큰당 지불하는 사용료의 절감 기대
둘째, 모델이 받을 수 있는 토큰의 수가 한정되어 있기 때문에, 프롬프트를 압축함으로써 더 많은 정보를 전달 가능- gpt 프롬프트 전달
토크나이저의 모델 종류에 따라 토큰을 세는 기준이 다르기 때문에
먼저 GPT api를 호출할때 어떤 버전의 토크나이저를 사용하여 과금하는지, 토큰당 얼마의 사용료가 책정되는지 알아야 한다.
api 호출당 책정되는 사용료는 홈페이지에서 확인할 수 있다.

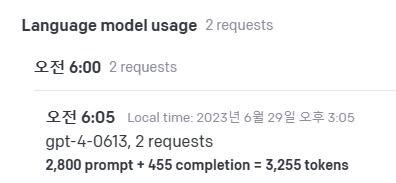
prompt와 completion의 토큰 수가 합산되는 것을 알 수 있다.
tiktoken 라이브러리를 사용하여 측정한 토큰의 수는 다음과 같다.
<tiktoken 호출 결과 이미지>
a 모델을 사용하여 api를 호출할 때 b 토크나이저를 사용하여 토큰의 수를 측정함을 알 수 있다.
이를 바탕으로 측정한 각 모델별 토크나이저 토큰 수치는 아래 표와 같다.
<각 api 모델별 토크나이저 토큰 측정 이미지>
- 프롬프트 압축
이제 각 모델별 토크나이저를 통해 토큰 수를 측정 할 수 있게 되었으니, 프롬프트를 압축하는 방법을 생각해야 한다.
그래서 한국어 형태소 분류기를 사용하여 프롬프트를 각 형태소 품사로 구분하고, 꼭 필요하다고 판단되는 성분만 남기는 방향으로 진행하였다.
이번 테스트에서는 Mecab, Kkma, Kiwi등의 한국어 형태소 분석기 중 범용성과 속도, 편의성등을 고려하여 Kiwi 분석기를 사용하였다.
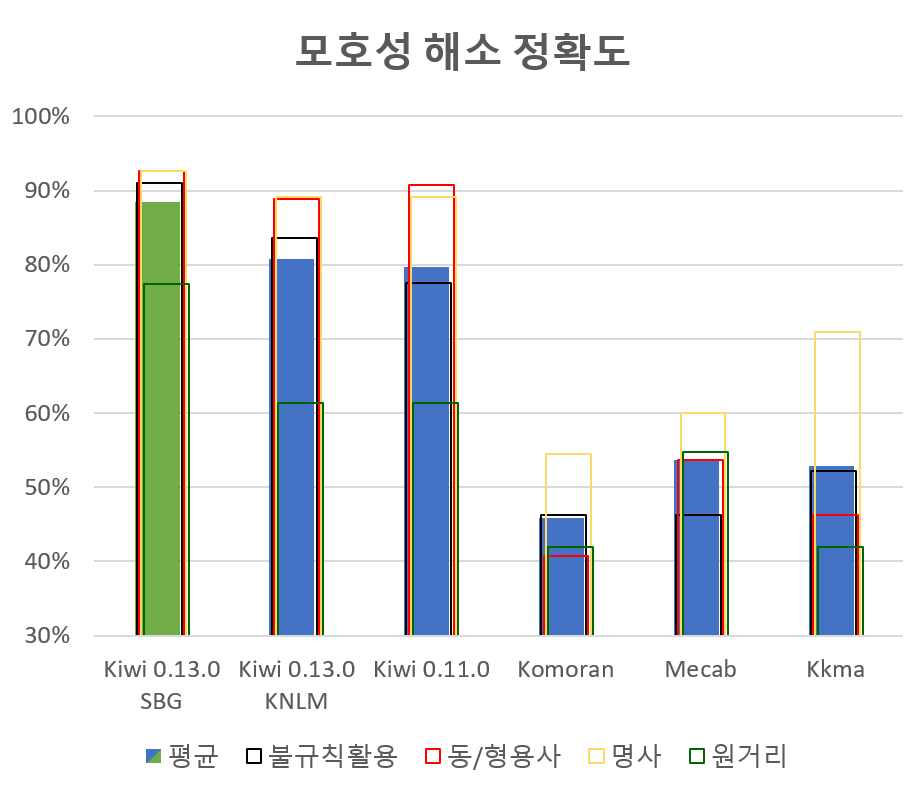
형태소 품사 태그는 꼬꼬마 한국어 형태소 분석기 태그표를 참고하였다.
kiwi 라이브러리 사용 예시는 다음과 같다.
def kiwi_tokenizer(tt):
kiwi = Kiwi(model_type="sbg", typos="basic")
result = kiwi.tokenize(tt)
# 동사, 일반명사, 어근, 형용사, 외국어, 숫자, 의존명사 태그로 필터링
tags = ["VV", "NNG", "XR", "VA", "SL", "SN", "NNB"]
word = [x.form for x in result if x.tag in tags]
return word예시 프롬프트를 토크나이저와 kiwi 형태소 분석기를 통해 토큰을 측정하고 문장을 압축한 결과는 다음과 같다.
def tokenize(prompt):
tz = tiktoken.get_encoding("cl100k_base")
tz = tiktoken.encoding_for_model("gpt-4-0613")
return len(tz.encode(prompt))
1. "적당한 길이의 sf 소설을 쓰세요. 그리고 소설의 주요 키워드와 주제문을 마지막에 작성하세요."
2. "적당 길이 sf 소설 쓰 소설 주요 키워드 주제문 마지막 작성"1번 프롬프트를 토크나이저로 계산 했을때는 47 토큰, kiwi 형태소 분류기를 사용하여 동사, 일반명사, 어근, 형용사 등의 한글 형태소 품사를 추출한 2번 프롬프트는 33 토큰으로 측정되었다.
프롬프트의 길이가 길어질수록 형태소 단위로 잘라낼 경우 토큰 수가 더 크게 차이날 것이다.
- 결과 정보 추출
이번 섹션에서는 프롬프트를 통해 얻은 결과물로 부터 정보를 추출하는 방법을 제시하고 실제로 그 결과를 비교할 것이다
이미지참조
https://github.com/bab2min/Kiwi
https://platform.openai.com/
