어렵다고 겁먹는 사람이 많은데…
매우 중요한 파트이다. 정렬이 컴퓨터 공학 분야의 정수나 다름없다!
정렬이란?
Sorting, 정렬 알고리즘이란 컬렉션(collection)의 항목을 재배열하는 과정을 의미한다.
보통 배열을 가지고 많이 한다.
숫자를 가진 배열을 오름차순, 또는 내림차순으로 정렬.
알파벳을 가진 배열을 알파벳 순으로 정렬하는 것도 가능.
뭘로 정렬할지는 중요하지 않음.
현존하는 유명 정렬 알고리즘은 15개도 더된다.
완전히 똑같은 작업을 수행하는 방법이 매우 다양하다.
성능 차이가 꽤 난다.
특정 상황에서만 빠르고 대부분 느린 경우도 있다.
다양한 정렬 알고리즘을 시각화해놓은 자료
https://www.youtube.com/watch?v=kPRA0W1kECg
정렬 알고리즘을 확실히 공부해야 하는 이유
정렬 알고리즘은 매우 흔하게 쓰인다. 어떤 언어를 사용하더라도 거기에 사용되는 알고리즘을 알고 특정 상황에서 알맞은 방법을 찾아야 한다.
특정 상황에 맞는 알고리즘을 사용하면 성능이 향상된다.
예를 들어 상당히 정렬된 데이터(nearly sorted data)를 가지고 작업을 한다고 가정하면, 일부만 정렬이 안된 상태이다. 이럴때 빠르게 작동하지 않을 내장 알고리즘을 사용하는 대신 직접 정렬 알고리즘을 사용할 수 있다.
또한 정렬은 전형적인 면접 주제이다. ← 제일 중요
훌륭한 주제이다. 접근법도 다양하고 비판적 사고가 필요한 도전 과제.
다양한 정렬 알고리즘을 시각화해서 비교해놓은 사이트.
https://www.toptal.com/developers/sorting-algorithms
알고리즘을 비주얼화해서 보여주는 사이트
배울것들
- Bubble sort (버블정렬)
- Selection sort (선택정렬)
- Insertion sort (삽입정렬)
이렇게 3개가 기본 정렬 알고리즘.
효율성이 떨어지기 때문에 흔히 사용되지는 않음.
특정 상황에서는 매우 효율적임.
자바스크립트 내장 정렬
sort()자바스크립트의 내장 정렬은 문자열 유니코드(unicode) 코드 포인트에 따른다.
즉 배열의 모든 항목이 문자열로 변환되고, 해당 문자열의 유니코드 값이 선택되고, 그에따라 항목이 정렬.
하지만 sort() 괄호 안에 비교 함수를 넣어주면 원하는대로 정렬이 가능하다.
a,b가 들어가는 함수. 반환되는 값을 토대로 정렬 순서를 만든다.
-
함수가 음수를 반환 → a가 b앞에 온다.
-
함수가 양수를 반환 → a가 b뒤에 온다.
-
함수가 0를 반환 → a와 b를 동일하게 취급하고 한꺼번에 정렬함.
-
sort((a,b) -> a-b) // 오름차순 1,2,3
-
sort((a,b) -> b-a) // 내림차순 3,2,1
문자열의 길이가 짧은 순으로 정렬한다면 이렇게 가능.
function compareByLen(str1, str2) {
return str2.length - str1.length;
}
.sort(compareByLen)Bubble Sort (버블 정렬)
sinking sort라고도 한다. 별로 효율적이지 않음.
흔히 사용되지도 않음. 하지만 사용되는 케이스가 있다.
버블정렬의 개념은 배열을 오름차순으로 정렬 한다면
더 큰 숫자가 한 번에 하나씩 뒤로 이동을 한다는 것.
작동방식은 루프를 돌면서 각 항목을 다음 항목(해당 항목의 오른쪽에 있는 항목)과 비교하는 것.
비교해서 왼쪽이 더 크면 swap(교환)한다.
루프를 한번 돌면 가장 큰 값이 맨 오른쪽으로 이동한다.
그 다음 처음부터 다시 비교한다. 그러면 두번재로 큰 값이 오른쪽에서 두번째 자리로 간다.
swap이 일어나지 않을때까지 반복.
버블정렬 구현
- 외부 루프를 i라는 변수로 시작. i는 배열의 끝에서 시작.
- 내부 루프는 j라는 변수로 시작. j는 i-1 전까지.
- arr[j]가 arr[j+1]보다 크면 스왑.
- 반복.
function bubbleSort(arr){
for(var i = arr.length; i > 0; i--){
for(var j = 0; j < i - 1; j++){
console.log(arr, arr[j], arr[j+1]);
if(arr[j] > arr[j+1]){
var temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
return arr;
}바깥에 루프는 뒤에서부터 앞으로 간다.(정렬이 진행될수록 뒤쪽에는 큰값이 쌓이므로 뒷부분은 비교할 필요가 없기 때문)
안쪽 루프가 돌아가면서 오른쪽 옆 값과 비교하여 왼쪽이 더 크면 스왑한다.
만약 거의 정렬이 된 상태여서 중간정도에서 이미 정렬이 다 된 상태가 되었다고 가정하면, 앞에 나머지 절반은 루프를 돌 필요가 없다. 따라서 스왑이 한번도 발생하지 않는(정렬이 완료된 상태)라면 루프를 break하는 코드를 넣으면 더 최적화 된다.
function bubbleSort(arr){
var noSwaps;
for(var i = arr.length; i > 0; i--){
noSwaps = true; // 디폴트는 트루
for(var j = 0; j < i - 1; j++){
if(arr[j] > arr[j+1]){
var temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
noSwaps = false; // 스왑이 발생하면 false로 바뀜.
}
}
if(noSwaps) break; // 스왑이 발생하지 않았다면(true라면) break;
}
return arr;
}
bubbleSort([8,1,2,3,4,5,6,7]);버블정렬의 Big-O
일반적으로는 O(n^2) 이다.
이중 반복문으로 배열의 각 항목이 모든 항목과 하나하나 비교하기 때문.
하지만 데이터가 거의 정렬됐거나(nearly sorted), 이미 정렬이 끝난 상태에서는선형 시간(linear time)에 가깝다.
즉 최고의 경우 O(n).
즉 버블정렬은 ‘데이터가 거의 정렬된 상태’ 라는 것을 알고 있는 경우에 사용하면 된다.
Selection Sort (선택정렬)
처음부터 루프를 돌면서 최솟값을 찾아내어 루프의 마지막까지 돈 후 맨 앞에 배치함.
다음 루프를 돌때는 앞에 배치한 다음 인덱스부터 루프 시작.(가장 작은 값이니 비교할 필요가 없다)
선택정렬 구현
- 최솟값을 저장할 변수를 만든다. 처음에는 첫번째 항목과 같게 설정. (값이 아닌 인덱스를 저장)
- 다음 항목과 비교, 다음 항목이 더 작으면 해당 항목을 변수 값으로 갱신. 반복.
- 배열의 끝에 도달하면 가장 작은 최솟값을 맨 앞으로 스왑.
- 그 다음인덱스를 시작점으로 해서 반복.
function sselectionSort(arr){
for(var i = 0; i < arr.length; i++){ // 외부 루프에서 최솟값 변수 지정.
var lowest = i;
for(var j = i+1; j < arr.length; j++){ // 최솟값을 찾아내는 내부 루프
if(arr[j] < arr[lowest]){
lowest = j;
}
}
if(i !== lowest){ // 맨 앞에 인덱스가 최솟값이 아니라면 스왑.
//SWAP!
var temp = arr[i];
arr[i] = arr[lowest];
arr[lowest] = temp;
}
}
return arr;
}선택정렬의 Big-O
O(n^2)이다. 모든 요소를 배열 속 다른 모든 요소와 비교해야 한다.
배열의 길이가 길어지면 비교 횟수도 n의 제곱 비율로 늘어난다.
대부분의 경우 효율적이지 못함.
선택정렬이 버블정렬보다 나은 시나리오는 스왑 수를 최소화하는 경우.
버블정렬은 매번 바꾸지만 선택정렬은 끝가지 비교 후 한번만 스왑.
따라서 메모리에 쓰는 것을 고려하거나 실제 스왑을 수행한다면 매우 드물긴 하지만 선택정렬이 효율적이다.
Insertion Sort (삽입정렬)
배열의 과반을 점차적으로 만들어 정렬을 구축하고, 그 과반은 항상 정렬되어 있다.
하나씩 이동하거나, 가장 큰값, 가장 작은 값을 찾는 대신,
각 요소를 취하여 정렬되어 있는 절반 속 해당되는 위치에 배치한다.
앞에서부터 새로운 정렬을 만들어 뒤로 가면서 취하는 값을 앞에 정렬에서 제 자리에 삽입해줌.
끝까지 돌면 새로운 정렬이 전체 정렬이 된다.
즉 ‘한 번에 하나를 취해서 올바른 위치에 삽입’하는 방식이다.
삽입정렬 구현
- 배열의 두번째부터 시작함. 왜냐면 첫번째 요소는 정렬된 부분으로 간주.
- 두번째 요소를 첫번째 요소와 비교하여 삽입.
- 뒤로 이동하며 반복.
function insertionSort(arr){
var currentVal;
for(var i = 1; i < arr.length; i++){
currentVal = arr[i];
for(var j = i - 1; j >= 0 && arr[j] > currentVal; j--) {
arr[j+1] = arr[j]
}
arr[j+1] = currentVal;
}
return arr;
}
insertionSort([2,1,9,76,4])삽입정렬의 Big-O
최악의 경우 → O(n^2)
이중 반복문으로 배열의 길이가 늘어날수록 비교 획수를 n제곱해야하기 때문.
하지만 데이터가 거의 정렬되어 있는 경우, 스왑이 일어나지 않고 지나가므로 빠르다.
삽입정렬에서 최악의 경우는 reverse. 내림차순을 오름차순으로 바꾸는 것. 전부다 스왑이 일어난다.
온라인 알고리즘으로 데이터가 들어오는 대로 작동해야 한다면.
들어오는 것만 제자리에 넣어주면 되니 효율적이다. 어떤 숫자가 들어와도 제자리에 놓을 수 있다.
이런 방식으로 작동하는 정렬 알고리즘을 찾을 경우 효율적이다.
라이브, 스트리밍 방식.
버블, 선택, 삽입 정렬 비교
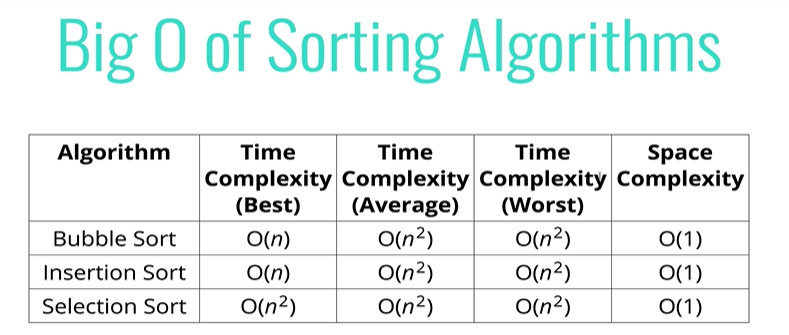
베스트 케이스에서 O(n)을 보이는 경우는
거의 정렬된 데이터를 가지고 버블정렬, 삽입정렬을 하는 경우.
버블정렬은 스왑이 일어나지 않고 넘어가니 빠르다.
삽입정렬도 올바른 위치에 배치되어 있다면 아무것도 수행하지 않고 각 항목을 이전 항목과 비교만 하고 넘어간다.
기본적으로 루프를 한번만 돌면 된다.
하지만 선택정렬은 매번 최솟값을 찾기 위해 끝까지 루프를 돌기 때문에 거의 정렬된 데이터를 해도 느리다.
공간 복잡도는 모두 크지 않다. 새로운 배열 같은 것을 만들지 않기 때문.
뒤에 배우는 합병 정렬 등은 더 작은 배열을 여러개 만든다. 그러면 공간 복잡도는 O(1)이 아니다.
삽입정렬은 기존에 정렬된 데이터가 있고 새로 받은 데이터를 넣어서 정렬할때 유용하다.
정렬들의 작동방식을 시각화한 사이트
