[논문요약] SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
논문요약

Abstract
SegFormer의 특징은 크게 두가지로 볼 수 있다.
1) Encoder를 계층적으로 구성해 multiscale feature output을 가진다. 또한 position encoding을 사용하지 않는다.
-기존 ViT라면 학습 시 사용되지 않은 이미지를 테스트하기 위해 fine-tuning할 때 position code에 interpolation 사용해아하는데 그러지 않아도 되기에 interpolation으로 인한 성능하락은 피할수 있게된다.
2) 복잡한 Decoder가 아니라 MLP만 사용되는 가벼운 Decoder를 사용한다.
-각기 다른 레이어들의 output들을 통합함으로써 local attention과 global attention을 결합해 강력한 표현력을 갖는다.
이러한 SegFormer는 Cityscapes,ADE20K 데이터셋에서 SOTA를 기록했으며, Cityscapes-C에서 우수한 zero-shot robustness도 입증했다.
Method
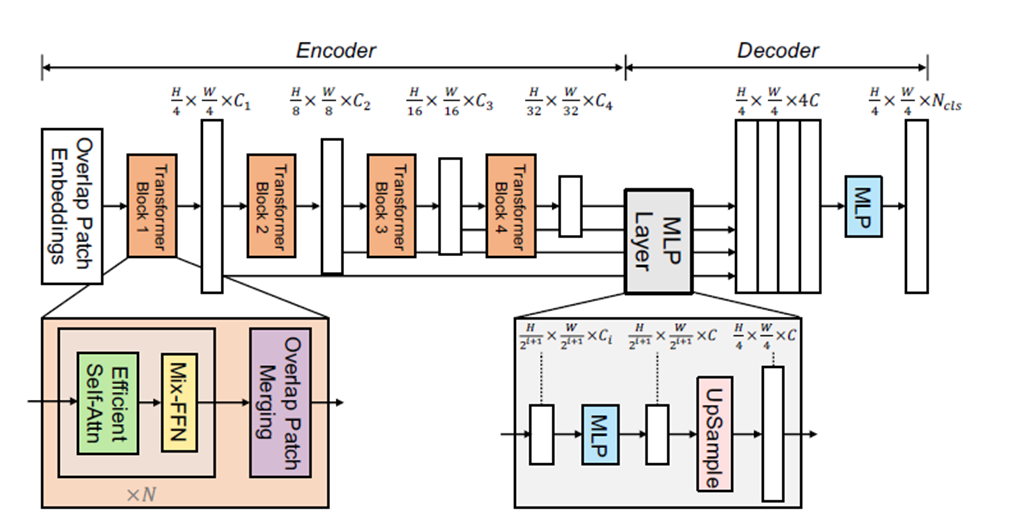
Hierarchical Transformer Encoder
저자가 디자인한 Transformer Encoder를 Mix Transformer encoder(MiT)라고 명명한다.
Hierarchical Feature Representation
ViT는 single scale resolution feature map만 뽑는 것에 반해 이 모델은 CNN처럼 multi-level feature map을 추출한다.
이 feature map들은 high-resolution coarse features와 low-resolution fine-grained features를 제공해 semantic segmentation 성능을 향상시킨다.
stage별로 아래와 같은 해상도를 가진다.
Overlapped Patch Merging
초기 ViT는 non-overlapping patch merging방법이 사용되었으나, 이는 패치 주변의 local continuity를 보존하지 못한다.
이를 해결하고자 Swin Transformer는 Shifted Window으로 문제에 접근했고, SegFormer에서는 overlapping patch merging 으로 접근했다.
CNN에서 window sliding하는 것처럼 겹치게 움직여가며 patch merging을 한다.
이를 위해 사전에 K=patch size, S=stride, P=padding size를 정의한다.
논문에서는 non-overlapping process와 동일한 size의 output feature를 생성하도록 stage 1 : K=7, S=4, P=3 , stage 2,3,4 : K=3, S=2, P=1로 설정했다.
Efficient Self-Attention
본래 Self-Attention 연산 시에 Q,K,V은 같은 demension(NxC, N=HxW)을 가지며, 계산복잡도는 O(N^2)가 된다. 이 경우 이미지의 해상도가 높아지면 계산량이 과도하게 커진다.
그래서 연산량을 줄이기 위해 K,V의 사이즈를 줄여 Self-Attention연산을 한 것이 Efficient Self-Attention이다.
K, V의 사이즈를 줄이는 과정은 아래와 같다.
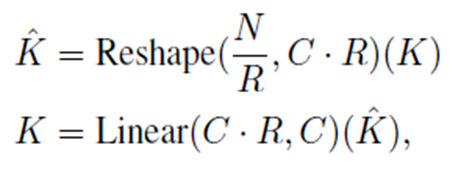
연산시 사용되는 R은 reduction ratio를 의미하는 변수이다.
이런 과정을 거치고 attention 연산을 할 경우, 계산복잡도가 O(N^2)에서 O(N^2/R)로 줄어든다.
Mix-FFN
ViT에서는 Positional Encoding(PE)를 사용하지만 저자는 Positional Encoding이 semantic segmentation에서는 필요하지 않다고 주장한다.
그렇기에 Positional Encoding대신 3x3 Covolution을 도입한다.
location 정보를 convolution에 zero padding을 사용함으로써 고려할 수 있다고 언급한다.
공식은 아래와 같다.
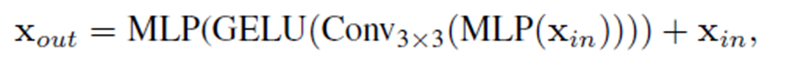
이는 수를 줄이며 효율성을 향상시킨다.
Lightweight All-MLP Decoder
오직 MLP으로만 구성된 Decoder로 수작업 및 연산량이 크게 요구되지 않는다.
main step은 아래와 같다.
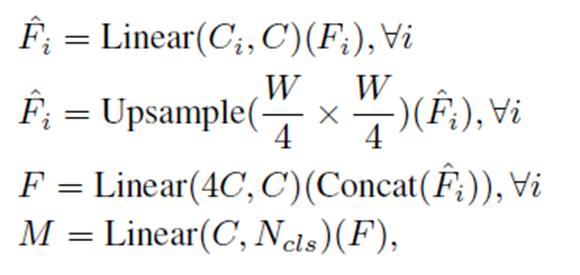
1) Linear연산으로 multi-level feature들의 channel을 모두 동일하게 통합
2) Upsampling으로 feature size를 original image의 1/4 크기로 통합
3-1) 모든 feature들을 concatenate
3-2) 4배로 증가한 channel을 원래대로 복구
4) 최종 segmentation mask를 예측(shape = B(batch) x N(num of class) x H/4 x W/4)
Experiment
1. Ablation Studies
Influence of the size of model.
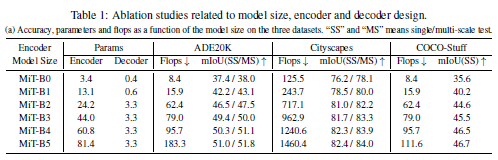
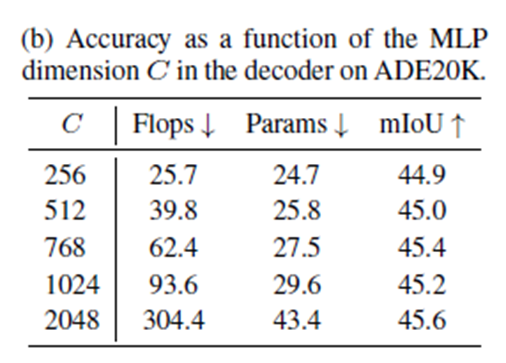
Influence of C, the MLP decoder channel dimension
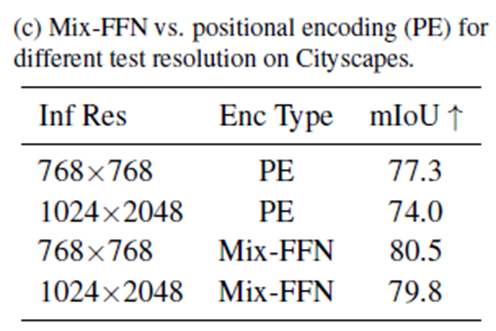
Mix-FFN vs. Positional Encoder (PE).
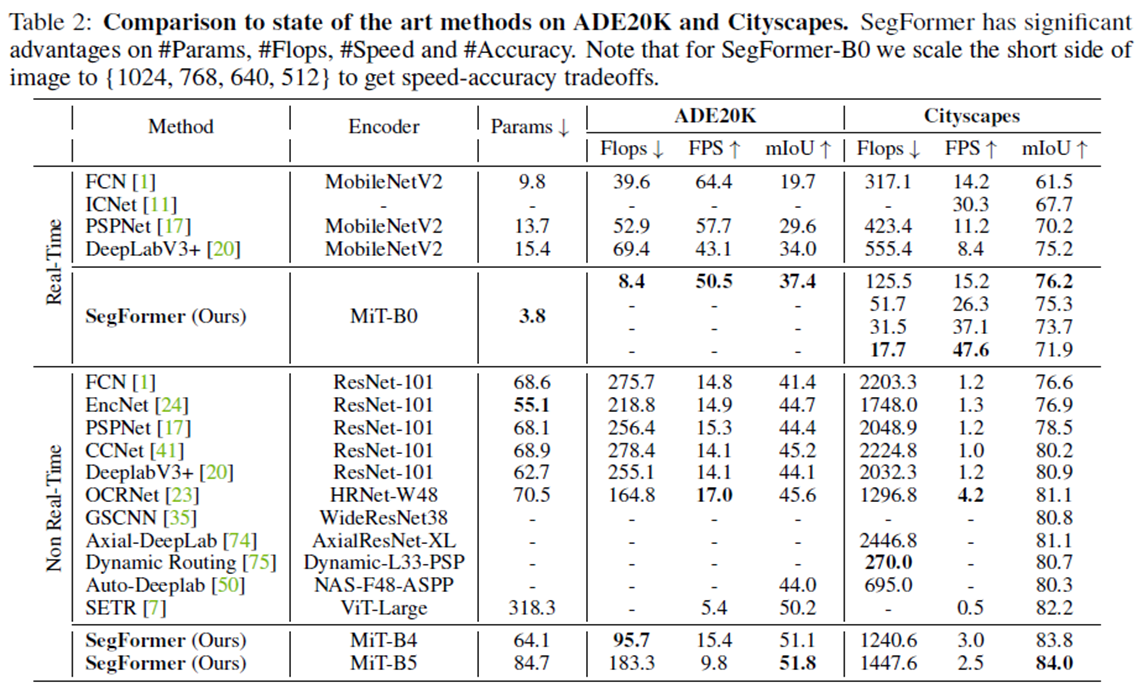
2. Comparison to state of the art methods
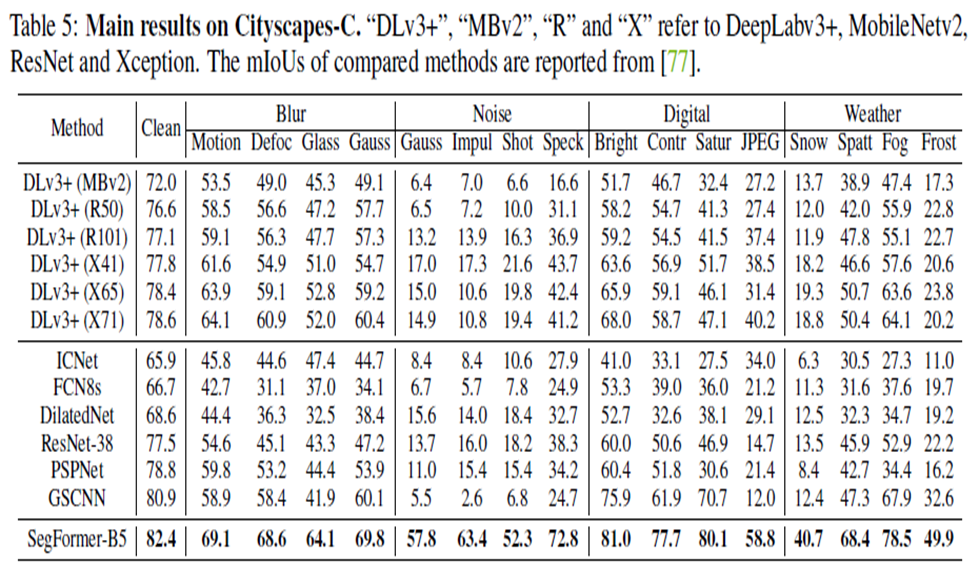
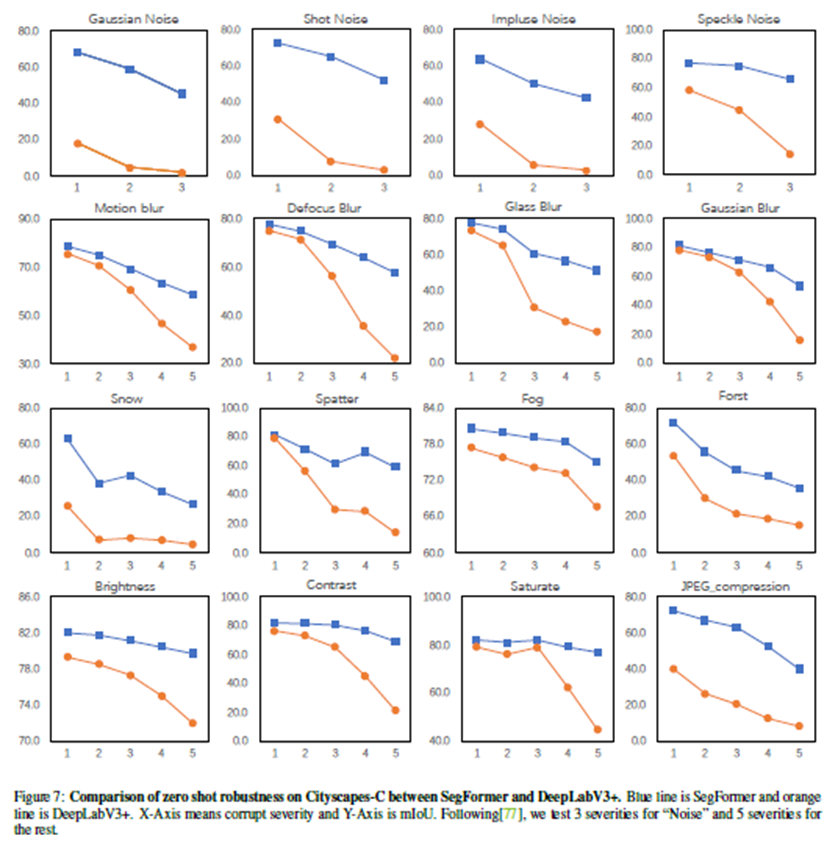
3. Robustness to natural corruptions
Conclusion
SegFormer는 positional-encoding-free, hierarchical Transformer encoder and a lightweight All-MLP decoder를 포함하는 semantic segmentation model이다.
이전 모델들의 복잡한 디자인을 피해 높은 효율성과 성능을 보였다.
기존 Dataset에서 SOTA 달성했을 뿐만 아니라 강력한 zero-shot robustness를 입증했다.
한계점으로는 SegFormer의 가장 작은 모델은 일반적인 CNN 모델보다 적은 파라미터를 가지지만 100k memory수준의 edge device에서 잘 작동 될지는 불분명하다는 것이다.
참고
썸네일 제작 : https://ye-yo.github.io/toy/2022/01/21/thumbnail-maker.html
