Abstract
Recent advances in image-based 3D human shape estimation have been driven by the significant improvement in representation power afforded by deep neural networks. Although current approaches have demonstrated the potential in real world settings, they still fail to produce reconstructions with the level of detail often present in the input images. We argue that this limitation stems primarily form two conflicting requirements; accurate predictions require large context, but precise predictions require high resolution. Due to memory limitations in current hardware, previous approaches tend to take low resolution images as input to cover large spatial context, and produce less precise (or low resolution) 3D estimates as a result. We address this limitation by formulating a multi-level architecture that is end-to-end trainable. A coarse level observes the whole image at lower resolution and focuses on holistic reasoning. This provides context to an fine level which estimates highly detailed geometry by observing higher-resolution images. We demonstrate that our approach significantly outperforms existing state-of-the-art techniques on single image human shape reconstruction by fully leveraging 1k-resolution input images.
2D 이미지에서 인간 3D geometry를 생성하는 방법은 많은 발전을 이루어냈지만, 입력 이미지의 세부적인 디테일을 재구성하지 못함.
왜냐하면 딥러닝 예측의 정확성을 올리기 위해선 큰 용량의(고해상도의) 데이터가 필요하지만 하드웨어상의 한계로 인해 현재의 접근방식은 저해상도의 이미지를 사용하기 때문에 결과로써 저해상도의 결과를 생성하는 경향이 있음.
본 논문에서는 multi level로 쌓을 수 있는 end to end (trainable) 아키텍쳐를 공식화하여 이러한 문제를 해결하였고 이러한 접근 방식으로 고해상도 이미지를 효과적으로 처리할 수 있음은 물론이고 기존의 기술들보다 좋은 성능을 기록한것을 보여주었음.
Introduction
Our observation is that existing approaches do not make full use of the high resolution (e.g., 1k or larger) imagery of humans that is now easily acquired using commodity sensors on mobile phones.
충분히 좋은 성능의 사진을 쉽게 구할 수 있음에도 고화질의 사진을 하드웨어상의 한계로 사용하지 못함.이러한 저해상도의 이미지 인풋을 해결하기 위한 다음과 같은 방법들이 있다.
Approaches that aim to address this limitation can be categorized into one of two camps. In the first camp, the problem is decomposed in a coarse-to-fine manner, where high-frequency details are embossed on top of low-fidelity surfaces. In this approach, a low image resolution is used to obtain a coarse shape. Then, fine details represented as surface normal [51] or displacements [3] are added by either a post-process such as Shape From Shading [14] or composition within neural networks. The second camp employs high-fidelity models of humans (e.g., SCAPE [5]) to hallucinate plausible detail.
첫번째는 coarse-to-fine 방법이다. 이는 고해상도의 디테일들(high-frequency details)을 저해상도의 표면에 투사하여 후처리 하는 방법으로 저해상도(coarse)에서 디테일이 사라지는 문제를 해결한다.
두번째 방법은 고해상도의 인간 3D geometry 모델을 사용하는 방법이다. 두 방식 모두 디테일들을 재구성할 수 있지만 실제 입력 이미지의 디테일을 구현하지 못한다.
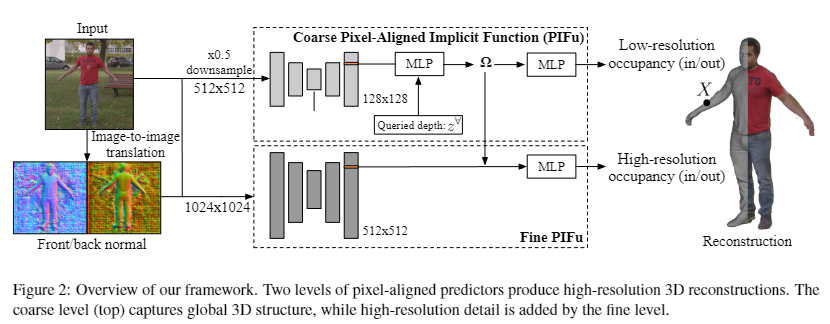
We base our method on the recently introduced Pixel-Aligned Implicit Function (PIFu) represen- tation [35]. The pixel-aligned nature of the representation allows us to seamlessly fuse the learned holistic embedding from coarse reasoning with image features learned from the high-resolution input in a principled manner. Each level incrementally incorporates additional information missing in the coarse levels, with the final determination of geometry made only in the highest level.
PIFu를 기반으로 재표현된 Pixel-aligned 특성은 coarse reasoning에서 추론한 임베딩과 고해상도 이미지 피쳐들을 합칠 수 있게 해줌.
missing information that is not predictable from observable measurements will result in overly smooth and blurred estimates. We overcome this problem by leveraging image-to-image translation net- works to produce backside normals, similar to [30, 11, 39]. Conditioning our multi-level pixel-aligned shape inference with the inferred back-side surface normal removes ambi- guity and significantly improves the perceptual quality of our reconstructions with a more consistent level of detail between the visible and occluded parts.
보이지 않는 뒷면의 이미지를 복구하기 위해 image-to-image translation net-works 를 사용하여 후면 법선을 생성함.
이렇게 추론된 후면 법선을 조건으로 하여 multi-level pixel-aligned shape를 inference 하면 reconstruction 성능이 개선되는것을 확인 함
Related Work
Single-View 3D Human Digitization
The recently introduced Pixel-Aligned Implicit Function (PIFu) [35] does not explicitly discretize the output space representation but instead regresses a function which de- termines the occupancy for any given 3D location. This approach shows its strength in reconstructing high-fidelity 3D geometry without having to keep a discretized represen- tation of the entire output volume in memory simultaneously. Furthermore, unlike implicit surface representations using a global feature vector [29, 32, 10], PIFu utilizes fully convolutional image features, retaining local details present in an input image
이전에 연구팀이 발표했던 PIfu를 사용해 메모리 효율적으로 3D geometry를 표현할 수 있는 장점을 보여준다. 또한 PIFu는 글로벌 피쳐를 사용하는 다른 Implict surface method와는 다르게 Fully convolutional 네트워크를 사용해 지역적 디테일을 가질 수 있다.
High-Resolution Synthesis in Texture Space

기존에 사용하던 텍스처 맵 표현 방식(Tex2Shape : UV 택스쳐 맵을 만들고 이를 딥러닝으로 보완하여 높은 해상도의 텍스처를 만듬)은 템플릿 매쉬의 토폴로지와 UV 맵의 토폴로지에 의존성을 가지고 있음
Method
Pixel-Aligned Implicit Function
Limitation
Importantly, the network should be designed such that its receptive field covers the entire image so that it can employ holistic reasoning for consistent depth inference— thus, a repeated bottom-up and top-down architecture with intermediate supervision [31] plays an important role to achieve robust 3D reconstruction with generalization ability.
We found that while in theory the continuous representation of PIFu can represent 3D geometry at an arbitrary resolution, the expressiveness of the representation is bounded by the feature resolution in practice.
Thus, we need an effective way of balancing robustness stemming from long-range holistic reasoning and expressiveness by higher feature embedding resolutions.
결론적으로 깊이 추론(z value)의 일관성을 위하여 네트워크의 receptive field 가 전체 이미지를 포함하도록 설계되어야 함.
-> PIFu가 이론상 임의의 해상도에서의 3D geometry를 나타낼 수 있지만 재구축된 3D geometry의 resolution(the expressiveness of the representation)은 feature 임베딩 공간의 resolution을 따라간다는것을 알 수 있음.
->따라서 고화질의 피쳐 임베딩 레졸루션을 뽑아내는 네트워크를 로버스트하게 유지시킬 효과적인 방법이 필요하다.
Multi-Level Pixel-Aligned Implicit Function
1024x1024 해상도 이미지를 입력으로 사용하기 위해 2가지의 PIFu 모듈을 사용함.
1) 1024x1024에서 다운샘플링된 512x512이미지를 입력으로 받아 geometric 정보를 가지고 있는 128x128 image feature를 생성하는 Coarse level PIFu Backbone 네트워크
2) 1024x1024이미지를 입력으로 받아 512x512 image feature를 생성하는 Fine level PIFu Backbone 네트워크

또한 다음 섹션에서 설명할 image-to-image 네트워크로 생성된 전면과 후면 normal map를 각각 PIFu 모듈에서 사용함
Low-resolution PIfu

- : low-resolution input(512x512)
- , : predicted Front/Back normal map (same resolution)
- : 3D point 에서 카메라에 투영한 2D 좌표
- : low-resolution image feature extrator 결과로써 임베딩된 이미지 피쳐를 리턴함
High-resolution PIFu
고해상도 PIFu 모듈은 저해상도 PIFu 모듈에서 추출한 embedding feature : 를 depth val 대신 사용한다.
- : high-resolution input(1024x1024)
- , : predicted Front/Back normal map (same resolution)
- : 3D point 에서 카메라에 투영한 2D 좌표 이 경우 이 된다(512->1024)
- : high-resolution image feature extrator.
Low-resolution Pifu와의 차이점은 의 receptive필드가 이미지 전체(1024x1024)를 커버하지 않고 슬라이딩 윈도우 형식으로 네트워크를 훈련한다는 점, 그리고 low-resolution PIFu에서 가져온 feature인 를 sdf함수의 입력으로 사용한다는 점이 있다.
Because the fine level takes these features from the first pixel-aligned MLP as a 3d embedding, the global reconstruc- tion quality should not be degraded, and should improve if the network design can properly leverage the increased image resolution and network capacity.
Additionally, the fine network doesn’t need to handle normalization (i.e., producing a globally consistent 3D depth) and therefore doesn’t need to see the entire image, allowing us to train it with image crops.
This is important to allow high-resolution image inputs without being limited by memory.
High resolution Pifu는 Low-resolution Pifu에서 전체적인 feature를 가져오기 때문에 슬라이딩 윈도우를 통해 지역적인 feature를 학습하여도 global reconstruction quality에는 저하가 없다. 또한 High resolution Pifu는 정규화 작업이 필요없기 때문에 디테일한 feature를 훈련하기 위해 슬라이딩 윈도우로 네트워크를 훈련할 수 있다. 또한 슬라이딩 윈도우를 사용하므로 하드웨어의 물리적 한계를 극복할 수 있다.
Front-to-Back Inference
The backside must therefore be inferred entirely by the MLP prediction network and, due to the ambiguous and multimodal nature of this problem, the 3D reconstruction tends to be smooth and featureless.
사람의 정면 이미지가 주워졌을 때 관찰하지 않은 등의 geometry를 알 수 없기때문에 뒷면은 MLP 네트워크에 의해 전부 추론하여야 하고 이때 사용되는 평균Loss의 특성상 3D geometry가 부드럽고 디테일한 특징이 사라지는 경향이 있음. 또한 PIfu 네트워크가 한번에 앞면과 뒷면을 inference 하기 위해서는 네트워크가 복잡해지므로 오버피팅의 위험성이 존재한다.
이를 해결하기 위해 뒷면의 이미지를 예측해주는 task를 따로 추가하여 normal map을 생성하였고 이를 Pifu에 입력함으로써 더 좋은 퀄리티의 3D geometry를 얻을 수 있었다.
본 논문에서는 Pix2PixHD 네트워크를 사용해 이미지의 후면 법선과 전면 법선을 예측한다.
Pix2PixHD loss
Loss Functions and Surface Sampling
크로스엔트로피 loss를 사용하였음
- : loss를 측정할 sample들의 set
- : 에서 표면 밖 점들의 비율
- : GT
- : Pred
Evaluations
Quantitative eval
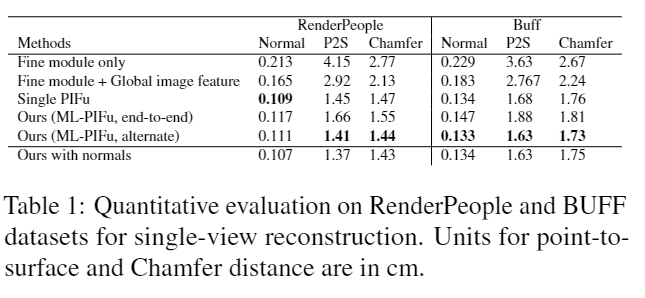
-
Fine module only : High resolution module만 사용
-> 오버피팅 -
Fine module + Global image feature : Pifu image encoder에 Resnet34 사용
-> 디테일하지만 Robust 하지 않음 -
Coarse module (Pifu) : Low resolution module만 사용
-
Our(ML-Pifu,end to end) : Fine+Coarse module 둘 다 사용
-
Our(ML-Pifu, alter) : Fine,Coarse 뒤바꿔서 사용
Qualitative eval
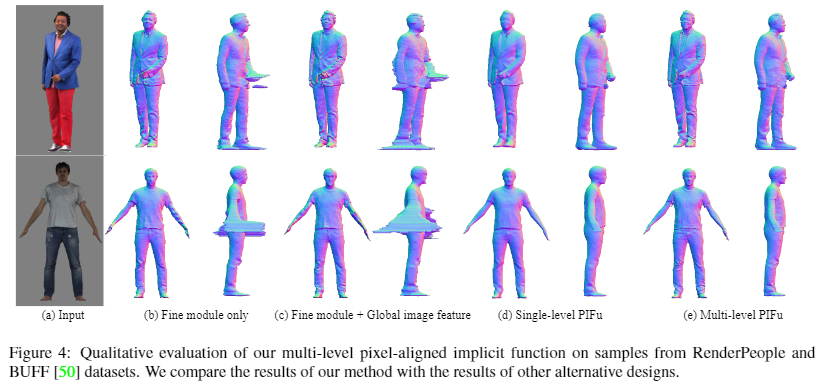
with normal
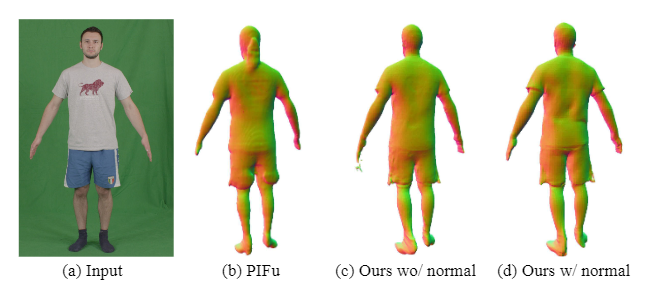
image-to-image translation 네트워크로 이미지의 법선백터를 재공하면 관측되지 않은 부분의 세부적인 디테일이 살아나는것들 확인할 수 있다.
Key idea
ML-Pifu
해상도 증가를 위한 coarse to fine 프레임워크
image-to-image translation networks
보이지 않는 구역(뒷면)을 추론하는 네트워크
